1.本发明属于路径规划技术领域,更进一步涉及动态路径规划技术领域中的一种多智能体动态路径规划方法。本发明可以高效规避动态障碍物,从而规划出智能体在运动过程中前往目的地的最优路径。
背景技术:
2.多智能体是由一系列相互作用的智能体构成,内部的各个智能体遵循相应的组织规完成特定任务,其中智能体指具有自组织性与社会性基本特性的实体,可以看作是相应的软件程序或者一个实体(如人、车辆、机器人等),它嵌入到环境中,通过传感器感知环境,通过效应器自治地作用于环境并满足设计要求。对多智能体的路径规划广泛应用于智能巡检、飞行器航迹规划、自动驾驶等领域。多智能体路径规划是指在存在障碍物的空间中,对地图等先验信息和传感器所感知的数据进行分析处理,感知智能体周围环境状态。在对周围环境完成感知后,通过设计好的策略寻找到一条从起始点到目标点的符合某种评价指标的最优无冲突路径,确保按照该路径进行行驶时可以绕过障碍物,顺利到达目的地。多智能体的路径规划中,主要实现三个目标:规划一条从起点到目标点的路径;在沿着该路径行驶的过程中智能体遇到能够成功规避障碍物;在满足以上两个目标的基础上,尽量使规划路径满足全局最优性。目前,解决这类问题的方法通常有:启发式的随机搜索算法与智能优化算法。
3.启发式的随机搜索算法是一种基于启发式信息的路径规划方法,利用问题自身所携带的启发式信息引导算法朝着最有希望的方向搜索,从而寻找到最优路径。例如:
4.电子科技大学在其申请的专利文献“一种基于改进rrt算法的无人机路径规划方法”(申请号:cn202110409420.5,申请公布号:cn112987799a)中公开了一种基于启发式多方向快速探索树的机器人路径规划优化方法。该方法在高维配置空间中,借鉴快速扩展随机树rrt(rapidly exploring random tree)算法的思想。首先在随机树在扩展过程中没有遇到障碍时,会逐渐增强其向目标点方向快速靠拢的倾向,然后一旦遇到障碍,将会立即降低这种倾向,最大化生长的随机性,从而使得随机树更高效地避开障碍物,最终生成成功规避障碍物的一条局部最优路径。该方法能够以较小的代价会选择父节点,而不是简单地选择最近节点,最大限度地提高了规划效率和速度。但是,该方法仍然存在的不足之处是:改进的rrt算法规划的路径没有考虑动态障碍物,即其他智能体,则只能等待来规避或者沿原路返回,增加了无效行驶路径的长度,严重影响移动智能体的行驶速度。
5.通过智能优化算法进行多智能体动态路径规划的方法多为在强化学习方法等基础上进行的研究,例如q
‑
learning算法、sarsa(state action reward state action)算法,即通过智能体与环境的不断交互,统一障碍物构建环境建模,快速实现路径与所有障碍物的碰撞检测,为智能体规划一条最优路径,例如:
6.大连理工大学在其申请的专利文献“一种基于蚁群算法的多智能体强化学习路径规划方法”(申请号:cn202011257321.1,申请公布号:cn112286203a)中公开了一种基于蚁
群算法的多智能体强化学习路径规划方法。该方法包括两个阶段,第一阶段获取智能体集群当前环境信息。首先,利用蚁群算法中的信息素作为启发式信息,探测环境中的障碍物,并存储其极坐标信息,其次按照传感器信息、目标位置信息、信息素信息、自身序号的顺序,将收集到的状态信息抽象为一个多元组,作为当前的状态描述初始化环境中的信息素地图。第二阶段训练多智能体路径规划深度强化学习模型,首先初始化共享经验池d,设置共享经验池大小为n,初始化蚁群信息素地图,设置信息素的扩散速率η和衰减率ρ,智能体集群中智能体数量ω,采用基于q
‑
learning的改进dqn深度强化学习方法及蚁群“信息素”协同机制,然后利用智能体集群历史信息对神经网络进行训练更新,最终得到智能体集群中各智能体的最优路径规划策略。该方法虽然同样可以用于多智能体的路径规划,但是,该方法仍然存在的不足之处是:只考虑了非相向冲突,忽略了由移动智能体本身带来的相向冲突,导致智能体实际行驶过程中需要不断规避,无法重规划智能体的最优规避路径,严重影响智能体的行驶效率。
技术实现要素:
7.本发明的目的在于针对上述现有技术的不足,提出一种多智能体动态路径规划方法,旨在解决智能体在动态路径规划中由其它移动智能体本身带来的相向冲突,导致智能体实际行驶过程中需要不断规避,严重影响智能体行驶效率的问题。
8.为实现上述目的,本发明的思路是:当两个智能体行驶发生相向冲突时,采用双智能体q学习协同避障算法规划冲突智能体的行驶路径,两个智能体以可通行栅格位置的组合为起始位置实现全局动态路径规划,并对智能体给予奖励值,指引智能体选择可搜索范围内使行驶路径最短的移动方向作为下一个移动方向,解决了不能重新规划找到两个智能体的最优规避路径的问题。本发明通过在栅格地图中引入安全区,使两个行驶方向相对的智能体只有一个能进入该区域,另一个停留在此区域入口处,摆脱现有动态路径规划方法中障碍物固定的束缚,解决了智能体动态路径规划中行驶重复路段的问题。
9.实现本发明目的的具体步骤如下:
10.步骤1,构建含有安全区的栅格地图:
11.(1a)利用栅格法,构建一个宽度、长度为x、y的栅格地图;
12.(1b)在栅格地图中将同一时刻为其它智能体的避让相向行驶智能体的区域,设置为该单向车道中的安全区;
13.(1c)以栅格地图左上角为原点,向右延伸为横轴正方向,向下延伸为纵轴正方向,建立栅格地图的笛卡尔直角坐标系,在该坐标系中标注智能体的起始位置与目标位置;
14.步骤2,利用a
*
算法,在栅格地图的笛卡尔直角坐标系中对每个智能体的行驶路径进行粗规划;
15.步骤3,利用双智能体q学习协同避障算法规划冲突智能体的行驶路径:
16.(3a)每个智能体按照为其粗规划的路径行驶,若单向车道中两个智能体发生相向冲突时,为两个智能体同时规划无冲突的行驶路径;
17.(3b)创建一个用于存储两个智能体信息的q值表,将q值初始值设置为
‑2×
10
‑9,其中,q值表的横坐标表示两个智能体可通行栅格位置的组合,纵坐标表示两个智能体移动方向的组合;
18.(3c)当两个智能体同时检测到同一个安全区时,使两个行驶方向相对的智能体只有一个能进入该区域,另一个停留在此区域入口处,将当前位置各自作为两个智能体的起始位置;
19.(3d)按照ε
‑
greedy策略,两个智能体利用探索率ε分别在上行、下行、左行、右行,停止中随机选择一个移动方向,其中,将探索率ε的值设置为0.5;
20.(3e)两个智能体按照所选方向更新位置,将更新后的位置作为起始位置;
21.(3f)将起始位置的类型为目标位置的两个智能体各奖励1分,将两个智能体中至少有一个遇到障碍物或者起始位置的类型属于安全区的智能体惩罚1分,将至少一个智能体到达可通行的位置,但此位置不是目标位置的,则奖励该智能体1分;
22.(3g)利用更新公式,更新q值表中的所有q值并选出更新后的最大q值;
23.(3h)判断更新后的起始位置是否为步骤(1c)设定的目标位置,若是,则执行步骤4,否则,执行步骤(3d);
24.步骤4,将智能体起始位置至目标位置经过的路径点顺序连接得到智能体的无冲突行驶路径。
25.与现有技术相比,本发明具有以下优点:
26.第一,本发明采用双智能体q学习协同避障算法规划冲突智能体的行驶路径,以两个智能体可通行栅格位置的组合为起始位置实现全局动态路径规划,并对智能体给予奖励值,指引智能体选择可搜索范围内使行驶路径最短的移动方向作为下一个移动方向,克服了现有技术不能重规划找到两个智能体的最优规避路径,严重影响移动智能体行驶效率的问题,使得本发明规划的路径提高了智能体的行驶效率,减少了智能体的行驶时间,有效的避免再次发生冲突。
27.第二,本发明通过在栅格地图中引入安全区,使两个行驶方向相对的智能体只有一个能进入该区域,另一个停留在此区域入口处,直接触发相向冲突规避算法,克服了现有技术规划动态路径中存在动态障碍物时,则只能等待或者沿原路返回来规避,严重影响移动智能体行驶速度的问题,使得本发明规划的路径提高了智能体的行驶速度,提升了相向冲突规避算法的效率,减少了智能体无效行驶的路程。
附图说明
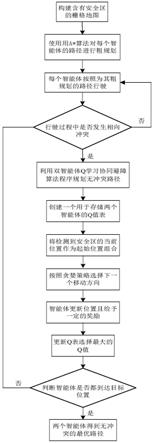
28.图1是本发明的流程图;
29.图2是本发明的含有安全区的栅格地图示意图;
30.图3是本发明的智能体发生冲突的示意图;
31.图4是本发明的仿真图。
具体实施方式
32.下面结合附图和实施例对本发明做进一步的详细描述。
33.参照图1,对本发明的实现步骤做进一步的详细描述。
34.步骤1,构建含有安全区的栅格地图。
35.利用栅格法,构建一个宽度、长度为x、y的栅格地图。
36.在栅格地图中将同一时刻为其它智能体的避让相向行驶智能体的区域,设置为该
单向车道中的安全区。
37.以栅格地图左上角为原点,向右延伸为横轴正方向,向下延伸为纵轴正方向,建立栅格地图的笛卡尔直角坐标系,在该坐标系中标注智能体的起始位置与目标位置。
38.参照图2,对本发明构建的含有安全区的栅格地图做进一步的详细描述。
39.图2为本发明构建的含有安全区的栅格地图,栅格地图的左上角为原点o,x轴表示栅格地图的宽度,单位为米,y轴表示栅格地图的长度,单位为米。图2中的白色小方块表示可通行栅格,深色小方块表示不可通行栅格。图2中的数字1表示智能体1,2表示智能体2,斜线表示的区域为安全区。
40.步骤2,利用a
*
算法,在栅格地图的笛卡尔直角坐标系中对每个智能体的行驶路径进行粗规划。
41.步骤3,利用q学习算法规划冲突智能体的行驶路径。
42.第一步,每个智能体按照为其粗规划的路径行驶,若单向车道中两个智能体发生相向冲突时,为两个智能体同时规划无冲突的行驶路径。
43.第二步,创建一个用于存储两个智能体信息的q值表,将q值初始值设置为
‑2×
10
‑9,其中,q值表的横坐标表示两个智能体可通行栅格位置的组合,纵坐标表示两个智能体移动方向的组合。
44.第三步,当两个智能体同时检测到同一个安全区时,将当前位置各自作为两个智能体的起始位置。
45.第四步,按照ε
‑
greedy策略,两个智能体利用探索率ε分别在上行、下行、左行、右行,停止中随机选择一个移动方向,其中,将探索率ε的值设置为0.5。
46.第五步,两个智能体按照所选方向更新位置,将更新后的位置作为起始位置。
47.第六步,将起始位置的类型为目标位置的两个智能体各奖励1分,将两个智能体中至少有一个遇到障碍物或者起始位置的类型属于安全区的智能体惩罚1分,将至少一个智能体到达可通行的位置,但此位置不是目标位置的,则奖励该智能体1分。
48.第七步,利用更新公式,更新q值表中的所有q值并选出更新后的最大q值。
49.第八步,判断更新后的起始位置是否为步骤1设定的目标位置,若是,则执行步骤4,否则,执行本步骤的第四步。
50.参照图3,对本发明规划无冲突路径的相向冲突类型做进一步的详细描述。
51.图3是发生相向冲突的两种类型的示意图,图3(a)为第一类两个智能体发生的相向冲突类型的示意图,其中黑色圆点表示智能体1与智能体2的可能碰撞发生在栅格的中间位置,此时两个智能体在栅格地图中的发生相向冲突后的起始位置坐标相同。图3(b)为第二类两个智能体发生的相向冲突类型的示意图,其中黑色表示智能体1与智能体2在栅格的交接处碰撞,此时两个智能体在栅格地图中的发生相向冲突后的起始位置坐标不相同。
52.步骤4,将智能体起始位置至目标位置经过的路径点顺序连接得到智能体的无冲突行驶路径。
53.下面结合仿真实验,对本发明的效果做进一步的说明。
54.1.仿真实验条件:
55.本发明仿真实验的硬件平台为:处理器为intel(r)core(tm)i7
‑
9700 cpu,主频为3.00ghz,内存16.0gb。
56.本发明仿真实验的软件平台为:windows10操作系统和java11。
57.本发明仿真实验主要验证相向冲突规避以及最短路径规划算法的完成度,为了能够更加清楚地展示出智能体的移动轨迹,选择在15m*29m的小规模栅格地图中对两个智能体的行驶路径进行规划。其中,每个栅格边长为1m,地图中的可通行栅格与不可通行栅格的分布为手动设定。
58.2.仿真实验内容及结果分析:
59.本发明的仿真实验采用本发明的方法和一个现有技术基于a
*
算法的路径规划方法分别对预先设定完成的栅格地图的路径规划进行仿真。
60.仿真实验的具体参数如表1所示:
61.表1:仿真实验参数表
62.参数名称参数值智能体的数目number100个任务的到达率λ1个每秒智能体的行驶速度v
rob
1m/s智能体的转弯耗时t
turn
1s学习率α0.5
63.在仿真实验中,采用的一个现有技术是指:
64.现有a
*
技术基于算法的路径规划方法是指,gelperin等人在“on the optimality of a*[j].artificial intelligence,1977,8(1):69
‑
76.”中提出的路径规划方法,简称基于a
*
算法的路径规划方法。
[0065]
下面结合图4的仿真图对本发明的效果做进一步的描述。
[0066]
图4是本发明的仿真图,其中黑色圆点表示智能体1,以黑色实线表示智能体1的行驶路径,灰色圆点表示智能体2,以黑色虚线表示智能体2的行驶路径,箭头表示其行驶方向。图4中的菱形栅格即为卸载任务的目标位置。
[0067]
图4(a)为进行路径规划前智能体行驶的原始路径的仿真结果图;图4(b)表示若按照原定路线行驶,两个智能体将在黑色三角形标注处发生相向冲突的仿真结果图;图4(c)表示两个智能体将分别在黑色圆点色与灰色圆点处,即碰撞的前一步,进行动态避障的仿真结果图;图4(d)中为本发明的路径规划方法进行路径规划的仿真结果图,黑色实线为智能体1重新规划的路径,黑色虚线表示智能体2重新规划的路径。
[0068]
从仿真实验结果可以看出,双智能体q学习协同避障算法可以成功规避相向冲突,并实现最短路径到达目标位置。当图4(c)中当两个智能体发生相向冲突时,采用动态路径规划算法进行规避,通过对比图4(c)与图4(d),可看出采用双智能体q学习协同避障算法后,相较于规划前原始行驶路径,智能体的行驶路程明显减少。程序里面直接记录输出。
[0069]
表2:仿真实验中本发明和现有技术路径规划结果的定量分析表
[0070][0071]
为了对本发明仿真实验中三种方法的行驶效率进行比较,采用java软件中的多线程中的计时器,在程序里面直接记录输出对智能体完成一个任务数目的行驶时间,其统计记录结果如表2所示。其中,智能体数目固定在100个,任务数目从200到2000之间变化,间隔为200,即选取10个不同的任务数对行驶时间进行统计,每次任务数都进行了5次实验取平均值,并且计算了行驶时间的提升比例。
[0072]
结合表2可以看出,随着任务数目的逐渐增加,本发明的路径规划方法,较于基于a
*
算法与q学习算法的路径规划方法行驶时间减少的多,行驶效率的比例也有所提升。可见本发明在规划相向冲突的路径时所需的行驶时间少于现有技术的方法,证明采用本发明的方法可以得到更优的规划路径。
[0073]
为了对本发明仿真实验中在栅格地图中引入的安全区进行验证,分别计算智能体完成一定的任务数量的总行驶路程与路径差值,其统计结果如表3所示。同样,智能体数目、任务数与统计方法与计算行驶时间的方法一致。
[0074]
表3:仿真实验中在栅格地图中引入安区的路径规划结果的定量分析表
[0075][0076]
结合表3可以看出,随着任务数目的逐渐增加,本发明的路径规划方法由于在栅格地图中引入安全区后智能体的总行驶路程减少,减少比例平均可达16%,行驶效率的比例也有所提升。可见本发明在规划相向冲突的路径时引入安全区后智能体所需的总行驶路程
减少,证明采用本发明的方法可以得到更优的规划路径。
[0077]
以上仿真实验表明:本发明通过采用双智能体q学习协同避障算法,结合在栅格地图中引入安全区的方法,为发生相向冲突的两个智能体重新规划出两条无冲突的最优路径,减少了动态路径规划中的行驶时间与总行驶路程,提高了智能体的行驶效率。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。