1.本发明涉及语义识别领域,具体涉及一种基于字典树分类的可配置化领域识别方法。
背景技术:
2.意图识别是自然语言处理中的一个方向,常用的方法有:基于词典模板的规则分类、基于过往日志匹配(适用于搜索引擎)、基于分类模型进行意图识别。这三种方式基本上是目前比较主流的方法。基于词典的模板规则匹配通用性有限,当请求文本发生变化时(无法预测用户请求的说法),容易出现识别失误的情况。基于日志匹配的方法不适用于电视上语音交互系统。分类模型的方法难点主要是两点,一点是数据来源的匮乏,因为方法已经比较固定,基本都是有监督学习,需要很多的标记数据。第二点是尽管是分类工作,但是意图识别分类种类很多,并且要求的准确性,拓展性都不是之前的分类可比的,这一点也是很困难的。
3.目前的领域识别服务中,当需要新增一个领域时,算法模型需新增大量的对应训练数据,训练过程耗时较长,并由于数据量不平衡,对新增领域的支持效果不够好;采用规则、缓存的形式新增领域,可以解决上述训练模型的问题,但是由于缓存一类方法要求完全匹配,导致这种识别方式泛化性不够好,当请求稍微变化后,便难以正确识别。
4.针对识别方法的泛化性:领域识别由缓存—规则—算法,三部分实现,其中算法采用深度学习的方式,是完成领域识别泛化性的主要方式,但是当需要新增领域的时候,用深度学习方式支持新增领域需要增加大量的训练数据,并且需要重新迭代模型,比较耗时,并且无法立即生效。
5.针对服务的可配置性:领域识别中缓存可以随时添加并立即生效,但是泛化性不强;cnn的深度学习模型泛化性高但是无法随时更改。
技术实现要素:
6.本发明的目的是提供一种基于字典树分类的可配置化领域识别方法,实现了对新增领域的支持,相比缓存和规则,拥有更好的泛化性,并且实现动态添加、删除以及修改领域特征词,达到了可配置的效果。
7.本发明采取如下技术方案实现上述目的,基于字典树分类的可配置化领域识别方法,包括:
8.步骤1、分析各领域请求文本,提取各领域关键词,并生成字典树数据;
9.步骤2、根据字典树数据构建字典树,并为字典树添加数据增添、删除以及修改方法;
10.步骤3、将请求文本预处理后输入字典树,计算其命中领域权重;
11.步骤4、判断权重最大领域是否在配置领域内,若是则输出领域识别结果,否则返回空值。
12.进一步的是,步骤1中,分析各领域请求,提取各领域关键词,并生成字典树数据的具体方法包括:
13.步骤101、从用户请求、训练数据以及测试数据中获取分析各领域的请求文本;
14.步骤102、通过tf
‑
idf方法提取各领域关键词;
15.步骤103、对得到的关键词进行数据分词,并构建特征规则,根据特征规则替换其中包含的具体实体内容,若没有具体实体内容则替换为特征数据;
16.步骤104、根据替换后的分词数据生成字典树数据。
17.进一步的是,步骤2中,根据字典树数据构建字典树的具体方法包括:
18.将字典树数据中的字符按照阅读先后顺序,分别作为字典树的父节点、子节点构建字典树。
19.进一步的是,步骤2中,数据增添方法包括:增添数据时,若特征规则已在字典树中并且所属数据领域不同时,则在子节点添加领域值。
20.进一步的是,步骤2中,数据删除的方法包括:删除数据时,将目标特征的领域置为none。
21.进一步的是,步骤2中,数据修改的方法包括:修改数据时,则删除原特征领域,增加新特征领域。
22.进一步的是,步骤3中,计算各命中领域权重的具体方法包括:
23.步骤301、对文请求文本的具体实体的属性进行判断,若请求文本中具体实体内容包含多个属性,则将替换后的实体分别带入原句并拼接,保证与规则特征匹配;
24.步骤302、将替换处理后的请求文本全分词,把所有分词结果在字典树中查找,已匹配字符长度与总字符长度比值作为该领域特征权重,特征权重计算公式为:匹配字符长度与总字符长度比值作为该领域特征权重,特征权重计算公式为:为已匹配字符长度,l为总字符长度;
25.步骤303、对特征权重进行归一化处理,获取各对应领域分值,分值计算公式为:β
k
表示第k个领域权重,ω
k
表示第k个领域分值,min(β)表示最小权重,max(β)表示最大权重。
26.进一步的是,步骤4中,判断权重最大领域是否在配置领域内的具体方法包括:对各领域权重按照分值进行排序,取分值最大的领域作为权重最大领域。
27.本发明采用字典树的形式,匹配领域特征,实现对新增领域的支持,相比缓存和规则,拥有更好的泛化性。通过增加数据增添、删除以及修改方法,实现了动态添加、删除以及修改领域特征词,达到了动态配置的效果;采用字典树避免了新增领域时大量的模型训练,提高了领域识别效率。
附图说明
28.图1是本发明字典树的结构示意图。
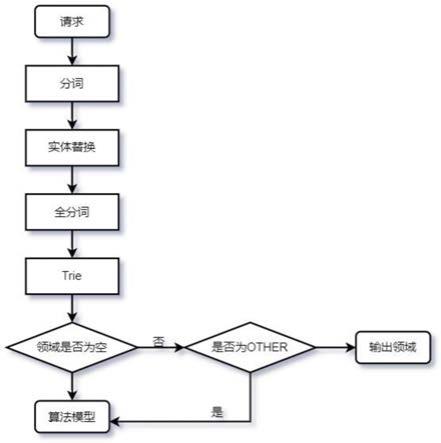
29.图2是本发明领域识别方法流程图。
30.图3是本发明动态配置示意图。
具体实施方式
31.本发明基于字典树分类的可配置化领域识别方法,包括:
32.步骤1、分析各领域请求文本,提取各领域关键词,并生成字典树数据;
33.步骤2、根据字典树数据构建字典树,并为字典树添加数据增添、删除以及修改方法;
34.步骤3、将请求文本预处理后输入字典树,计算其命中领域权重;
35.步骤4、判断权重最大领域是否在配置领域内,若是则输出领域识别结果,否则返回空值。
36.步骤1中,分析各领域请求,提取各领域关键词,并生成字典树数据的具体方法包括:
37.步骤101、从用户请求、训练数据以及测试数据中获取分析各领域的请求文本;
38.步骤102、通过tf
‑
idf方法提取各领域关键词;
39.步骤103、对得到的关键词进行数据分词,并构建特征规则,根据特征规则替换其中包含的具体实体内容,若没有具体实体内容则替换为特征数据;
40.步骤104、根据替换后的分词数据生成字典树数据。
41.步骤2中,根据字典树数据构建字典树的具体方法包括:
42.将字典树数据中的字符按照阅读先后顺序,分别作为字典树的父节点、子节点构建字典树。
43.步骤2中,数据增添方法包括:增添数据时,若特征规则已在字典树中并且所属数据领域不同时,则在子节点添加领域值;
44.数据删除的方法包括:删除数据时,将目标特征的领域置为none;
45.数据修改的方法包括:修改数据时,则删除原特征领域,增加新特征领域。
46.步骤3中,计算各命中领域权重的具体方法包括:
47.步骤301、对文请求文本的具体实体的属性进行判断,若请求文本中具体实体内容包含多个属性,则将替换后的实体分别带入原句并拼接,保证与规则特征匹配;
48.步骤302、将替换处理后的请求文本全分词,把所有分词结果在字典树中查找,已匹配字符长度与总字符长度比值作为该领域特征权重,特征权重计算公式为:匹配字符长度与总字符长度比值作为该领域特征权重,特征权重计算公式为:为已匹配字符长度,l为总字符长度;
49.步骤303、对特征权重进行归一化处理,获取各对应领域分值,分值计算公式为:β
k
表示第k个领域权重,ω
k
表示第k个领域分值,min(β)表示最小权重,max(β)表示最大权重。
50.步骤4中,判断权重最大领域是否在配置领域内的具体方法包括:对各领域权重按照分值进行排序,取分值最大的领域作为权重最大领域。
51.本发明领域识别方法的一种实施例流程图如图2,第一步从用户请求、训练数据、测试数据中获取,分析各领域的请求文本,通过tf
‑
idf方法,获取各个领域的关键词;通过人工筛选,对得到的数据分词,替换其中包含的实体(如“刘德华的无间道”,替换后变为“演
员的视频”),生成字典树的数据;
52.第二步,构建字典树(trie树,一种哈系树的变种),树的父节点为各领域特征词,子节点为该特征词所在领域,如“我—想—听—music”,“我想听”是“music”领域的关键词,将其拆分为单字,“我”作为父节点,“想”是其子节点,以次类推,最终的子节点便是该关键词所属领域“music”。如关键词所属多个领域,则子节点便含有多个领域;
53.字典树的一种实施例结构示意图如图1,我作为父节点,“想”、“要”是其子节点,以次类推;
54.同时增加动态配置方法,通过数据库中更新时间标志以及删除标志,判断是否对字典树数据进行更改(增加关键词数据或删除),如图3所示,判断是否有变化标志,如果是则进一步判断是否对字典树数据进行更改,如有删除标志,则删除对应词,结束;否则对更改标志进行判断,如有更改标志,则修改对应词,结束,若没有更改标志,则添加对应词,结束。
55.第三步,对获取到的用户请求,以处理字典树数据相同的方式,分词替换其中实体,再全分词后输入字典树匹配,利用字符长度作为权重计算标准,计算各个命中领域的权重;
56.第四步,判断权重最大领域是否为配置领域,是的话,输出预测结果,否则返回空,交由后续模型识别。
57.具体实施例如下:
58.a.生成字典树:
59.根据新加领域数据特征,构建规则,组合成为字典树的领域特征数据,如story领域中,将所有故事名称类实体替换为“故事”字符(“讲一下乌鸦喝水的故事”—“讲一下故事的故事”),如没有具体实体,则直接存为特征数据(“给我讲个故事”)。同时,以相同的规则构建方法,对其余所有未配置的领域特征数据作为修正领域“other”的特征;
60.b.构建字典树,添加数据增删改方法:
61.将存入的特征数据中的字符按阅读顺序,分别作为树的父节点
‑
子节点,构建字典树(“给——我——讲——个——故——事——story”)。如特征规则属于多个领域,则最终子节点全部包含(“story other”)。
62.进行配置时调用字典树的增删数据方法:增添数据时,如特征规则已在树中并且领域不同,则在子节点添加领域值;删除数据时,将目标特征的领域置为none;修改时,则删除特征原领域,增加特征新领域;
63.c.请求预处理后输入字典树,计算各命中领域权重:
64.将请求以步骤a中构建数据时使用的相同方法替换其中实体,如果请求中实体名包括多个属性(如无间道——video&song),将替换后的实体别分带入原句并拼接,保证与规则特征匹配(我想看无间道——我想看视频我想看电影)。
65.将处理后的请求全分词,把所有分词结果在字典树中查找,已匹配字符长度与总字符长度比值作为该领域特征权重:
[0066]66.为已匹配字符长度,l为总字符长度;
[0067]
对特征权重进行归一化处理,获取各对应领域分值,分值计算公式为:
β
k
表示第k个领域权重,ω
k
表示第k个领域分值,min(β)表示最小权重,max(β)表示最大权重;
[0068]
d.判断权重最大领域是否在配置领域内,输出结果:
[0069]
对得到可能领域权重排序,取得分最大领域,如果最大领域不为修正领域“other”,则输出领域。
[0070]
综上所述,本专利利用字典树模型,用于识别需新增领域、语料较少的领域,使领域识别服务更加灵活,同时减少了模型部分的训练数据,减少训练模型的消耗同时增加了整体服务识别的准确率。同时因字典树的可配置性,整体领域识别服务也可以实施配置,并且和缓存配置相比具有较强的泛化性。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。