1.本发明涉及油气储层评价技术领域,具体是关于一种基于煤层气井排采曲线特征参数的产能分类方法及装置。
背景技术:
2.煤层气是一种清洁能源且我国资源量大,煤层气的勘探与开发对满足经济社会发展日益增长的低碳能源需求具有重要意义。煤层气产能分类结果可以指导煤层气井开采。如何对煤层气井进行科学地产能分类,对认识煤层气井产能级别,制定不同开采方式、提高煤层气井产量都具有重要作用。
3.目前,对煤层气井产能评价主要通过确定影响煤层气产能的主控因素(储层的裂隙等重要参数),据此建立相应的煤层气产能潜力数学指标实现产气井的产能能力评级。如cn112987106a提供了一种基于微地震静态监测的煤层气井产能潜力评价方法,包括选取高精度四维三分量微地震监测仪;制定研究区微地震监测方案;对高精度四维三分量微地震监测仪采集到的微地震信号进行分析处理,解释目标层的关键参数,所述关键参数包括裂隙数量、裂隙尺度、裂隙地质力学属性和裂隙密度;对不同性质的裂隙进行权重赋值,计算单位面积的煤层气井产气潜力因子。cn102830442a提供了一种预测预报煤层气产能的潜力系数评价方法,包括在煤层气井产气机理分析基础上确定主控因素;应用gis强大的数据管理和空间分析功能,建立各主控因素的子专题图;应用ann确定各主控因素对产能的权重贡献;建立基于ann与gis耦合的煤层气产能潜力系数评价模型,进行煤层气产能潜力系数分区及评价。
4.然而,上述方法要么所需要的条件严苛,某些参数的获取成本高,推广性不强,要么分类参数指标少,不能全面反映煤层气井产能特征,因此,在层气发展愈发迅速的情况下,亟需一种可以简单快速、解释性强且能广泛推广的方法对煤层气井产能级别进行正确分类。
技术实现要素:
5.针对上述问题,本发明的目的是提供一种基于煤层气井排采曲线特征参数的产能分类方法及装置,能够基于煤层气井的排采曲线特征参数,通过无监督学习方法(k-means聚类)实现一种简单、可解释强、可推广性强的确定煤层气井产能级别分类的方法,该方法对正确认识煤层气井产能、提高煤层气井开采效益具有重要作用。
6.为实现上述目的,本发明采取以下技术方案:
7.本发明所述的基于煤层气井排采曲线特征参数的产能分类方法,包括如下步骤:
8.获取区块待评价井的排采曲线特征参数;
9.根据排采曲线特征参数确定有效的排采井数据集,保证所选排采井为正常产气井,能达到稳定的排采状态,拥有完整的排采周期;
10.从排采曲线特征参数中分析获取影响产能的主控排采曲线特征参数,通过遍历法
聚类,从聚类结果的有效性和泛化性两方面确定最佳的聚类特征参数及聚类模型;
11.使用sklearn库中的tsne模块实现聚类结果降维显示,以二维平面图展示各聚类类别,其中,降维方式选择经典的pca降维;
12.绘制各聚类类别的排采特征的概率密度图,并通过聚类结果相对应的排采特征的概率密度图来说明各聚类类别的实际解释意义,其中,实际解释意义为:将三类聚类结果赋予实际生产中高产、中产和地产的级别分类。
13.所述的产能分类方法,优选地,所述排采曲线特征参数包括:是否产气、目前日历排采时间、当前平均有效日产气、高峰套压、见气井底流压、高峰前平均有效日产气、90天日产气、有效见套压时间以及见套压前平均有效日产水。
14.所述的产能分类方法,优选地,所述获取区块待评价井的排采曲线特征参数的方式为:通过实际排采数据绘制排采图,并通过ofm工具获取。
15.所述的产能分类方法,优选地,所述分析产能主控排采曲线特征参数,通过遍历法聚类,从聚类结果的有效性和泛化性两方面确定最佳的聚类特征参数及聚类模型具体包括如下步骤:
16.基于原理性分析,认为对产能评价影响较大的主控排采曲线特征参数为:高峰套压、见气井底流压、高峰前平均有效日产气、90天日产气、有效见套压时间、见套压前平均有效日产水、当前平均有效日产气;
17.以对产能评价影响较大的排采曲线特征参数作为特征的输入,使用python的sklearn库中的kmeans模块进行聚类建模;
18.基于对产能评价影响较大的排采曲线特征参数,使用k-means方法遍历上述输入特征的所有组合建模,以轮廓距离为模型评价指标,轮廓距离仅表征聚类质量,其中,达到预设值即为聚类质量良好。
19.本发明还提供一种基于煤层气井排采曲线特征参数的产能分类装置,包括:
20.第一处理单元,用于获取区块待评价井的排采曲线特征参数;
21.第二处理单元,用于根据排采曲线特征参数确定有效的排采井数据集,保证所选排采井为正常产气井,能达到稳定的排采状态,拥有完整的排采周期;
22.第三处理单元,用于从排采曲线特征参数中分析获取影响产能的主控排采曲线特征参数,通过遍历法聚类,从聚类结果的有效性和泛化性两方面确定最佳的聚类特征参数及聚类模型;
23.第四处理单元,用于聚类结果可视化:使用sklearn库中的tsne模块实现聚类结果降维显示,以二维平面图展示各聚类类别,其中,降维方式选择经典的pca降维;
24.第五处理单元,用于模型评价:绘制各聚类类别的排采特征的概率密度图,并通过聚类结果相对应的排采特征的概率密度图来说明各聚类类别的实际解释意义,其中,实际解释意义为:将三类聚类结果赋予实际生产中高产、中产和地产的级别分类。
25.本发明还提供一种计算机存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述的基于煤层气井排采曲线特征参数的产能分类方法步骤。
26.本发明还提供一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述基于煤层气井排采曲线特征参数的产能分类方法步骤。
27.本发明由于采取以上技术方案,其具有以下优点:
28.本发明实现了煤层气产能级别的有效分类,具有简单方便、可解释性强和推广性强的特点,能对煤层气井产能级别进行科学合理划分,对正确认识煤层气井产能、提高煤层气井开采效益具有重要作用;
29.本发明已在沁水盆地柿庄南区块255口有效排采井上实现,聚类效果良好,且各类别井特征明显,与实际生产中的高效益、中效益、低效益井相吻合。
附图说明
30.通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本发明的限制。在整个附图中,用相同的附图标记表示相同的部件。在附图中:
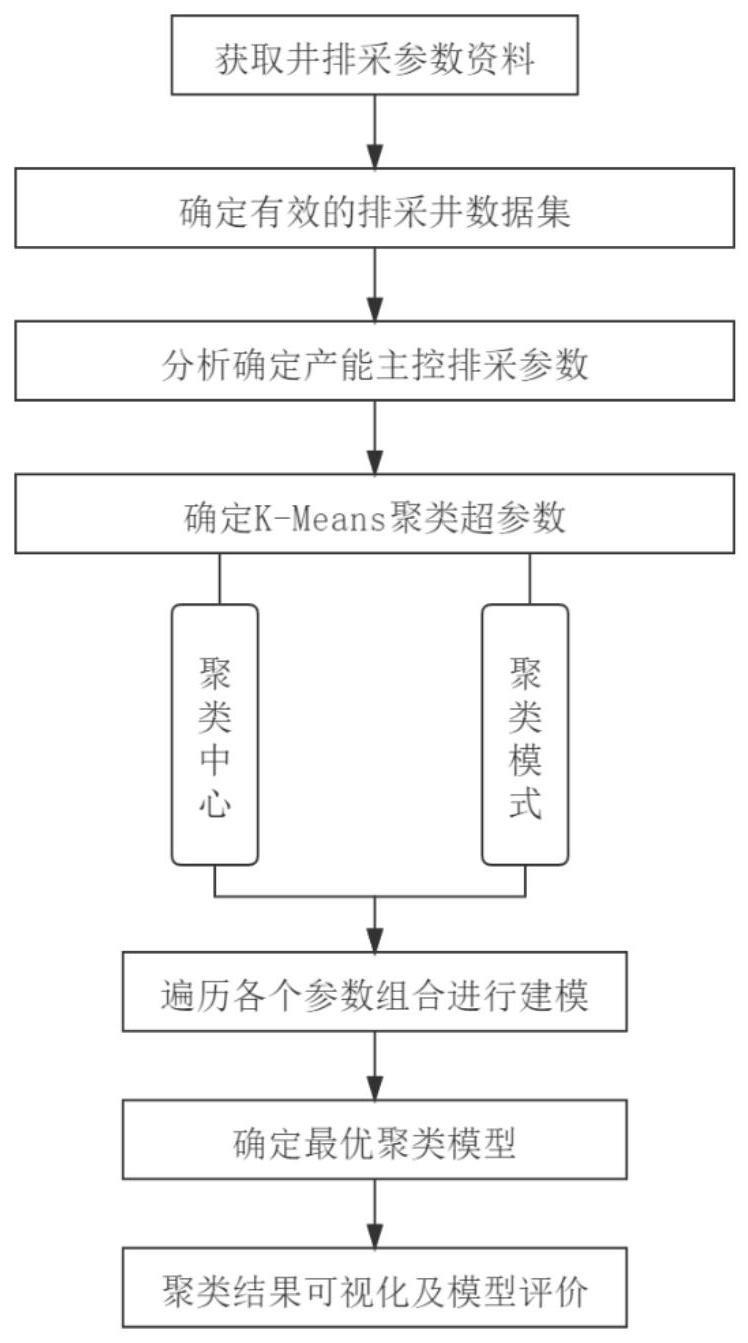
31.图1是本发明的工作流程框图;
32.图2是本发明的聚类结果二维可视化图;
33.图3是本发明的聚类ⅰ井各参数概率密度图;
34.图4为本发明的聚类ⅱ井各参数概率密度图;
35.图5为本发明的聚类ⅲ井各参数概率密度图。
具体实施方式
36.下面将参照附图更详细地描述本发明的示例性实施方式。虽然附图中显示了本发明的示例性实施方式,然而应当理解,可以以各种形式实现本发明而不应被这里阐述的实施方式所限制。相反,提供这些实施方式是为了能够更透彻地理解本发明,并且能够将本发明的范围完整的传达给本领域的技术人员。
37.本发明提供一种基于煤层气井排采曲线特征参数的产能分类方法,基于排采曲线特征参数的无监督学习的k-means聚类方法实现了煤层气产能级别的有效分类,具有简单方便、可解释性强和推广性的特点,能为煤层气产能建模前的产能级别分类提供有力支持,有利于机器学习或深度学习等在煤层气产能评价上的应用。
38.如图1所示,本发明提供的基于煤层气井排采曲线特征参数的产能分类方法,包括如下步骤:
39.1)获取区块待评价井的排采曲线特征参数:
40.(1)排采曲线特征参数主要包括是否产气、目前日历排采时间、当前平均有效日产气、高峰套压、见气井底流压、高峰前平均有效日产气、90天日产气、有效见套压时间、见套压前平均有效日产水等;
41.(2)排采曲线特征参数获取通过实际排采数据绘制成的排采图,并用ofm工具完成。在提取过程中,考虑到某些排采异常数据带来的不利影响,使用了更为合理的方式,如表征某井产气峰值的参数为高峰产气,但是部分井会出现突变的异常高值,这种异常点不能作为峰值产气水平,所以提取数据时只依据最高值显然不合理。故针对此情况,提取另一个参数——90天日产气,为高峰产气往后共90天的产气均值,此参数本质上表征产气高峰,有效避免突变值带来的影响。
42.2)根据排采曲线特征参数确定有效的排采井数据集,保证所选排采井为正常产气
井,能达到稳定的排采状态,拥有完整的排采周期;
43.主要依据是否产气和目前日历排采时间两个参数,筛选能产气且目前日历排采时间达到1000天的井;另外,对于异常井或部分能产气但是产气量非常小的井(排采图上显示为小段低产)予以剔除,这些井参与聚类井没有意义。
44.3)从排采曲线特征参数中分析获取影响产能的主控排采曲线特征参数,通过遍历法聚类,从聚类结果的有效性和泛化性两方面确定最佳的聚类特征参数及聚类模型,具体包括如下步骤:
45.(1)基于原理性分析,认为对产能评价影响较大的主控排采曲线特征参数主要为:高峰套压、见气井底流压、高峰前平均有效日产气、90天日产气、有效见套压时间、见套压前平均有效日产水、当前平均有效日产气等7个参数;
46.(2)以对产能评价影响较大的排采曲线特征参数作为特征输入,使用python的sklearn库中的kmeans模块进行聚类建模,超参数主要为聚类中心个数和聚类模式,考虑到实际中对产能的评级一般为高效益、中效益、低效益井三类,所以聚类中心选定为3个,聚类模式选择基于k-means改进的k-means 方法,k-means 相较于k-means能最大化聚类中心的距离,能降低聚类结果的相对误差。
47.(3)基于对产能评价影响较大的排采曲线特征参数,使用k-means方法遍历1到7个输入特征的所有组合建模,以轮廓距离为模型评价指标,轮廓距离仅表征聚类质量,理论上达到0.4即为聚类质量良好。得到所有组合情况下的聚类效果,结果表明参与聚类的特征曲线在3条以下时,聚类质量非常好,但是最终的聚类结果极不均衡,可解释性差;参与聚类的特征曲线在5条以上时,聚类质量较差。在实际应用中,不仅要考虑聚类质量,还要考虑参数综合可解释性,参与聚类曲线较少时聚类效果虽好,但是信息利用不充分,导致聚类结果极不均衡,呈现类似于回归中“过拟合”的效果,而参与聚类的曲线达到6条或7条时,轮廓距离呈现下降的趋势,达不到良好的聚类质量,呈现类似于回归中“欠拟合”的效果。故考虑到聚类模型的有效性(轮廓距离)和泛化性,参与聚类建模的参数不能过多也不能过少,最终选择5条曲线的特征组合模型,具体的排采特征曲线为:90天日产气、高峰前平均有效日产气、有效见套压时间、见套压前平均有效日产水、当前平均有效日产气,此聚类模型轮廓距离可达到0.52,满足聚类效果且信息利用比较充分,三类井数相对较为均衡。
48.4)聚类结果可视化:
49.为使聚类结果更加直观,建模最后使用了sklearn库中的tsne模块实现聚类结果降维显示,以二维平面图展示,降维方式选择经典的pca降维,具体结果见图2。可见三类井聚类中心区别明显,聚类结果效果良好;而且在本区块中等效应的井较多的情况下,聚类结果呈现某一类占比较多但没有表现极不均衡的情况,说明此聚类模型充分利用了排采特征信息,符合实际区块排采井分布情况,实际解释意义将在下节详细说明。
50.5)模型评价:绘制各聚类类别的排采特征的概率密度图,并通过聚类结果相对应的排采特征的概率密度图来说明各聚类类别的实际解释意义,其中,实际解释意义为:将三类聚类结果赋予实际生产中高产、中产和地产的级别分类。
51.无监督聚类得到的结果本质上没有实际表征意义,它仅仅通过输入特征实现了最大程度的类别区分,无法直接表征实际生产井中的产能级别。为此绘制了三类井的排采特征各参数概率密度图,具体结果见图3、图4、图5。
52.由图3可见聚类ⅰ井90天日产气、当前平均有效日产气和高峰前平均有效日产气均为高值分布,见套压前平均有效日产水和有效见套压时间均为低值分布,说明此类井产气快且产量大、水量少,此为高效益井。
53.由图4可见聚类ⅱ井90天日产气、当前平均有效日产气、高峰前平均有效日产气、见套压前平均有效日产水和有效见套压时间均处于总体的中等水平值分布,此为中效益井。
54.由图5可见聚类ⅲ井90天日产气、当前平均有效日产气和高峰前平均有效日产气均为低值分布,见套压前平均有效日产水和有效见套压时间均为相对中高值分布,说明此类井产气慢且产量小、水量多,此为低效益井。
55.本发明还提供一种基于煤层气井排采曲线特征参数的产能分类装置,包括:
56.第一处理单元,用于获取区块待评价井的排采曲线特征参数;
57.第二处理单元,用于根据排采曲线特征参数确定有效的排采井数据集,保证所选排采井为正常产气井,能达到稳定的排采状态,拥有完整的排采周期;
58.第三处理单元,用于从排采曲线特征参数中分析获取影响产能的主控排采曲线特征参数,通过遍历法聚类,从聚类结果的有效性和泛化性两方面确定最佳的聚类特征参数及聚类模型;
59.第四处理单元,用于聚类结果可视化:使用sklearn库中的tsne模块实现聚类结果降维显示,以二维平面图展示各聚类类别,其中,降维方式选择经典的pca降维;
60.第五处理单元,用于模型评价:绘制各聚类类别的排采特征的概率密度图,并通过聚类结果相对应的排采特征的概率密度图来说明各聚类类别的实际解释意义,其中,实际解释意义为:将三类聚类结果赋予实际生产中高产、中产和地产的级别分类。
61.本发明还提供一种计算机存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述的基于煤层气井排采曲线特征参数的产能分类方法步骤。
62.本发明还提供一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述基于煤层气井排采曲线特征参数的产能分类方法步骤。
63.最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。