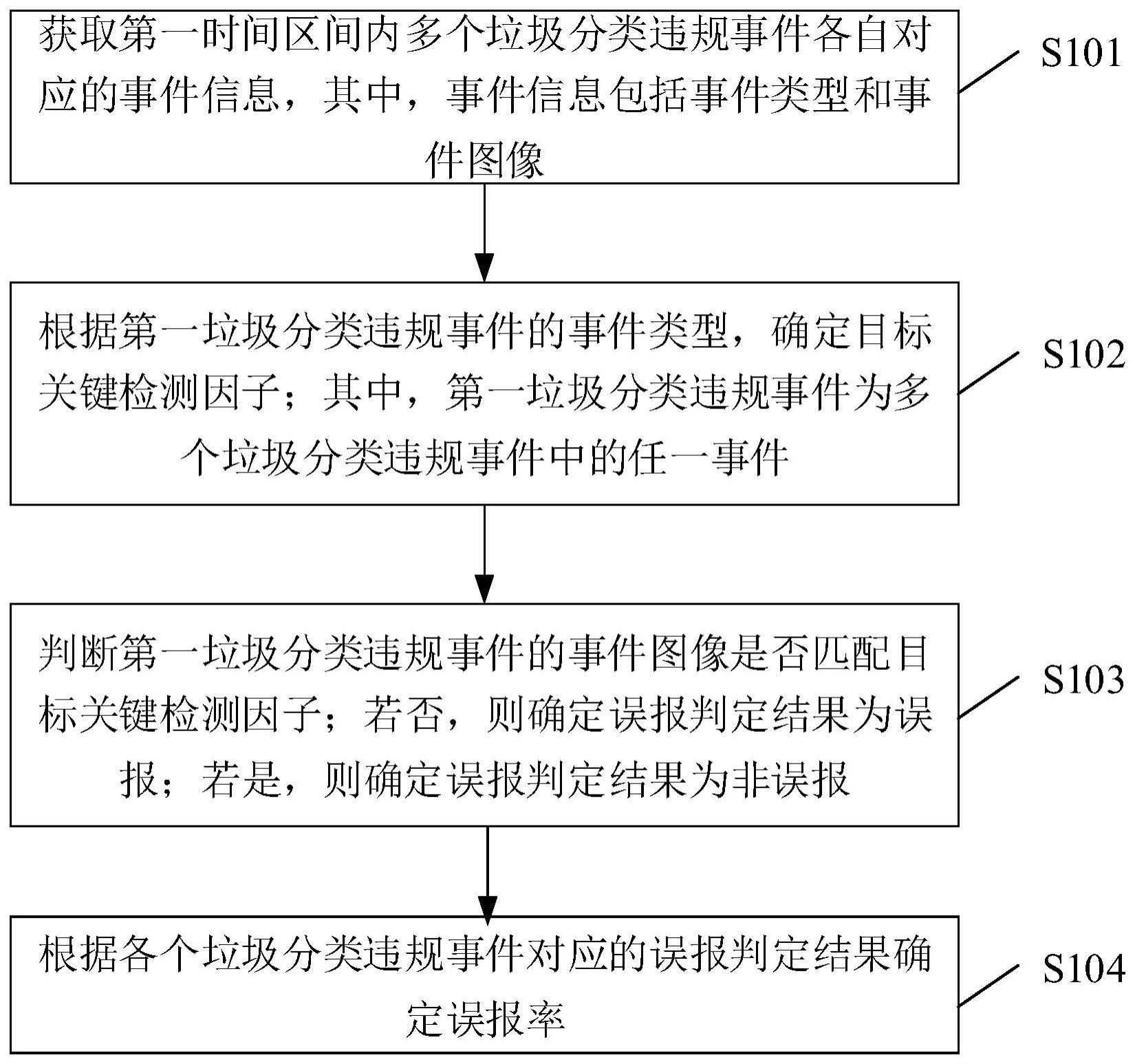
一种面向脑卒中非平衡数据集的分类方法及系统
1.本发明是发明名称为“一种面向脑卒中非平衡数据集的分类方法及系统”的分案申请,其中,母案的申请号为201911189087.0,申请日为2019.11.28。
技术领域
2.本发明涉及数据处理技术领域,特别是涉及一种面向脑卒中非平衡数据集的分类方法及系统。
背景技术:
3.脑卒中又称“中风”、“脑血管意外”,是一种急性脑血管疾病,是由于脑部血管突然破裂或因血管阻塞导致血液不能流入大脑而引起脑组织损伤的一种疾病。随着医疗信息化的发展,脑卒中数据逐渐呈现非平衡数据集特性,脑卒中患者要普遍少于非脑卒中患者,由于分类模型普遍存在偏向性,即对非脑卒中患者(称为多数类)的分类效果较好,对脑卒中患者(称为少数类)的分类性能偏低甚至不能识别,因此采用现有的分类模型对脑卒中非平衡数据集进行分类时,对脑卒中患者(少数类)数据的分类性能较差。
技术实现要素:
4.本发明的目的是提供一种面向脑卒中非平衡数据集的分类方法及系统,以解决现有分类模型对脑卒中非平衡数据集分类中脑卒中患者即少数类分类性能较差的问题。
5.为实现上述目的,本发明提供了如下方案:
6.一种面向脑卒中非平衡数据集的分类方法,包括:
7.获取脑卒中非平衡数据集;所述脑卒中非平衡数据集中的数据为二分类数据,将数量多的正常个体视为负类样本,将数量较少的患病个体视为正类样本;
8.将所述脑卒中非平衡数据集按照7:3比例随机划分成训练样本集和测试样本集,其中训练样本集和测试样本集非平衡率不改变;所述训练样本集中的样本点表示为xi∈rd,xi代表所述脑卒中非平衡数据集中的第i个样本点的特征向量,d是特征向量的维数,表示第d维特征向量,rd是指训练样本集合属于d维实数空间;采用yi代表两种不同的类别标签,yi∈{-1, 1},则yi=-1代表负类样本,即非脑卒中患者;yi= 1代表正类样本,即脑卒中患者;u(xi)是模糊隶属度函数,表示第i个样本的隶属度,代表第i个样本xi属于yi类的程度,0<u(xi)≤1;
9.计算所述训练样本集中各个样本点之间的距离;
10.根据所述各个样本点之间的距离确定正/负类样本自适应调节半径;根据所述正/负类样本自适应调节半径确定正/负类样本自适应调节因子;根据所述正/负类样本自适应调节因子构建差异矩阵;
11.根据所述差异矩阵统计所述样本点有效范围内的正类样本个数和负类样本个数;其中正类样本是指脑卒中非平衡数据集中脑卒中患者数据,负类样本是指脑卒中非平衡数据集中非脑卒中患者数据;
12.根据所述正类样本个数和所述负类样本个数确定所述样本点所含的正/负类信息量;
13.根据所述样本点所含的正/负类信息量构造信息量模糊隶属函数u1(xi);
14.根据所述各个样本点之间的距离确定基于样本间距离的正/负类模糊隶属度函数;
15.根据所述信息量模糊隶属函数及所述基于样本间距离的正/负类模糊隶属度函数确定改进后的正/负类模糊隶属度函数;
16.根据所述改进后的正/负类模糊隶属度函数构造模糊支持向量机分类器;
17.采用所述模糊支持向量机分类器对脑卒中非平衡数据集中的测试样本集进行分类;将待分类的脑卒中非平衡数据集输入构造的模糊支持向量机分类器中,输出所述脑卒中非平衡数据集的各个测试数据对应的类别,将其划分为脑卒中患者或者非脑卒中患者。
18.可选地,根据所述各个样本点之间的距离确定正/负类样本自适应调节半径,具体包括:
19.正类样本自适应调节半径定义为:
20.ar
=max(d
ij
)/q
;
21.负类样本自适应调节半径定义为:
22.ar
—
=max(d
ij
)/q-;
23.其中,max(d
ij
)表示各个样本点之间的距离d
ij
的最大值,正类样本自适应因子q
=q,负类样本的自适应因子q-=q/r;q为自适应因子;r为非平衡数据集对应的非平衡率,r=负类样本数/正类样本数。
24.可选地,根据所述正/负类样本自适应调节半径确定正/负类样本自适应调节因子,具体包括:
25.正类样本自适应调节因子为:
[0026][0027]
负类样本自适应调节因子为:
[0028][0029]
可选地,构建的差异矩阵为:
[0030][0031]
其中,t
ij
为正/负类样本自适应调节因子,n为训练样本集中样本点的个数;根据所述差异矩阵统计所述样本点有效范围内的正类样本个数m
和负类样本个数m-。
[0032]
可选地,根据所述各个样本点之间的距离确定基于样本间距离的正/负类模糊隶属度函数,具体包括:
[0033]
根据所述训练样本集中的第i个样本点xi和第j个样本点xj之间的距离d
ij
,采用公式确定正类的向心度
[0034]
根据所述训练样本集中的第i个样本点xi和第j个样本点xj之间的距离d
ij
,采用公式确定负类的向心度m
和m
—
分别代表正类样本个数和负类样本个数;
[0035]
根据所述正类的向心度采用公式确定基于样本间距离的正类模糊隶属度函数其中δ为正值参数值;表示正类向心度的最大值;
[0036]
根据所述负类的向心度采用公式确定基于样本间距离的负类模糊隶属度函数的负类模糊隶属度函数表示负类向心度的最大值。
[0037]
可选地,根据所述信息量模糊隶属函数及所述基于样本间距离的正/负类模糊隶属度函数确定改进后的正/负类模糊隶属度函数,具体包括:
[0038]
根据所述信息量模糊隶属函数u1(xi)及所述基于样本间距离的正类模糊隶属度函数采用公式确定改进后的正类模糊隶属度函数u
(xi);
[0039]
根据所述信息量模糊隶属函数u1(xi)及所述基于样本间距离的负类模糊隶属度函数采用公式m
≠0确定改进后的负类模糊隶属度函数u-(xi)。
[0040]
可选地,所述模糊支持向量机分类器的函数公式为:
[0041][0042]
其中,w代表超平面的法向量;c
、c
—
分别代表正类样本、负类样本的惩罚因子,c
,c-为常数;n为样本点的个数;代表正类模糊隶属度函数,即u
(xi);代表负类模糊隶属
度函数,即u-(xi);ξi为松弛因子;yi代表两种不同的类别标签,φ(xi)代表核函数,b代表偏移量;
[0043]
通过求解所述模糊支持向量机分类器的函数公式,得到最优分类超平面,从而得到样本点xi的类别标签。
[0044]
为达上述目的,本发明还提供了如下技术方案:
[0045]
一种面向脑卒中非平衡数据集的分类系统,所述系统包括:
[0046]
非平衡数据集获取模块,用于获取脑卒中非平衡数据集;
[0047]
非平衡数据集划分模块,用于将所述脑卒中非平衡数据集按照7:3比例随机划分成训练样本集和测试样本集,其中训练样本集和测试样本集非平衡率不改变;
[0048]
样本间距离计算模块,用于计算所述训练样本集中各个样本点之间的距离;
[0049]
差异矩阵构造模块,用于根据所述训练样本集中各个样本点之间的距离构造差异矩阵;
[0050]
样本数量统计模块,用于根据所述差异矩阵统计所述样本点有效范围内的正类样本个数和负类样本个数;其中正类样本是指脑卒中非平衡数据集中脑卒中患者数据,负类样本是指脑卒中非平衡数据集中非脑卒中患者数据;
[0051]
正负类信息量计算模块,用于根据所述正类样本个数和所述负类样本个数确定所述样本点所含的正/负类信息量;
[0052]
信息量模糊隶属函数构造模块,用于根据所述样本点所含的正/负类信息量构造信息量模糊隶属函数;
[0053]
基于样本间距离的正负类模糊隶属度函数确定模块,用于根据所述各个样本点之间的距离确定基于样本间距离的正/负类模糊隶属度函数;
[0054]
改进后的正负类模糊隶属度函数构建模块,用于根据所述信息量模糊隶属函数及所述基于样本间距离的正/负类模糊隶属度函数确定改进后的正/负类模糊隶属度函数;
[0055]
模糊支持向量机分类器构造模块,用于根据所述改进后的正/负类模糊隶属度函数构造模糊支持向量机分类器;
[0056]
非平衡数据分类模块,用于采用所述模糊支持向量机分类器对脑卒中非平衡数据集中的测试样本集进行分类。
[0057]
可选的,所述样本间距离计算模块具体包括:
[0058]
样本间距离计算单元,用于采用公式d
ij
=|x
i-xj|计算所述训练样本集中的第i个样本点xi和第j个样本点xj之间的距离d
ij
。
[0059]
可选的,所述差异矩阵构造模块具体包括:
[0060]
自适应调节半径确定单元,用于根据所述各个样本点之间的距离d
ij
确定正/负类样本自适应调节半径;
[0061]
自适应调节因子确定单元,用于根据所述正/负类样本自适应调节半径确定正/负类样本自适应调节因子;
[0062]
差异矩阵构建单元,用于根据所述正/负类样本自适应调节因子构建差异矩阵。
[0063]
根据本发明提供的具体实施例,本发明公开了以下技术效果:
[0064]
本发明提供一种面向脑卒中非平衡数据集的分类方法及系统,将数量多的正常个体视为负类样本,将数量较少的患病个体视为正类样本,以得到脑卒中非平衡数据集;利用
自适应因子来构造正类样本与负类样本的差异矩阵,充分考虑了脑卒中数据集的非平衡特性对分类结果的影响,使得改进后的模糊隶属度函数更适用于脑卒中非平衡数据集的分类,即对大量患者数据中的脑卒中患者或者非脑卒中患者进行分类;本发明在设计模糊隶属度函数时,首先根据不同类别样本间数量关系,利用信息熵来衡量样本点的不确定性,其次考虑同类样本间距离的关系,构造出一种改进后的模糊隶属度函数,将改进后的模糊隶属度函数应用于模糊支持向量机中,所构造的模糊支持向量机分类器主要是对模糊隶属度函数进行改进设计,目的是为了有效解决数据中少数类的分类准确率较低的问题,提高模糊支持向量机分类器对脑卒中非平衡数据集的分类性能。
[0065]
本发明充分考虑了不同类别样本间的数量关系,以及同类样本间距离的关系,基于此进行模糊隶属度的计算,并构建模糊支持向量机;当需要对某一脑卒中非平衡数据集中的数据进行分类时,将该数据集直接输入至已训练好的模糊支持向量机中可得到各个数据的类别,即为脑卒中患者或者非脑卒中患者,从而解决脑卒中非平衡数据集的分类问题,提高分类准确率。
附图说明
[0066]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0067]
图1为本发明提供的面向脑卒中非平衡数据集的分类方法的流程图;
[0068]
图2为本发明提供的面向脑卒中非平衡数据集的分类方法的原理图;
[0069]
图3为本发明提供的面向脑卒中非平衡数据集的分类系统的结构图。
具体实施方式
[0070]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0071]
本发明主要针对模糊支持向量机对脑卒中非平衡数据集分类过程中存在的模糊隶属度函数赋予不准确和分类效果不佳等不足,提出一种面向脑卒中非平衡数据集的分类方法及系统,为改进模糊隶属函数提供一定的参考,最后将其应用于模糊支持向量机中,有效提高其在脑卒中非平衡数据集中的分类性能。
[0072]
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
[0073]
图1为本发明提供的面向脑卒中非平衡数据集的分类方法的流程图。图2为本发明提供的面向脑卒中非平衡数据集的分类方法的原理图。参见图1和图2,本发明提供的面向脑卒中非平衡数据集的分类方法具体包括:
[0074]
步骤101:获取脑卒中非平衡数据集。
[0075]
所述非平衡数据集是指,如果一个数据集中某一个类别的样本远远多余其他的类
定义正/负类样本自适应调节因子。
[0096]
其中正类样本自适应调节因子为:
[0097][0098]
负类样本自适应调节因子为:
[0099][0100]
3)根据所述正/负类样本自适应调节因子t
ij
构建差异矩阵r。
[0101]
设t={t
ij
}是基于非平衡率的自适应矩阵,其构成如下:
[0102][0103]
另外根据求得的d
ij
,可进一步得到差异矩阵r为
[0104][0105]
其中n为训练样本集中样本点的个数,t
ij
为正/负类样本对应的自适应调节因子,d
ij
为样本间差异。
[0106]
步骤105:根据所述差异矩阵统计所述样本点有效范围内的正类样本个数和负类样本个数。
[0107]
统计样本点xi有效范围内的正类样本和负类样本的个数m
和m-,其中样本点xi对应的有效范围根据差异矩阵r第i行确定。
[0108]
步骤106:根据所述正类样本个数和所述负类样本个数确定所述样本点所含的正/负类信息量。
[0109]
所述正/负类信息量包括样本点所含的正类信息量和负类信息量。设样本点xi属于正类的概率为属于负类的概率为其中k=m
m-。m
为第i个样本点xi有效范围内的正类样本个数;m-为第i个样本点xi有效范围内的负类样本个数。则可以得出xi所含正/负类信息量分别为:
[0110]h
(xi)=-p
lnp
ꢀꢀ
(8)
[0111]
h-(xi)=-p-lnp-ꢀꢀ
(9)
[0112]
其中h
(xi)表示所述训练样本集中的第i个样本点xi所含的正类信息量;h-(xi)表示所述训练样本集中的第i个样本点xi所含的负类信息量;p
为样本点xi属于正类的概率,p-为样本点xi属于负类的概率。
[0113]
步骤107:根据所述样本点所含的正/负类信息量构造信息量模糊隶属函数。
[0114]
根据所述第i个样本点xi所含的正类信息量h
(xi)和负类信息量h-(xi)构造信息量模糊隶属函数u1(xi):
[0115]
u1(xi)=1-(h
(xi) h-(xi))
ꢀꢀ
(10)
[0116]
式中0<u1(xi)≤1。
[0117]
步骤108:根据所述各个样本点之间的距离确定基于样本间距离的正/负类模糊隶属度函数。
[0118]
根据自适应调节半径内目标样本xi与其同类样本之间的距离得到正类和负类的向心度和
[0119]
其中正类的向心度:
[0120]
负类的向心度:
[0121]
其中,d
ij
代表目标样本与其同类样本之间的差异,m
和m
—
分别代表正类样本个数和负类样本个数。
[0122]
所述基于样本间距离的正/负类模糊隶属度函数包括基于样本间距离的正类模糊隶属度函数和基于样本间距离的负类模糊隶属度函数。根据式(11)可得基于样本间距离的正类模糊隶属度函数:
[0123][0124]
根据式(12)可得基于样本间距离的负类模糊隶属度函数:
[0125][0126]
其中和分别表示基于样本间距离的正类和负类的模糊隶属度函数;δ表示一个很小的正值参数值,表示正类向心度的最大值,表示负类向心度的最大值。
[0127]
本发明通过类内向心度来体现样本之间的紧密程度,提出一种基于类内向心度的模糊支持向量机,克服了传统模糊支持向量机缺陷的同时,还可以通过向心度来对混合程度较高的样本进行区分,从而达到有效地识别有效样本、噪声野值点的目的,减小了噪声、野值点对构造最优分类面的影响。
[0128]
步骤109:根据所述信息量模糊隶属函数及所述基于样本间距离的正/负类模糊隶属度函数确定改进后的正/负类模糊隶属度函数。
[0129]
在计算模糊隶属度函数时,首先需要确定所有样本点之间的差异,并根据自适应半径构造出差异矩阵,随后在此差异矩阵中利用正、负类样本数目的差异确定隶属度函数。当样本点xi属于正类,且xi周围无正类样本,且只有负类样本时,将其视为噪声点,并将其隶属度值设为一个极小值δ;同理,当样本点xi属于负类,且xi周围无负类样本,且只有正类样
本时,同样将其视为噪声点,并将其隶属度值设为一个极小值。当样本点xi属于正类,xi周围无负类样本,且只有正类样本时,则将其视为有效点,将其隶属度设为1;同理,当样本点xi属于负类,且xi周围无正类样本,只有负类样本时,也将其视为有效点,将其隶属度设为1。当其周围既有正类样本又有负类样本,则需要同时考虑每个样本点周围正负类样本的数量以及样本间距离,利用信息熵来衡量其周围样本数量的关系,利用基于样本间距离的隶属度函数衡量正类和负类的模糊隶属度函数。
[0130]
所述改进后的正/负类模糊隶属度函数包括改进后的正类模糊隶属度函数和改进后的负类模糊隶属度函数。根据式(13)、式(14)和式(10)可以得出改进后的模糊隶属度函数计算公式。其中根据所述信息量模糊隶属函数u1(xi)及所述基于样本间距离的正类模糊隶属度函数确定改进后的正类模糊隶属度函数u
(xi)为:
[0131][0132]
根据所述信息量模糊隶属函数u1(xi)及所述基于样本间距离的负类模糊隶属度函数确定改进后的负类模糊隶属度函数u-(xi)为:
[0133][0134]
其中0<u
(xi)≤1,0<u-(xi)≤1分别表示改进后的正类及负类模糊隶属度函数,表示了第i个样本的隶属度,代表着第i个样本xi属于yi类的可靠程度。δ为一个很小的值,可以根据实际情况设定。
[0135]
步骤110:根据所述改进后的正/负类模糊隶属度函数构造模糊支持向量机分类器。
[0136]
模糊支持向量机(fuzzy support vector machine,fsvm)是在支持向量机的基础上给每个训练样本分别加上一个隶属度,这样不同的训练样本就会有不同的隶属度。在构造目标函数时,使不同的样本对最优解的求取有不同的作用,从而使不同的样本对最优超平面的确定有不同的贡献。让噪声或孤立点的隶属度很小,达到减小噪声或孤立点对最优超平面影响的目的。隶属度函数的设计直接影响模糊支持向量机的分类性能。不同的隶属度函数设计方法对于算法实现的难易程度以及最终的分类结果都有很重要的影响。
[0137]
本发明利用所述改进后的模糊隶属度函数构造模糊支持向量机分类器,并采用模糊支持向量机分类器完成对测试样本的分类。
[0138]
本发明构造的模糊支持向量机分类器的一般形式可以表示为:
[0139][0140]
式中w代表超平面的法向量;c
、c
—
分别代表正、负类样本的惩罚因子,c
,c-为常数。n为样本点的个数。y= 1代表正类样本标签,即脑卒中患者标签;y=-1代表负类样本标签,即非脑卒中患者标签。代表改进后的正类的模糊隶属度函数,即u
(xi);代表改进后的负类的模糊隶属度函数,即u-(xi)。ξi为松弛因子。yi代表两种不同的类别标签,yi∈{-1, 1}。φ(xi)代表核函数,b代表偏移量。
[0141]
通过求解公式(17),可以得到最优分类超平面,从而得到样本点xi的类别标签。
[0142]
本发明构造的模糊支持向量机分类器主要是对模糊隶属度函数进行了改进设计,目的是为了有效解决数据中少数类的分类准确率较低的问题,本发明充分考虑了不同类别样本间的数量关系,以及同类样本间距离的关系,可以用来解决脑卒中非平衡数据集的分类问题,提高分类准确率。
[0143]
步骤111:采用所述模糊支持向量机分类器对脑卒中非平衡数据集进行分类。
[0144]
在实际应用中,将待分类的脑卒中非平衡数据集输入新构造的模糊支持向量机分类器中,就可以输出该脑卒中非平衡数据集的各个测试数据对应的类别,即将其划分为脑卒中患者或者非脑卒中患者。
[0145]
一般的模糊隶属函数设计方法没有综合考虑到样本数量与样本距离之间的关系,本发明主要针对现有的模糊支持向量机分类模型在对脑卒中非平衡数据集进行分类的过程中存在的模糊隶属度函数赋予不准确和分类效果不佳等不足,在设计模糊隶属度函数时,首先根据不同类别样本间数量关系,利用信息熵来衡量样本点的不确定性,其次考虑同类样本间距离的关系,构造出一种新的模糊隶属度函数,为改进模糊隶属函数提供一定的参考,最后将其应用于模糊支持向量机中,有效提高脑卒中非平衡数据集的分类性能。
[0146]
下面采用测试样本集中的数据验证本发明所设计的脑卒中模糊支持向量机分类器能否有效地提升脑卒中患者数据的分类准确率以及其分类性能。验证实验的评价指标采用二分类问题常用的评价指标:敏感性se(sensitivity),特异性sp(specificity)、准确率acc(accuracy)以及几何平均gm(g-mean),其定义分别为:
[0147][0148]
上式中tp、fn、tn、fp分别代表样本点被分类模型(即本发明的模糊支持向量机分类器)正确预测为脑卒中患者的脑卒中患者样本数、被分类模型错误预测为非脑卒中患者的脑卒中患者样本数、被分类模型正确预测为非脑卒中患者的非脑卒中患者样本数、以及被分类模型错误预测为脑卒中患者的非脑卒中患者样本数,se、sp、acc和gm的值越大表明分类效果越好。se大说明对脑卒中患者数据的分类准确率较高,也是非平衡数据集期望的结果;sp则反映了对非脑卒中患者数据的分类性能。但通常情况下,具有较高se的分类器不一定有高的sp,也就是对脑卒中患者数据分类性能好的同时,对非脑卒中患者数据的分类
性能会有所下降,因此本发明对脑卒中非平衡数据集,进一步采用gm作为评价指标,以更精确反映本发明设计的脑卒中分类器的总体性能。
[0149]
实验选取kaggle数据库中的脑卒中非平衡数据集进行本发明方法的性能验证,基于kaggle数据库中的脑卒中非平衡数据集,重新整理得到三个不同平衡率的脑卒中数据集,表1给出了三个数据集data1、data2和data3的详细介绍。
[0150]
表1三个不同平衡率的脑卒中非平衡数据集介绍
[0151][0152]
使用本发明构建好的脑卒中模糊支持向量机分类器对3个不同平衡率的脑卒中数据集data1、data2和data3分别进行分类实验,其详细结果如下表2所示。
[0153]
表2实验详细结果
[0154]
数据集sespaccgmdata162.579.3176.4370.41data276.4971.572.2273.95data373.6870.0670.4371.84
[0155]
由表2所示的实验结果可知,在三个数据集的分类结果中,acc和gm均可达70%以上,另外随着数据集样本总数的增大,本发明所提出的方法具有较好的适应性。通过观察表1和表2可知,当样本总数变大以及非平衡率变高的时候,se逐渐增大,脑卒中患者数据分类性能提升,sp逐渐减小,但降低的幅度不是很大,说明本发明充分考虑了不同类别样本间的数量关系,以及同类样本间距离的关系,可以用来解决脑卒中非平衡数据集的分类问题,提高对脑卒中非平衡数据集的分类性能。
[0156]
本发明方法利用自适应因子来构造差异矩阵,充分考虑了非平衡性对正负类样本数量的影响,使得改进后的模糊隶属度函数更适用于脑卒中非平衡数据集的分类。本发明在设计模糊隶属度函数时,首先设置差异矩阵,其次通过正负类样本数量间的关系将隶属度函数分为两个部分,利用信息熵衡量正、负类样本所含的信息量大小,以及使用基于样本间距离的隶属度函数衡量样本间距离的关系,构造出一种全新的、改进后的模糊隶属度函数。本发明不仅更加准确地设计了模糊隶属度函数,还为如何设计模糊隶属度函数提供了一种新的思路。
[0157]
基于本发明提供的面向脑卒中非平衡数据集的分类方法,本发明还提供一种面向脑卒中非平衡数据集的分类系统,参见图3,所述系统包括:
[0158]
非平衡数据集获取模块301,用于获取脑卒中非平衡数据集。
[0159]
非平衡数据集划分模块302,用于将所述脑卒中非平衡数据集按照7:3比例随机划分成训练样本集和测试样本集,其中训练样本集和测试样本集的非平衡率不改变。
[0160]
样本间距离计算模块303,用于计算所述训练样本集中各个样本点之间的距离。
[0161]
差异矩阵构造模块304,用于根据所述训练样本集中各个样本点之间的距离构造
差异矩阵。
[0162]
样本数量统计模块305,用于根据所述差异矩阵统计所述样本点有效范围内的正类样本个数和负类样本个数。
[0163]
正负类信息量计算模块306,用于根据所述正类样本个数和所述负类样本个数确定所述样本点所含的正/负类信息量。
[0164]
信息量模糊隶属函数构造模块307,用于根据所述样本点所含的正/负类信息量构造信息量模糊隶属函数。
[0165]
基于样本间距离的正负类模糊隶属度函数确定模块308,用于根据所述各个样本点之间的距离确定基于样本间距离的正/负类模糊隶属度函数。
[0166]
改进后的正负类模糊隶属度函数构建模块309,用于根据所述信息量模糊隶属函数及所述基于样本间距离的正/负类模糊隶属度函数确定改进后的正/负类模糊隶属度函数。
[0167]
模糊支持向量机分类器构造模块310,用于根据所述改进后的正/负类模糊隶属度函数构造模糊支持向量机分类器。
[0168]
非平衡数据分类模块311,用于采用所述模糊支持向量机分类器对脑卒中非平衡数据集进行分类。
[0169]
其中,所述样本间距离计算模块303具体包括:
[0170]
样本间距离计算单元,用于采用公式d
ij
=|x
i-xj|计算所述训练样本集中的第i个样本点xi和第j个样本点xj之间的距离d
ij
。
[0171]
所述差异矩阵构造模块304具体包括:
[0172]
自适应调节半径确定单元,用于根据所述各个样本点之间的距离d
ij
确定正/负类样本自适应调节半径。
[0173]
自适应调节因子确定单元,用于根据所述正/负类样本自适应调节半径确定正/负类样本自适应调节因子。
[0174]
差异矩阵构建单元,用于根据所述正/负类样本自适应调节因子构建差异矩阵。
[0175]
所述正负类信息量计算模块306具体包括:
[0176]
正类信息量计算单元,用于采用公式h
(xi)=-p
lnp
确定所述训练样本集中的第i个样本点xi所含的正类信息量h
(xi);其中k=m m-;m
为第i个样本点xi有效范围内的正类样本个数;m-为第i个样本点xi有效范围内的负类样本个数。
[0177]
负类信息量计算单元,用于采用公式h-(xi)=-p-lnp-确定所述训练样本集中的第i个样本点xi所含的负类信息量h-(xi);其中
[0178]
所述信息量模糊隶属函数构造模块307具体包括:
[0179]
信息量模糊隶属函数构造单元,用于根据所述第i个样本点xi所含的正类信息量h
(xi)和负类信息量h-(xi),采用公式u1(xi)=1-(h
(xi) h-(xi))构造信息量模糊隶属函数u1(xi)。
[0180]
所述基于样本间距离的正负类模糊隶属度函数确定模块308具体包括:
[0181]
正类向心度计算单元,用于根据所述训练样本集中的第i个样本点xi和第j个样本
点xj之间的距离d
ij
,采用公式确定正类的向心度
[0182]
负类向心度计算单元,用于根据所述训练样本集中的第i个样本点xi和第j个样本点xj之间的距离d
ij
,采用公式确定负类的向心度
[0183]
基于样本间距离的正类模糊隶属度函数确定单元,用于根据所述正类的向心度采用公式确定基于样本间距离的正类模糊隶属度函数其中δ为正值参数值,表示正类向心度的最大值。
[0184]
基于样本间距离的负类模糊隶属度函数确定单元,用于根据所述负类的向心度采用公式确定基于样本间距离的负类模糊隶属度函数其中表示负类向心度的最大值。
[0185]
所述改进后的正负类模糊隶属度函数构建模块309具体包括:
[0186]
改进后的正类模糊隶属度函数确定单元,用于根据所述信息量模糊隶属函数u1(xi)及所述基于样本间距离的正类模糊隶属度函数采用公式m-≠0确定改进后的正类模糊隶属度函数u
(xi)。
[0187]
改进后的负类模糊隶属度函数确定单元,用于根据所述信息量模糊隶属函数u1(xi)及所述基于样本间距离的负类模糊隶属度函数采用公式m
≠0确定改进后的负类模糊隶属度函数u-(xi)。
[0188]
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的系统而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
[0189]
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。