1.本发明总体上涉及一种功率放大器系统,并且更具体地涉及一种数字多尔蒂功率放大器(doherty power amplifier)系统以及用于增强射频功率放大器的性能的数字预失真(dpd)系统和功率放大器系统的基于学习的自动调谐优化方法。
背景技术:
2.无线通信数据量和速率的快速增长使得无线发射机的功耗显著增加,其中功率放大器(pa)是能耗的关键部件。提出了包括包络跟踪(et)、多尔蒂功率放大器(dpa)、包络消除与恢复(eer)的多项先进技术来提高pa的功率附加效率(pae)。在这些技术中,dpa由于其基于有源负载调制的实现了高平均效率的简单的结构而非常有前景。
3.尽管dpa表现出用于效率增强的许多优点,但是传统的模拟dpa仍然存在缺陷,这导致在能量效率和操作带宽方面的性能下降。传统的dpa设计基于包含模拟功率分配器(可能是可调的)、固定相位对准、运行在ab类上的载波pa和运行在c类模式上的峰值pa的单输入配置,以及输出功率组合器。为了提高dpa的效率,研究了几种方法,包括栅极偏置自适应、非对称dpa、多路dpa、可调相位对准和自适应功率分配比。
4.为了获得最优的数字预失真(dpd)和pa性能,设计者需要手动地调谐电路操作参数,并且调谐过程仅针对固定的诸如输入功率、频率和信号标准之类的操作条件有效。而在实际场景中,最优控制参数随输入和电路状态的变化而变化。补偿电路部分也是复杂的并且难以优化,使得dpa设计非常麻烦。这些正是基于纯模拟的设计的局限性。
5.需要更灵活的结构,例如数字dpa(ddpa),以自适应地找到针对各种电路状态和各种带宽、调制格式、功率电平和调制格式的输入信号的最优控制参数。此外,在本发明中,我们提出不仅可以自调pa的参数,而且还可以自调作为dpd性能的函数的pa的学习成本函数,从而使两个系统同步提高其性能。
技术实现要素:
6.一些实施方式基于这样的认识:数字功率放大器(dpa)是可编程的,使得其便于设计者进行电路调谐过程(自动调谐),并且可以考虑多个路径的例如相位延迟的电路不平衡和包括温度的环境变化。因此,与模拟dpa相比,dpa不仅灵活,而且能够提供增强的性能。
7.此外,本发明的一些实施方式基于这样的认识:可以提供自动调谐控制器来提高数字功率放大器(dpa)的功率效率和线性度。自动调谐控制器可以包括:接口,该接口包括连接到dpa的输入端子和输出端子,所述接口被配置为获取输入信号和输出信号;数字预失真(dpd)-dpa自适应控制器,该dpd-dpa自适应控制器包括运行和存储dpd算法、效率增强方法和学习成本函数的处理器和存储器。所述dpd自适应控制器可以被配置为执行以下步骤:通过使用数据驱动优化方法来计算dpd系数以基于dpd模型来定义学习成本函数,其中,所述学习成本函数包括dda性能的变量和dpd性能的变量两者;基于所述dpd性能来更新所述
学习成本函数;通过关于所述dda性能的变量求解更新的学习成本函数来优化更新的学习成本函数;以及通过所述接口提供dpa和dpd的最优参数。在一些情况下,提供步骤可以是经由所述接口将经优化的更新的学习成本函数的变量发送到所述dpa。
8.根据本发明的实施方式,提供了一种dpa系统、数字多尔蒂功率放大器(ddpa)系统、数字预失真(dpd)和基于学习的自动调谐方法(优化方法),其特别地通过同时满足线性度要求的自适应控制来提高与pa系统一起工作的dpd的效率和增益。ddpa系统和优化方法可用于宽带移动通信,包括3g、4g lte、5g及以上的发射机的基站无线电前端。
9.在一些情况下,所述ddpa系统可以包括自动调谐控制器和具有控制输入和用于生成输出信号的输出的多尔蒂功率放大器(dpa)电路。自动调谐控制器可以包括:接口,该接口包括连接到dpa的输入端子和输出端子,所述接口被配置为获取输入信号和输出信号;数字预失真(dpd)-dpa自适应控制器,该dpd-dpa自适应控制器包括运行和存储dpd算法、效率增强方法和学习成本函数的处理器和存储器。所述dpd自适应控制器可以被配置为执行以下步骤:通过使用数据驱动优化方法来计算dpd系数以基于dpd模型来定义学习成本函数,其中,所述学习成本函数包括dda性能的变量和dpd性能的变量两者;基于所述dpd性能来更新所述学习成本函数;通过关于所述dda性能的变量求解更新的学习成本函数来优化更新的学习成本函数;以及通过所述接口提供dpa和dpd的最优参数。在一些情况下,提供步骤可以是经由所述接口将经优化的更新的学习成本函数的变量发送到所述dpa。
10.本发明的一些实施方式提供了一种dpd和数字多尔蒂放大器(dda)系统,其完全自适应地找到最优控制参数集,而不管装置参数、环境变化如何,而无需复杂的工程调谐,其中最优控制的目标是例如宽带无线电发射机中具有合理增益的高效率。
11.本发明的一个实施方式是不具有关于dpa装置的假设或先验知识的无模型算法,其中该算法基于黑盒优化来搜索最优配置,其中用于pa的优化学习成本函数是dpd性能的函数。
12.一些实施方式不仅优化dpa效率,而且以灵活的方式增强增益和线性特性,而学习成本中的线性特性项与dpd线性化性能成比例。例如,在一些实施方式中,系统可以平衡不同频带中的增益和效率权衡,或者在某些约束下使效率最大化。一个示例是优化效率,同时要求增益大于配置的阈值。在调制信号的情况下,我们在相同的ddpa场景下优化效率、增益以及相邻信道功率比(acpr)。acpr是调制信号中使主信道向相邻信道发射的功率受限的重要因素。
13.根据本发明的实施方式,数字功率放大器(dpa)系统包括:具有控制输入和用于生成输出信号的输出的功率放大器(pa)电路;以及自适应控制电路,该自适应控制电路包括输入接口、输出接口、存储自适应控制算法的存储器和与所述存储器连接的基于所述自适应算法执行指令的处理器,其中,所述输入接口接收所述pa电路的输入状态信号和输出信号,其中,所述自适应控制算法响应于所述输入状态信号和所述输出信号,确定从所述输出接口发送到所述控制输入以用于控制所述pa电路的操作的控制信号的控制参数。
14.附图被包括在本说明书中以提供对本发明的进一步理解,阐释本发明的实施方式,且与说明书一起用于解释本发明的原理。
附图说明
15.[图1]
[0016]
图1是示出根据本发明的实施方式的数字功率放大器(dpa)的示意图;
[0017]
[图2]
[0018]
图2是示出根据本发明的实施方式的通过dpd(数字预失真)处理来改善功率放大器的线性度和效率的各阶段的示意图;
[0019]
[图3a]
[0020]
图3a是示出根据本发明的实施方式的用于pa自动调谐的算法的框图的示意图;
[0021]
[图3b]
[0022]
图3b是示出根据本发明的实施方式的数字功率放大器(dpa)的框图;
[0023]
[图4]
[0024]
图4是示出根据本发明的实施方式的dpd、dpa和学习成本更新过程之间的交互的框图;
[0025]
[图5a]
[0026]
图5a是根据本发明的实施方式的dpd/dpa调谐算法的流程图;
[0027]
[图5b]
[0028]
图5b是示出根据本发明的实施方式的在dpd/dpa调谐算法中使用的若干数据驱动优化的框图;
[0029]
[图5c]
[0030]
图5c是示出根据本发明的实施方式的在dpd/dpa调谐算法中使用的若干dpd模型选择的框图;
[0031]
[图6]
[0032]
图6是示出根据本发明的实施方式的dpd和dpa性能对学习成本函数更新过程的影响的框图;
[0033]
[图7]
[0034]
图7示出了根据本发明的实施方式的用于更新学习成本函数的算法的步骤;以及
[0035]
[图8]
[0036]
图8示出了根据本发明的实施方式的用于修剪过程的算法的步骤。
具体实施方式
[0037]
下文参照附图描述本发明的各种实施方式。应当注意,附图不是按照比例绘制的,在整个附图中,具有相似结构或功能的元件由相似的附图标记表示。此外,一些部件和工艺步骤由数字指示。还应当注意的是,附图仅旨在便利于对本发明的特定实施方式的描述。它们不意在作为本发明的穷举描述或作为对本发明范围的限制。另外,结合本发明的特定实施方式描述的方面不一定限于该实施方式,并且可以在本发明的任何其他实施方式中实践。
[0038]
本发明的一些实施方式基于这样的认识,即可以提供自动调谐控制器来提高数字功率放大器(dpa)的功率效率和线性度。自动调谐控制器可以包括:接口,该接口包括连接到dpa的输入端子和输出端子,所述接口被配置为获取输入信号和输出信号;数字预失真
(dpd)-dpa自适应控制器,该dpd-dpa自适应控制器包括处理器和运行并存储dpd算法、效率增强方法和学习成本函数的存储器。所述dpd自适应控制器可以被配置为执行以下步骤:通过使用数据驱动优化方法来计算dpd系数以基于dpd模型来定义学习成本函数,其中,所述学习成本函数包括dda性能的变量和dpd性能的变量两者;基于所述dpd性能来更新所述学习成本函数;通过针对所述dda性能的变量求解更新的学习成本函数来优化更新的学习成本函数;以及经由所述接口将优化的更新的学习成本函数的变量发送到所述dpa。
[0039]
图1是根据本发明的一些实施方式的数字功率放大器(dpa)模块(ddpa系统)100的框图。dpa模块100可以是数字功率放大器(dpa)模块,其由诸如多尔蒂功率放大器、异相功率放大器、平衡功率放大器和推挽功率放大器之类的多输入功率放大器120配置。作为示例,在数字功率放大器(dpa)模块100中使用多尔蒂功率放大器来解释dpa模块的功能。dpa模块100可以被称为ddpa(数字多尔蒂功率放大器)模块100。然而,应当注意,根据电路设计的变化,也可以使用异相功率放大器电路、平衡功率放大器电路或推挽功率放大器电路。
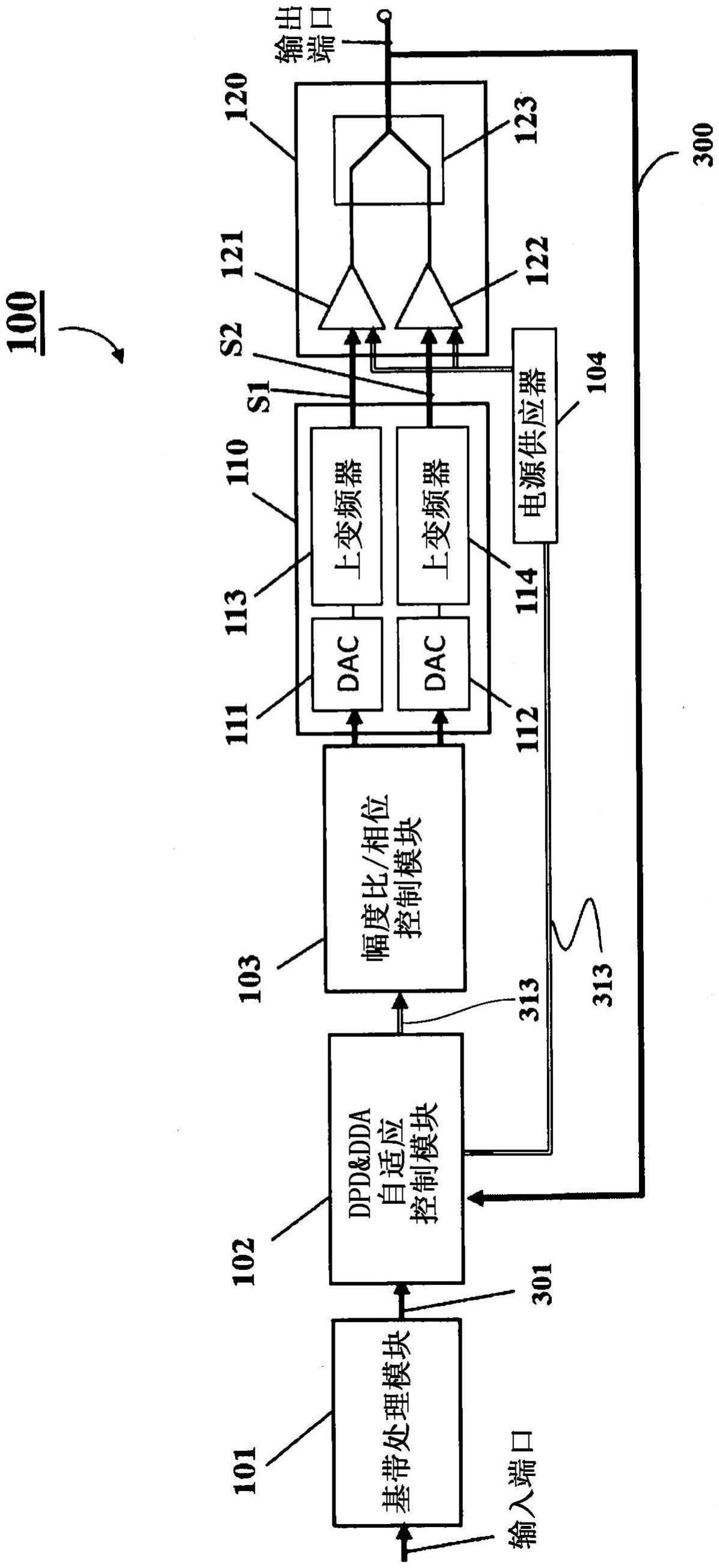
[0040]
ddpa模块100可以包括基带处理模块101、数字预失真(dpd)和数字多尔蒂放大器(dda)自适应控制模块102、幅度比/相位控制模块(amp-phase模块)103、信号转换器110、双输入dpa模块(dpa模块,但不限于双输入)120和电源供应器104,电源供应器104用于根据由dda自适应控制模块102生成的最优控制参数(或控制参数)313向dpa单元120提供偏置条件(电压和/或电流)。dpa模块120包括主pa(载波pa)121、峰值pa 122和输出组合器123。信号转换器110包括数模转换器(dac)111和112以及上变频器113和114。在该图中省略了pa的输出和输入阻抗匹配网络。
[0041]
双输入dpa 120包括用于控制载波信号的载波功率放大器(pa)121和用于控制峰值信号的峰值功率放大器(pa)122,以及用于组合来自载波pa 121和峰值pa122的信号的输出组合器123。显然,数字多尔蒂的配置可以扩展到多路多尔蒂,其中以与100中描述的类似拓扑包括多于两个pa。
[0042]
当在模块100中使用除了多尔蒂放大器之外的功率放大器(例如异相pa和平衡pa)时,dpd&dda自适应控制模块102可以被称为用于改善数字功率放大器(dpa)的线性度和功率效率的自动调谐控制器或者数字自适应(da)控制模块102。dpd&dda自适应控制模块102包括图中未示出的部分。例如,dpd&dda自适应控制模块102包括接口,该接口包括连接到dpa的输入端子和输出端子。接口被配置为获取来自基带处理模块101的输入信号和来自双输入dpa 120的输出信号,并被配置为发送最优控制参数(最优控制参数信号)313和104。自动调谐控制器102还包括数字预失真(dpd)-dpa自适应控制器。数字预失真(dpd)-dpa自适应控制器包括运行并存储dpd算法、效率增强方法和学习成本函数的处理器和存储器。在这种情况下,dpd自适应控制器被配置为执行以下步骤:通过使用数据驱动优化方法来计算dpd系数以基于dpd模型来定义学习成本函数,其中,所述学习成本函数包括dda性能的变量和dpd性能的变量两者;基于所述dpd性能来更新所述学习成本函数;通过针对所述dda性能的变量求解更新的学习成本函数来优化更新的学习成本函数;以及通过所述接口提供dpa和dpd的最优参数。
[0043]
输入信号301经由接口被发送到da自适应控制模块102。da自适应控制模块102使用输入信号301和来自dpa模块120的输出信号300来执行数据驱动优化,并且生成关于pa 121和122之间的相位差以及pa 121与122的输入功率比的最优控制参数313。在一些情况
下,控制参数313可以被称为更新的ddpa参数。更新的ddpa参数313被提供给放大器相位(amp-phase)模块103。此外,上面讨论的优化可以被称为功率放大器系统的基于学习的自动调谐方法。
[0044]
在这种情况下,控制参数313包括pa 121(vg1)和122(vg2)的栅极偏置参数、pa 121和122之间的输入信号相位差、以及pa 121与122的输入功率分布(比率)。此外,电源供应器104从dda自适应控制模块102接收栅极偏置参数,并且根据栅极偏置参数(vg1、vg2)将栅极偏置电压施加到pa 121和122。当放大器相位(amp-phase)模块103从dda自适应控制模块102接收到pa 121和122之间的相位差和pa 121与122的输入功率比作为控制参数313的一部分时,放大器相位(amp-phase)模块103生成信号s1和s2以分别施加到pa 121和pa 122。在这种情况下,信号s1和s2被形成为使得信号s1与s2的幅度比和信号s1及s2之间的相位差满足由dda自适应控制模块102计算出的最优控制参数313所指示的值。
[0045]
在一些情况下,dda自适应控制模块102可以包括电源供应器104,并且pa 121和122可以是使用基于氮化镓(gan)的材料或其他不同的半导体装置技术制造的场效应晶体管(fet)。此外,pa 121和122可以是双极晶体管(bpt)。在这种情况下,用双极晶体管的基极电流偏置代替栅极偏置。可以通过基于gan的材料或其他不同的半导体装置技术来形成bpt。
[0046]
输出组合器123的输出信号(例如,四分之一波长传输线可用作输出组合网络。此外,也可以使用诸如基于集总元件电感器、电容器的其他形式来进行相同的组合功能)可以经由预定的带通滤波器(未示出)从天线(未示出)发送。在一些其他情况下,输出组合网络可以是空间组合,而没有任何物理组件或电路,诸如在5g中使用的大规模mimo相控阵的情况下(例如,如3gpp标准规范3gpp ts 38.104版本15.2.0第1515版中所定义的)。此外,dda控制模块102的输入接口(未示出)接收(检测)输出组合器123的输出信号,以计算分别控制载波pa 121和峰值pa 122的控制参数313。在一些情况下,控制参数313可以被称为调谐参数。
[0047]
可以通过指示栅极偏置、相位和输入信号功率的控制参数313来控制载波pa 121和峰值pa 122中的每一个。相位信号和输入功率信号被施加到放大器相位(amp-phase)模块103。放大器相位(amp-phase)模块103根据dda自适应控制模块102产生的控制参数313来调整载波pa 121和峰值pa 122的信号的幅值比和相位。
[0048]
在这种情况下,如果需要,信号转换器110经由驱动载波pa 121和峰值pa 122的驱动放大器(未示出)生成适当定相的信号和输入功率信号并将其提供给载波pa 121和峰值pa 122。
[0049]
dpd&dda自适应控制模块102包括与存储自适应控制算法的一个或更多个存储器(未示出)连接的处理器(未示出),其中,处理器根据预定的自适应算法执行指令。此外,自适应控制算法基于称为自适应调整控制的无模型优化。
[0050]
控制参数313由通过自适应优化控制计算控制参数313的值的dda自适应控制模块102生成。在一些情况下,控制参数313可以被称为数据驱动优化参数。
[0051]
此外,dda自适应控制模块102还包括用于接收双输入dpa模块120的输入信号301和输出信号300的输入接口(未示出),以及生成控制参数313的输出接口(未示出),控制参数313包括用于控制双输入dpa 120以及载波pa 104和峰值pa 105的相位控制信号、功率比
控制信号和偏置信号。
[0052]
dda自适应控制模块102从基带处理模块101接收基带信号,并经由输入接口检测输出组合器106的输出信号300,以基于自适应控制算法产生控制参数313,控制参数313可被称为数据驱动优化参数313。在这种情况下,数据驱动优化参数313的一部分经由输出接口被提供给放大器相位(amp-phase)控制模块103,以用于控制pa 121和pa 122的相位和功率比。此外,数据驱动优化参数313的另一部分被转换为栅极偏置,栅极偏置经由电源供应器104分别被提供给pa 121和pa 122,以用于控制pa 121和pa 122的栅极偏置。
[0053]
在图1中,ddpa模块100是可编程的,使得其便于设计者进行电路调谐过程,并且可以全面考虑多路径的电路不平衡和缺陷。因此,ddpa模块100不仅灵活且低成本,而且与模拟dpa相比提供更好的性能。根据本发明的实施方式的设计受益于软件设计原理,使得控制端口可以通过算法被修改为达到最优性能。
[0054]
使rf功率放大器更有效意味着将其驱动到接近其饱和点的点。在这种情况下,调制波形趋于失真(引入由acpr(相邻信道功率比)表征的非线性)。因此,设计目标是使功率附加效率(pae)最大化,同时维持高增益和良好线性度(acpr)。在一些情况下,可以通过数字预失真(dpd)来实现数字线性度。
[0055]
图2示出了分别通过dpd(数字预失真)处理201和效率增强处理202来改善pa 121和122的线性度和效率的阶段。在处理中,在步骤201中执行输入信号的数字预失真,在步骤202中执行效率增强,并且在步骤203中将通过数字预失真(dpd)和效率增强进行的处理而获得的输入信号提供给pa 121和121。
[0056]
图3a示出了我们的用于pa自动调谐的算法的详细框图,其中输入信号(输入状态信号)301被用作输入状态,输入状态包括指示频率和输入功率电平的不同状态,但不限于这两种状态,并且也可以包括诸如信号调制格式的其他状态。指示频率和输入信号功率电平的输入状态信号301被馈送到dda自适应控制模块102,以通过使用输入信号301和双输入dpa模块120的输出信号330自适应地调谐ddpa 120的控制参数313,诸如栅极偏置303、主放大器和峰值放大器之间的相位差304以及输入功率分布305。最后,调谐的参数被馈送到双输入dpa模块120。
[0057]
根据电路设计变化,dpa模块120可以包括三个或三个以上功率放大器(pa)。例如,参见图3b。在这种情况下,dda自适应控制模块102为三个或三个以上功率放大器中的每一个提供控制参数313。
[0058]
图3b是示出根据本发明的实施方式的执行dpa模块的自动调谐过程的多输入数字功率放大器模块350的框图。
[0059]
在该图中,当部件的功能与图1中的那些相似时,对部件使用图1中相同的部件编号。此外,省略了对相同部件编号的描述。
[0060]
多输入数字功率放大器模块350包括基带处理模块101、dpd&dda自适应控制模块102、幅度比/相位控制模块103、信号转换器110和多输入pa模块120。在这种情况下,信号转换器110包括数模转换器(dac)111、112和112n以及上变频器113、114和114n。
[0061]
多输入pa模块120包括用于控制载波信号的载波功率放大器(pa)121和用于控制峰值信号的峰值功率放大器122、用于控制第二峰值信号的第二峰值功率放大器(pa)122n、以及用于组合来自pa 121、pa 122和pa 122n的信号的输出组合器123。在这种情况下,信号
转换器110包括三个或三个以上dac和三个或三个以上上变频器,并且多输入pa模块120包括三个或三个以上功率放大器121、122和122n。
[0062]
da自适应控制模块102使用输入信号301和多输入pa模块120的输出信号300产生更新的dpa参数313,并将更新的dpa参数提供给放大器相位(amp-phase)模块103。然后,放大器相位(amp-phase)模块103向信号转换器110提供信号,使得信号转换器产生要分别施加至pa 121、pa 122和pa 122n的s1、s2和s2n。
[0063]
如上所述,使用dpd&dda自适应控制模块102来计算最优控制参数313。下面将提供关于最优控制参数的详细讨论。
[0064]
如图4所示,本发明的主要实施方式是在dpd和dda自适应控制模块102中执行的dpd自适应和dda自适应之间的交互循环450的设计。该交互循环450的一部分是基于学习成本函数410对dpd性能401的适配。基于dpd性能调整学习成本函数,然后学习成本函数用来执行dda的自适应控制405(dda自适应405)。该系统是耦合的,dda 405的自适应也影响dpd性能401。这种相互影响的循环使这个问题具有挑战性。
[0065]
如图5a所示,在本发明的一些实施方式中,我们提出交互循环450可以如下实现:系统优化过程开始于预优化阶段560,其中首先单独地修改dda。在该预优化阶段560中,定义561dda的优化变量,然后仅定义562针对dda的局部学习成本函数。然后使用数据驱动优化方法566来优化563该局部dda学习成本函数。如图5b所示,例如,可以使用极值搜索方法576、模拟退火方法567、贝叶斯优化方法577、爬山方法579等597。在该预优化阶段560之后,算法检查用户(来自用户接口的输入)是否包括dpd调谐564,如果不需要dpd调谐,则算法终止,如果需要ddp调谐,则算法移动到下一阶段,即dpd调谐和dda调谐之间的交互循环450,这构成本发明的主要实施方式。
[0066]
在该dpd-dda交互循环中,首先选择581dpd模型。例如,在一个实施方式中,选择多项式模型;在另一实施方式,选择非线性三角模型,而在又一实施方式中,选择深神经网络模型作为dpd模型。然后,使用优化方法在dpd迭代582的阶段计算dpd系数。例如,使用583最小二乘(ls)优化。在其他实施方式中,在该阶段582可以使用其他非线性优化方法。然后,测量584全局学习成本函数(cf)。该全局成本函数与局部学习成本函数562的不同之处在于以下事实,该全局成本函数包括来自dda性能405和dpd性能401的两个元素。将该学习成本函数与期望的成本函数阈值进行比较584;如果学习成本的值足够高,则算法停止,否则算法移动到学习成本更新阶段410。
[0067]
在该阶段中,基于dpd 401的性能来更新410学习成本的系数。作为本发明的一个主要实施方式,稍后将在图6中详细介绍该阶段。
[0068]
接下来,优化596更新的学习成本函数410。该优化通过求解使更新的学习成本函数410关于dda变量313最大化来实现。这些变量可定义为:
[0069]
θ=[a
cr,db α φ φ
att v
gs,m v
gs,p
]
ꢀꢀ
(1)
[0070]
其中,a
cr,db
是papr降低的阈值,α是功率比,φ是相位差,phi
att
是衰减差,v
gs,m
是功率放大器的主偏置电压,v
gs,p
是功率放大器的峰值偏置电压。
[0071]
然而,我们认识到,通过修剪需要优化的dda系数580,可以简化该优化问题。该过程580可以基于修剪580结果而导致完全或局部优化596。实际上,如果修剪580选择在优化过程中最敏感的dda变量的子集,则针对596求解局部优化。另一方面,如果修剪过程580发
现所有dda变量在优化中同等重要,则针对596求解完全优化。
[0072]
在本发明的若干实施方式中,我们提出在算法的不同阶段开始修剪过程。例如,在一个实施方式中,我们提出在预优化阶段560之后开始修剪过程580,如果用户想要包括dpd调谐564,则与定义dpd模型581和算法的后续阶段并行地开始599修剪过程580。在另一实施方式中,我们建议仅在已经更新410学习成本函数之后才开始591修剪过程580。修剪过程的细节在后面的图8中给出。
[0073]
然后,优化596的解导致学习成本函数的值被改进(即,与584中的成本函数值相比更高),或者不被改进。如果存在学习成本函数值的改进(即,更高),则算法循环回到dpd优化迭代582。如果没有改进,则在588,算法测试dpd的性能401和dda性能405是否在用户设置的期望阈值性能内。如果是,则算法终止其对最佳dpd系数和dda系数的学习。如果否,则修改587dpd模型,以寻找可能导致学习成本函数584的改进的更好的dpd模式。
[0074]
对于本发明的不同实施方式,可以不同地进行dpd模型修改587。例如,我们可以仅修改的dpd模型的大小5871。这种大小修改也称为dpd模型调整大小,其可以使用爬山方法或其他优化方法来完成。我们还可以修改dpd模型非线性5872。例如通过实现三角非线性而不是多项式非线性。我们还可以使用深度神经网络5873来对dpd进行建模,等5874。
[0075]
如图6所示,在本发明的一个实施方式中,我们认识到学习成本410可以被定义为:
[0076][0077]
其中,acpr
t
,evm
t
,p
out,t
和pae
t
分别是acpr目标、evm目标、输出功率目标和效率目标。类似地,acpr,evm,p
out
和pae分别是测量的acpr 610、evm 640、输出功率620和效率630。w1631是与第一dpd性能acpr 610相关联的权重,w
2 632是与第二dpd性能evm 640相关联的权重,w
3 633是与第一dpa功率性能620相关联的权重,w
4 634是与第二dpa效率性能630相关联的权重。
[0078]
我们提出的方法的目标是将j 410最大化为1,这意味着满足用户规范目标。加权系数的确定是学习成本函数设计中的一个重要方面。
[0079]
例如,等权重方法赋予每个目标函数同等的重要性。如果在优化过程中不使用线性化过程,则可以使用该原则来确定加权系数。然而,dpd显著地提高了线性度,这使得我们可以通过假设dpd会提高dpa线性度性能来降低线性度的dpd性能601的权重。在这种情况下,我们希望关注功率和效率的dpa性能602。另一方面,应用dpd在操作功率电平方面引入了回退,这显著地降低了输出功率和功率效率。因此,其对成本函数有影响,与应用dpd之前的值相比,成本函数会变差。
[0080]
因此,我们提出设计自适应成本函数,其中权重系数根据优化过程的演进而调整。针对与先前迭代相比dpd改进品质因数acpr 610和evm 640多少来执行加权系数的更新。
[0081]
在如图7所示的算法701中描述系数wi,i=1,2,3,4的更新。在本发明的一个实施方式中,权重w
1 631、w
2 632、w
3 633和w4634如下进行调整:权重被初始化为常数值711,使得它们的和等于1。运行721优化以使用这些恒定权重来优化学习成本函数,然后计算731所得到的acpr、evm和学习成本值j。设置731最大学习迭代的次数。然后,将dpd应用于系统,并且测量其性能601。然后,通过评估dpd性能acpr 610和性能evm 640离期望的性能目标acpr
t
和evm
t
有多远来主要对w1,w2执行权重调整;然后,通过两个连续acpr性能之间的距离
与目标acpr
t
性能的比率771来给出w1的调整值。类似地,w2的调整值由两个连续evm性能之间的距离与目标evm
t
性能的比率781给出。然后使用这些调整值来调整w
1 702和w
2 703。简单地调整剩余权重,使得所有权重的和保持等于一704、706。
[0082]
然后,利用更新的权重再次进行707学习成本j的优化,并且获得708相关联的学习成本j。如果该学习成本值大于在先前学习迭代709处的先前学习成本,则权重的自适应算法终止。如果不是大于,则递增755学习迭代计数器i,并且重新执行705权重自适应循环。当学习成本已经改善710、709时,或者当学习迭代计数器已经达到其最大数n时,算法终止。
[0083]
在另一实施方式中,我们提出如下更新权重w1和w2:
[0084]w1,i
=w
1,i
||acpr
1,i-acpr
t
||
[0085]w2,i
=w
2,i
||evm
i-evm
t
||
[0086]
然后,如在704、706中,可以更新剩余权重,以将总权重之和保持为1。
[0087]
在另一实施方式中,我们提出将所有权重更新为dpd性能601的一般函数。例如,我们可以将权重写为:
[0088]w1,i
=w
1,i
f1(acpri,acpr
t
,evmi,evm
t
)
[0089]w2,i
=w
2,i
f2(acpri,acpr
t
,evmi,evm
t
)
[0090]w3,i
=w
3,i
f3(acpri,acpr
t
,evmi,evm
t
)
[0091]w4,i
=w
4,i
f4(acpri,acpr
t
,evmi,evm
t
),
[0092]
其中,fi,i=1,2,3,4,被定义为评估dpd性能acpr 610、evm 640与期望性能acpr
t
,evm
t
之间的距离的函数。
[0093]
如图8所示,在本发明的一些实施方式中,我们提出以下修剪过程580。修剪过程从最后得到的dda的系数值599、591开始,并且敏感系数索引被初始化为i=1 5801。然后,通过加减一个小的探索值对索引系数i进行左右扰动5802。该探索5802导致dda系数的两个新值,针对其评估5803学习成本。然后,将获得的学习成本的值保存在存储器中5804。然后,dda系数索引增加1 5805。如果新索引小于dda系数的总数(其等于6),则算法循环回到通过向dda系数值的新索引加减一个小的探索值5802来扰动dda系数的值。如果该索引等于dda系数的总数(其等于6),则得到保存的所有学习成本函数值中的最大值,对应的值为dda系数的新值,对应的系数索引为敏感系数之一,然后将其存储在存储器中5807。然后,修剪过程通过使用dda系数的新值并将索引重新初始化为i=1而继续。修剪过程继续,直到不再有学习成本的改进。最后,找到的存储在存储器中的所有索引是dda系数的敏感系数5811。
[0094]
本发明的上述实施方式可以以多种方式中的任何方式来实现。例如,可以使用硬件、软件或其组合来实现实施方式。当以软件实现时,软件代码可以在任何合适的处理器或处理器集合上执行,无论是在单个计算机中提供还是分布在多个计算机之间。这样的处理器可以被实现为集成电路,在集成电路组件中具有一个或多个处理器。然而,可以使用任何适当格式的电路来实现处理器。
[0095]
此外,本发明的实施方式可以实现为已经提供了示例的方法。作为方法的一部分执行的动作可以以任何合适的方式排序。因此,可以构建其中以不同于所示出的顺序执行动作的实施方式,所述顺序可包括同时执行一些动作,虽然在说明性实施方式中示出为顺序动作。
[0096]
在权利要求中使用诸如“第一”、“第二”之类的顺序术语来修饰权利要求元素本身
并不意味着一个权利要求元素相对于另一个权利要求元素的任何优先级、优先或顺序或者执行方法动作的时间顺序,而仅仅用作将具有某一名称的一个权利要求元素与具有相同名称的另一元素(除了顺序术语之外)区分开来的标签,以区分权利要求元素。
[0097]
虽然已经通过优选实施方式的示例的方法是描述了本发明,但是应当理解,在本发明的精神和范围内可以进行各种其他的调整和修改。
[0098]
因此,所附权利要求书的目的是覆盖落入本发明的真实精神和范围内的所有这些变化和修改。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。