用于对矩阵值灵活求和的设备和方法
1.发明背景
2.使用神经网络可以解决一整类复杂的人工智能问题。许多神经网络所需的常见运算包括,例如在执行矩阵运算时的求和、乘法和点积。由于人工智能问题通常是计算和数据密集型的,所以硬件解决方案通常有利于提高性能。创建一个灵活且计算效率高的硬件平台是一项技术挑战。因此,存在对针对高效、高吞吐量硬件方案的技术的需求,该技术不会引入显著的硬件复杂性和费用。
3.附图简述
4.在以下详细描述和附图中公开了本发明的各种实施例。
5.图1是示出用于解决人工智能问题和其他计算问题的系统的实施例的框图。
6.图2是示出用于解决人工智能问题和其他计算问题的处理元件的实施例的框图。
7.图3是示出使用矩阵转置组件和低位宽(low
‑
bit
‑
width)矩阵处理组件对数字组求和的系统的实施例的框图。
8.图4a
‑
图4c是示出与使用矩阵转置组件和低位宽矩阵处理组件对数字组求和相关联的数据处理的示意图。
9.图5是示出使用矩阵转置组件和低位宽矩阵处理组件对数字组求和的过程的实施例的流程图。
10.详细描述
11.本发明可以以多种方式实现,包括作为过程;装置;系统;物质的组成;体现在计算机可读存储介质上的计算机程序产品;和/或处理器,诸如被配置为执行存储在耦合到处理器的存储器上和/或由该存储器提供的指令的处理器。在本说明书中,这些实现或者本发明可以采取的任何其他形式可以被称为技术。通常,在本发明的范围内,可以改变所公开的过程的步骤顺序。除非另有说明,否则被描述为被配置成执行任务的诸如处理器或存储器的组件可以被实现为在给定时间被临时配置为执行任务的通用组件或者被制造为执行任务的特定组件。如本文所使用的,术语“处理器”指的是被配置成处理数据(诸如计算机程序指令)的一个或更多个设备、电路和/或处理核心。
12.下面提供了本发明的一个或更多个实施例的详细描述连同说明本发明原理的附图。结合这些实施例描述了本发明,但是本发明不限于任何实施例。本发明的范围仅由权利要求限定,并且本发明包括许多替代、修改和等同物。为了提供对本发明的全面理解,在以下描述中阐述了许多具体细节。这些细节是出于示例的目的而提供的,并且本发明可以根据权利要求来被实施,而不需要这些具体细节中的一些或全部。为了清楚起见,没有详细描述与本发明相关的技术领域中已知的技术材料,以便不会不必要地模糊本发明。
13.公开了一种被配置为提高硬件中数字处理的效率的设备(例如,专用集成电路芯片)。所公开的设备包括各种组件(例如,集成电路组件):矩阵转置组件、矩阵处理组件、数据对齐组件和数据缩减(data reduction)组件。矩阵转置组件被配置为转置元素的输入矩阵以输出已经转置的元素的输出矩阵,其中:使用第一数量的比特来表示元素的输入矩阵中的每个元素,使用比第一数量的比特更大的第二数量的比特来表示存储在输入矩阵中的
一组值中的每个值,并且该组值中的每个值被存储为跨越输入矩阵元素中的一个以上元素的分割段(split segment)。矩阵处理组件被配置为将第一乘法输入矩阵与第二乘法输入矩阵相乘,其中矩阵转置组件的输出矩阵被用作第一乘法输入矩阵,并且掩码向量被用作第二乘法输入矩阵。数据对齐组件被配置成修改矩阵处理组件的结果的元素的至少一部分。数据缩减组件被配置为至少对矩阵处理组件的经修改结果的元素求和,以确定该组值的和。所公开的设备的实际和技术益处是关于数字处理的增加的灵活性,例如,使用低位宽矩阵处理组件对高位宽数字求和的能力。例如,可以本地处理低位宽格式(例如,8比特整数)的数字的点积引擎可以用于处理更高位宽的数字(例如,32比特整数)。这种灵活性节省了硬件资源。不需要实现多种硬件设计来处理多种数据格式。
14.在一些实施例中,使用专用集成电路设备将32比特整数的矩阵中的值(例如,所有值)求和为单个标量,该专用集成电路设备包括矩阵转置组件、可以本地处理8比特整数的矩阵乘法组件、多个比特移位器和加法器单元。在一些实施例中,矩阵乘法组件是多个点积组件。乘以一个矩阵可以分解成矩阵的行与特定向量的一组点积。将矩阵值求和为单个标量的应用包括神经网络计算(例如,应用softmax函数)和其他计算问题。如本文进一步详细描述的,在各种实施例中,输入矩阵由矩阵转置组件转置,并且转置的矩阵的行与一的掩码向量(mask vector of ones)进行向量相乘,以获得向量结果,该向量结果的元素然后被比特移位指定的量并求和。
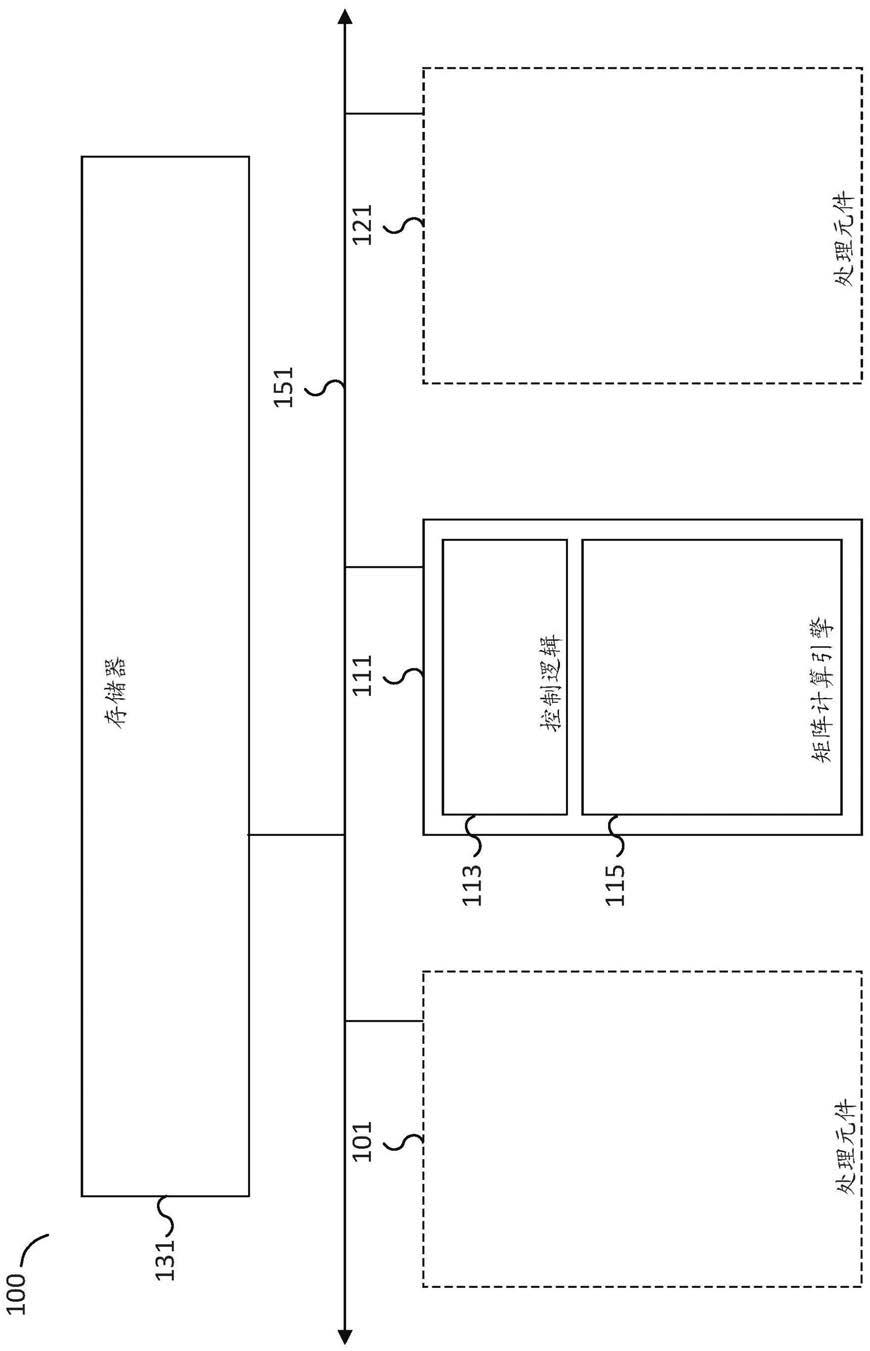
15.图1是示出用于解决人工智能问题和其他计算问题的系统的实施例的框图。例如,系统100可被应用以使用神经网络来解决诸如图像识别和推荐系统匹配的问题。在所示的示例中,系统100包括多个处理元件,诸如通过总线151连接到存储器单元131的处理元件101、111和121。系统100可以包括更少或更多的处理元件。例如,处理元件的数量可以根据预期的计算和数据要求而按比例增加(scaled up)或减少。在一些实施例中,诸如101、111和121的处理元件经由总线151而彼此通信地连接和/或通信地连接到存储器单元131。例如,存储器单元可以是末级高速缓存(last level cache,llc)和/或可以使用静态随机存取存储器(sram)来实现。系统100可以利用每个处理元件来执行矩阵计算运算,诸如求和、乘法、点积、矩阵乘法等,包括整数和浮点运算。在一些实施例中,不同的处理元件用于不同的运算和/或数据格式。例如,一些处理元件可以用于计算整数点积,而其他处理元件用于计算浮点点积。
16.在一些实施例中,诸如总线151的通信总线用于传输处理元件指令和可选的指令参数(argument)。例如,矩阵运算和矩阵操作数可以经由总线151传输到处理元件,诸如处理元件101、111和/或121。附加的处理元件指令可以包括求和、乘法、点积、矩阵乘法等运算指令,诸如整数或浮点运算指令。在各种实施例中,可以使用系统100通过将问题细分成较小的子问题来解决大型的复杂人工智能问题。较小的子问题可以被分派和分配给不同的处理元件。较小子问题的结果可以被合并,以确定较大和更复杂问题的解。在某些情况下,子问题是并行地和/或在流水线级(pipelined stage)解决的。在一些情况下,来自第一处理元件的结果作为输入被馈送到第二处理元件。
17.在一些实施例中,系统100的每个处理元件至少包括控制逻辑单元和矩阵计算引擎。如关于处理元件111所示,处理元件111包括控制逻辑113和矩阵计算引擎115。处理元件101和121显示为虚线框,并且没有示出处理元件101和121的一些细节。在一些实施例中,处
理元件的控制逻辑单元用于控制处理元件的操作,包括处理元件的矩阵计算引擎的操作。在所示的示例中,控制逻辑113处理经由通信总线151导向处理元件111的指令。例如,处理元件指令可以包括整数或浮点运算指令。在一些实施例中,控制逻辑113确定如何使用矩阵计算引擎115执行整数或浮点运算,包括如何确定整数或浮点数操作数的分量。在一些实施例中,控制逻辑113经由总线151接收处理元件指令,并且可以用于启动从存储器131检索数据和/或向存储器131写入数据。
18.在一些实施例中,矩阵计算引擎115是硬件矩阵计算引擎,用于执行矩阵运算,包括与整数或浮点求和、乘法、点积、矩阵乘法和/或卷积运算相关的运算。例如,矩阵计算引擎115可以是用于执行需要整数乘法和加法运算的点积运算的矩阵引擎。在一些实施例中,支持的卷积运算包括逐深度(depthwise)、逐组(groupwise)、正常(normal)、规则(regular)、逐点(pointwise)、二维和/或三维卷积等。例如,矩阵计算引擎115可以接收第一输入矩阵(例如大图像的子集)以及接收第二输入矩阵(例如滤波器、核(kernel)或卷积矩阵等)以应用于第一输入矩阵。矩阵计算引擎115可用于使用两个输入矩阵执行卷积运算,以确定结果输出矩阵。在一些实施例中,矩阵计算引擎115包括输入和/或输出缓冲器,用于加载输入数据矩阵或向量和写出结果数据矩阵或向量。在一些实施例中,矩阵计算引擎115包括多个向量单元,并且每个向量单元包括向量乘法单元和向量加法器单元。
19.图2是示出用于解决人工智能问题和其他计算问题的处理元件的实施例的框图。在所示的示例中,处理元件201通信地连接到总线251。处理元件201包括控制逻辑203和矩阵计算引擎205。矩阵计算引擎205包括向量单元211、221、231和241。矩阵计算引擎205可以包括更多或更少的向量单元。例如,矩阵计算引擎可以包括32个向量单元,每个向量单元能够处理两个256位向量。在各种实施例中,每个向量单元包括向量乘法单元和向量加法器单元。在所示的示例中,向量单元211包括向量乘法单元213和向量加法器单元215。为简单起见,向量单元221、231和241的向量乘法单元和向量加法器单元未示出,但功能类似于向量乘法单元213和向量加法器单元215。在一些实施例中,不同的向量单元用于不同的运算和/或数据格式。例如,一些向量单元可用于计算整数点积,而其他向量单元用于计算浮点点积。处理元件中的所有向量单元也可以用于相同的运算和/或数据格式。在一些实施例中,处理元件201是图1的处理元件101、111和/或121。在一些实施例中,控制逻辑203和矩阵计算引擎205分别是图1的控制逻辑113和矩阵计算引擎115。
20.在一些实施例中,矩阵计算引擎205接收输入矩阵(或向量)操作数以执行矩阵运算。例如,矩阵计算引擎205可以接收对应于图像的一部分的一个或更多个数据输入向量和对应于滤波器矩阵的至少一个权重输入向量。输入向量(诸如输入数据和权重向量)可以作为参数传递给向量单元,诸如矩阵计算引擎205的向量单元211、221、231和241之一。例如,矩阵计算引擎205的向量单元可以使用数据输入向量和权重输入向量对来确定矩阵结果,诸如点积结果。在一些实施例中,矩阵计算引擎205包括32个向量单元。每个向量单元可以取两个n元向量作为自变量,并确定一个n元向量结果。在一些实施例中,该结果是输出向量结果。在一些实施例中,通过跨多个向量单元运算累加部分向量结果来确定输出结果。例如,乘法运算可以分解为多个乘法运算,并将结果相加。在各种实施例中,矩阵计算引擎205的向量单元的数量可以变化,向量单元长度和元素大小也可以变化。根据向量单元的能力,可以在本地支持不同的元素大小。在一些实施例中,本地支持8比特整数格式。
21.在一些实施例中,矩阵计算引擎205的每个向量单元(诸如向量单元211、221、231或241)接收两个向量操作数,并且执行一个或更多个向量运算。例如,向量单元可以通过将第一输入向量的每个元素与第二输入向量的对应元素相乘来计算多个乘法运算的结果。所得到的乘法结果可以被累加并用于将来的运算,诸如对部分结果求和。例如,向量单元结果可以被累加,并用作由向量单元执行的后续运算的操作数。
22.在一些实施例中,矩阵计算引擎205的每个向量单元(诸如向量单元211、221、231或241)包括向量乘法单元和向量加法器单元。每个向量乘法单元(诸如向量乘法单元213)被配置为使经由输入向量操作数接收的相应元素相乘。在一些实施例中,结果是相乘结果的向量。来自第一输入向量的第一元素与第二输入向量的第一元素相乘。类似地,来自第一输入向量的第二元素与第二输入向量的第二元素相乘。在各种实施例中,相乘结果的向量被传递到向量单元的向量加法器单元。例如,向量乘法单元213可以将其乘法结果传递给向量加法器单元215。向量加法器单元215可用于加法运算,诸如对部分结果求和、至少部分计算点积结果或其他适当的功能。例如,可以通过使用向量加法器单元215来对向量乘法单元213的输出的所有元素求和来计算点积。
23.在一些实施例中,向量单元的每个向量加法器单元(诸如向量加法器单元215)被配置为使用来自输入向量的元素来计算加法运算。例如,可以由向量加法器单元215计算从由向量乘法单元213计算的乘法结果的向量中选择的元素的和。在一些实施例中,向量加法器单元的结果是用作相应向量乘法单元的输入的向量的点积。在各种实施例中,每个向量加法器单元(诸如向量加法器单元215)被实现为加法器树。例如,加法器树的顶层可以将成对的元素相加以确定一组部分和,例如将元素0和1相加以确定第一部分和,以及将元素2和3相加以确定第二部分和,等等。每个后续层可以对来自前一层的成对的部分和进行求和,直到最后一层计算出最终结果和(result sum)。在一些实施例中,指定的部分和可以被输出作为加法器单元的结果。在一些实施例中,每个加法器树并行计算部分和,以得到结果和。并行运算显著提高了对数字向量进行求和的效率。在一些实施例中,每个加法器树包括多个二进制加法器、至少一个寄存器和数据路由路径。多个向量单元可以并行运算以并行计算多个结果,从而显著提高矩阵计算引擎205的吞吐量。
24.在一些实施例中,矩阵计算引擎205包括一个或更多个累加器(例如,实现为寄存器),例如,累加每个向量单元的结果。在一些实施例中,累加器适当地作为向量单元的一部分或者作为矩阵计算引擎205的一部分而被包括。累加器也可以与矩阵计算引擎205分离,但是通信地连接到矩阵计算引擎205。在一些实施例中,累加器是向量累加器。例如,可以基于矩阵计算引擎205的输出向量的大小来确定累加器的大小。累加器还可以用于存储和添加跨多次迭代的单个元素结果。在各种实施例中,一旦矩阵处理完成,累加器结果就经由总线251被推送到存储器。
25.图3是示出使用矩阵转置组件和低位宽矩阵处理组件对数字组求和的系统的实施例的框图。在各种实施例中,系统300是专用集成电路(asic)设备或asic设备的一部分。在所示的示例中,系统300包括矩阵转置组件304、矩阵处理组件306、数据对齐组件308和数据缩减组件310。
26.在所示的示例中,系统300接收输入a 302。在一些实施例中,输入a302是将要求和的整数矩阵,其中与矩阵处理组件306被配置为本地处理的整数相比,这些整数具有更高的
位宽。例如,输入a 302可以是32比特整数(例如,int32格式)的矩阵,而矩阵处理组件306被配置为本地处理8比特整数(例如,int8格式)。在各种实施例中,使用包括转置输入a 302和执行矩阵乘法的技术来对存储在输入a 302中的一组高位宽的值(例如,32比特整数的矩阵或其一部分)进行求和。
27.在所示的示例中,矩阵转置组件304接收输入a 302。在各种实施例中,矩阵转置组件304将接收的数据表示为与矩阵处理组件306相同的低位宽格式的元素。例如,矩阵转置组件304可以接收32比特整数数据,并将每个32比特整数表示为四个8比特整数组成部分(component)。参考图4a,图4a的矩阵402是可以由矩阵转置组件304接收的整数矩阵的示例。在一些实施例中,矩阵402包括32比特整数,其至少一部分由矩阵转置组件304接收并以8比特组块(chunk)的方式存储,如图4a的布局404所示。在示出矩阵402中所示值的存储的布局404中,矩阵402中示出的每个值被存储为跨越四个元素的分割段。矩阵402的每个值都是32比特整数,这意味着它在布局404中被存储为四个8比特整数。例如,矩阵402中的第一值a
00
被存储为元素a
00,3
、a
00,2
、a
00,1
和a
00,0
,分别对应于值a
00
的最高有效8比特、第二最高有效8比特、第二最低有效8比特和最低有效8比特。矩阵402中所示的其他32比特值也分别表示为四个8比特元素。
28.在布局404的示例中,矩阵402的每个值的分割段占据同一行。相似的比特位置组(最高有效8比特、第二最高有效8比特、第二最低有效8比特或最低有效8比特的组)占据同一列。例如,代表a
00
的a
00,3
、a
00,2
、a
00,1
和a
00,0
存储在布局404的第一行,分别代表值a
00
、a
10
、a
20
和a
30
的最高有效8比特的a
00,3
、a
10,3
、a
20,3
和a
30,3
存储在布局404的第一列。如下面进一步详细描述的,出于比特移位的目的,在同一行而不是同一列中存储相似的比特位置组在计算上是有益的。为了在同一行而不是同一列中存储相似的比特位置组,在各种实施例中,使用矩阵转置组件304对布局404进行矩阵转置。在矩阵转置之后,图4a的布局404中所示的元素具有图4b的布局406中所示的排列。如布局406所示,布局404的每个元素的行和列位置已经被交换。例如,布局404的行1、列4中的a
00,0
位于布局406的行4、列1中。此外,布局406的每行存储一种类型的比特位置元素,最高有效8比特元素(下标3)、第二最高有效8比特元素(下标2)、第二最低有效8比特元素(下标1)或最低有效8比特元素(下标0)。可以使用本领域技术人员已知的各种技术在硬件(例如,asic实现方式)中实现矩阵转置组件304。例如,布置在布局404中的元素可以被传送到缓冲储存器,并如布置在布局406中一样被复制回来。换句话说,输入a 302的内容可以以不同的顺序复制到存储器中。在一些实施例中,原位矩阵转置(in
‑
place matrix transposition)技术用于节省存储器空间使用。
29.在各种实施例中,矩阵转置组件304的输出是输入a 302的矩阵转置版本,并且由矩阵处理组件306接收。如上所述,图4b的布局406示出了示例转置的矩阵部分。图4b的布局406是图4a的布局404的转置。在各种实施例中,矩阵处理组件306将转置的矩阵部分乘以8比特格式的相同大小的一的矩阵(matrix of ones),以确定转置的矩阵部分中的值的总和。在一些实施例中,矩阵处理组件306是图1的处理元件101、111或121或者图2的处理元件201。图1的矩阵计算引擎115或图2的矩阵计算引擎205可以执行实际的矩阵乘法。在一些实施例中,矩阵乘法被实现为多个点积,其中执行转置的矩阵部分的每行与一的向量之间的点积运算。可以将一的向量广播到转置的矩阵部分的每一行。图4c示出了这种矩阵乘法的一个示例。图4c的矩阵部分408示出了图4b的布局406的转置的矩阵部分的前八行。矩阵部
分408的每一行被发送到点积处理组件(图4c的多个点积处理组件410中的一个),以通过计算该行和相同大小的一的向量之间的点积来求和。在一些实施例中,多个点积处理组件410中的每个点积处理组件是图2的矩阵计算引擎205的向量单元211、221、231或241。例如,可以通过如下操作来对矩阵部分408的一行进行求和:使用图2的向量乘法单元213将该行与一的向量相乘,并使用图2的向量加法器单元215将所得输出向量中的元素求和为标量。在各种实施例中,矩阵部分408中的元素是8比特整数,并且点积处理组件被配置为本地处理8比特整数。
30.在各种实施例中,矩阵处理组件306的输出是被发送到数据对齐组件308的向量。在一些实施例中,数据对齐组件308包括多个比特移位器。在各种实施例中,这些比特移位器对由数据对齐组件308接收的向量中的元素执行指定的向左比特移位。由数据对齐组件308接收的向量中的每个值是一行8比特元素的总和。例如,数据对齐组件308可以接收图4c的多个点积处理组件410的输出。如图4c的矩阵部分408所示,被求和的每一行都具有比特位置相似的元素。例如,矩阵部分408中的第一行具有全部是最高有效8比特元素的元素。这些元素的总和需要向左比特移位24比特,以考虑元素的最高有效比特在相应的32比特整数值中的位置(该最高有效比特是这些32比特整数值的组成部分)。矩阵部分408中的第二行具有全部是第二最高有效8比特元素的元素,这意味着这些元素的总和需要向左比特移位16比特。出于类似的原因,矩阵部分408中的第三行的总和需要向左比特移位8比特,矩阵部分408中的第四行的总和不需要比特移位(0比特的比特移位),矩阵部分408中的第五行的总和需要向左比特移位24比特,以此类推。在图4c所示的示例中,多个比特移位器412接收行总和并执行图4c所示的比特移位。
31.在各种实施例中,数据对齐组件308的输出是数据对齐元素的向量。例如,在一些实施例中,向量包括多个点积处理组件的比特移位输出,如图4c所示。在各种实施例中,比特移位输出的向量被发送到数据缩减组件310。在一些实施例中,数据缩减组件310是加法器,其对数据对齐组件308的向量输出的比特移位元素求和,以确定系统300接收的一组值(例如,在输入a 302中包括的值)的和。加法器可以实现为加法器树。在一些实施例中,加法器树包括多个二进制加法器、至少一个寄存器和数据路由路径。图4c的加法器414是从点积处理组件接收比特移位输出的加法器的示例。
32.在图3中示出的示例中,示出了组件之间的部分通信路径。可能存在其他通信路径,并且图3的示例已被简化以清楚地示出该示例。例如,图3中没有明确示出控制信号和控制逻辑。此外,存储元件和存储器未示出。尽管为了简化图表,只示出了组件的单一实例,但是图3中示出的任何组件的附加实例都可能存在。图3中所示的组件和连接的数量仅仅是说明性的。图3中未示出的组件也可能存在。
33.本文描述的示例仅仅是说明性的。还可以将本文描述的技术应用于不同位宽和/或不同格式的数字矩阵的求和。例如,对本领域技术人员来说容易明显的是,将本文描述的技术应用于64比特整数的矩阵求和可以包括对八个8比特的组块而不是四个8比特的组块执行处理。也可以容纳不同的矩阵处理组件。例如,使用被配置为本地处理16比特整数的矩阵处理组件对64比特整数的矩阵求和可以包括对四个16比特的组块执行处理。
34.图4a
‑
图4c是示出与使用矩阵转置组件和低位宽矩阵处理组件对数字组求和相关联的数据处理的示意图。在上面与图3相关的描述中提供了图4a
‑
图4c的进一步描述。
35.图5是示出使用矩阵转置组件和低位宽矩阵处理组件对数字组求和的过程的实施例的流程图。在一些实施例中,图5的过程由图3的系统300执行。
36.在501,元素的输入矩阵被转置。在一些实施例中,矩阵转置由图3的矩阵转置组件304执行。在各种实施例中,使用第一数量的比特(例如,8比特)来表示元素的输入矩阵的每个元素,该第一数量的比特少于用于表示存储在输入矩阵中的值的比特数量(例如,32比特)。换句话说,在一些实施例中,输入矩阵存储跨多个较低位宽段分割的较高位宽元素(例如,32比特数字)(例如,存储为四个8比特组成部分的32比特数字)。将较高位宽的数字存储为跨越输入矩阵的元素中的多于一个的元素的分割段的优点在于,较低位宽的矩阵处理组件可用于对32比特数字求和。这在允许使用较低位宽的硬件来处理较高位宽的数字方面提供了灵活性。在各种实施例中,对元素的输入矩阵执行矩阵转置,以将元素排列成适于由矩阵处理组件进行有效处理的布局。
37.在503,第一乘法输入矩阵与第二乘法输入矩阵相乘。在一些实施例中,乘法由图3的矩阵处理组件306执行。在各种实施例中,元素的转置输入矩阵被用作第一乘法输入矩阵。在一些实施例中,掩码向量被用作第二乘法输入矩阵。例如,掩码向量可以是与转置输入矩阵的每行宽度相同的向量,并且其元素都具有值一。在一些实施例中,掩码向量被广播到转置输入矩阵的所有行,并且在转置输入矩阵的每行和掩码向量之间形成点积,得出向量积,其中每个元素是元素的转置输入矩阵的相应行的元素的总和(由于矩阵的行和一的向量之间的点积得到的总和导致矩阵中的行的总和)。在一些实施例中,矩阵处理组件的多个实例(例如,图3的矩阵处理组件306的多个实例)被用于并行处理。例如,32比特整数的32
×
32矩阵可以被转置(例如,通过图3的矩阵转置组件304),并且得出的数据可以被分割并发送到多个(例如,两个、四个等)独立的矩阵处理组件。
38.在505,结果矩阵的元素的至少一部分被修改。在一些实施例中,修改由图3的数据对齐组件308执行。在一些实施例中,结果矩阵是由转置输入矩阵的每一行和广播的一的向量之间的点积得出的向量积。在一些实施例中,向量积中的至少一些元素被比特移位(一些元素可能不需要比特移位)。在各种实施例中,元素根据它们相对于较高位宽数字的比特位置而被比特移位。例如,32比特数字的8个最高有效比特部分的总和可以向左比特移位24比特,接下来的8个最高有效比特部分的总和可以向左比特移位16比特,倒数第二8个最低有效比特部分的总和可以向左比特移位8比特,并且8个最低有效比特部分的总和可以比特移位0比特(无比特移位)。
39.在507,至少将修改后的结果矩阵的元素求和。在一些实施例中,求和由图3的数据缩减组件310执行。在一些实施例中,修改后的结果矩阵是由转置输入矩阵的每行和广播的一的向量之间的点积得出的向量积的比特移位版本。在各种实施例中,修改后的结果矩阵的元素之和是存储在元素输入矩阵中的值之和。
40.尽管为了清楚理解的目的已经详细描述了前述实施例,但是本发明不限于所提供的细节。有许多实现本发明的替代方式。所公开的实施例是说明性的,而不是限制性的。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。