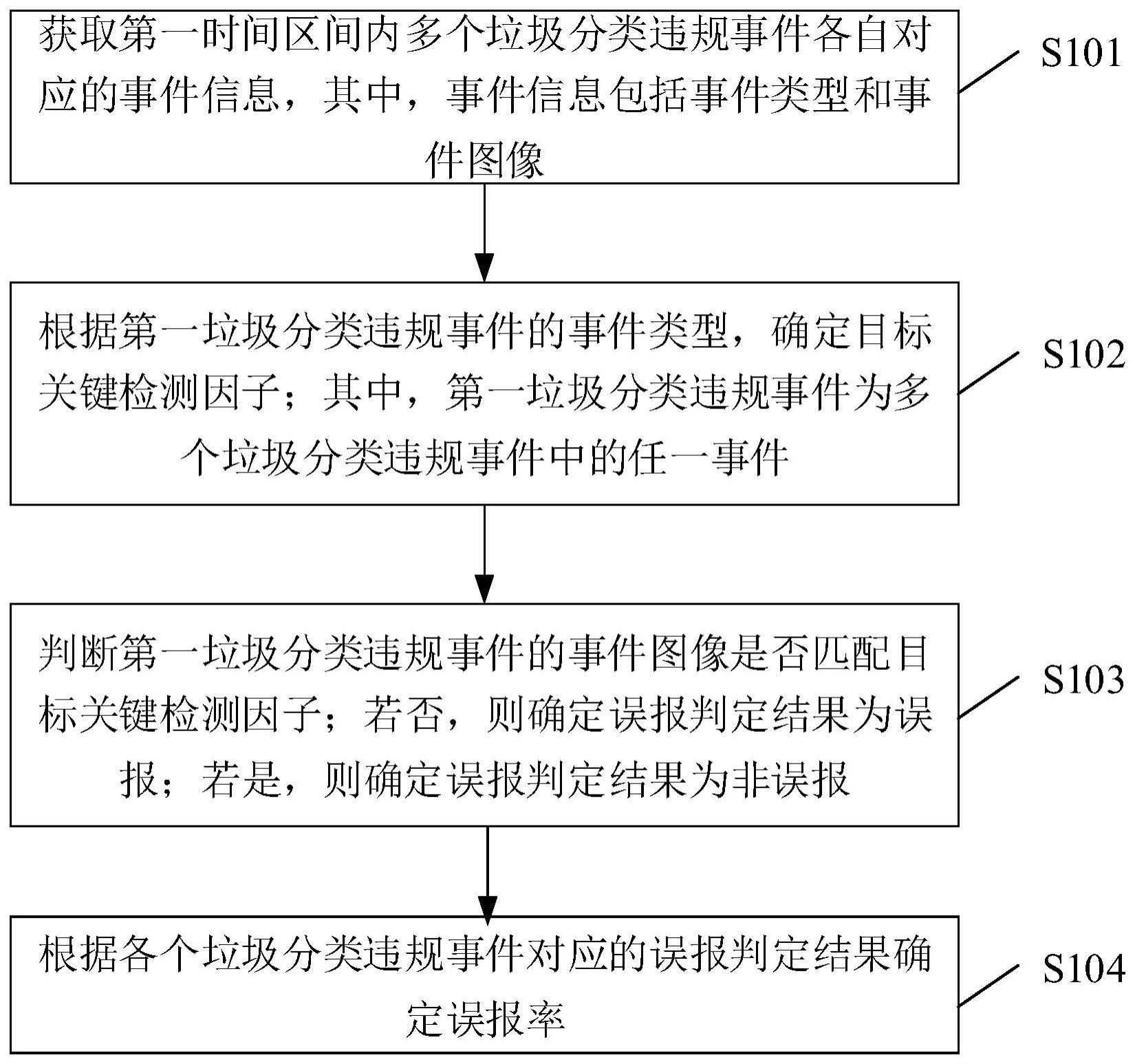
技术特征:
1.一种面向脑卒中非平衡数据集的分类方法,其特征在于,所述方法包括:获取脑卒中非平衡数据集;所述脑卒中非平衡数据集中的数据为二分类数据,将数量多的正常个体视为负类样本,将数量较少的患病个体视为正类样本;将所述脑卒中非平衡数据集按照7:3比例随机划分成训练样本集和测试样本集,其中训练样本集和测试样本集非平衡率不改变;所述训练样本集中的样本点表示为x
i
代表所述脑卒中非平衡数据集中的第i个样本点的特征向量,d是特征向量的维数,表示第d维特征向量,r
d
是指训练样本集合属于d维实数空间;采用y
i
代表两种不同的类别标签,y
i
∈{-1, 1},则y
i
=-1代表负类样本,即非脑卒中患者;y
i
= 1代表正类样本,即脑卒中患者;u(x
i
)是模糊隶属度函数,表示第i个样本的隶属度,代表第i个样本x
i
属于y
i
类的程度,0<u(x
i
)≤1;计算所述训练样本集中各个样本点之间的距离;根据所述各个样本点之间的距离确定正/负类样本自适应调节半径;根据所述正/负类样本自适应调节半径确定正/负类样本自适应调节因子;根据所述正/负类样本自适应调节因子构建差异矩阵;根据所述差异矩阵统计所述样本点有效范围内的正类样本个数和负类样本个数;其中正类样本是指脑卒中非平衡数据集中脑卒中患者数据,负类样本是指脑卒中非平衡数据集中非脑卒中患者数据;根据所述正类样本个数和所述负类样本个数确定所述样本点所含的正/负类信息量;根据所述样本点所含的正/负类信息量构造信息量模糊隶属函数u1(x
i
);根据所述各个样本点之间的距离确定基于样本间距离的正/负类模糊隶属度函数;根据所述信息量模糊隶属函数及所述基于样本间距离的正/负类模糊隶属度函数确定改进后的正/负类模糊隶属度函数;根据所述改进后的正/负类模糊隶属度函数构造模糊支持向量机分类器;采用所述模糊支持向量机分类器对脑卒中非平衡数据集中的测试样本集进行分类;将待分类的脑卒中非平衡数据集输入构造的模糊支持向量机分类器中,输出所述脑卒中非平衡数据集的各个测试数据对应的类别,将其划分为脑卒中患者或者非脑卒中患者。2.根据权利要求1所述的面向脑卒中非平衡数据集的分类方法,其特征在于,根据所述各个样本点之间的距离确定正/负类样本自适应调节半径,具体包括:正类样本自适应调节半径定义为:ar
=max(d
ij
)/q
;负类样本自适应调节半径定义为:ar
—
=max(d
ij
)/q-;其中,max(d
ij
)表示各个样本点之间的距离d
ij
的最大值,正类样本自适应因子q
=q,负类样本的自适应因子q-=q/r;q为自适应因子;r为非平衡数据集对应的非平衡率,r=负类样本数/正类样本数。3.根据权利要求2所述的面向脑卒中非平衡数据集的分类方法,其特征在于,根据所述正/负类样本自适应调节半径确定正/负类样本自适应调节因子,具体包括:正类样本自适应调节因子为:
负类样本自适应调节因子为:4.根据权利要求3所述的面向脑卒中非平衡数据集的分类方法,其特征在于,构建的差异矩阵为:其中,t
ij
为正/负类样本自适应调节因子,n为训练样本集中样本点的个数;根据所述差异矩阵统计所述样本点有效范围内的正类样本个数m
和负类样本个数m-。5.根据权利要求1所述的面向脑卒中非平衡数据集的分类方法,其特征在于,根据所述各个样本点之间的距离确定基于样本间距离的正/负类模糊隶属度函数,具体包括:根据所述训练样本集中的第i个样本点x
i
和第j个样本点x
j
之间的距离d
ij
,采用公式确定正类的向心度根据所述训练样本集中的第i个样本点x
i
和第j个样本点x
j
之间的距离d
ij
,采用公式确定负类的向心度m
和m
—
分别代表正类样本个数和负类样本个数;根据所述正类的向心度采用公式确定基于样本间距离的正类模糊隶属度函数其中δ为正值参数值;表示正类向心度的最大值;根据所述负类的向心度采用公式确定基于样本间距离的负类模糊隶属度函数表示负类向心度的最大值。6.根据权利要求5所述的面向脑卒中非平衡数据集的分类方法,其特征在于,根据所述信息量模糊隶属函数及所述基于样本间距离的正/负类模糊隶属度函数确定改进后的正/负类模糊隶属度函数,具体包括:根据所述信息量模糊隶属函数u1(x
i
)及所述基于样本间距离的正类模糊隶属度函数采用公式m-≠0确定改进后的正类模糊隶属度函数u
(x
i
);根据所述信息量模糊隶属函数u1(x
i
)及所述基于样本间距离的负类模糊隶属度函数采用公式m
≠0确定改进后的负类模糊隶属度函数u-(x
i
)。7.根据权利要求1所述的面向脑卒中非平衡数据集的分类方法,其特征在于,所述模糊支持向量机分类器的函数公式为:其中,w代表超平面的法向量;c
、c
—
分别代表正类样本、负类样本的惩罚因子,c
,c-为常数;n为样本点的个数;代表正类模糊隶属度函数,即u
(x
i
);代表负类模糊隶属度函数,即u-(x
i
);ξ
i
为松弛因子;y
i
代表两种不同的类别标签,φ(x
i
)代表核函数,d代表偏移量;通过求解所述模糊支持向量机分类器的函数公式,得到最优分类超平面,从而得到样本点x
i
的类别标签。8.一种面向脑卒中非平衡数据集的分类系统,其特征在于,所述系统包括:非平衡数据集获取模块,用于获取脑卒中非平衡数据集;非平衡数据集划分模块,用于将所述脑卒中非平衡数据集按照7:3比例随机划分成训练样本集和测试样本集,其中训练样本集和测试样本集非平衡率不改变;样本间距离计算模块,用于计算所述训练样本集中各个样本点之间的距离;差异矩阵构造模块,用于根据所述训练样本集中各个样本点之间的距离构造差异矩阵;样本数量统计模块,用于根据所述差异矩阵统计所述样本点有效范围内的正类样本个数和负类样本个数;其中正类样本是指脑卒中非平衡数据集中脑卒中患者数据,负类样本是指脑卒中非平衡数据集中非脑卒中患者数据;正负类信息量计算模块,用于根据所述正类样本个数和所述负类样本个数确定所述样本点所含的正/负类信息量;信息量模糊隶属函数构造模块,用于根据所述样本点所含的正/负类信息量构造信息量模糊隶属函数;基于样本间距离的正负类模糊隶属度函数确定模块,用于根据所述各个样本点之间的距离确定基于样本间距离的正/负类模糊隶属度函数;改进后的正负类模糊隶属度函数构建模块,用于根据所述信息量模糊隶属函数及所述基于样本间距离的正/负类模糊隶属度函数确定改进后的正/负类模糊隶属度函数;
模糊支持向量机分类器构造模块,用于根据所述改进后的正/负类模糊隶属度函数构造模糊支持向量机分类器;非平衡数据分类模块,用于采用所述模糊支持向量机分类器对脑卒中非平衡数据集中的测试样本集进行分类。
技术总结
本发明公开了一种面向脑卒中非平衡数据集的分类方法及系统,涉及数据处理技术领域,方法包括:将脑卒中非平衡数据集划分成训练样本集和测试样本集;根据各个样本点之间的距离确定正/负类样本自适应调节半径,以确定正/负类样本自适应调节因子,进而构建差异矩阵;根据差异矩阵统计样本点有效范围内的正类样本个数和负类样本个数,以确定样本点所含的正/负类信息量,进而构造信息量模糊隶属函数;确定基于样本间距离的正/负类模糊隶属度函数;确定改进后的正/负类模糊隶属度函数,进而构造模糊支持向量机分类器;采用模糊支持向量机分类器对脑卒中非平衡数据集进行分类。本发明有效提高对脑卒中非平衡数据集的分类性能。有效提高对脑卒中非平衡数据集的分类性能。有效提高对脑卒中非平衡数据集的分类性能。
技术研发人员:李凤莲 张雪英 魏鑫 回海生 李彦民
受保护的技术使用者:太原理工大学
技术研发日:2019.11.28
技术公布日:2023/10/24
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。