1.本发明涉及电力系统不同区域的分时电价引导电动物流车队路径规划的调度技术领域,特别是涉及了一种基于强化学习的考虑配送时效性和充电需求的电动物流车队路径规划方法。
背景技术:
2.近年来,随着电动汽车普及率的增高,与其相对应的充电网建设业也发展迅速。与此同时,随着通信技术的发展,以平台为通信载体的绿色物流配送方式更加流行。新型的绿色物流交通系统不仅可以满足客户要求的物流服务质量,还可以使用更加清洁的电力资源,这也迎合了全球追求的碳减排目标。
3.与传统物流方式不同的是,通过平台的在线调度和各区域不同时间内充电价格的引导,电动物流车队不仅可以在需求不确定下保持高订单交付率,还可以实现与电网的良性互动。合理的调度有利于降低车队充电成本,不仅意味着车队收益的增加,还意味着在相同时间内使用更少的电能获得更高的收益,减小充电行为对电网的冲击,同时经过区域调度,也可以有效缓解不同区域间的负荷不平衡现象。
4.中国专利公开号cn108764777a公开了一种带时间窗的电动物流车调度方法和系统,并且基于电动物流车的配送参数建立了混合整数规划模型,在规划需求约束条件和充电约束条件下求解得到配送路径的安排;中国专利公开号cn112541627а公开了一种基于多种群协同进化遗传算法,对电动物流车的路径规划和电动物流车的性能参数优化进行综合迭代处理,从而在协同进化中各自达到优化目标;上述两种方法均局限于电动物流车的路径规划与性能优化问题,忽略了需求的不确定性及其导致的物流车队的充电行为特征,同时也忽略了区域电价对于电动物流车调度的影响。
技术实现要素:
5.为解决上述提到的技术问题,本发明提供了一种基于强化学习的考虑配送时效性和充电需求的电动物流车队路径规划方法。
6.本发明的设计目的通过以下技术方案实施:
7.提供一种基于强化学习的考虑配送时效性和充电需求的电动物流车队路径规划方法,包括以下步骤:
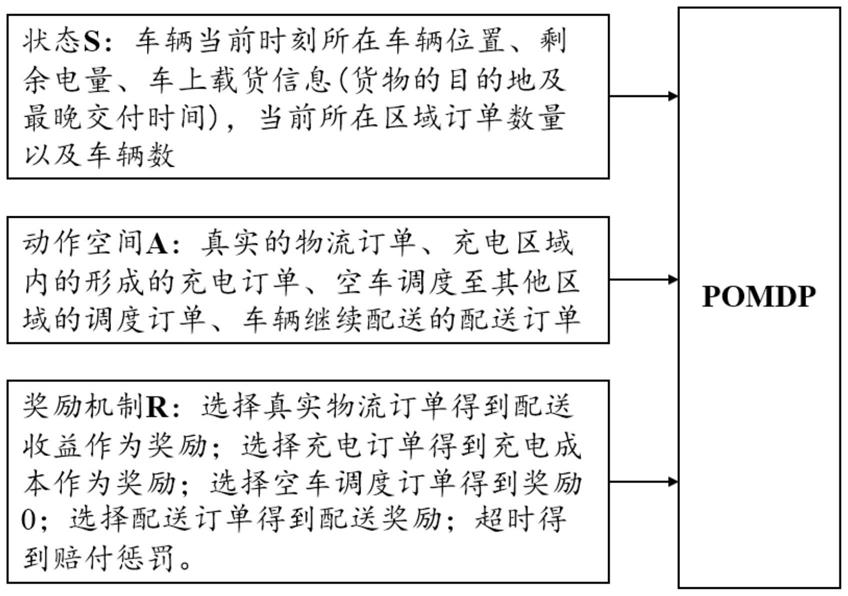
8.s1:设立智能体与交互环境,将派单模式建立成部分可观测的马尔科夫决策过程(partially observable markov decision process,pomdp),基于车辆信息与部分环境信息设定智能体状态s;将电动物流车的每项决策建立成不同的订单类型,把规划与调度问题转化成派单问题,设定动作空间a;根据车辆上的货物配送信息及订单类型来设计奖励机制r。
9.s2:设计平台在同一时间内的派单机制,在同一个时间内,每个区域内智能体根据
状态动作价值表q(s,a)与订单选择的可行表,按照轮次进行选单。车辆首先选出当前一轮内车辆可以选择的所有订单;其次车辆按照最大的状态行为价值选择相应的订单,如果不同车辆选择同一个订单,则由有最高状态行为价值的车辆进行选单;最后未选择订单的车辆进入下一轮选单,订单类别剔除已被选择的订单。
10.s3:根据可行区域建立模型,根据订单信息处理数据,采用神经网络来拟合智能体的状态价值。基于建立的pomdp模型,输入处理后的订单数据,智能体根据状态行为价值以及构建的派单方法选择订单执行,更新智能体与环境的状态。采集需要规划的多个智能体与环境交互的历史信息存入经验回访池,再从中进行采样来训练神经网络。
11.作为进一步改进,以15分钟为时间尺度进行划分,按照订单发起时间归类,按顺序在每个时刻载入相应的订单,对海口市连续20周的订单数据采样进行网络训练集。
12.作为进一步改进,采用两个神经网络分别作为状态价值估计网络与目标网络,每次训练只更新估计网络,再按照一定的更新次数更新目标网络。
13.作为进一步改进,采集智能体与环境的历史交互信息,存储在经验回访池中,通过采样得到训练样本集来训练拟合状态价值的神经网络,消除数据之间的强相关性。
14.本发明提出的一种基于强化学习并且考虑了电动物流车队配送时效性以及充电需求的路径规划方法,取得的技术效果为:
15.本发明基于车辆决策过程建立了不同类型的订单模型,将路径规划问题与充电策略转换成订单调度模式,灵活性更高,基于车辆载货信息(货物地点及最晚交付时间)、车辆剩余电量、区域电价引导、未来需求影响和超时配送风险选择最有利与车队收益最大化的订单类型,通过训练好的神经网络以及派单机制进行决策,在一定的运营时间内车队不仅可以获得最高收益与最低的充电成本,还可以保持较高的订单交付率。
附图说明
16.图1为本发明所提供的将派单环境建立成pomdp模型的流程图。
17.图2为本发明所提供的基于智能体状态行为价值的派单方法流程图。
18.图3为本发明所提供的一种考虑电动物流车队配送时效性以及充电需求的路径规划方法的整体流程图。
具体实施方式
19.下面结合附图,对本发明作详细说明。
20.结合图1所示,本发明所提供的将派单模型建立成pomdp模型的建模方法如下所示:
21.s11:智能体状态s包括车辆当前时刻所在车辆位置(区域编号)、剩余电量、车上载货信息(货物的目的地及最晚交付时间),当前所在区域订单数量以及车辆数;
22.s12:动作空间a包括真实的物流订单、充电区域内的形成的充电订单、空车调度至其他区域的调度订单、车辆继续配送的配送订单;
23.s13:奖励机制r包括选择真实物流订单得到配送收益作为奖励;选择充电订单得到充电成本作为奖励;选择空车调度订单得到奖励0;选择配送订单得到配送奖励;超时交付得到赔付惩罚。
24.结合图2所示,本发明所提供的基于智能体状态行为价值的派单方法如下所示:
25.s21:在某个区域内选出当前一轮内所有智能体可以选择的订单的合集;
26.s22:智能体按照最大的状态行为价值选择相应的订单,如果不同车辆选择同一个订单,则由有最高状态行为价值的车辆进行选单
27.s23:未选择订单的车辆进入下一轮选单,订单类别剔除已被选择的订单。
28.结合图3所示,本发明所提供的一种考虑电动物流车队配送时效性以及充电需求的路径规划方法,包括以下步骤:
29.s31:针对区域内的物流订单数据进行处理,提取物流订单信息(货物体积及重量),将规划区域按照六边形划分可行区域与不可行区域,将订单的起始点与目的地按照规定区域划分整理标号,与其余信息形成输入规划模型的完整数据。同时按照区域划分充电桩类型,确定区域内充电桩数量、充电功率以及充电电价。
30.s32:初始化模型,设立智能体与环境交互。每辆车都作为一个智能体与环境进行交互,得到交互信息(s,a,r,s’),s为当前状态,a为智能体选择的动作,r为智能体选择动作a得到的即时奖励,s’为智能体执行完动作a后达到的下一个状态,将这组信息存进经验回访池中,初始化经验回访池的容量为b;设立两个神经网络分别作为估计网络q(s,a;θ)与目标网络q’(s,a;θ),用于拟合智能体在状态s下状态价值v(s)。
31.s33:环境在每个时刻给出每个区域当前真实的物流订单信息、可用车辆信息、充电站的充电电价以及可用充电桩数量,除了真实的物流订单,各区域将充电选择、空车调度以及配送货物的动作建成订单模型,与真实的物流订单整合,作为动作空间传给智能体,同时各区域将计算出各车辆对于所有订单的可行表,表内元素为0/1,0表示智能体可以选择该订单,1表示智能体不能选择该订单,可行表作为智能体选单依据之一。
32.s34:在时刻t下,电动汽车智能体首先需要根据所处位置判断车上货物是否送达,更新车上货物信息以及车辆的状态;其次是利用环境提供的可行表以及估计网络来拟合状态s下的状态价值v(s),同时计算选择各类订单分别可以得到的奖励r,得到在状态s下选择订单a的状态行为价值q(s,a),整合得到某区域所有智能体对于所有订单的状态行为价值表q(s,a);最后通过派单机制与状态行为价值表q(s,a)确定所有车辆在下一时刻的选择的动作。
33.s35:将智能体与环境交互的信息(s,a,r,s’)存进经验回访池,根据目标网络计算得到目标值targetq=(r γ*q’(s,a)),其中γ为折扣因子;根据损失函数l(θ)=e[(targetq
‑
q(s,a;θ))2]更新估计网络的网络参数;当估计网络参数更新次数达到要求时,更新目标网络的参数。
[0034]
s36:车辆选择真实的物流订单,则要更新环境内的真实物流信息,更新车辆的货物信息;车辆选择充电,则在区域内使用可用充电桩充满电,此时要更新区域内可用电桩的数量;车辆选择继续配送,则按照规划路线选择移动到下一个区域,更新各区域内的车辆信息及数量;车辆选择调度,则移动到选择调度的区域,更新各区域内的车辆信息及数量。执行完订单,环境继续载入下一时刻的物流订单,再将信息传递给智能体。
[0035]
以上对本发明实施例所提供的一种基于强化学习并且考虑了电动物流车队配送时效性和充电需求的路径规划方法进行了详细介绍,本文中利用具体实例对本发明的原理进行了介绍,用于阐述本发明的核心思想,不能将本说明书内容理解为对本发明保护范围
的限制。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

