1.本发明涉及深度预测技术领域,特别涉及一种基于多种仿真红外辐射时间序列特征的目标类型预测方法。
背景技术:
2.目前,随着传感器、数据接收器等硬件设备的发展,由传感器等硬件导出的数据量也逐步增多。将数据进行合理的整合与分析是目前计算机领域的一个热门研究课题。采集后的数据可以通过深度学习手段按需进行预测、分类、识别、专家系统构建等。其中,基于时间序列的数据分析是目前深度学习领域中的热点。由于由传感器等硬件导出的数据多数具备时间属性,即时间是其因变量之一,所以可以通过时间序列(时序)进行函数曲线拟合,找寻时间与数据的潜在映射关系,进而达到未来数据预测、相关曲线分类等目的。所以基于时间序列的数据分析可以分为时序预测分析以及时序分类分析等。
3.时间序列分类方法有基于统计的时间序列分类方法和基于无监督的聚类方法等。基于统计的时间序列分类方法主要是对时间序列进行时间差分,通过判定方差的大小判定时间序列的周期性,进而完成二分类的目的,基于统计的时间序列分类实现简单,但是准确度不高且仅适用于二分类问题。使用基于无监督的聚类方法进行时间序列分类属于常见的机器学习手段之一,如使用k-means方法,通过计算预测数据与已知数据之间的距离关系,达到数据分类的目的,基于无监督的聚类方法进行时序分类需要进行大量的计算,具备较高的时间复杂度和空间复杂度。
技术实现要素:
4.为了在最少数据量的情况下最大限度地发挥深度学习网络模型的拟合和学习功能,本发明提供一种基于多种仿真红外辐射时间序列特征的目标类型预测方法。
5.本发明为解决技术问题所采用的技术方案如下:
6.本发明的基于多种仿真红外辐射时间序列特征的目标类型预测方法,包括以下步骤:
7.步骤一、仿真红外辐射时间序列特征数据的清洗与整合;
8.步骤二、仿真红外辐射时间序列特征数据的合理化分割;
9.步骤三、时序数据训练及数据特征提取;
10.步骤四、目标类型分类预测。
11.进一步的,步骤一的具体操作步骤如下:
12.通过传感器采集仿真红外辐射时间序列特征数据并采用深度学习网络模型对其进行清洗和整合;将维度为n的时序数据集合作为深度学习网络模型的输入,所述时序数据集合包括时间序列集合t={t1,t2,t3…
tm}和n类仿真红外辐射特征v1,v2,v3…vn
,对于任意一类仿真红外辐射特征均与时间序列集合t具备相关性:v1=f1(t),v2=f2(t)
…
,vn=fn(t),f1,f2…
,fn分别表示仿真红外辐射特征v1,v2,
…vn
关于时间序列集合t的映射;将总的
时序数据表示为一个大小为m
×
n的时序数据矩阵y,y∈rm×n,m为时序数据集合长度,n为仿真红外辐射特征的总类别数目。
13.进一步的,步骤一中,通过传感器采集仿真红外辐射时间序列特征数据时,采集波段包括短波波段、中波波段和长波波段;每类波段均采集五种不同的波段范围,短波波段范围分别为:0.75μm-1.25μm、1.25μm-1.80μm、1.80μm-2.35μm、2.35μm-3.0μm和0.75μm-3.0μm,中波波段范围分别为:3.0μm-3.75μm、3.75μm-4.50μm、4.50μm-5.25μm、5.25μm-6.0μm和3.0μm-6.0μm,长波波段范围分别为:6.0μm-7.5μm、7.5μm-9.0μm、9.0μm-10.5μm、10.5μm-12.0μm和6.0μm-12.0μm。
14.进一步的,步骤二的具体操作步骤如下:
15.采用类卷积网络的类卷积核结构进行数据的窗口分割处理,类卷积核结构均为各项值为1的单元矩阵;对于步骤一中的时序数据矩阵y,每一行对应一个时刻的传感器采集的时序数据集合,在时序数据分割处理过程中,分割窗口即类卷积核结构大小设定为k
×
n,k为对应的分割窗口长度即一次滑动所包含的时序长度;假设有n个传感器采集n个仿真红外辐射特征时序数据,且每个时序数据的时长均为m,每个时刻采集的时序数据具备n个对应特征,步骤一中的时序数据矩阵y表示如下:
[0016][0017]
其中y
ij
表示传感器i(i=1
…
n)在时刻j(j=1
…
m)采集的时序数据;用t
a:a b
表示长度为b的连续时间ta,t
a 1
,t
a 2
,
…
t
a b
,用表示n个传感器在时间范围(a,a b)内采集的仿真红外辐射特征,为大小为b
×
n的矩阵,且
[0018]
进一步的,步骤三的具体操作步骤如下:
[0019]
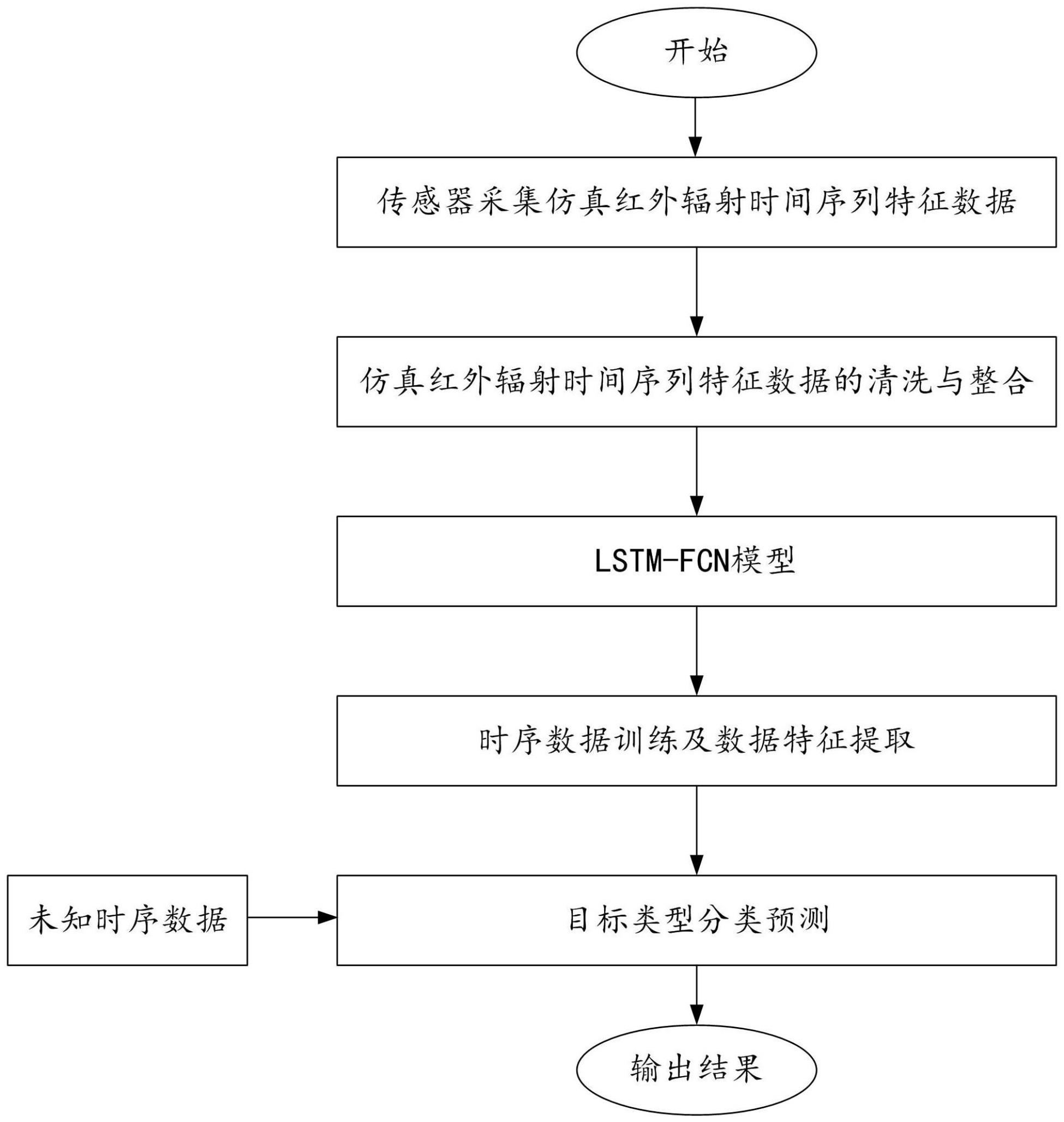
使用长短期记忆递归网络(lstm)进行多通道特征提取;同时使用全连接卷积神经网络(fcn)进行特征提取;将特征提取结果进行拼接进行目标类型分类预测。
[0020]
进一步的,所述使用全连接卷积神经网络(fcn)进行特征提取的具体操作步骤如下:
[0021]
所述全连接卷积神经网络(fcn)的卷积层层数设为l层,在卷积层的每一层应用一组一维滤波器,用于捕捉信号在时序过程中的变化;使用张量和偏置对每一层的一维滤波器进行参数化处理,l∈1,
…
,l是卷积层的索引,d是过滤的持续时间段,f
l-1
为上一层卷积核大小,f
l
表示当前卷积层中卷积核的大小,表示输出张量的尺寸,对于第l层的非标准化激活函数的第i个分量是来自前一层的输入时刻t的激活矩阵t
l-1
表示第l-1的时间步,表示前一层激活矩阵的大小,对于第l层的非标准化激活函数定义如公式(1)所示:
[0022]
[0023]
式中,f函数是校正线性单元relu函数,表示l层非标准化激活函数的偏置,表示l层非标准化激活函数的偏置权重,表示l-1层的激活矩阵。
[0024]
进一步的,所述使用长短期记忆递归网络(lstm)进行多通道特征提取的具体操作步骤如下:
[0025]
假设长短期记忆递归网络(lstm)的输入层、隐含层和输出层的神经元个数分别为i、h和o;t时刻输入层的序列x(t)的第i个输入值为xi(t),隐含层和输出层的第j个输入值分别为pj(t)和qj(t),而这两者经过激活函数后作为隐含层和输出层的输出值,分别为hj(t)和yj(t);所述长短期记忆递归网络(lstm)结构的计算表达式如下:
[0026]gu
=σ(w
uht-1
iux
t
)
ꢀꢀ
(2)
[0027]
gf=σ(wfh
t-1
ifx
t
)
ꢀꢀ
(3)
[0028]
gc=tanh(wch
t-1
icx
t
)
ꢀꢀ
(4)
[0029]go
=σ(w
oht-1
iox
t
)
ꢀꢀ
(5)
[0030]mt
=g
f m
t-1
g
u gcꢀꢀ
(6)
[0031]hj
(t)=tanh(g
o m
t
),j=1,...,h
ꢀꢀ
(7)
[0032][0033]
yj(t)=fo(qj(t)),j=1,...,o
ꢀꢀ
(9)
[0034]
式中,gu、gf、go、gc分别表示输入门、遗忘门、输出门以及中间单元状态门,σ表示sigmoid函数,wu、wf、wo、wc均表示递归权重矩阵,h
t-1
表示前一个隐藏层的状态节点,iu、if、io、ic均表示投影矩阵,x
t
表示当前时刻的输入,m
t
表示长期记忆,m
t-1
表示上一时刻输出的长期记忆,表示权重矩阵,hi(t)表示短期记忆,表示偏置,表示元素乘法,fo为输出层的激活函数。
[0035]
进一步的,所述激活函数fo的公式如下:
[0036][0037]
式中,tanh(x)表示与σ(x)均为激活函数。
[0038]
进一步的,所述将特征提取结果进行拼接进行目标类型分类预测的具体操作步骤如下:
[0039]
对于时间序列多分类问题,输出层神经元个数设为目标类型个数为c,网络的输出值为各目标类型的概率,表示如下:
[0040][0041]
式中,p(c|x)与yc均表示类型c的输出概率,表示归一化后类型c的输出概率,表示归一化后类型i的输出概率;再将网络的输出值进行“0-1”二值编码,概率最大的目标类型编码为1,其他类型均编码为0,设此时的输出值为d(t)=[d1(t),d2(t),...,dc(t)];因此网络对输入的时序数据的判决分类正确的概率p
right
为:
[0042][0043]
进一步的,步骤四的具体操作步骤如下:
[0044]
利用时序数据以及权重文件进行预测,对未知时序数据首先进行真假判断,再进行目标类型分类预测;设定损失函数,使用分类交叉熵作为损失函数,损失函数公式如下:
[0045][0046]
式中,los为损失函数值,c为总类别的数目,p
right
为网络对输入的时序数据的判决分类正确的概率。
[0047]
本发明的有益效果是:
[0048]
本发明旨在通过由传感器获得的长波红外辐射数据、中波红外辐射数据以及短波红外辐射数据等多路时序数据进行目标类型分类。本发明采用lstm模型与fcn模型作为基础模型,对多维度的仿真红外辐射时间序列特征数据进行深度的挖掘,将时序数据组成的数据矩阵进行多方面的挖掘。针对目标红外辐射数据进行仿真模拟,按照辐射的不同波段将传感器采集的数据分为15种特征类型,其中短波、中波、长波各为5类,提出将传感器采集模拟的数据使用cnn窗口滑动卷积过程进行时序数据分割,可以针对不完全周期、满周期、多周期数据进行多角度补充,提升不同情况下不同数据量的分类准确度,并通过多路lstm-fcn模型进行分类结果预测。本发明提升了分类的准确度与可靠性。
附图说明
[0049]
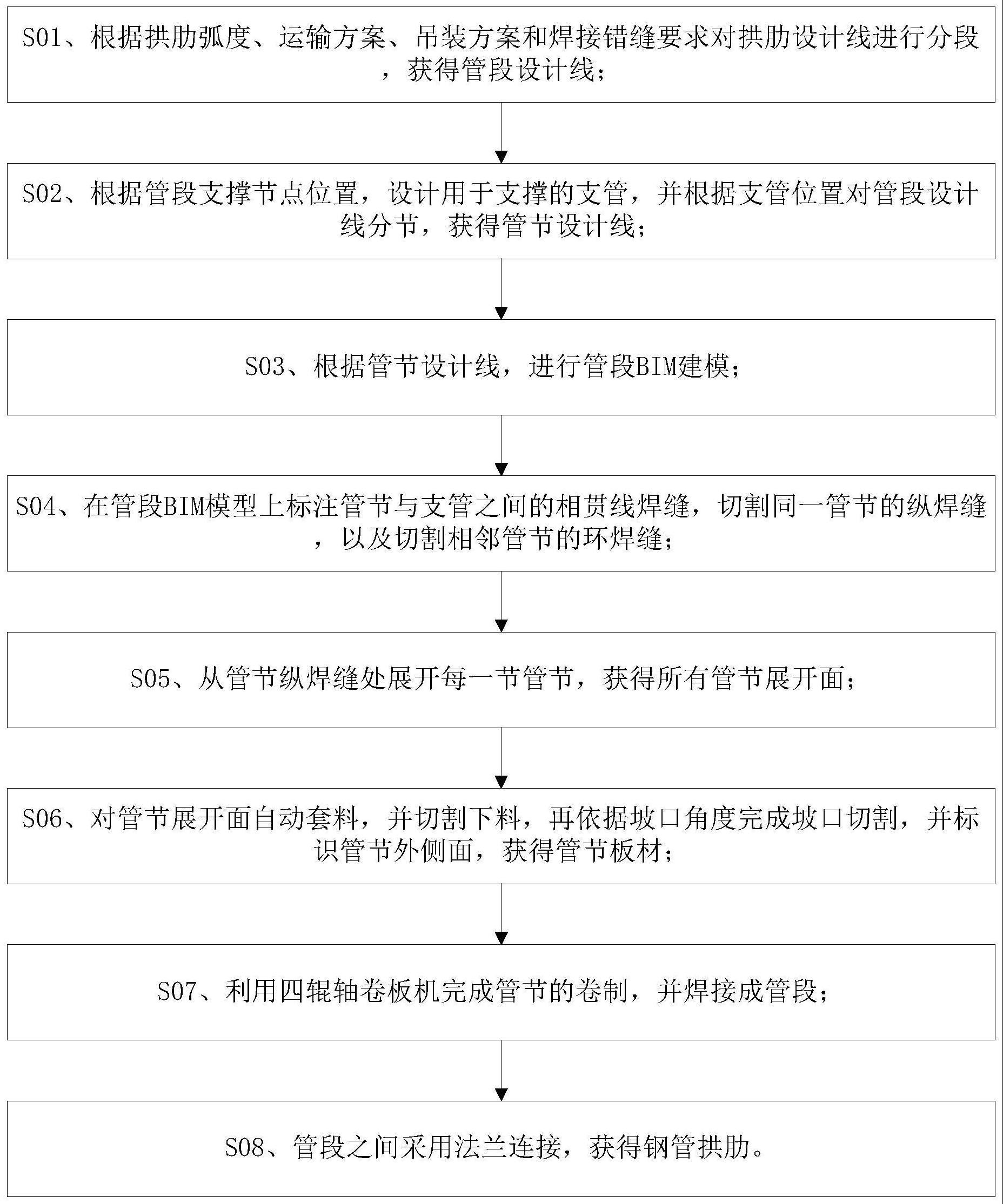
图1为本发明的一种基于多种仿真红外辐射时间序列特征的目标类型预测方法的整体操作流程示意图。
[0050]
图2为lstm-fcn模型架构示意图。
具体实施方式
[0051]
本发明的一种基于多种仿真红外辐射时间序列特征的目标类型预测方法,包括以下步骤:时序数据清洗步骤
→
时序数据分割步骤
→
时序数据训练步骤
→
目标类型分类预测步骤。以下结合附图对本发明作进一步详细说明。
[0052]
如图1所示,本发明的一种基于多种仿真红外辐射时间序列特征的目标类型预测方法,具体操作步骤如下:
[0053]
步骤一、仿真红外辐射时间序列特征数据的清洗与整合;
[0054]
通过传感器采集的仿真红外辐射时间序列特征数据(以下简称时序数据),所采集的时序数据的波段包括短波波段(0.75-3.0)μm、中波波段(3.0-6.0)μm和长波波段(6.0-12.0)μm,并且每类波段均采集五种不同的波段范围,对于短波波段可分为:0.75μm-1.25μm、1.25μm-1.80μm、1.80μm-2.35μm、2.35μm-3.0μm、0.75μm-3.0μm等五种波段范围,对于中波波段可分为:3.0μm-3.75μm、3.75μm-4.50μm、4.50μm-5.25μm、5.25μm-6.0μm、3.0μm-6.0μm等五种波段范围,对于长波波段可分为:6.0μm-7.5μm、7.5μm-9.0μm、9.0μm-10.5μm、10.5μm-12.0μm、6.0μm-12.0μm等五种波段范围,在采集完成后采用深度学习网络模型对时序数据进行清洗和整合。
[0055]
具体操作步骤如下:
[0056]
对于时序数据预测问题以及时序数据分类问题,深度学习网络模型的主要输入为维度为n的时序数据集合,包含的主要数据可分为时间序列集合t={t1,t2,t3…
tm}以及n类仿真红外辐射特征v1,v2,v3…vn
,对于任意一类仿真红外辐射特征均与时间序列集合t具备相关性,即:v1=f1(t),v2=f2(t)
…
,vn=fn(t),f1,f2…
,fn分别表示仿真红外辐射特征v1,v2,
…vn
关于时间序列集合t的映射。对于总的时序数据可以表示为一个大小为m
×
n的时序数据矩阵y,y∈rm×n,其中m为时序数据集合长度,n为仿真红外辐射特征的总类别数目。
[0057]
步骤二、仿真红外辐射时间序列特征数据的合理化分割;
[0058]
通过传感器所采集的时序数据通常具备采集频率高、采集时间长、特征周期范围交错等特点,因此对于连续时间内的一次采集结果,需要进行合理化分割。
[0059]
使用本发明所提出的类cnn方法对采集后的时序数据进行合理化分割,从而将时序数据分割为多类不同长度的时序数据子集集合,以便涵盖不足一周期、一周期以及多周期等多种类型数据。
[0060]
具体操作步骤如下:
[0061]
采用类卷积网络的类卷积核结构进行数据的窗口分割处理,其中,类卷积核结构均为各项值为1的单元矩阵;对于步骤一中的时序数据矩阵y,y∈rm×n,每一行对应一个时刻的传感器采集的时序数据集合,在时序数据分割处理过程中,分割窗口即类卷积核结构大小设定为k
×
n,其中n为仿真红外辐射特征的总类别数目,k为对应的分割窗口长度即一次滑动所包含的时序长度。假设有n个传感器采集n个仿真红外辐射特征时序数据,且每个时序数据的时长均为m,每个时刻采集的时序数据具备n个对应特征,步骤一中的时序数据矩阵y,y∈rm×n可表示如下:
[0062][0063]
其中y
ij
表示传感器i(i=1
…
n)在时刻j(j=1
…
m)采集的时序数据;用t
a:a b
表示长度为b的连续时间ta,t
a 1
,t
a 2
,
…
t
a b
,用表示n个传感器在时间范围(a,a b)内采集的仿真红外辐射特征,为大小为b
×
n的矩阵,且若采用步长为1对时序数据进行分割,通过每次分割后可以获得m-b 1个时序数据子集,由于分割窗口设定值有四种,所以可以获得4类不同长度的时序数据子集集合。
[0064]
步骤三、时序数据训练及数据特征提取;
[0065]
将分割后的时序数据输入至lstm-fcn模型之中,进行训练获取权重文件,从而完成数据特征提取。
[0066]
具体操作步骤如下:
[0067]
使用长短期记忆递归网络(lstm)进行多通道特征提取以及使用全连接卷积神经网络(fcn)进行特征提取,将特征提取结果进行拼接从而进行目标类型分类预测。
[0068]
全连接卷积神经网络(fcn)的卷积层层数设为l层,在卷积层的每一层应用一组一维滤波器,以用于捕捉信号在时序过程中的变化。使用张量维滤波器,以用于捕捉信号在时序过程中的变化。使用张量和偏置
对每一层的一维滤波器进行参数化处理,其中l∈1,
…
,l是卷积层的索引,d是过滤的持续时间段,f
l-1
为上一层卷积核大小,f
l
表示当前卷积层中卷积核的大小,表示输出张量的尺寸,对于第l层的非标准化激活函数的第i个分量是来自前一层的输入(标准化的)时刻t的激活矩阵t
l-1
表示第l-1的时间步,表示前一层激活矩阵的大小,对于第l层的非标准化激活函数定义如公式(1)所示:
[0069][0070]
式中,f函数是校正线性单元relu函数,表示l层非标准化激活函数的偏置,表示l层非标准化激活函数的偏置权重,表示l-1层的激活矩阵。
[0071]
假设长短期记忆递归网络(lstm)的输入层、隐含层和输出层的神经元个数分别为i、h和o;t时刻输入层的序列x(t)的第i个输入值为xi(t),隐含层和输出层的第j个输入值分别为pj(t)和qj(t),而这两者经过激活函数后作为隐含层和输出层的输出值,分别为hj(t)和yj(t)。
[0072]
长短期记忆递归网络(lstm)结构的计算表达式为:
[0073]gu
=σ(w
uht-1
iux
t
)
ꢀꢀ
(2)
[0074]
gf=σ(wfh
t-1
ifx
t
)
ꢀꢀ
(3)
[0075]
gc=tanh(wch
t-1
icx
t
)
ꢀꢀ
(4)
[0076]go
=σ(w
oht-1
iox
t
)
ꢀꢀ
(5)
[0077]mt
=g
f m
t-1
g
u gcꢀꢀ
(6)
[0078]hj
(t)=tanh(g
o m
t
),j=1,...,h
ꢀꢀ
(7)
[0079][0080]
yj(t)=fo(qj(t)),j=1,...,o
ꢀꢀ
(9)
[0081]
式中,gu、gf、go、gc分别表示输入门、遗忘门、输出门以及中间单元状态门,σ表示sigmoid函数,wu、wf、wo、wc均表示递归权重矩阵,h
t-1
表示前一个隐藏层的状态节点,iu、if、io、ic均表示投影矩阵,x
t
表示当前时刻的输入,m
t
表示长期记忆,m
t-1
表示上一时刻输出的长期记忆,表示权重矩阵,hi(t)表示短期记忆,表示偏置,表示元素乘法,fo为输出层的激活函数。
[0082]
本发明所使用的激活函数fo的公式如下:
[0083][0084]
式中,tanh(x)表示与σ(x)均为激活函数。
[0085]
对于时间序列多分类问题,输出层神经元个数设为目标类型个数为c,网络的输出值为各目标类型的概率,表示如下:
[0086][0087]
式中,p(c|x)与yc均表示类型c的输出概率,表示归一化后类型c的输出概率,表示归一化后类型i的输出概率。
[0088]
再将网络的输出值进行“0-1”二值编码,概率最大的目标类型编码为1,其他类型均编码为0,设此时的输出值为d(t)=[d1(t),d2(t),...,dc(t)]。因此网络对输入的时序数据的判决分类正确的概率p
right
为:
[0089][0090]
步骤四、目标类型分类预测;
[0091]
利用时序数据以及权重文件进行预测,对未知时序数据首先进行真假判断,再进行目标类型分类预测。
[0092]
设定损失函数,具体可使用分类交叉熵作为损失函数,损失函数公式如下所示:
[0093][0094]
式中,los为损失函数值,c为总类别的数目,p
right
为网络对输入的时序数据的判决分类正确的概率(公式(12))。
[0095]
下面以具体的测试来验证本发明提供的一种基于多种仿真红外辐射时间序列特征的目标类型预测方法的可行性。
[0096]
1、本实施例采用红外辐射强度的仿真数据进行测试和分类结果的实验。仿真数据包含了15个维度的时序数据,为增加仿真数据的可靠性,这15个维度的时序数据之间满足了对应的潜在关系。
[0097]
2、在本实施例中,仿真数据时长为8分钟,采样频率为100毫秒,在8分钟内可以采集到4800条连续的时序数据。
[0098]
更具体的,分割窗口长度k值设定为50、100、200、400四种类型。在窗口滑动过程中,分割窗口即类卷积核结构大小分别为50
×
15、100
×
15、200
×
15和400
×
15,即可以将4800条连续的时序数据分割为对应的4类不同长度的时序数据子集集合(分别为4751条、4701条、4601条和4401条)。分割窗口大小设定原因与时序数据周期有关,因为仿真数据的周期为20s,所以分割窗口长度k值设定为50、100、200、400分别对应了0.25周期、0.5周期、1周期以及2周期。
[0099]
3、为了提升后续训练模型的训练稳定性,使训练模型的拟合程度最优,对滑动分割的数据进行随机采样处理,即共18454条数据,采样1/3作为训练数据,即约6150条数据。
[0100]
对于训练数据,共包含4种仿真真目标类型以及一种假目标类型,共有5种类型时序数据。每种类型时序数据共包含6150条时序长度为50/100/200/400的时序子集数据。将这些数据作为输入,传输到训练模型。
[0101]
在本实施例中,需要训练的模型为lstm-fcn模型,该lstm-fcn模型包括两部分,分别为多通道的长短期记忆递归网络lstm模型以及全连接卷积神经网络fcn模型。
[0102]
更具体的,长短期记忆递归网络lstm模型的输入包括时序数据类型数目、最长时
序长度以及时序特征数目,除此之外lstm模型的输出为1
×
128维度的张量,lstm模型的层数为1,且lstm模型的dropout层大小设置为0.8。其中时序数据类型数目设为5,最长时序长度设为400,时序特征数目设为15。
[0103]
将输入的时序数据同时输入给全连接卷积神经网络fcn模型,更为具体的,如图2所示,该fcn模型包含了输入层、卷积层(第一层卷积层至第三层卷积层)、批归一化层(第一批归一化层至第三批归一化层)、激活层(第一激活层至第三激活层)、dropout层(第一dropout层至第三dropout层)、se层(第一se层至第三se层)和全局池化层。对于输入层,输入大小为30750
×
15
×
400的张量数据。其中30750为6150
×
5,即共有5种类型时序数据,每种类型时序数据共包含6150条时序子集数据,每一条时序子集数据的长度均为400,其中不足400的使用0进行补全,每一条时序子集数据的宽度均为15,即每一条时序子集数据具有15种时序特征。对于卷积层,共包含三层一维卷积层,第一层卷积层输入维度为15,输出维度为128,卷积核大小为8
×
15;第二层卷积层输入维度为128,输出维度为256,卷积核大小为5
×
128;第三层卷积层输入维度为256,输出维度为128,卷积核大小为3
×
256。每一层卷积后的结果均需要进行批量归一化,将批量归一化结果进行激活函数处理,具体可采用relu函数进行激活,激活后再进行dropout层处理,fcn模型的dropout值设置为0.3。卷积层中的三层一维卷积层是相互链接的,第一层卷积层的输出依次经过第一批归一化层、第一激活层、第一dropout层输入至第一se层(se-module),se层主要为了提升fcn模型对channel特征的敏感性,将第一se层的输出作为第二层卷积层的输入,同理第二层卷积层的输出依次经过第二批归一化层、第二激活层、第二dropout层输入至第二se层,再将第二se层的输出作为第三层卷积层的输入,同理第三层卷积层的输出依次经过第三批归一化层、第三激活层、第三dropout层输入至第三se层;最终将fcn模型的输出以及lstm模型的输出进行拼接(concat函数和全连接层softmax)作为最后的模型输出。
[0104]
通过实验可将lstm-fcn模型的整体参数设定如下:训练过程训练批次设定为100,批处理大小设定为128,学习率设定为0.001,数据集训练、验证、测试比例设定为7:2:1。经过100次训练后,模型的损失率达到稳定状态。
[0105]
经过数据集验证,lstm-fcn模型在分类准确率上与其他时序分类模型相比具备更好的准确度,且由于加入了窗口处理和随机采样方式,lstm-fcn模型的容错率和准确率均有提升,加入了信噪比对测试数据进行处理,在信噪90%-50%区间内,准确率均可以达到80%以上。
[0106]
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。