1.本发明涉及数据处理技术领域,具体涉及一种网络信息的数据安全防护方法。
背景技术:
2.网络信息数据安全是当前互联网时代中的一个非常重要的问题,随着互联网的不断发展,网络安全问题也越来越突出,数据安全防护技术是保障网络安全的重要手段之一。数据压缩可以减少数据的大小,从而提高加密和解密的效率。加密算法通常需要处理大量的数据,如果数据量庞大,会增加计算和传输的时间和资源消耗。通过对数据进行压缩,可以减少数据量,从而提高加密和解密的效率。
3.然而在网络信息数据的数据中,存在许多不同种类的字符,而这些不同种类的字符会使传统的lzw压缩算法中的字典的大小非常大,从而占用大量的内存,导致网络信息数据得不到良好的压缩。
4.本发明根据字符分布区间和频率更新lzw中的字典尽可能将具有重复模式概率较高的字符串存入lzw中的字典,动态调整lzw中的字典,使其涵括尽可能多的重复模式,且不存入低频短字符串从而减小lzw中的字典大小,从而达到更好的压缩效果。
技术实现要素:
5.本发明提供一种网络信息的数据安全防护方法,以解决现有的问题。
6.本发明的一种网络信息的数据安全防护方法采用如下技术方案:本发明一个实施例提供了一种网络信息的数据安全防护方法,该方法包括以下步骤:获取网络信息数据,所述网络信息数据由若干种字符组成;根据网络信息数据中各种字符数量的占比,获取数据中各种字符的优先级参数;根据各种字符之间在数据中的位置,获取各种字符的中心字符位置;根据各种字符之间在数据中的分布,获取各种字符的离散程度;根据各种字符的中心字符位置与各种字符的离散程度,获取任意两种字符所组成的字符段的概率参数;根据数据中各种字符的优先级参数和字符所组成的字符段的概率参数,获取字符段优先级参数;根据字符段的优先级,调整lzw压缩算法中的字典的字符段编码,使用调整后的lzw压缩算法中的字典对网络信息数据进行压缩,得到网络信息数据的压缩结果;对网络信息数据的压缩结果采用aes算法进行加密。
7.优选的,所述获取数据中各种字符的优先级参数,包括的具体步骤如下:以各种字符在数据的占比作为各种字符的优先级,得到各种字符的优先级并记为,其中表示第种字符的优先级。
8.优选的,所述获取各种字符的中心字符位置,包括的具体步骤如下:首先将每种字符从数据中提取出来,统计提取出的所有字符两两间在数据中的距
离,然后计算所提取的字符中第一个字符与其他所提取的字符之间的距离和,并记为第一距离和,同时将第一个字符记为第一距离和的起始字符;计算所提取的字符中第二个字符与其他所提取的字符之间的距离和,并记为第二距离和,同时将第二个字符记为第二距离和的起始字符;计算所提取的字符中第三个字符与其他所提取的字符之间的距离和,并记为第三距离和,同时将第三个字符记为第三距离和的起始字符;以此类推,直至获得所有提取的字符与其他所提取的字符之间的距离和;取所有距离和中最小的距离和中的起始字符作为所提取字符的中心点字符,并将各种字符的中心点字符在数据中的位置记为,其中表示第种字符的中心点字符在数据中的位置。
9.优选的,所述获取各种字符的离散程度,包括的具体步骤如下:将每种字符在数据中的位置的标准差作为每种字符在数据中的离散程度记为,其中表示第种字符的离散程度。
10.优选的,所述获取任意两种字符所组成的字符段的概率参数,包括的具体计算公式如下:式中,为第种字符与第种字符所组成的字符段的概率参数;与分别为第种字符与第种字符的中心点字符在数据中的位置;与分别为第种字符与第种字符在数据中的离散程度。
11.优选的,所述获取字符段优先级参数,包括的具体计算公式如下:式中,为长度的特定字符段的优先级,为在长度的特定字符段中前个字符优先级的累乘积,为在长度的特定字符段中第个字符的优先级,为在长度的特定字符段中第一个字符与第二个字符所组成字符段的概率参数,为在长度的特定字符段中第个字符的中心字符的位置,为在长度的特定字符段中前个字符中各个字符的中心字符位置的均值,为在长度的特定字符段中第字符在数据中的离散程度,为在长度的特定字符段中前个字符中各个字符在数据中的离散程度的均值。
12.优选的,所述调整lzw压缩算法中的字典的字符段编码,包括的具体步骤如下:
通过预设一个可信的阈值,当特定字符段的优先级大于所设置阈值时,将的字符段存入lzw压缩算法中的字典,反之则不将字符段存入lzw压缩算法中的字典。
13.本发明的技术方案的有益效果是:由于在网络信息数据的数据中,存在许多不同种类的字符,而这些不同种类的字符会使传统的lzw压缩算法中的字典的大小非常大,从而占用大量的内存,导致网络信息数据得不到良好的压缩。
14.本发明根据字符分布区间和频率更新lzw压缩算法中的字典尽可能将具有重复模式概率较高的字符串存入lzw中的字典,动态调整lzw中的字典,使其涵括尽可能多的重复模式,且不存入低频短字符串从而减小lzw中的字典大小,从而达到更好的压缩效果。
附图说明
15.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
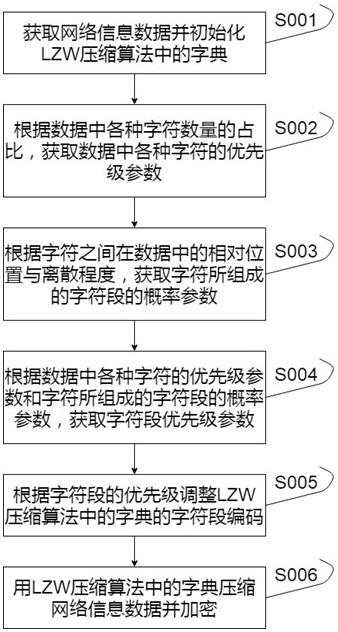
16.图1为本发明一种网络信息的数据安全防护方法的步骤流程图。
具体实施方式
17.为了更进一步阐述本发明为达成预定发明目的所采取的技术手段及功效,以下结合附图及较佳实施例,对依据本发明提出的一种网络信息的数据安全防护方法,其具体实施方式、结构、特征及其功效,详细说明如下。在下述说明中,不同的“一个实施例”或“另一个实施例”指的不一定是同一实施例。此外,一或多个实施例中的特定特征、结构或特点可由任何合适形式组合。
18.除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。
19.下面结合附图具体的说明本发明所提供的一种网络信息的数据安全防护方法的具体方案。
20.请参阅图1,其示出了本发明一个实施例提供的一种网络信息的数据安全防护方法的步骤流程图,该方法包括以下步骤:步骤s001:获取网络信息数据并初始化lzw压缩算法中的字典。
21.网络信息数据包含多种字符,例如汉字、字母、数字、标点符号、特殊字符(空格、换行符)等字符,这些字符在网络信息数据中或多或少的会重复出现,因此在网络信息数据存储时便可根据字符存在重复出现这一特点进行优化存储,例如lzw压缩算法便是基于字符在网络信息数据中重复出现这一特点设计的压缩算法。
22.lzw压缩算法的基本原理是建立字典,其中包含了输入数据流中出现的所有可能的字符序列,在初始化时,lzw中的字典中只包含单个字符序列;然后,算法从输入数据流中读取字符,将它与已有的字符序列进行匹配,如果匹配成功,算法继续读取下一个字符,并将匹配的字符序列扩展为更长的序列;如果匹配失败,算法将当前的字符序列添加到lzw中的字典中,并将它的编码输出;然后,算法从下一个字符开始重新匹配。
23.而本实施例是基于lzw压缩算法思想对数据进行处理,所以需要统计待压缩网络
信息数据字符种类,将所有字符添加到lzw中的字典,并为每个字符分配一个唯一的编码。
24.然而现有的lzw压缩算法虽然是基于字符序列是否已经在网络信息数据中重复出现的频率这一特征来构建字典,进而实现压缩的,但是该算法没有考虑到网络信息数据中重复出现的字符的相对位置分布情况以及离散分布情况。因此本实施例接下来利用网络信息数据中字符的相对位置分布情况以及离散分布情况来分析不同字符片段加入字典的优先级来进一步提高网络信息数据的压缩效率。
25.步骤s002:根据数据中各种字符数量的占比,获取数据中各种字符的优先级参数。
26.需要说明的是,由于lzw压缩算法在初始化后,会在lzw中的字典内依次更新字典内所有字符段,并用符号表示,在后续读取相同字符段时,用记录好的符号表示字符段,但其对于有重复模式的数据压缩效果比较好,对于重复度不高的数据压缩效果欠佳,将所有字符段都加入lzw中的字典会浪费字典空间,增加搜索速度,使后续字典中记录字符段的编码长度更长,影响压缩效果;而本实施例根据各种字符频率和分布,判断字符段的优先程度,根据概率参数大小选择性加入lzw中的字典,将概率参数较小的字符段用字典内表示过的字符和字符或字符和字符段编码(字典编码)进行表示,降低了lzw中的字典的冗余程度,使字典中字符段编码长度更短,且可以使lzw中的字典有尽可能多的空间记录待压缩数据中更多具有重复模式的字符段。
27.需要进一步说明的是,当字符在数据中的占比越高,即该种字符在数据中出现的次数越多,该种字符的优先级就越高。
28.具体的,以各种字符在数据的数量占比作为各种字符的优先级,得到各种字符的优先级并记为,其中表示第种字符的优先级。
29.步骤s003:根据字符之间在数据中的相对位置与离散程度,获取字符所组成的字符段的概率参数。
30.需要说明的是,当字符之间的分布位置越接近,则由字符所组成的字符段的概率参数就越大;而当字符之间的分布位置越接近时,字符之间在数据中的相对位置与离散程度也会越相似,所以可以通过字符之间在数据中的相对位置与离散程度,获取由字符所组成的字符段的概率参数。
31.将任意一种字符记为目标字符,目标字符在网络信息数据中可能会多次出现。
32.首先将目标字符从数据中全都提取出来,统计提取出的所有字符两两间在数据中的距离,然后计算所提取的字符中第一个字符与其他所提取的字符之间的距离和,并记为第一距离和,同时将第一个字符记为第一距离和的起始字符;计算所提取的字符中第二个字符与其他所提取的字符之间的距离和,并记为第二距离和,同时将第二个字符记为第二距离和的起始字符;计算所提取的字符中第三个字符与其他所提取的字符之间的距离和,并记为第三距离和,同时将第三个字符记为第三距离和的起始字符;以此类推,直至获得所有提取的字符与其他所提取的字符之间的距离和。
33.取所有距离和中最小的距离和中的起始字符作为目标字符的中心点字符,并将中心点字符在数据中的位置记为,表示目标字符的中心点位置。
34.至此,得到每种字符的中心点字符和每种字符的中心点位置。
35.将各种字符之间的中心点位置之间距离,作为各种字符之间在数据中的相对位置。
36.至此,获取各种字符之间在数据中的相对位置。
37.接着将每种字符在数据中的位置的标准差作为每种字符在数据中的离散程度记为。
38.最后通过中心点字符在数据中的位置与字符在数据中的离散程度,获取任意两种字符所组成的字符段的概率参数,其具体计算公式为:式中,为第种字符与第种字符所组成的字符段的概率参数;与分别为第种字符与第种字符的中心点字符在数据中的位置;与分别为第种字符与第种字符在数据中的离散程度;其需要进一步说明的是,当所计算的第种字符与第种字符所组成的字符段的概率参数,第种字符与第种字符组成的字符段的概率越大。
39.需要进一步说明的是,由任意两种字符所组成的字符段的概率参数越小,特定字符组成对应的字符段的概率越大;因此本实施例通过分析网络信息数据中字符的相对位置分布情况以及离散分布情况获得任意两种字符组成的字符段的概率参数,能够保证后续多字符(两个以上)组成的字符段的概率参数的计算。
40.至此,获取字符所组成的字符段的概率参数。
41.步骤s004:根据数据中各种字符的优先级参数和字符所组成的字符段的概率参数,获取字符段优先级参数。
42.需要说明的是,字符所组成的字符段的概率参数越小,特定字符组成对应的字符段的概率越大,而组成对应的字符段的特定字符优先级越高,则说明特定字符在数据中出现的次数可能较高,即特定字符组成的对应的字符段的概率越大。
43.需要进一步说明的是,lzw压缩算法中的字典的记录过程是一个一个字符记录的,即如果记录了长度为w的字符段,那么lzw中的字典内一定存在该字符段按字符增加时从长度为2-w时的每一个字符段,所以想要得到长度为w的字符段的优先级,需要根据字符依次计算。
44.具体的,在计算长度为2的字符段优先级时,需要用第一个字符和第二个字符进行计算,计算长度为3的字符段优先级时,此时前面两个字符组成的字符段需要被当作一个整体,再与第三个字符计算得到长度为3的字符段优先级;以此类推,计算每一层字符段的优先级,直至到达长度为w的字符段的优先级为止,具体的计算公式为:
式中,为长度的特定字符段的优先级,为在长度的特定字符段中前个字符优先级的累乘积,为在长度的特定字符段中第个字符的优先级,为在长度的特定字符段中第一个字符与第二个字符所组成字符段的概率参数,为在长度的特定字符段中第个字符的中心字符的位置,为在长度的特定字符段中前个字符中各个字符的中心字符位置的均值,为在长度的特定字符段中第个字符在数据中的离散程度,为在长度的特定字符段中前个字符中各个字符在数据中的离散程度的均值。其中,当所计算的的值越大,则长度的特定字符段的优先级越高。
45.至此,获得字符段的优先级。
46.步骤s005:根据字符段的优先级调整lzw压缩算法中的字典的字符段编码。
47.需要说明的是,在lzw压缩算法中,在字典对字符和字符段进行编码时,先编码短字符段,才能编码长字符段。
48.需要进一步说明的是,当特定字符段的长度增加后的特定字符段的优先级一定不大于定字符段的长度增加前的特定字符段的优先级,所以通过预设一个可信的阈值,阈值的具体取值可以根据具体场景进行设置,本实施了不做具体要求,在本实施例中取,当特定字符段的长度增加后的特定字符段的优先级大于所设置阈值时,将高于阈值的字符段存入lzw中的字典,反之则不存入lzw压缩算法中的字典,同时停止计算该字符段的下一级字符段的优先级。
49.至此,得到lzw压缩算法中的字典。
50.步骤s006:用lzw压缩算法中的字典压缩网络信息数据并加密。
51.用得到的lzw压缩算法中的字典,对网络信息数据进行压缩可以节省字典空间,且使字典中涵括更多可能具有重复模式的字符串,提高压缩比,最后对网络信息数据的压缩结果采用aes算法进行加密,从而实现对网络信息数据的安全防护。
52.以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。