1.本公开涉及芯片互连网络中的信息处理和通信领域,具体而言,涉及一种存储设备、信息存储方法及系统。
背景技术:
2.许多电子技术,如数字计算机、计算器、音频设备、视频设备和电话系统,在商业、科学、教育和娱乐的大多数领域,有助于提高分析和通信数据和信息的生产率和降低成本。电子元件可以用于许多重要的应用中(例如,医疗程序、车辆辅助操作、金融应用,等等),而这些活动经常会涉及到处理和存储大量的信息。这些应用通常涉及大量的信息处理。处理(例如,存储、处理、通信,等等)大量的信息可能存在问题并且是困难的。
3.在许多应用中,快速准确地处理信息对系统来说是非常重要的,而快速准确处理信息的能力往往依赖于对信息的访问。传统的系统,尤其是在并行处理环境中,通常难以对大量信息进行归类和处理。提供很少的存储器通常是非常有害的,并且经常导致应用完全故障。在具有足够专用存储器容量以存储所有信息的每个并行处理资源处提供大量专用存储器的传统尝试通常非常昂贵。此外,每个处理资源通常在不同的时间具有不同的存储器存储访问需求,并且许多存储器资源可能是空闲的或本质上浪费的。共享存储器资源的传统尝试通常会引起通信问题,并且会大大减慢处理资源对信息的访问,从而导致相当大的性能限制和恶化。
4.图1是示出了尝试共享存储器资源的示例传统系统100的框图。通常,系统100包括多个服务器,并且每个服务器包括多个并行计算单元。在图1的示例中,系统100包括服务器101和102。服务器101包括并行处理单元(parallel processing unit,ppu)ppu_0a至ppu_n、外围组件互连高速(peripheral component interconnect express,pcie)总线111、存储卡113、网络接口控制器或卡(network interface card,nic)112、主中央处理单元(central processing unit,cpu)114和存储器115。服务器102包括并行处理单元(ppu)ppu_0b至ppu_m、外围组件互连高速(pcie)总线121、存储卡123、网络接口控制器或卡(nic)122、以及主中央处理单元(cpu)124。每个ppu包括诸如处理核和存储器(未示出)的元件。在一个实施例中,ppu可以是神经网络处理单元(neural network processing unit,npu)。在一个示例性实施例中,多个npu以并行配置布置。外围组件互连高速(pcie)总线111与ppu_0a至ppu_n、存储卡113、主中央处理单元(cpu)114和网络接口控制器或卡(nic)112通信耦合,网络接口控制器或卡(nic)112与网络130通信耦合。主中央处理单元(cpu)114与存储器115(例如,ram、dram、ddr4、ddr,等等)耦合。外围组件互连高速(pcie)总线121与ppu_0b至ppu_m、存储卡123、主中央处理单元(cpu)124和网络接口控制器或卡(nic)122通信耦合,网络接口控制器或卡(nic)122与网络130通信耦合。在一个示例中,网络130可以是以太网。
5.系统100包括使用例如分区全局地址空间(partitioned global address space,pgas)编程模型的统一存储器寻址空间。在许多应用中,特定ppu可能需要访问存储在系统的存储卡上的信息。因此,在图1的示例中,服务器101上的ppu_0a可能需要访问存储在存储
卡113和123上的信息。为了访问存储卡113上的信息,根据在系统中的位置,通过总线111在系统中的某处传送信息。例如,为了将数据从ppu_0a写入服务器101上的存储卡113,通过pcie总线111将数据从ppu_0a发送到存储卡113;为了将数据从服务器101上的ppu_0a写入服务器102上的存储卡123,通过pcie总线111将数据从ppu_0a发送到nic112,然后通过网络130将数据发送到nic122,然后通过pcie总线121将数据发送到存储卡123。
6.系统100可用于诸如图分析和图神经网络的应用,并且更具体地可用于诸如在线购物引擎、社交网络、推荐引擎、映射引擎、故障分析、网络管理和搜索引擎的应用。这些应用执行大量的存储器访问请求(例如,读和写请求),并因此还传送(例如,读和写)大量的数据以供处理。虽然pcie带宽和数据传输速率相当可观,但是其对这些应用来说仍然是有限的。作为一个实际问题,对于这些应用来说,pcie通常确实太慢,其带宽太窄。传统pcie总线方法的慢且窄的带宽也可能限制灵活配置和扩展存储器容量的传统尝试。
技术实现要素:
7.本公开的系统实现了高效和有效的网络通信。
8.在一个实施例中,存储设备包括:存储器模块,包括被配置为存储信息的多个存储芯片;以及芯片互连网络(inter-chip network,icn)/共享智能存储器扩展(smart memory extension,smx)存储器接口控制器(icn/smx存储器接口控制器),被配置为在存储器模块和芯片互连网络(icn)之间提供接口,其中icn被配置为将存储设备通信耦合到并行处理单元(ppu)。在一个示例性实施例中,icn/smx存储器接口控制器包括芯片互连网络(icn)接口、共享智能存储器扩展(smx)接口、多个包缓冲器和交换机。icn接口被配置为与icn通信耦合。共享智能存储器扩展(smx)接口被配置为与icn接口通信耦合。多个包缓冲器被配置为缓冲来自smx接口的信息包。交换机被配置为将多个包缓冲器通信耦合到smx接口,且将信息路由到多个包缓冲器和从多个包缓冲器路由信息。
9.可以理解,icn/smx存储器接口控制器能够灵活扩展可用于处理资源的存储器资源。在一个实施例中,icn/smx存储器接口控制器和icn能够将存储设备和ppu直接通信连接,其中直接通信连接灵活扩展ppu对存储器模块的访问。icn/smx存储器接口控制器和icn可以将存储设备和ppu通信耦合,该通信耦合总体上比存储设备和ppu之间的其他通信总线更快。在一个示例性实施例中,直接通信连接灵活扩展ppu和另一ppu对到存储器模块的访问。
10.存储设备可以包括处理元件阵列组件,处理元件阵列组件被配置为在存储设备上执行并行处理。在一个实施例中,处理元件阵列组件包括:多个处理元件,被配置为处理信息;以及处理元件控制器,被配置为控制进出所述多个处理元件的信息流。在一个示例性实施例中,处理元件阵列组件用于处理与加速图形处理相关联的信息。
11.可以理解的是,存储设备可以与各种存储器配置兼容。icn/smx存储器接口控制器可针对各种灵活扩展架构配置进行动态配置,灵活扩展架构配置包括一个存储设备对一个ppu、一个存储设备对多个ppu、多个存储设备对一个ppu和多个存储设备对多个ppu。存储设备可以被配置为包括存储器模块的存储卡。存储器模块可以是双列直插式存储器模块(dual in-line memory module,dimm)。存储器模块可以是双倍数据速率双列直插式存储器模块(double data rate dual in-line memory module,ddr dimm)。
12.在一个实施例中,本公开实施例实现了一种存储器存储通信方法。在一个示例性实施例中,该方法包括:在第一处理组件中生成存储器访问请求;从icn中的多个互连中选择互连;以及经由icn中的选定互连将存储器访问请求从第一处理组件转发到第一存储器组件。在一个实施例中,存储器访问请求包括与第一存储器组件中的位置相关联的地址,并且存储器访问请求与通过芯片互连网络(icn)的通信兼容。该通信可以与共享存储器扩展协议兼容。在一个示例性实施例中,选定互连将第一处理组件和第一存储器组件耦合。
13.在一个实施例中,第一处理组件和第一存储器组件包括在icn的第一节点中,其中第一处理组件和第一存储器组件经由第一节点中的总线彼此通信耦合,该总线不包括icn。第一存储器组件可以包括在icn的第一节点中,第二存储器组件可以包括在icn的第二节点中。除了icn之外,第一存储器组件和第二存储器组件还可以经由另一网络通信耦合。在一个示例性实施例中,icn能够动态灵活扩展用于通信耦合到icn的ppu的可用存储器资源。在一个示例性实施例中,其他网络与第一节点中的第一网络接口卡和第二节点中的第二接口卡通信耦合。在icn的第一节点中可以包括第一存储器组件和第二存储器组件,并且第一存储器组件和第二存储器组件通过共享存储器扩展协议彼此通信耦合。在推送模式下,可以将信息从第一存储器组件推送到第二存储器组件,在拉取模式下,可以将信息从第二存储器组件拉取到第一存储器组件。在一个实施例中,该方法还可以包括经由icn中包括的另一互连接收另一存储器访问请求。
14.在一个实施例中,系统包括:多个处理核、多个存储器和芯片互连网络(icn)中的多个互连。该多个处理核的第一处理核组可包括在第一芯片中。多个存储器包括作为第一芯片中的内部存储器的第一存储器组和作为外部存储器的第二存储器组。第一存储器组和第二存储器组耦合到第一处理核组。icn被配置为与多个处理核和第二存储器组通信耦合。第二存储器组可作为对第一存储器组的扩展,用于多个处理核。第二存储器组可包括存储设备,该存储设备包括:存储器模块,包括被配置为存储信息的多个存储器芯片;以及icn/smx存储器接口控制器,被配置为在存储器模块与芯片互连网络(icn)之间进行接口,芯片互连网络(icn)被配置为将多个处理核和第二存储器组通信耦合,第二存储器组能够灵活扩展可用于多个处理核的存储器资源。icn可以包括互连链路,互连链路将并行处理单元(ppu)和第二存储器组通信耦合,其中ppu包括多个处理核和第一存储器组。在一个实施例中,第二存储器组内的存储器通过共享智能存储器扩展(smx)协议进行通信。icn/共享存储器扩展(smx)控制器可以针对各种灵活扩展架构配置进行动态配置,该灵活扩展架构配置包括一个存储卡对一个ppu、一个存储卡对多个ppu、多个存储卡对一个ppu、以及多个存储卡对多个ppu。
15.本公开实施例提高了系统元件之间的存储器访问请求(例如,读请求和写请求)的传输速度和由此产生的数据传输的完成速度,因此提高了诸如神经网络和ai工作负载的应用的操作速度。
16.本领域的普通技术人员在阅读了在各附图中示出的实施例的以下详细描述后,将认识到本公开各实施例的这些和其他目的和优点。
附图说明
17.包括在本说明书中并形成本说明书的一部分的附图示出了本公开的实施例,并且
附图与详细描述一起用于解释本公开的原理。在附图中相似的数字指示相似的元件。
18.图1示出了示例性传统系统;
19.图2a示出了根据本公开实施例的示例性系统的框图;
20.图2b示出了根据本公开实施例的另一示例性系统的框图;
21.图3示出了根据本公开实施例的包括存储器扩展的示例性并行处理单元(ppu)结构的框图;
22.图4a示出了根据本公开实施例的用于灵活且可扩展的存储器结构的示例性ppu icn控制的框图;
23.图4b示出了根据本公开实施例的另一示例性的灵活且可扩展的存储器结构的框图;
24.图5示出了根据本公开实施例的示例性存储卡的框图;
25.图6示出了根据本公开实施例的示例性统一存储器寻址空间的框图;
26.图7示出了根据本公开实施例的具有多个存储卡的示例性系统的框图;
27.图8示出了根据本公开实施例的多个cpu和共享存储器扩展卡之间的示例性通信的框图;
28.图9示出了根据本公开实施例的缩放层次结构的框图;
29.图10示出了根据本公开实施例的示例性信息存储方法的框图。
具体实施方式
30.现在将详细参考本公开的各种实施例,其示例在附图中示出。尽管结合这些实施例进行描述,但应当理解,它们并不旨在将本公开限制到这些实施例。相反,本公开旨在涵盖可包括在所附权利要求所定义的本公开的精神和范围内的替代、修改和等同物。此外,在本公开的以下详细描述中,为了提供对本公开的透彻理解,阐述了许多具体细节。然而,应当理解,本公开可以在没有这些特定细节的情况下实施。在其他实例中,未详细描述公知的方法、程序、组件和电路,以避免不必要地模糊本公开的各个方面。
31.以下详细描述的某些部分以程序、逻辑块、处理和对计算机存储器中的数据比特进行的操作的其他符号表示的方式来呈现。这些描述和表示是数据处理技术领域的技术人员使用的手段,以最有效地将其工作的实质传达给本领域的其他技术人员。在本公开中,程序、逻辑块、处理等被认为是导致期望结果的步骤或指令的自洽序列。这些步骤是利用物理量的物理操作的那些步骤。通常,尽管不是必须的,这些量采取电或磁信号的形式,能够在计算系统中被存储、传输、组合、比较和以其他方式操纵。有时,主要出于常见用法的原因,已经证明将这些信号称为事务、比特、值、元件、符号、字符、样本、像素或类似物是方便的。
32.然而,应当记住,所有这些和类似的术语都是与适当的物理量相关联的,且只是应用于这些量的方便标签。除非从下面的讨论中明确指出,否则可以理解,在整个本公开中,使用诸如“访问”、“分配”、“存储”、“接收”、“发送”、“写入”、“读取”、“传送”、“加载”、“推送”、“拉取”、“处理”、“缓存”、“路由”、“确定”、“选择”、“请求”、“同步”、“复制”、“映射”、“更新”、“转换”、“生成”等术语的讨论指的是设备或计算系统或类似的电子计算设备、系统或网络(例如,图2a的系统及其组件和元件)的动作和过程(例如,图7、8、9和10的方法)。计算系统或类似的电子计算设备操纵和变换在存储器、寄存器或其他此类信息存储、传输或显
示设备中表示为物理(电子)量的数据。
33.这里描述的一些元件或实施例可以在驻留在某种形式的计算机可读存储介质上的由一个或多个计算机或其他设备执行的计算机可执行指令的一般上下文中讨论,计算机可执行指令例如是程序模块。作为示例而非限制,计算机可读存储介质可以包括非暂时性计算机存储介质和通信介质。通常,程序模块包括执行特定任务或实现特定抽象数据类型的例程、程序、对象、组件、数据结构等。在各种实施例中,程序模块的功能可以根据需要组合或分布。
34.计算机存储介质包括用于存储诸如计算机可读指令、数据结构、程序模块或其他数据的信息的任何方法或技术实现的易失性和非易失性、可移动和不可移动介质。计算机存储介质可以包括双倍数据速率(ddr)存储器、随机存取存储器(ram)、静态ram(sram)或动态ram(dram)、只读存储器(rom)、电可擦除可编程rom(eeprom)、闪存(例如,ssd)或其他存储器技术、压缩光盘rom(cd-rom)、数字多功能盘(dvd)或其他光存储器、盒式磁带、磁带、磁盘存储器或其他磁存储设备,或可用于存储所需信息且可被访问以获取信息的任何其他介质。
35.通信介质可以体现计算机可执行指令、数据结构和程序模块,且包括任何信息传递媒介。作为示例而非限制,通信介质包括诸如有线网络或直接有线连接的有线介质,以及诸如声学、射频(rf)、红外和其他无线介质的无线介质。上述任一项的组合也可以包括在计算机可读介质的范围内。
36.系统和方法被配置为高效和有效地实现存储器扩展容量。在一个实施例中,在芯片互连网络(icn)中实现灵活和可扩展的存储器方案。与传统方法相比,芯片互连网络有助于提高处理资源和外部存储器(例如,片外存储器等)之间的通信带宽和通信速度。icn可以被认为是使用高速协议的高速网络。芯片互连网络还可以有助于提高存储资源的灵活实现和利用。在一个示例性实施例中,芯片互连网络兼容并利用共享智能存储器扩展(smx)特征以促进提高存储资源的灵活实现和利用。在一个示例性实施例中,存储卡被认为是smx存储卡。
37.在一个实施例中,并行处理单元(ppu)与存储设备耦合。存储设备可以包括:存储器模块,包括被配置为存储信息的多个存储器芯片;以及icn/smx存储器接口控制器,被配置为在存储器模块和芯片互连网络(icn)之间进行接口。icn被配置为将并行处理单元ppu通信耦合到存储设备。
38.icn/smx存储器接口控制器可以是可配置的,以用于各种扩展架构。icn/smx存储器接口控制器可以针对各种灵活扩展架构配置进行动态配置,该灵活扩展架构配置包括一个存储卡对一个ppu(例如,1v1等)、一个存储卡对多个ppu(例如,1vn等)、多个存储卡对一个ppu(例如,nv1等)和多个存储卡对多个ppu(例如,nvn等)。存储器模块可以是单列直插式存储器模块(single in-line memory module,simm)。存储器模块可以是双列直插式存储器模块(dual in-line memory module,dimm)。存储器模块可以是双倍数据速率双列直插式存储器模块(double data rate dual in-line memory module,ddr dimm)。存储器模块可以包括各种类型的存储器(例如,dram、sdra、闪存,等等)。可以理解,ppu可以包括各种类型的并行处理单元,包括中央处理单元(central processing unit,cpu)、图形处理单元(graphic processing unit,gpu)、现场可编程门阵列(field programmable gate array,
fpga)等。
39.图2a是示出了根据一个实施例的示例性系统200a的框图。通常,系统200a可用于任何信息存储和处理,包括海量数据存储和并行处理。在一个实施例中,系统200a可用于神经网络和人工智能(ai)工作负载。
40.可以理解,图中所示的系统(例如,200、300、400等)可以包括除了在此所示和描述的那些元件或组件之外的元件或组件,并且元件或组件可以如图中所示或以不同的方式布置。示例系统和组件(例如,200、ppu、存储卡250等)中的一些块可以根据它们执行的功能来描述。本公开不限于将系统的元件和组件描述和绘示为单独块;也就是说,例如,块/功能的组合可以集成到执行多个功能的单个块中。在一个实施例中,系统(例如,200a等)可以被扩大以包括附加的(例如,ppu、存储卡等),并且系统与包括分层缩放(hierarchical scaling)方案和扁平缩放(flattened scaling)方案的不同缩放方案兼容。
41.通常,系统包括多个计算节点,每个计算节点包括多个并行处理单元或芯片(例如,ppu)。可以理解,本技术所提出的扩展式(extended/expanded)存储器容量与各种计算节点配置的使用兼容。在一个示例性实施例或应用场景中,计算节点类似于网络环境中的服务器。
42.系统200a包括计算节点201和存储卡250。计算节点201包括并行处理单元ppu210、2e版高带宽存储器(例如,high bandwidth memory version 2e,hbm2e)211、212、213、214、215和216。计算节点201与icn 217和219通信耦合。icn 219与存储卡250通信耦合。存储卡250包括icn/smx存储器接口控制器271和商用双倍数据速率双列直插式存储器模块(commodity ddr dimm)281、282、283和284。商用ddr dimm 281、282、283和284包括多个dram(例如,291、292、293、294、295、297、298等)。
43.在一个实施例中,icn 219和icn/smx存储器接口控制器271有助于ppu和存储器之间的通信。在一个示例性实施例中,icn 219使得存储器(dram 291、292等)与ppu 210之间能够进行高速通信。可以理解,这里提出的icn是一种新颖的通信系统,其有助于信息存储资源和处理资源之间以比传统系统和方法更快的速度和更宽的带宽进行通信。与传统系统相比,除了提供显著提高的带宽和速度之外,系统200a还提供了增加的存储器扩展和存储器使用灵活性。
44.在一个实施例中,icn 219包括通信耦合ppu 210和存储卡250的直接连接。直接连接使得处理资源(例如,ppu210等)能够比限制于较慢通信结构(例如,pcie等)的传统系统更高效和有效地访问存储器资源(例如,存储卡250等)。在一个实施例中,icn/smx存储器接口控制器可以包括smx特征和功能。在一个示例性实施例中,smx协议使得能够进行存储卡中的存储器之间的高速通信,而icn协议使得能够进行往来于存储卡的高速通信(例如,存储卡与ppu之间、多个存储卡之间等)。通信可以包括在软件和应用之间传送信息。icn和smx通信的其他细节在本说明书的其他部分中说明。
45.图2b是根据一个实施例的示例性系统200b的框图。系统200b类似于系统200a,除了系统200b具有将计算节点201通信耦合到存储卡250的icn 299。
46.图3是根据一个实施例的示例性系统300的框图。通常,系统300包括多个计算节点,并且每个计算节点包括多个并行计算单元或芯片(例如,ppu)和多个存储卡。系统300包括通信耦合到icn 350和网络340的计算节点310和计算节点370。可以理解,所提出的扩展
式存储器容量与各种计算节点配置的使用兼容。在一个示例性实施例或应用场景中,计算节点类似于网络环境中的服务器。
47.往来于存储卡之间的通信可以在命令级(例如,dma复制)和/或在指令级(例如,直接加载或存储)。icn 350允许系统300中的计算节点(例如,服务器等)和ppu在不使用网络总线(例如,pcie总线等)的情况下进行通信,从而避免其带宽限制和相对速度不足。ppu之间的通信可以包括存储器访问请求(例如,读请求和写请求)的传输和响应于这些请求的数据传输。通信可以是直接的,也可以是间接的。
48.在一个实施例中,计算节点包括ppu和存储卡。计算节点310包括通过icn 350通信耦合到存储卡311的ppu 312和通过icn 350通信耦合到存储卡317的ppu319。计算节点370包括通过icn 350通信耦合到存储卡371的ppu 377和通过icn350通信耦合到存储卡375的ppu 379。存储卡371经由icn 350通信耦合到存储卡372。可以理解,将存储卡(例如,311、317等)通信耦合到ppu的icn 350提供了比限制于通过较窄和较慢总线协议(例如,pcie等)进行通信的传统方法大得多的带宽和高得多的通信速度。与传统系统相比,除了提供显著提高的带宽和速度之外,系统300还提供增加的存储器扩展和灵活性。
49.图3的系统300包括高带宽芯片互连网络(icn)350,其允许系统300中的ppu之间的通信。在一个实施例中,系统300中的存储卡(例如,311、317、371、372、375等)和ppu(312、319、377、379等)经由icn 350通信耦合。在一个实施例中,icn包括可通信耦合组件(例如,存储卡、ppu等)的互连(例如,互连352、354、355、357等)。互连可以是直接连接。互连可以具有各种配置(例如,交换的、多个分层交换机等)。在一个实施例中,互连是将ppu直接连接到存储卡的硬连线或电缆连接。可以理解,可以有各种连接拓扑配置。在一个实施例中,互连是基于或利用串行/解串器(serial/deserializer,serdes)功能的线路或电缆。在一个实施例中,存储卡和ppu之间的icn链路或互连的数量基于存储卡的带宽。在一个示例性实施例中,icn中的链路或互连的带宽与存储卡的带宽匹配。
50.在一个实施例中,系统可以包括并利用ppu之间的通信以进一步增加总体存储器灵活性和可扩展性。在一个实施例中,计算节点310上的ppu可以通过在icn 350上彼此通信(通信耦合)且访问彼此的本地存储卡来有效地提高存储器扩展性和灵活性。在一个示例性实施例中,除了访问存储卡311,ppu 312可以经由通过icn 350和ppu 319的通信访问存储卡317。在一个实施例中,计算节点310上的ppu可以通过经由icn 350与计算节点370中的ppu通信(通信耦合)且访问彼此的本地存储卡来有效地提高存储器扩展性和灵活性。在一个示例性实施例中,除了访问存储卡311,ppu 312可以经由通过icn 350和ppu 377的通信来访问存储卡371和372。
51.可以理解,所提出的灵活可扩展存储器结构与除了icn方法之外还包括其他通信特征和功能的系统兼容。在一个实施例中,系统可以包括并利用多个通信协议以进一步提高总体存储器灵活性和可扩展性。在计算节点中的存储卡和ppu可以通过除icn之外的其他总线彼此通信。在一个实施例中,计算节点的存储卡和ppu彼此通信耦合并且计算节点的存储卡和ppu通信耦合到icn和外围组件互连高速(pcie)总线。在一个实施例中,除了icn 350之外,计算节点(例如310等)上的ppu(例如312、319等)还可以经由总线(例如381等)访问存储卡(例如311、317等)。在一个实施例中,ppu可以访问不同计算节点上的存储器。计算节点310包括主中央处理单元(cpu)391,并经由网络接口控制器或卡(nic)392连接到网络340。
计算节点370包括主中央处理单元(cpu)397,并经由网络接口控制器或卡(nic)398连接到网络340。计算节点310上的ppu可以经由总线381和382以及nic 392和398通过网络340与计算节点370上的ppu和存储卡通信。
52.在一个实施例中,ppu还可以使用包括在神经网络中的ppu来实现,或者可以称为包括在神经网络中的ppu。该ppu还可以被实现为或使用实现策略处理应用的ppu。ppu还可以包括其他功能块或组件(未示出),例如命令处理器、直接存储器访问(direct memory access,dma)块和便于与pcie总线通信的pcie块。
53.图4a是根据一个实施例的示例性系统400a的框图。系统400a包括ppu 401a和存储卡470、480和485。ppu 401a与icn 405通信耦合。存储卡470、480和485也通信耦合到icn 405。在一个实施例中,ppu访问内部或片上存储器(例如415、417、421、422等)和外部或片外存储器(例如存储卡470、480和485等)。在一个示例性实施例中,ppu通过icn与外部存储器直接通信。通常,ppu可以包括诸如处理核和内部或片上存储器的元件。ppu 401a包括与计算元件或处理核(例如,411、412、413、414等)以及高速缓存(例如415、417、418、419等)通信耦合的片上网络(network-on-a-chip,noc)410。ppu 401a还包括与noc 410通信耦合的高带宽存储器(例如,421、422、423、424等)。高速缓存和hbm可以被认为是内部或片上存储器。在一个实施例中,高速缓存是经由noc通信耦合的hbm和cpu/核之间的最后一级信息存储。计算节点可以包括其它级别的高速缓存(例如,l1、l2等)。可以(例如,在运行时)将hbm中的存储器空间声明或分配作为缓冲器(例如,乒乓缓冲器等)。
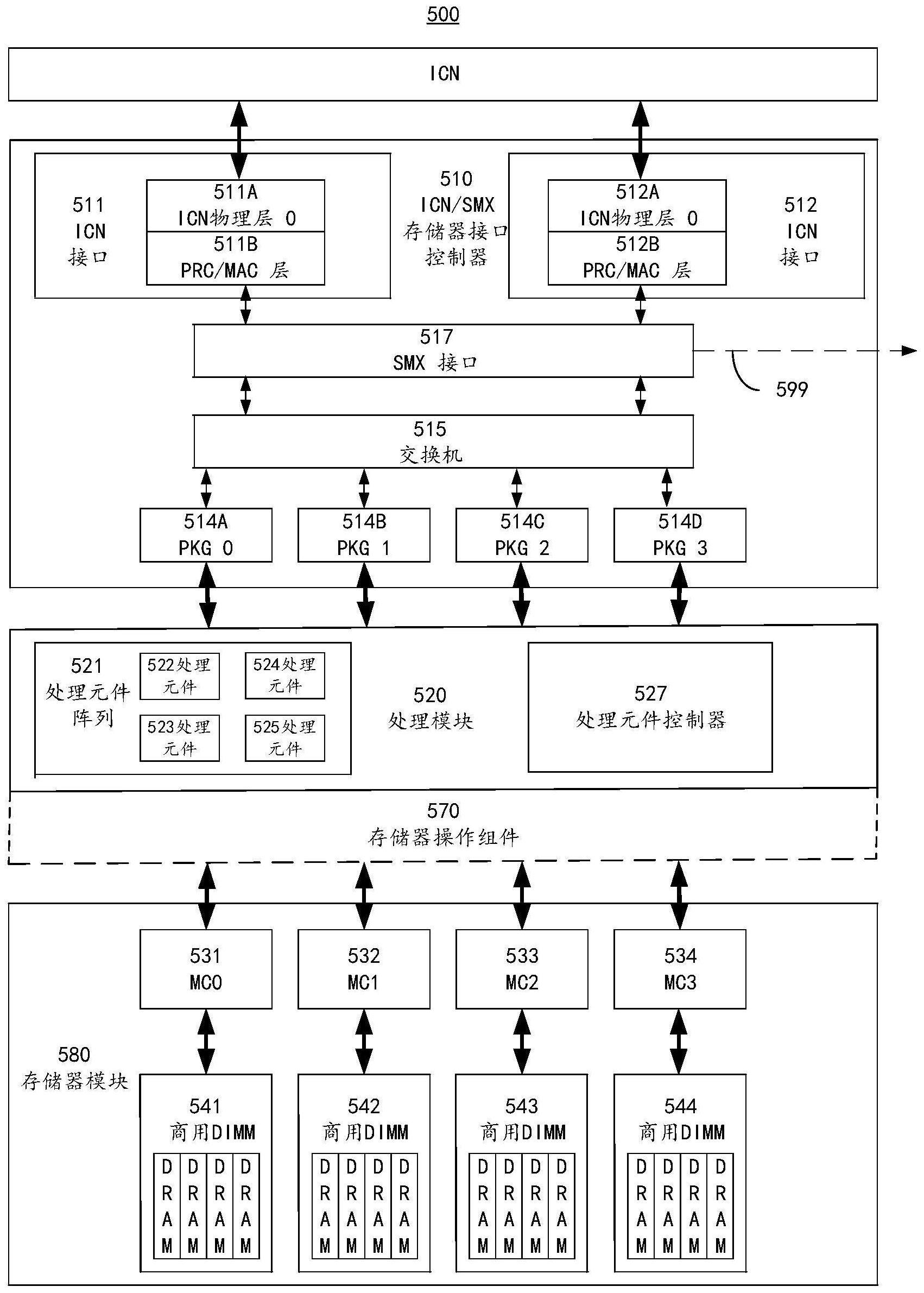
54.ppu还包括icn子系统,其处理经由icn到外部存储器和其他ppu的外部或片外通信。ppu 401a包括icn子系统430。ppu通过耦合到noc 410的icn子系统430通信耦合到icn 405。icn子系统430包括icn通信控制块(通信控制器)432、交换机433和通信间链路(inter-communication link,icl)434、435、436、437、438和439。icl可以构成或包括通信端口。在一个实施例中,icl 434、435、436、437、438和439连接到icn 405的相应互连。互连可以是直接连接。互连可以通过外部交换机设备。在一个示例性实施例中,互连491和492的一端可(分别)连接到ppu 401a上的icl(端口)437和438,而互连491和492的另一端可连接到存储卡470上的icn/smx存储器接口控制器471。存储卡470包括icn/smx存储器接口控制器471和双列直插式存储器模块(dimm)472、473、474和475。存储卡480和485类似于存储卡470,并且与ppu401a通信耦合。存储卡480经由icn405的互连493通信耦合到ppu 401a。存储卡485与另一个ppu(未示出)通信耦合。
55.在一个实施例中,ppu 401a的存储器访问请求(例如,读请求、写请求等)经由noc 410从核(例如,411、412等)发送到icn子系统430的icn通信控制块432。存储器访问请求包括标识哪个存储位置是存储器访问请求的目标的地址。icn通信控制块432使用该地址来确定哪个icl(直接或间接)连接到与该地址相关联的存储位置(例如,存储卡、存储器模块等)。然后由交换机433将存储器访问请求路由到选定icl(例如,437、438、439等),然后通过icn 405将存储器访问请求路由到与该地址相关联的存储卡(例如470、480等)。在一个示例性实施例中,存储器访问请求是对存储卡470中存储地址的请求。在接收端,在存储卡470中的icn/smx存储器接口控制器471处接收存储器访问请求。如果访问请求是写请求,则将信息转发并存储在该访问请求标识的相应dimm(例如,472、473、474、475等)中。如果存储器访问请求是读请求,则dimm中该地址处的信息被返回到ppu 401a。以这种方式,使用高带宽
icn 405快速地完成存储器访问。在一个实施例中,访问通信绕过其他通信总线(例如,pcie总线等),从而避免其他总线的带宽限制和相对速度不足。
56.可以理解,所提出的icn通信方案能够实现灵活的存储器扩展和利用。图4b是根据一个实施例的示例性系统400b的框图。系统400b类似于系统400a,除了系统400b的ppu 401b还包括icn子系统440,并且icn 450通过icn子系统440将ppu 401b通信耦合到存储卡470、480和485。icn子系统440包括icn通信控制块(通信控制器)442、交换机443和通信间链路(icl)444、445、446、447、448和449。icl可以构成或包括通信端口。在一个实施例中,icl444、445、446、447、448和449连接到icn 450的相应互连。互连可以是直接连接。在一个示例性实施例中,互连497和498的一端可(分别)连接到ppu 401b上的icl(端口)447和448,而互连497和498的另一端可连接到存储卡470上的icn/smx存储器接口控制器471。
57.在一个实施例中,icn通信控制块432包括命令调度块和指令调度块。命令调度块和指令调度块用于由ppu 401b寻址另一ppu的存储器访问请求。命令调度块用于涉及相对大数据量(例如,两兆字节或更多兆字节)的存储器访问请求。指令调度块提供更精细的控制级别,并用于涉及较小数据量(例如,小于2兆字节;例如,128或512字节)的存储器访问请求。一般来说,在一些实施例中,命令调度块处理icn读和写,指令调度块处理远程存储和远程加载,尽管本公开不限于此。来自通信命令环的命令被发送到命令调度块。来自noc 410的指令被发送到指令调度块。指令调度块可以包括远程加载/存储单元(未示出)。
58.更具体地说,当计算命令被分解并调度到一个(或多个)核(例如,411、412等)时,操作系统内核(kernel)(例如,程序或处理器指令序列等)将开始在那个核或那多个核中运行。当存在存储器访问指令时,该指令被发送到存储器。如果存储地址被确定为本地存储地址,则指令经由noc 410转到本地hbm(例如,421、422等);否则,如果存储地址被确定为外部存储地址,则指令转到指令调度块。
59.icn子系统还可以包括耦合到命令调度块和指令调度块的多个芯片到芯片(chip-to-chip,c2c)dma单元。dma单元还通过c2c结构和网络接口单元(network interface unit,niu)耦合到noc,并且dma单元还耦合到交换机(例如,433、443等),相应地,交换机耦合到与icn(例如405、450等)耦合的icl。
60.icn通信控制块432将传出的存储器访问请求映射到基于该请求中地址选择的icl(434、437等)。icn通信控制块432将存储器访问请求转发到对应于所选择的icl的dma单元。然后由交换机433将该请求从dma单元路由到所选择的icl。
61.在一个实施例中,系统400a和400b中的ppu和存储卡类似于系统200a、200b、300等中的ppu和存储卡。
62.在一个实施例中,系统(例如,200a、200b、300、400a、400b等)包括使用例如分区全局地址空间(partitioned global address space,pgas)编程模型的统一存储器寻址空间。因此,可以全局分配系统中的存储空间,使得例如ppu 210上的hbm 216可由那个计算节点(例如,201等)或服务器上的ppu访问,并且可由系统(例如,200a、200b等)中其他计算节点或服务器上的ppu访问,ppu 210可以访问系统中其他ppu/服务器上的hbm。因此,在图2a的示例中,一个ppu可以从系统200a中的另一个ppu读取数据或向系统200a中的另一个ppu写入数据,其中两个ppu可以在相同的计算节点(例如,服务器等)上或在不同的计算节点(例如,服务器等)上,并且读或写可以如上所述直接或间接地发生。
63.图5是根据一个实施例的示例性存储卡500的框图。在一个示例性实施例中,存储卡500类似于存储卡250。存储卡500包括icn/smx存储接口控制器510、处理模块520和存储器模块580。icn/smx存储器接口控制器510包括icn接口511和512、smx接口517、交换机515、包缓冲器514a至514d。icn接口511和512包括icn物理层接口(例如,511a、512a等)、prc/mac接口(例如511b、512b等)。多个包缓冲器被配置为缓冲信息包。icn物理层接口被配置为与耦合到处理元件的icn的部分耦合。相应的prc/mac接口与相应的icn物理层耦合。在一个实施例中,smx接口517被配置为实现smx通信且与icn接口511和512的部分耦合。交换机515被配置为将信息路由到多个包缓冲器(例如,514a、514b、514c和514d等)和smx接口517。
64.存储卡可以包括被配置为在存储卡上执行并行处理的处理元件阵列组件或模块(例如,520等)。在一个实施例中,处理元件阵列组件/模块包括:多个处理元件,被配置为处理信息;以及处理元件控制器,被配置为控制往来于多个处理元件的信息流。处理模块520包括处理阵列521和控制模块527。处理阵列521包括处理元件522、523、524和525。处理元件可以是专用的或定制用途的处理元件。专用的或定制用途的处理元件可以被指向特定应用处理。还应理解,处理元件可以是通用处理元件(例如,cpu、gpu等)。
65.存储器模块580包括分别通信耦合到商用dimm 541、542、543和544的存储控制器531、532、533和534。在一个实施例中,dimm包括dram。可以理解,可以使用各种类型的存储器(例如,ram、dram、flash等)并且各种类型的存储器可以与不同的标准和协议(例如ddr4、ddr5等)兼容。
66.在一个实施例中,存储卡500还可以包括存储器操作组件570。存储器操作组件570可以执行针对存储器操作的各种功能。这些功能可以与流控制、可靠性特性、适用性特性、纠错代码功能、日志特征等相关联。存储器操作组件570可以包括高速缓存以协助处理或避免延迟问题。
67.在一个实施例中,smx接口517还可以与具有不同于icn的通信配置和协议的通信链路通信耦合。smx接口可以与smx设备通信兼容的其他非ppu设备通信。在一个示例性实施例中,smx接口可以经由可选的通信链路599通信耦合到其他smx兼容的非ppu设备。
68.在一个实施例中,在没有smx特征的情况下实现存储卡和icn/smx存储器接口控制器。存储卡可以通过icn和ppu通信耦合到另一存储卡。
69.图6是根据一个实施例的示例性统一存储器寻址空间600的框图。统一存储器寻址空间600能够实现分区全局地址空间(pgas)类型的编程模型。程序(program)之间的通信在不同的级别上流动。在命令级中,通信可以包括直接存储器访问(dma)复制操作。在指令级中,通信可以包括直接加载/存储操作。可以在物理存储器hbm2e 610、物理存储器hbm2e 620、物理存储卡640和物理存储卡650的部分上实现统一存储器寻址空间。在一个实施例中,物理存储器hbm2e610包括在ppu_a601中,物理存储器hbm2e620包括在ppu_b602中,并且物理存储卡650经由icn通信耦合到ppu_c605。在一个实施例中,运行在ppu_b上的进程可以从物理存储器620读取(由运行在ppu_a上的进程写入的)信息var a,并且还可以从物理存储卡650读取(由运行在ppu_c上的进程写入的)信息var b。因此,处理组件(例如,ppu等)可以快速和方便地访问存储在各种存储器组件(例如,hbm2e、存储卡等)中的信息,这些存储器组件可以在灵活和可扩展的结构中动态地配置。
70.应当理解的是,所提出的smx/icn方法与各种系统配置兼容。图7是根据一个实施
例的具有多个存储卡的示例性系统700的框图。系统700包括计算节点(例如,服务器等)710和存储卡731、732、733、734、737、738和739。在一个示例性实施例中,存储卡731、732、733、734、737、738和739类似于存储卡600。
71.图8是根据一个实施例的多个ppu和共享存储器扩展卡之间的示例性系统800通信的框图。系统800包括存储卡850和ppu810、820和830。ppu 810经由icn链路/互连879通信地耦合ppu 820。ppu820经由icn链路/互连878通信耦合到ppu830。ppu830经由icn链路/互连877通信耦合到ppu810。ppu 830经由icn链路/互连872通信耦合到存储卡850。ppu820经由icn链路/互连871通信耦合到存储卡850。ppu810经由icn链路/互连873和874通信耦合到存储卡850。ppu和存储卡之间的多个icn链路/互连(例如873、874等)实现了较大的带宽(例如双倍单链路、三倍单链路等)。
72.图9是根据一个实施例的缩放层次结构900的框图。在一个示例性实施例中,缩放层次结构包括多个ppu和相应的存储器(未示出)之间的通信,多个ppu和相应的存储器在灵活和可扩展的结构中经由icn通信耦合。系统900包括ppu 901,902、903、904、905、911、913、914、915、916、917、921、922、923、924、925、931、932、933、934、935、942、943、947、948、949、951、952、952、953、954、955、957和959。系统900还包括存储卡971、972、973、974、975、977、978、981、982、983、984、987、988和989。单个存储卡可以通信耦合到ppu(例如,通信耦合到ppu 911的存储卡974,等等)。多个存储卡可以通信耦合到ppu(例如,通信耦合到ppu952的存储卡988和989,等等)。可以理解,组件到icn可以有各种耦合配置,包括一个存储卡对一个ppu(例如,1v1等)、一个存储卡对多个ppu(例如,1vn等)、多个存储卡对一个ppu(例如,nv1等)、多个存储卡对多个ppu(例如,nvn等),等等。
73.在一个实施例中,这里描述的系统和组件(例如200、ppu、存储卡250等)是用于实现诸如本公开的那些方法的系统和组件的示例。
74.图10是根据一个实施例的示例性信息存储方法的框图。
75.在框1010中,在第一处理组件中生成存储器通信请求。在一个实施例中,存储器通信请求包括与第一存储器组件中的存储位置相关联的地址,并且存储器通信请求与通过芯片互连网络(icn)的通信兼容。
76.在框1020中,从icn中包括的多个互连中选择互连。在一个示例性实施例中,选定互连将第一处理组件和第一存储器组件耦合在一起。在一个实施例中,第一处理组件和第一存储器组件包括在icn的第一节点中,其中第一处理组件和第一存储器组件还通过包括在第一节点中的总线彼此通信耦合,并且总线不包括icn。第一存储器组件可以包括在icn的第一节点中,第二存储器组件可以包括在icn的第二节点中。第一存储器组件和第二存储器组件可以与icn通信耦合。除了icn之外,第一存储器组件和第二存储器组件还可以经由另一网络通信耦合。icn能够对通信耦合到icn的ppu的可用存储器资源进行动态、灵活的扩展。在一个示例性实施例中,另一网络与包括在第一节点中的第一网络接口卡和包括在第二节点中的第二接口卡通信耦合。在一个实施例中,第一存储器组件和第二存储器组件包括在icn的第一节点中,并且第一存储器组件和第二存储器组件通过共享存储器扩展(shared memory extension,smx)协议彼此通信耦合。
77.在框1030中,经由icn中包括的选定互连将存储器通信请求从第一处理组件转发到第一存储器组件。可以在推送模式下,将信息从第一存储器组件推送到第二存储器组件,
并且可以在拉取模式下,将信息从第二存储器组件拉取到第一存储器组件。
78.在一个实施例中,该方法还可以包括经由icn中包括的另一互连接收附加信息。
79.在一个实施例中,在共享存储器扩展smx结构中实现icn。本公开所提出的高速互连接口(例如,ppu icn协议)可用于扩展(extend/expand)ppu(例如,gpu、cpu等)高速存储器,并提供大容量和高灵活性的ppu存储器解决方案。在一个示例性实施例中,icn与hbm ddr5统一寻址(统一存储器空间)、字节可寻址/存储器语义数据读取和基于区域的存储器管理兼容。所提出的icn提供了很大的灵活性(例如,对ppu扩展内存池(memory pooling)的灵活支持,灵活且可匹配的存储器/计算资源配给等)。在一个实施例中,具有smx接口的icn能够集成长路径计算和图计算加速模块。icn可以与pcie板形式的实现(pcie board form realization)兼容。具有smx接口的icn可以被认为是一种高速存储器扩展结构。在一个示例性实施例中,通信模块互连解决方案是基于高速的以ip为基础的串行/解串器的icn(serdes ip-based icn)。存储器可以包括计算模块(例如,控制逻辑 算术位置等)和存储模块。在一个示例性实施例中,该方法与ddr/scm控制单元兼容。
80.本公开所提出的系统实现了高效和有效的网络通信。在一个实施例中,存储设备包括:存储器模块,包括被配置为存储信息的多个存储芯片;以及芯片互连网络(icn)/共享智能存储器扩展(smx)存储器接口控制器(icn/smx存储器接口控制器),被配置为在存储器模块和芯片互连网络(icn)之间进行接口,其中icn被配置为将存储设备通信耦合到并行处理单元(ppu)。在一个示例性实施例中,icn/smx存储器接口控制器包括icn接口、共享智能存储器扩展(smx)接口、多个包缓冲器和交换机。icn接口被配置为与icn通信耦合。共享智能存储器扩展(smx)接口被配置为与icn接口通信耦合。多个包缓冲器被配置为缓冲来自smx接口的信息包。交换机被配置为将多个包缓冲器通信耦合到smx接口,并将信息路由到多个包缓冲器和从多个包缓冲器路由信息。
81.可以理解,icn/smx存储器接口控制器可以灵活扩展可用于处理资源的存储器资源。在一个实施例中,icn/smx存储器接口控制器和icn可以直接通信连接存储设备和ppu,其中直接连接可以灵活扩展ppu对存储器模块的访问。icn/smx存储器接口控制器和icn可以实现存储设备和ppu之间的通信耦合,该通信耦合总体上比存储设备和ppu之间的其他通信总线更快。在一个示例性实施例中,直接连接可以灵活扩展ppu和另一ppu对存储器模块的访问。
82.存储设备可以包括被配置为在存储设备上执行并行处理的处理元件阵列组件。在一个实施例中,处理元件阵列组件包括:多个处理元件,被配置为处理信息;以及处理元件控制器,被配置为控制进出多个处理元件的信息流。在一个示例性实施例中,处理元件阵列组件处理与加速图形处理相关联的信息。
83.可以理解的是,存储设备可以与各种存储器配置兼容。icn/smx存储器接口控制器可针对各种灵活的扩展架构配置进行动态配置,灵活扩展架构配置可以包括一个存储设备对一个ppu、一个存储设备对多个ppu、多个存储设备对一个ppu和多个存储设备对多个ppu。存储设备可以被配置为包括存储器模块的存储卡。存储器模块可以是双列直插式存储器模块(dimm)。存储器模块可以是双倍数据速率双列直插式存储器模块(ddr dimm)。
84.在一个实施例中,本公开提供了一种信息存储或存储器存储通信方法。在一个示例性实施例中,该方法包括:在第一处理组件中生成存储器访问请求;从icn中包括的多个
互连中选择互连;以及经由icn中包括的选定互连将存储器访问请求从第一处理组件转发到第一存储器组件。在一个实施例中,存储器访问请求包括与第一存储器组件中的位置相关联的地址,并且存储器访问请求与通过芯片互连网络(icn)的通信兼容。该通信可以与共享存储器扩展协议兼容。在一个示例性实施例中,选定互连将第一处理组件和第一存储器组件耦合在一起。
85.在一个实施例中,第一处理组件和第一存储器组件包括在icn的第一节点中,其中第一处理组件和第一存储器组件经由包括在第一节点中的总线彼此通信耦合,总线不包括icn。第一存储器组件可以包括在icn的第一节点中,第二存储器组件可以包括在icn的第二节点中。除了icn之外,第一存储器组件和第二存储器组件还可以经由另一网络通信耦合。在一个示例性实施例中,icn可以动态灵活扩展用于通信耦合到icn的ppu的可用存储器资源。在一个示例性实施例中,另一网络与包括在第一节点中的第一网络接口卡和包括在第二节点中的第二接口卡通信耦合。第一存储器组件和第二存储器组件可以包括在icn的第一节点中,并且第一存储器组件和第二存储器组件通过共享存储器扩展协议彼此通信耦合。可以在推送模式下,将信息从第一存储器组件推送到第二存储器组件,并且可以在拉取模式下,将信息从第二存储器组件拉取到第一存储器组件。在一个实施例中,该方法还可以包括经由icn中包括的另一互连接收另一存储器访问请求。
86.在一个实施例中,系统包括:多个处理核、多个存储器和芯片互连网络(icn)中的多个互连。多个处理核的第一处理核组可以包括在第一芯片中。多个存储器包括作为第一芯片中的内部存储器的第一存储器组和作为外部存储器的第二存储器组。第一存储器组和第二存储器组耦合到多个处理核的第一处理核组。icn被配置为将多个处理核和第二存储器组通信耦合。第二存储器组作为第一存储器组的扩展,可用于多个处理核。第二存储器组可包括存储设备,存储设备包括:存储器模块,包括被配置为存储信息的多个存储器芯片,以及icn/smx存储器接口控制器,被配置为在存储器模块和芯片互连网络(icn)之间进行接口,芯片互连网络(icn)被配置为将多个处理核和第二存储器组通信耦合,从而能够灵活扩展可用于多个处理核的存储器资源。icn可以包括将并行处理单元(ppu)和第二存储器组通信耦合的互连链路,其中ppu包括多个处理核和第一存储器组。在一个实施例中,第二存储器组内的存储器通过共享智能存储器扩展(smx)协议进行通信。在一个示例性实施例中,第二存储器组经由icn通信耦合到多个处理核的第二处理核组,并且第二存储器组和icn能够灵活扩展可用于多个处理核的第二处理核组的存储器资源。icn/共享存储器扩展(smx)控制器可以针对各种灵活扩展架构配置进行动态配置,扩展架构配置可以包括一个存储卡对一个ppu、一个存储卡对多个ppu、多个存储卡对一个ppu,以及多个存储卡对多个ppu。
87.在一个示例性应用中,本公开的实施例改善了对通用计算系统以及诸如在这种计算系统上执行的例如神经网络和ai工作负载的应用的功能。更具体地说,根据本公开的实施例提供的方法、编程模型和系统,该方法、编程模型和系统可通过提高系统元件之间的存储器访问请求(例如,读请求和写请求)的传输速度和由此产生的数据传输的完成速度来提高诸如神经网络和ai工作负载的应用的操作速度。
88.尽管前述公开使用特定的框图、流程图和示例阐述了各种实施例,但这里描述和/或示出的每个框图组件、流程图步骤、操作、和/或组件可以使用广泛的配置单独和/或集体地实现。此外,任何包含在其他组件中的组件的公开都应该被视为示例,因为可以实现许多
其他结构来实现相同的功能。
89.尽管已经用特定于结构特征和/或方法动作的语言描述了主题,但应当理解,在本公开中定义的主题不一定限于上述特定特征或动作。相反,上述的特定特征和动作被公开作为实现本公开的示例形式。
90.因此,以上描述了根据本公开的实施例。虽然在特定实施例中描述了本公开,但本公开不应被解释为受这些实施例的限制,而是根据上面的权利要求来解释。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。