1.本发明涉及人工智能技术领域,尤其涉及一种客运站环境温度预测方法及装置。
背景技术:
2.智能高铁已成为目前铁路运输领域的发展方向,推进智能车站的建设是构建智能高铁的重要组成部分。客运站作为城市间重要的桥梁,智能化体验、舒适旅行也成为了人们所追求的目标。某些大型客运站人流进出量大,容易出现人流密集、拥挤的情况,而其内部的空气环境直接影响着旅客舒适度的体验,尤其是温度成为了环境指数中重要的物理量。站内风水系统的调节直接受环境温度影响,随着环境温度高低的变化,风水系统可提前调节为合适的大小,从而可达到最佳的旅客感知体验。
3.车站环境温度值有两个特点,一是一种时间序列,即数据会随时间发展而展现出一种规律性,受季节与白天黑夜的影响呈现一种周期性波动;二是规律之中又有其特殊性,如会受湿度值、pm2.5、co2等环境因素的影响而发生波动,对于车站人员密集场所,这些因素的影响会更大。然而,现有技术缺乏对车站环境温度的整体预测感知能力,并且一些现有算法并不适用于进行车站环境温度值预测,即不能针对车站环境温度值的特点进行有效预测,预测结果缺乏参考意义,这并不利于推进智能车站的建设。
技术实现要素:
4.针对现有技术中存在的问题,本发明实施例提供一种客运站环境温度预测方法及装置。
5.第一方面,本发明实施例提供一种客运站环境温度预测方法,包括:
6.接收与当前时间对应的采集数据;其中,所述采集数据为环境传感器采集的湿度值、二氧化碳值、pm2.5值、以及pm10值;
7.将当前时间对应的湿度值、二氧化碳值、pm2.5值、以及pm10值中的一项或多项数值作为输入数据输入至预设的第一lstm模型进行预测,得到环境特征变量预测结果;其中,所述环境特征变量预测结果为与所述输入数据对应的预测结果;与所述输入数据对应的预测结果包括:预设未来时间的湿度值,和/或,二氧化碳值,和/或,pm2.5值,和/或,pm10值;所述预设的第一lstm模型为采用湿度值、二氧化碳值、pm2.5值、以及pm10值中的一项或多项样本数值作为输入数据,以及,与所述样本数值对应的环境特征变量预测结果作为输出数据,基于机器学习算法训练得到的;
8.将所述环境特征变量预测结果输入至预设的lightgbm模型,得到相应的温度预测值;其中,所述预设的lightgbm模型为采用环境特征变量预测结果样本数值作为输入数据,以及,与所述样本数值对应的温度预测值作为输出数据,基于机器学习算法训练得到的。
9.进一步地,所述预设的第一lstm模型为采用湿度值、二氧化碳值、pm2.5值、以及pm10值中的一项或多项样本数值作为输入数据,以及,与所述样本数值对应的环境特征变量预测结果作为输出数据,基于机器学习算法训练得到的,包括:
10.将所述样本数值整理成长短期记忆神经网络lstm需要的三维结构(trainx,seqlen,dim_in);其中,第一维度trainx表示对应的所述样本数值,第二维度seqlen表示所述样本数值所采集的序列数据,第三维度dim_in表示所述样本数值对应的特征维度;
11.基于所述三维结构(trainx,seqlen,dim_in)将所述样本数值划分训练集和测试集,然后基于机器学习算法训练。
12.进一步地,还包括:
13.获取与所述当前时间对应的未来预设时间段内环境传感器采集的温度值集合;
14.基于所述温度值集合采用均方根误差公式对所述预设的lightgbm模型输出的与所述样本数值对应的温度预测值进行校对优化。
15.进一步地,还包括:
16.将当前时间对应的湿度值、二氧化碳值、pm2.5值、以及pm10值中的一项或多项数值作为输入数据输入至预设的第二lstm模型进行预测,得到与所述输入数据对应的温度预测值;其中,所述预设的第二lstm模型为采用湿度值、二氧化碳值、pm2.5值、以及pm10值中的一项或多项样本数值作为输入数据,以及,与所述样本数值对应的温度预测值作为输出数据,基于机器学习算法训练得到的。
17.进一步地,还包括:
18.基于所述预设的lightgbm模型输出的温度预测值,和所述预设的第二lstm模型输出的温度预测值进行对比分析,确定温度预测值结果。
19.第二方面,本发明实施例提供了一种客运站环境温度预测装置,包括:
20.接收模块,用于接收与当前时间对应的采集数据;其中,所述采集数据为环境传感器采集的湿度值、二氧化碳值、pm2.5值、以及pm10值;
21.环境特征变量预测模块,用于将当前时间对应的湿度值、二氧化碳值、pm2.5值、以及pm10值中的一项或多项数值作为输入数据输入至预设的第一lstm模型进行预测,得到环境特征变量预测结果;其中,所述环境特征变量预测结果为与所述输入数据对应的预测结果;与所述输入数据对应的预测结果包括:预设未来时间的湿度值,和/或,二氧化碳值,和/或,pm2.5值,和/或,pm10值;所述预设的第一lstm模型为采用湿度值、二氧化碳值、pm2.5值、以及pm10值中的一项或多项样本数值作为输入数据,以及,与所述样本数值对应的环境特征变量预测结果作为输出数据,基于机器学习算法训练得到的;
22.温度值预测模块,用于将所述环境特征变量预测结果输入至预设的lightgbm模型,得到相应的温度预测值;其中,所述预设的lightgbm模型为采用环境特征变量预测结果样本数值作为输入数据,以及,与所述样本数值对应的温度预测值作为输出数据,基于机器学习算法训练得到的。
23.第三方面,本发明实施例还提供了一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上第一方面所述的客运站环境温度预测方法的步骤。
24.第四方面,本发明实施例还提供了一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如上第一方面所述的客运站环境温度预测方法的步骤。
25.由上述技术方案可知,本发明实施例提供的客运站环境温度预测方法及装置,通
过接收与当前时间对应的采集数据;基于所述采集数据采用预设的第一lstm模型进行预测,得到环境特征变量预测结果;基于所述环境特征变量预测结果采用预设的lightgbm模型,得到相应的温度预测值。本发明利用lstm模型和lightgbm模型进行未来时间的温度值预测,能够减少温度预测值与未来温度真实值的误差,从而提高了未来温度值的预测准确率,进而辅助客运站工作人员进行提前决策,如提前设定合适的空调温度值与通风量大小,达到节能减排的目的。
附图说明
26.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
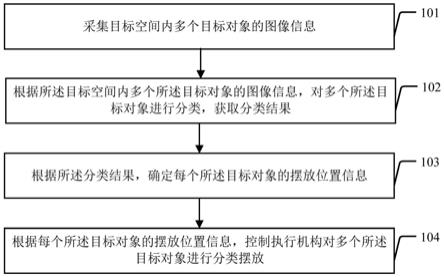
27.图1为本发明一实施例提供的客运站环境温度预测方法的流程示意图;
28.图2为本发明一实施例提供的lstm模型的算法结构图;
29.图3为本发明另一实施例提供的客运站环境温度预测方法的流程示意图;
30.图4为本发明一实施例提供的lstm模型的环境特征变量预测结果示意图;
31.图5为本发明一实施例提供的客运站环境温度预测方法的预测结果对比示意图;
32.图6本发明一实施例提供的客运站环境温度预测方法中环境特征变量重要性比对折线图;
33.图7为本发明一实施例提供的客运站环境温度预测装置的结构示意图;
34.图8为本发明一实施例提供的电子设备的实体结构示意图。
具体实施方式
35.为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。下面将通过具体的实施例对本发明提供的客运站环境温度预测方法进行详细解释和说明。
36.图1为本发明一实施例提供的客运站环境温度预测方法的流程示意图;如图1所示,该方法包括:
37.步骤101:接收与当前时间对应的采集数据;其中,所述采集数据为环境传感器采集的湿度值、二氧化碳值、pm2.5值、以及pm10值。
38.步骤102:将当前时间对应的湿度值、二氧化碳值、pm2.5值、以及pm10值中的一项或多项数值作为输入数据输入至预设的第一lstm模型进行预测,得到环境特征变量预测结果;其中,所述环境特征变量预测结果为与所述输入数据对应的预测结果;与所述输入数据对应的预测结果包括:预设未来时间的湿度值,和/或,二氧化碳值,和/或,pm2.5值,和/或,pm10值;所述预设的第一lstm模型为采用湿度值、二氧化碳值、pm2.5值、以及pm10值中的一项或多项样本数值作为输入数据,以及,与所述样本数值对应的环境特征变量预测结果作为输出数据,基于机器学习算法训练得到的。
39.步骤103:将所述环境特征变量预测结果输入至预设的lightgbm模型,得到相应的温度预测值;其中,所述预设的lightgbm模型为采用环境特征变量预测结果样本数值作为输入数据,以及,与所述样本数值对应的温度预测值作为输出数据,基于机器学习算法训练得到的。
40.在本实施例中,举例来说,针对预设的第一lstm模型和预设的lightgbm模型,在训练前获取用于训练的样本数据,如利用环境传感器采集温度、湿度、二氧化碳、pm2.5、pm10值,采样时间为48小时,每5分钟采样一次,并将采样数据导入第一lstm模型和预设的lightgbm模型。
41.优选的,对传感器数据:湿度、二氧化碳、pm2.5、pm10做标准化预处理,从而将标准化处理后的传感器数据输入lstm模型进行样本训练,得到预设的第一lstm模型;对传感器数据:湿度、二氧化碳、pm2.5、pm10做归一化处理输入lightgbm模型得到预设的lightgbm模型。其中,标准化预处理对应的公式为下述式一:x为原始数据,x
mean
为原始数据的均值,x
std
为原始数据的方差;归一化处理对应的公式为下述式二:x
max
为样本数据的最大值,x
min
为样本数据的最小值:
[0042][0043][0044]
在本实施例中,针对lstm模型,需要说明的是,lstm(long short
‑
term memory)是一种rnn特殊的类型,rnn会存在梯度消失和梯度爆炸的问题,lstm通过cell门开关实现时间上的记忆功能,并防止梯度消失,可以学习长期依赖信息,让信息长期保存,可解决rnn的缺陷问题,其算法结构如图2所示。lstm的当前输入x
t
和上一个状态传递下来的h
t
‑1拼接训练可以得到四个状态,所得状态公式如下:
[0045][0046][0047][0048][0049]
式中,(4)、(5)、(6)中z
i
,z
f
,z
o
是由拼接向量乘以权重矩阵之后,再通过一个sigmoid激活函数转换成0到1之间的数值,来作为一种门控状态。公式(3)中z是将结果通过一个tanh激活函数转换成
‑
1到1之间的值(使用tanh是因为将其做为输入数据,而不是门控信号)。
⊙
是操作矩阵中对应的元素相乘,要求两个相乘矩阵是同型的。代表矩阵加法。c
t
、h
t
、y
t
计算公式如下:
[0050]
c
t
=z
f
⊙
c
t
‑1 z
i
⊙
z
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0051]
h
t
=z
o
⊙
tanh(c
t
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
[0052]
y
t
=σ(w
f
h
t
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(9)
[0053]
lstm模型计算过程主要分为三个阶段:忘记阶段、输入阶段、输出阶段。忘记阶段
即“忘记”之前没用的信息。遗忘门会根据当前时刻节点的输入x
t
、上一时刻节点的状态c
t
‑1和上一时刻节点的输出h
t
‑1来决定哪些信息将被遗忘。输入阶段决定当前输入数据哪些信息被留下来。主要对输入x
t
进行选择记忆。当前输入内容由公式(3)z得出,选择门控信号由z
i
来进行控制。由公式(3)、(4)、(5)可得到传输给下一个状态的c
t
,即公式(7)。输出阶段确定输出值。lstm在得到最新节点状态c
t
后,结合上一时刻节点输出h
t
‑1和当前时刻节点的输入x
t
来决定当前时刻节点的输出y
t
,通过公式(8)的h
t
变化得到公式(9)。其中公式(8)中z
o
来进行控制,并对状态c
t
进行了缩放(通过tanh激活函数进行变化)。
[0054]
在本实施例中,针对lightgbm模型,需要说明的是,lightgbm(light gradient boosting machine)是由微软亚洲研究院分布式机器学习工具包(dmtk)团队开源的基于决策树算法的分布式梯度提升gbdt(gradient boosting decision tree)框架。gbdt是机器学习中非常流行且有效的算法模型,它是基于决策树的梯度提升算法。lightgbm具有训练速度快、内存占用少、准确率高、支持并行化学习、可处理大规模数据的特点。lightgbm在梯度算法中主要采用了一些优化算法:
[0055]
单边梯度采样算法(goss):lightgbm使用goss算法进行训练样本采样的优化。goss算法的基本思想是首先对训练集数据根据梯度排序,预设一个比例,保留在所有样本中梯度高于比例的数据样本;梯度低于该比例的数据样本不会直接丢弃,而是设置一个采样比例,从梯度较小的样本中按比例抽取样本。为了弥补对样本分布造成的影响,goss算法在计算信息增益时,会对较小梯度的数据集乘以一个系数用来放大。在计算信息增益时,算法可以更加关注“未被充分训练”的样本数据。
[0056]
efb(exclusive feature bundling)算法:lightgbm算法不仅通过goss算法对训练样本进行采样优化,也进行了特征抽取,以进一步优化模型的训练速度。efb算法可以将数据集中互斥的特征绑定在一起,形成低维的特征集合,能够有效避免对0值特征的计算。在算法中,可以对每个特征建立一个记录非零值特征的表格。通过对表中数据的扫描,可以有效降低创建直方图的时间复杂度。
[0057]
直方图算法:lightgbm采用了基于直方图的算法,将连续的特征值离散化成了k个整数,构造宽度为k的直方图,遍历训练数据,统计每个离散值在直方图中的累积统计量。在选取特征的分裂点时,只需要遍历排序直方图的离散值。使用直方图算法降低了算法的计算代价,同时降低了算法的内存消耗。
[0058]
按叶子生长算法:大多数决策树学习算法的树生成方式都采用按层生长的策略,lightgbm则采用一种更为高效的按叶子生长策略算法。该策略每次从当前决策树所有的叶子节点中,找到分裂增益最大的一个叶子节点进行分裂,如此循环往复。该机制减少了对增益较低的叶子节点的分裂计算。与按层策略相比,在分裂次数相同的情况下,按叶子生长算法可以降低误差,得到更好的精度。按叶子生长算法的缺点是可能会生成较深的决策树。因此,lightgbm模型在按叶子生长上增加了限制最大深度的参数,在保证算法高效的同时,防止过拟合。
[0059]
在本实施例中,需要说明的是,如将归一化的数据集划分为训练集和验证集,设置训练集和验证集比例系数。
[0060]
构建lightgbm模型,核心参数包括:
[0061]
objective:任务类型。可选任务类型为regression(回归)、binary(二分类)、
multiclass(多分类)等。
[0062]
num_leaves:叶节点的数目。该参数决定树模型的复杂度,越大会越准确,但可能过拟合。
[0063]
max_depth:控制了树的最大深度。该参数可以显式的限制树的深度。一般设置为不大于log2(num_leaves)的值。
[0064]
min_data_in_leaf:每个叶节点的最少样本数量。它是处理leaf
‑
wise树的过拟合的重要参数。将它设为较大的值,可以避免生成一个过深的树,但是也可能导致欠拟合。
[0065]
learning_rate:训练模型的学习率。较大的学习率会加快收敛速度,但是会降低准确率,默认为0.1。针对数据集的大小可调整学习率。
[0066]
num_boost_round:迭代次数。
[0067]
在本实施例中,运用组合模型(长短期记忆神经网络和梯度提升算法)对客运站内,未来时间对应的环境传感器温度值进行预测,有利于推进智能车站的建设,即帮助车站工作人员预知未来温度,提供辅助决策,如根据组合模型(即预设的第一lstm模型和预设的lightgbm模型对应的组合模型)的预测结果(温度预测值),提前设定合适的空调温度值与通风量大小,为节能减排提供有效手段。
[0068]
由上面技术方案可知,本发明实施例提供的客运站环境温度预测方法,通过接收与当前时间对应的采集数据;基于所述采集数据采用预设的第一lstm模型进行预测,得到环境特征变量预测结果;基于所述环境特征变量预测结果采用预设的lightgbm模型,得到相应的温度预测值。本发明实施例利用lstm模型和lightgbm模型进行未来时间的温度值预测,能够减少温度预测值与未来温度真实值的误差,从而提高了未来温度值的预测准确率,进而辅助客运站工作人员进行提前决策,如提前设定合适的空调温度值与通风量大小,达到节能减排的目的。
[0069]
在上述实施例的基础上,在本实施例中,所述预设的第一lstm模型为采用湿度值、二氧化碳值、pm2.5值、以及pm10值中的一项或多项样本数值作为输入数据,以及,与所述样本数值对应的环境特征变量预测结果作为输出数据,基于机器学习算法训练得到的,包括:
[0070]
将所述样本数值整理成长短期记忆神经网络lstm需要的三维结构(trainx,seqlen,dim_in);其中,第一维度trainx表示对应的所述样本数值,第二维度seqlen表示所述样本数值所采集的序列数据,第三维度dim_in表示所述样本数值对应的特征维度;
[0071]
基于所述三维结构(trainx,seqlen,dim_in)将所述样本数值划分训练集和测试集,然后基于机器学习算法训练。
[0072]
在本实施例中,需要说明的是,将样本数据整理成长短期记忆神经网络lstm需要的三维结构(trainx,seqlen,dim_in)第一个维度trainx表示对应样本,第二个维度seqlen表示该样本所采集的序列数据(指定序列长度),第三个维度dim_in表示对应的特征维度。按照此三维结构形式将数据集划分为训练集和测试集。
[0073]
构建lstm模型:模型结构表示为(units,input_shape,activation,recurrent_dropout)。units为隐含层神经元个数,input_shape为输入数据集的结构形式,activation为激活函数,recurrent_dropout为学习率。分析数据集样本大小和特点,得到最佳模型取值。
[0074]
训练lstm模型:训练模型结构为(x_train,y_train,epochs,batch_size,
validation_split)。x_train,y_train为模型训练数据;epochs为迭代次数;batch_size为批处理样本数;validation_split为训练验证集分割比例。
[0075]
在上述实施例的基础上,在本实施例中,还包括:
[0076]
获取与所述当前时间对应的未来预设时间段内环境传感器采集的温度值集合;
[0077]
基于所述温度值集合采用均方根误差公式对所述预设的lightgbm模型输出的与所述样本数值对应的温度预测值进行校对优化。
[0078]
在本实施例中,需要说明的是,误差标准采用均方根误差公式(rmse计算公式如下):
[0079][0080]
其中,y
i
为所采集的每个数据,为预测值,m为样本数。
[0081]
在上述实施例的基础上,在本实施例中,还包括:
[0082]
将当前时间对应的湿度值、二氧化碳值、pm2.5值、以及pm10值中的一项或多项数值作为输入数据输入至预设的第二lstm模型进行预测,得到与所述输入数据对应的温度预测值;其中,所述预设的第二lstm模型为采用湿度值、二氧化碳值、pm2.5值、以及pm10值中的一项或多项样本数值作为输入数据,以及,与所述样本数值对应的温度预测值作为输出数据,基于机器学习算法训练得到的。
[0083]
在本实施例中,可以理解的是,训练一种lstm模型(即预设的第二lstm模型),利用所述预设的第二lstm模型也可以进行未来温度值预测(即温度预测值)。
[0084]
在上述实施例的基础上,在本实施例中,还包括:
[0085]
基于所述预设的lightgbm模型输出的温度预测值,和所述预设的第二lstm模型输出的温度预测值进行对比分析,确定温度预测值结果。
[0086]
在本实施例中,基于组合模型的输出结果(即基于所述采集数据采用预设的第一lstm模型进行预测,得到环境特征变量预测结果;基于所述环境特征变量预测结果采用预设的lightgbm模型,得到相应的温度预测值),和预设的第二lstm模型的输出结果进行结果分析:采用rmse与波形观察法对第二lstm模型输出的温度预测结果、组合模型输出的温度预测结果进行对比分析,得出最佳预测结果。采用lightgbm输入变量重要性判别函数对环境特征变量重要性做对比,得出影响温度预测结果最大的环境特征变量。
[0087]
为了更好的理解本发明,下面结合实施例进一步阐述本发明的内容,但本发明不仅仅局限于下面的实施例。
[0088]
本发明实施例利用lstm与lightgbm的组合模型对温度进行预测,流程图见图3,其中环境特征变量为湿度、二氧化碳、pm2.5、pm10,环境传感器数据除上述4种环境特征变量外还包含温度值。
[0089]
本实施例数据来源为某车站环境传感器获取的两日内145条数据,包含温度、湿度、二氧化碳、pm2.5、pm10数据。本实施例先利用正规化方法标准化处理数据,采用公式为x为原始数据,x
mean
为原始数据的均值,x
std
为原始数据的方差。该公式结果用
于lstm模型。再归一化方法标准化处理,公式为其中x
max
为样本数据的最大值,x
min
为样本数据的最小值,该公式所得结果用于训练lightgbm模型。
[0090]
1)构造lstm训练模型
[0091]
首先将输入数据整理成lstm所需的三维结构,表示为(trainx,seqlen,dim_in)第一个维度trainx表示对应样本,第二个维度seqlen表示该样本所采集的序列数据(指定序列长度),第三个维度dim_in表示对应的特征维度,本实施例数据集环境特征变量为4个,因此dim_in取4。按照此三维结构形式将数据集划分为训练集和测试集。第二,构建lstm模型。模型结构表示为(units,input_shape,activation,recurrent_dropout)。units为隐含层神经元个数,input_shape为输入数据集的结构形式,activation为激活函数,recurrent_dropout为学习率。分析数据集样本大小和特点,得到最佳模型取值。本实施例units取45,activation取“relu”,recurrent_dropout为0.01。第三,训练lstm模型。训练模型结构为(x_train,y_train,epochs,batch_size,validation_split)。x_train,y_train为模型训练数据;epochs为迭代次数;batch_size为批处理样本数;validation_split为训练验证集分割比例。训练模型参数的取值是基于先验知识与大量实验得出,本实施例epochs取值为100,batch_size为16,validation_split为0.8。
[0092]
2)构造lightgbm训练模型
[0093]
将数据集划分为训练集和验证集,设置训练集和验证集比例系数为0.8。模型的参数设置是基于先验知识以及大量的实验,针对所用实验数据,lightgbm训练模型的核心参数设置如下:
[0094]
objective:任务类型。可选任务类型为regression(回归)、binary(二分类)、multiclass(多分类)等。本实施例任务是进行预测,设置为regression。
[0095]
num_leaves:叶节点的数目。该参数决定树模型的复杂度,越大会越准确,但可能过拟合,该参数设置为120。
[0096]
max_depth:控制了树的最大深度。该参数可以显式的限制树的深度。一般设置为不大于log2(num_leaves)的值,本实施例设置为7。
[0097]
min_data_in_leaf:每个叶节点的最少样本数量。它是处理leaf
‑
wise树的过拟合的重要参数。将它设为较大的值,可以避免生成一个过深的树,但是也可能导致欠拟合。本发明实施例设置为16。
[0098]
learning_rate:训练模型的学习率。较大的学习率会加快收敛速度,但是会降低准确率,默认为0.1。针对数据集的大小可调整学习率,本发明设置为0.05。
[0099]
num_boost_round:迭代次数。设置为1000。
[0100]
3)预测
[0101]
将环境特征变量湿度、二氧化碳、pm2.5、pm10数据输入lstm训练模型,计算出每个环境特征变量的预测值。该多维预测值作为输入变量,输入lightgbm模型,由此得出温度预测值。
[0102]
4)结果评价标准
[0103]
误差标准采用均方根误差(rmse)公式。rmse计算公式如下:其中y
i
为所采集的每
个数据,为预测值,m为样本数。
[0104][0105]
5)结果分析
[0106]
选取环境特征变量24条数据(即2小时)输入lstm模型,所得预测结果如图4,图4中a(humidity,湿度)、b(co2,二氧化碳)、c(pm2.5,大气中空气动力学当量直径小于或等于2.5微米的颗粒物)、d(pm10,大气中空气动力学直径小于或等于10微米的颗粒物)为每个环境特征变量的预测结果,其中实线波形为原始数据,与其对应的带圆点实线波形为预测数据。根据波形图可得出lstm模型对于有突变的尖峰预测灵敏度较差,但是可以将数据的整体上升下降趋势预测出来。表1为环境特征变量预测值与真实值的均方根误差rmse:
[0107] 湿度co2pm2.5pm10rmse9.8111.230.8826.39
[0108]
将lstm模型已预测的湿度、二氧化碳、pm2.5、pm10数据输入lightgbm训练模型,所得温度预测值如图5。其中实线波形为温度的真实值,带圆点虚线为第一lstm和lightgbm组合模型预测的温度值(predict2),带正方形虚线为单独使用lstm模型(即第二lstm模型)预测的温度值(predict1)。两模型预测结果(分别为第一lstm和lightgbm构建的组合模型,与第二lstm模型)rmse分别为0.82和1.35。从波形图可得出lstm
‑
lightgbm组合模型(即第一lstm和lightgbm对应的组合模型)比第二lstm模型结果更接近原始波形,lstm
‑
lightgbm组合模型对波形突变有更好的响应,能反应出环境特征变量所引起的温度变化。
[0109]
本发明实施例利用输入变量重要性判别函数对环境特征变量的重要性做了对比,重要性代表特征值在训练过程中使用的平均次数,结果参见图6。从图中纵坐标值可得出二氧化碳(co2)和pm10对预测结果有较大影响。
[0110]
本发明实施例基于客运火车站重点区域的环境传感器实际数据,采用预测算法对车站温度值进行预测分析。首先利用lstm模型分别对湿度、二氧化碳、pm2.5、pm10四项环境特征变量进行预测。再利用lstm模型预测的四项环境特征变量输入lightgbm模型对温度值进行预测。通过对比单独使用lstm模型与使用lstm
‑
lightgbm组合模型对温度的预测结果,得出lstm
‑
lightgbm组合模型的预测值有更低的rmse,其预测波形趋势更接近原始波形。
[0111]
本实施例研究内容可应用于车站重点区域环境温度的预测,可为工作人员提供辅助决策手段,如通过预测值提前设定站内风水系统的空调温度值与通风量大小,从而提升区域舒适度,减少能耗。
[0112]
图7为本发明一实施例提供的客运站环境温度预测装置的结构示意图,如图7所示,该装置包括:接收模块201、环境特征变量预测模块202和温度值预测模块203,其中:
[0113]
其中,接收模块201,用于接收与当前时间对应的采集数据;其中,所述采集数据为环境传感器采集的湿度值、二氧化碳值、pm2.5值、以及pm10值;
[0114]
环境特征变量预测模块202,用于将当前时间对应的湿度值、二氧化碳值、pm2.5值、以及pm10值中的一项或多项数值作为输入数据输入至预设的第一lstm模型进行预测,得到环境特征变量预测结果;其中,所述环境特征变量预测结果为与所述输入数据对应的
预测结果;与所述输入数据对应的预测结果包括:预设未来时间的湿度值,和/或,二氧化碳值,和/或,pm2.5值,和/或,pm10值;所述预设的第一lstm模型为采用湿度值、二氧化碳值、pm2.5值、以及pm10值中的一项或多项样本数值作为输入数据,以及,与所述样本数值对应的环境特征变量预测结果作为输出数据,基于机器学习算法训练得到的;
[0115]
温度值预测模块203,用于将所述环境特征变量预测结果输入至预设的lightgbm模型,得到相应的温度预测值;其中,所述预设的lightgbm模型为采用环境特征变量预测结果样本数值作为输入数据,以及,与所述样本数值对应的温度预测值作为输出数据,基于机器学习算法训练得到的。
[0116]
本发明实施例提供的客运站环境温度预测装置具体可以用于执行上述实施例的客运站环境温度预测方法,其技术原理和有益效果类似,具体可参见上述实施例,此处不再赘述。
[0117]
基于相同的发明构思,本发明实施例提供一种电子设备,参见图8,电子设备具体包括如下内容:处理器301、通信接口303、存储器302和通信总线304;
[0118]
其中,处理器301、通信接口303、存储器302通过通信总线304完成相互间的通信;通信接口303用于实现各建模软件及智能制造装备模块库等相关设备之间的信息传输;处理器301用于调用存储器302中的计算机程序,处理器执行计算机程序时实现上述各方法实施例所提供的方法,例如,处理器执行计算机程序时实现下述步骤:接收与当前时间对应的采集数据;其中,所述采集数据为环境传感器采集的湿度值、二氧化碳值、pm2.5值、以及pm10值;将当前时间对应的湿度值、二氧化碳值、pm2.5值、以及pm10值中的一项或多项数值作为输入数据输入至预设的第一lstm模型进行预测,得到环境特征变量预测结果;其中,所述环境特征变量预测结果为与所述输入数据对应的预测结果;与所述输入数据对应的预测结果包括:预设未来时间的湿度值,和/或,二氧化碳值,和/或,pm2.5值,和/或,pm10值;所述预设的第一lstm模型为采用湿度值、二氧化碳值、pm2.5值、以及pm10值中的一项或多项样本数值作为输入数据,以及,与所述样本数值对应的环境特征变量预测结果作为输出数据,基于机器学习算法训练得到的;将所述环境特征变量预测结果输入至预设的lightgbm模型,得到相应的温度预测值;其中,所述预设的lightgbm模型为采用环境特征变量预测结果样本数值作为输入数据,以及,与所述样本数值对应的温度预测值作为输出数据,基于机器学习算法训练得到的。
[0119]
基于相同的发明构思,本发明又一实施例还提供一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现以执行上述各方法实施例提供的方法,例如,接收与当前时间对应的采集数据;其中,所述采集数据为环境传感器采集的湿度值、二氧化碳值、pm2.5值、以及pm10值;将当前时间对应的湿度值、二氧化碳值、pm2.5值、以及pm10值中的一项或多项数值作为输入数据输入至预设的第一lstm模型进行预测,得到环境特征变量预测结果;其中,所述环境特征变量预测结果为与所述输入数据对应的预测结果;与所述输入数据对应的预测结果包括:预设未来时间的湿度值,和/或,二氧化碳值,和/或,pm2.5值,和/或,pm10值;所述预设的第一lstm模型为采用湿度值、二氧化碳值、pm2.5值、以及pm10值中的一项或多项样本数值作为输入数据,以及,与所述样本数值对应的环境特征变量预测结果作为输出数据,基于机器学习算法训练得到的;将所述环境特征变量预测结果输入至预设的lightgbm模型,得到相应的温度预测值;其中,所述预设的
lightgbm模型为采用环境特征变量预测结果样本数值作为输入数据,以及,与所述样本数值对应的温度预测值作为输出数据,基于机器学习算法训练得到的。
[0120]
以上所描述的装置实施例仅仅是示意性的,其中作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。本领域普通技术人员在不付出创造性的劳动的情况下,即可以理解并实施。
[0121]
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到各实施方式可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件。基于这样的理解,上述技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在计算机可读存储介质中,如rom/ram、磁碟、光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行各个实施例或者实施例的某些部分的方法。
[0122]
此外,在本发明中,诸如“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。在本发明的描述中,“多个”的含义是至少两个,例如两个,三个等,除非另有明确具体的限定。
[0123]
此外,在本发明中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括要素的过程、方法、物品或者设备中还存在另外的相同要素。
[0124]
此外,在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
[0125]
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。