1.本发明属于自然语言处理及指代消解技术的技术领域,尤其涉及一种参考外部知识的指代消解方法及装置。
背景技术:
2.在语言学中,采用简称或代称来代替已经出现过的某一词语,这种情况称为指代。指代能够避免同一词语反复出现造成语句臃肿和赘述,但也会出现指代不明的问题。将指代同一对象的不同指称划分到一个等价集合的过程称为指代消解。指代消解是nlp领域一项基础性研究,在阅读理解、信息抽取、多轮对话等任务中起到重要作用。
3.指代消解主要经历了从规则到神经网络模型的发展过程。hobbs等人提出一种指代消解算法,采用广度优先算法便利对文本解析生成的句法分析树,并根据手工规则有效匹配实体短语与先行语之间的共指关系。基于规则的指代消解方法通过制定严密的规则约束来达到匹配指代词和先行词的目的,没有很好的扩展性。随着数据规模的扩张,出现了基于统计学算法的指代消解。先行词和指代词之间的共现频率成为研究关系的指标。dagan等提出了一种在大型语料库中自动收集共现模式统计信息的方法,能够达到消除回指指称和句法歧义的效果。随着机器学习的兴起,出现了基于机器学习的指代消解方法。机器学习方法可以认为是规则加统计方法的结合。mccarthy等人提出指称对模型,将指代消解任务转化为判断先行语与指代词之间是否匹配的分类任务。luo等人将文本当中所有指称词组用贝尔树结构进行表示,采用“any”的特征表示形式来获取指代链特征。yang等人采用归纳逻辑编程算法构建实体-指称模型,为组织不同的实体知识和指称提供了一种关系式的方法。iida等人提出一种基于中心理论构建的“tournament”模型,对两个候选先行语进行比较,选择概率大的建立共指关系。近几年,深度学习的发展使得越来越多的神经网络模型用于指定消解。《improving coreference resolution by learning entity-level distributed representations》中提出了一种生成 cluster-pair 向量的方法,并利用聚类的方式进行指代消解。
4.然而指代消解是一项很有挑战的任务,它需要对文本和常识有深刻的理解。例如“我的口袋里装着一个又大又圆的苹果,它快被撑破了。”和“我的口袋里装着一个又大又圆的苹果,它肯定很好吃。”这两句,“它”指代的对象可以是“口袋”也可以是“苹果”。想要实现指代消解必须对句子语义和提及的知识有所了解。《knowledge-aware pronoun coreference resolution》提出了一种可以参考外部知识的指代消解方法,然而这种方法采用的模型结构提取特征能力弱,参考外部知识时也没有将整体句子语义考虑在内。之后的一些基于大模型以文本生成方式来进行指代消解的方法无法参考外部知识进行指代消解。
技术实现要素:
5.针对现有技术不足,本发明提出了一种参考外部知识的指代消解方法。
6.为实现上述目的,本发明的技术方案为:
7.本发明第一方面:一种参考外部知识的指代消解方法,所述方法包括以下步骤:
8.(1)生成训练数据:获取目标文本,标记目标文本句子中的提及作为提及识别模型的训练数据;所述训练数据包括提及识别训练数据和关系分类训练数据;
9.(2)搭建提及识别模型和关系分类模型;
10.(3)利用步骤(1)得到的数据训练提及识别模型和关系分类模型;
11.(4)将训练好的模型用于指代消解;即先利用提及识别模型识别出句子中的提及,指定句子中的任意两个提及,从知识库中检索出指定提及的知识,并拼接到句子中后输入至关系分类模型中,所述关系分类模型则预测输入的提及是否有共指关系。
12.具体地,所述步骤(1)中标记目标文本句子中的提及作为提及识别模型的训练数据,具体为,指定文本句子中的两个或三个提及,检索出指定提及对应的知识,并标注指定提及间是否存在共指关系和存在共指关系的提及,作为关系分类模型的训练数据。
13.具体地,所述步骤(1)中提及识别训练数据用于训练提及识别模型,即对于输入句子,用0表示非提及,1表示提及的开始位置,2表示提及的非开始位置对句子进行标注得到提及识别标签序列。
14.具体地,所述训练提及识别模型时,输入句子,训练模型预测每个字符的标签;训练提及识别模型的损失函数为:
[0015][0016]
其中loss_tag为提及识别的损失,i为第i个位置,n为输入句子的长度,为第i个位置模型的预测类型值,为第i个位置的类型标签,s为输入句子的整数索引向量。
[0017]
具体地,所述步骤(1)中关系分类训练数据用于训练关系分类模型,关系分类模型以“[cls]”开始,之后拼接输入句子,之后拼接“[sep]”,之后拼接指定提及对应的知识,保持长度不超过512;用指定提及码来表示指定提及的信息,将指定的提及信息以012序列的形式表示出来;0表示非指定内容,1表示指定提及的开始位置,2表示指定提及的非开始位置。
[0018]
进一步地,所述步骤(4)中所述关系分类模型预测输入的提及是否有共指关系,其所述关系分类模型在训练时不仅要判断指定提及中是否有共指关系,并标记出有共指关系的提及;具体为:
[0019]
(6.1)当所述关系分类模型输入中指定两个提及时,若这两个提及指代的是同一对象,关系分类模型应该判断有共指关系,并将这两个提及都进行标记;若这两个提及指代的是不同对象,关系分类模型应该判断无共指关系,则并不标记任何提及;
[0020]
(6.2)当所述关系分类模型输入中指定三个提及时,若这三个提及指代的是同一对象,则关系分类模型应该判断有共指关系,并将这三个提及都进行标记;若只有两个指代的是同一对象,则关系分类模型应该判断有共指关系,并将这两个提及进行标记;若三个提及指代的是不同的对象,则关系分类模型应该判断无共指关系,则并不标记任何提及。
[0021]
具体地,所述关系分类模型在训练时不仅要判断指定提及中是否有共指关系,并标记出有共指关系的提及,即训练关系分类模型时,指定两个或三个提及,训练模型判断指
定提及中是否存在共指关系,并标记出存在共指关系的提及,其训练关系分类模型的损失函数为:
[0022][0023]
其中loss_ref为关系分类模型的损失,为关系分类的模型预测值,r为关系分类的标签,sk为输入的句子和知识的拼接文本对应的整数索引向量,mids为输入的指定提及码,i为句子的第i个位置,n为句子的长度,为句子第i个位置模型的预测值,为句子第i个位置的标签。
[0024]
进一步地,所述训练关系分类模型预测时,若只需要指定两个提及,关系分类模型判断指代的两个提及是否有共指关系。
[0025]
具体地,所述步骤(2)中提及识别模型采用在中文语料上预训练过的spanbert模型;所述关系分类模型采用在中文语料上预训练过的roberta模型。
[0026]
本发明的第二方面:一种参考外部知识的指代消解装置,该装置包括以下模块:
[0027]
训练数据生成模块:获取目标文本,标记目标文本句子中的提及作为提及识别模型的训练数据;所述训练数据包括提及识别训练数据和关系分类训练数据;
[0028]
搭建模块:搭建提及识别模型和关系分类模型;
[0029]
模型训练模块:利用步骤(1)得到的数据训练提及识别模型和关系分类模型;
[0030]
指代消解模块:将训练好的模型用于指代消解;即先利用提及识别模型识别出句子中的提及,指定句子中的任意两个提及,从知识库中检索出指定提及的知识,并拼接到句子中后输入至关系分类模型中,所述关系分类模型预测输入的提及是否有共指关系。
[0031]
本发明的有益效果如下:
[0032]
首先提出了一种可以参考外部知识的指代消解方法。在参考外部知识进行指代消解的过程中,考虑了句子整体的语义信息,使得模型可以更好的根据句子语义理解和筛选外部知识;其次,提出的方法在关系分类模型训练过程中,加入了三个提及的情况。指定三个提及的情况下,不仅仅训练模型判断提及间是否存在共指关系,还训练模型标记出存在共指关系的提及。这种训练方法使得模型对提及和共指关系的理解更深刻,使模型有更强的指代消解能力。
附图说明
[0033]
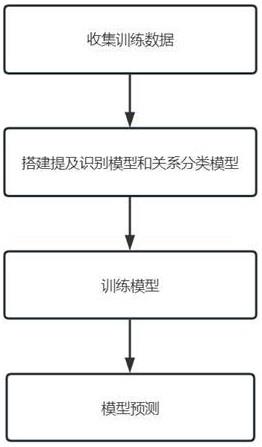
图1为本发明方法的流程图;
[0034]
图2为提及识别模型输入输出示意图;
[0035]
图3为关系分类模型输入输出示意图;
[0036]
图4为本发明的装置流程框图。
具体实施方式
[0037]
下面结合附图,对本发明提出的一种参考外部知识的指代消解方法进行详细说明。在不冲突的情况下,下述的实施例及实施方式中的特征可以相互组合。
[0038]
如图1所示,本发明提出的一种参考外部知识的指代消解方法包括如下步骤:
[0039]
(1)生成训练数据
[0040]
从网上爬取文章段落进行标注,先标记出句子中的提及,再对每个提及从知识库中搜索出对应的知识用于生成训练数据;训练数据包括提及识别训练数据和关系分类训练数据。
[0041]
提及识别训练数据用于训练提及识别模型。如图2所示,用0表示非提及,1表示提及的开始位置,2表示提及的非开始位置对句子进行标注得到提及识别标签序列。以“我的口袋里装着一个又大又圆的苹果,它快被撑破了。”为例,句子中有“我”、“口袋”、“苹果”和“它”四个提及,对应的提及识别标签序列为:“101200000000001201000000”。
[0042]
关系分类训练数据用于训练关系分类模型。关系分类训练数据包括两提及关系分类数据和三提及关系分类数据。两提及关系分类数据指定句子中的两个提及,训练模型判断这两个提及是否有共指关系。三提及关系分类数据指定句子中的三个提及,训练模型判断这三个提及中是否存在共指关系,并标记出存在共指关系的提及。如果三个提及都存在共指关系,则三个提及都要标记出来。
[0043]
如图3所示,以“我的口袋里装着一个又大又圆的苹果,它快被撑破了。”为例,两提及关系分类数据的样例如下:
[0044]
输入文本:“[cls]我的口袋里装着一个又大又圆的苹果,它快被撑破了。[sep]口袋:口袋指指缝在衣服上用以装东西的袋形部分,衣兜;或一种装物用具,一般用布、皮做成;用布、皮等做成的装东西的用具。苹果:又称柰或林檎,是苹果树的果实,一般呈红色,但需视品种而定,富含矿物质和维生素,是人们最常食用的水果之一。有时苹果也指某科技公司,总部位于某加州的某个地区。”[0045]
输入指定提及码:“000120000000000120000000000
……”
;
[0046]
关系分类标签:0;
[0047]
存在共指关系提及标签:000000000000000000000000;
[0048]
输入文本:“[cls]我的口袋里装着一个又大又圆的苹果,它快被撑破了。[sep]口袋:口袋指指缝在衣服上用以装东西的袋形部分,衣兜。或一种装物用具,一般用布、皮做成;用布、皮等做成的装东西的用具。它:代词,代指非人的事物。”[0049]
输入指定提及码:“000120000000000000100000000
……”
;
[0050]
关系分类标签:1;
[0051]
存在共指关系提及标签:001200000000000001000000;
[0052]
三提及关系分类数据如下:
[0053]
输入文本:“[cls]我的口袋里装着一个又大又圆的苹果,它快被撑破了。[sep]我:第一人称代词。口袋:口袋指指缝在衣服上用以装东西的袋形部分,衣兜;或一种装物用具,一般用布、皮做成;用布、皮等做成的装东西的用具。苹果:又称柰或林檎,是苹果树的果实,一般呈红色,但需视品种而定,富含矿物质和维生素,是人们最常食用的水果之一。有时苹果也指某科技公司,总部位于某加州的某个地区。”[0054]
输入指定提及码:“010120000000000120000000000
……”
;
[0055]
关系分类标签:0;
[0056]
存在共指关系提及标签:000000000000000000000000;
[0057]
输入文本:“[cls]我的口袋里装着一个又大又圆的苹果,它快被撑破了。[sep]口
袋:口袋指指缝在衣服上用以装东西的袋形部分,衣兜。或一种装物用具,一般用布、皮做成;用布、皮等做成的装东西的用具。苹果:又称柰或林檎,是苹果树的果实,一般呈红色,但需视品种而定,富含矿物质和维生素,是人们最常食用的水果之一。有时苹果也指某科技公司,总部位于某加州的某个地区。它:代词,代指非人的事物。”[0058]
输入指定提及码:000120000000000120100000000
……
;
[0059]
关系分类标签:1;
[0060]
存在共指关系提及标签:001200000000000001000000;
[0061]
其中输入文本在需要指代消解的句子前拼接[cls],之后拼接[sep]。在[sep]之后拼接指定提及的知识,输入指定提及码将指定的提及信息以012序列的形式表示出来,0表示非指定内容,1表示指定提及的开始位置,2表示指定提及的非开始位置。上述例子中输入指代提及码后面的省略号表示省略的0。关系分类标签表示指定的提及是否有共指关系,0表示无共指关系,1表示有共指关系。由于三提及分类数据输入中指定了三个提及,它们的关系存在如下几种可能:三个提及都没共指关系、只有两个提及有共指关系、三个提及都有共指关系。当三个提及都没共指关系时,关系分类标签为0,否则为1。当关系分类标签为1时,还需要标记出存在共指关系的提及来区分是只有两个提及有共指关系还是三个提及都有共指关系。为了保持关系分类任务数据格式的统一,给两提及关系分类任务也添加存在共指关系提及标签。存在共指关系提及标签用012序列的方式表达了存在共指关系的提及;1表示存在共指关系提及的开始位置,2表示存在共指关系提及的非开始位置,0表示其他。
[0062]
(2)搭建模型
[0063]
搭建模型包括提及识别模型和关系分类模型的搭建。
[0064]
提及识别模型用于标注出句子中的提及。提及识别模型采用在中文语料上预训练过的spanbert模型。spanbert与bert模型结构相同,但在训练任务上有所改进。它采用spanmasking的方式屏蔽连续的随机跨度,而不是随机标记的方式生成训练数据。增加span boundary objective的训练目标,训练跨度边界表示来预测屏蔽跨度的整个内容,而不依赖其中的单个标记表示。在训练任务上的改进使得spanbert很适合实体识别和提及识别这类的任务。
[0065]
关系分类模型用于判断输入的提及中是否存在共指关系,并标记出存在共指关系的提及。关系分类模型的输入是指定了提及的句子和提及相关的知识。在大规模预料上预训练过的roberta模型有很好的特征提取能力,采用roberta中文预训练模型作为关系分类模型。
[0066]
(3)训练模型
[0067]
将提及识别训练数据的输入句子转化为整数索引向量输入spanbert,得到每个位置对应的输出向量。再将每个位置对应的输出向量输入线性层进行分类,得到该位置的标签。对比模型的预测标签序列和标注得到损失。最小化损失来训练模型。提及识别模型的训练过程用公式表示为:
[0068][0069]
[0070]
;
[0071]
其中为spanbert模型输出的编码矩阵,s为输入句子的整数索引向量,为spanbert的编码运算,mlp为前馈神经网络,loss_tag为提及识别的损失,i为第i个位置,n为输入句子的长度,为第i个位置模型的预测类型值,为第i个位置的类型标签,s为输入句子。
[0072]
将关系分类训练数据的输入句子转化为整数索引向量,与指定提及码一起输入模型,训练模型判断是否存在共指关系,并标记出存在共指关系的提及。训练的损失函数为关系分类损失和提及标记损失的和。关系分类模型的训练过程用公式表示为:
[0073]
;
[0074]
;
[0075]
;
[0076]
;
[0077]
其中为roberta模型输出的编码矩阵,roberta_encode为roberta的编码运算,mlp1和mlp2为前馈神经网络运算,loss_ref为关系分类模型的损失,为关系分类的模型预测值,r为关系分类的标签,sk为输入的句子和知识的拼接文本对应的整数索引向量,mids为输入的指定提及码,i为句子的第i个位置,n为句子的长度,为句子第i个位置模型的预测值,为句子第i个位置的标签。
[0078]
(4)模型预测
[0079]
将训练好的提及识别模型和关系分类模型用于指代消解,先用提及识别模型识别出句子中的提及,再检索每个提及对应的知识。将所有两个提及的组合指定出来,拼接对应的知识输入关系分类模型,关系分类模型预测指定的提及是否有共指关系。
[0080]
提及识别模型进行预测时,将句子转化为整数索引列表输入模型,模型将整数索引对应的嵌入向量和位置编码信息相加得到矩阵,用公式表示为:
[0081]
;
[0082]
其中为得到的结果矩阵,s为输入句子的整数索引列表,为获取字嵌入矩阵运算,为获取位置编码矩阵运算。
[0083]
获取位置编码矩阵运算通过构造三角函数来表征位置信息,具体的:
[0084]
;
[0085]
;
[0086]
其中为位置k的编码向量的第2i个分量,为位置k的编码向量的第2i 1个分量,k为位置,i为维度分量。
[0087]
之后将得到的矩阵输入多层encoder得到编码输出。计算过程可表示为:
[0088]
;
[0110]
输入指定提及码:010120000000000000000000000
……
;
[0111]
输入文本:“[cls]我的口袋里装着一个又大又圆的苹果,它肯定很好吃。[sep]我:第一人称代词。苹果:又称柰或林檎,是苹果树的果实,一般呈红色,但需视品种而定,富含矿物质和维生素,是人们最常食用的水果之一。有时苹果也指某科技公司,总部位于某加州的某个地区。”[0112]
输入指定提及码:010000000000000120000000000
……
;
[0113]
输入文本:“[cls]我的口袋里装着一个又大又圆的苹果,它肯定很好吃。[sep]我:
……
它:
……”
;
[0114]
输入指定提及码:010000000000000000100000000
……
;
[0115]
输入文本:“[cls]我的口袋里装着一个又大又圆的苹果,它肯定很好吃。[sep]口袋:
……
苹果:
……”
;
[0116]
输入指定提及码:000120000000000120000000000
……
;
[0117]
输入文本:“[cls]我的口袋里装着一个又大又圆的苹果,它肯定很好吃。[sep]口袋:
……
它:
……”
;
[0118]
输入指定提及码:000120000000000000100000000
……
;
[0119]
输入文本:“[cls]我的口袋里装着一个又大又圆的苹果,它肯定很好吃。[sep]苹果:
……
它:
……”
;
[0120]
输入指定提及码:000000000000000120100000000
……
;
[0121]
将数据输入关系分类模型,模型的计算过程用公式表示为如下形式:
[0122]
;
[0123]
其中为将输入的指定提及码编码为矩阵的运算,sk为输入的句子拼接上知识后的整数索引向量,mids为指定提及码;其余符号与提及识别模型运算的公式表示相同。
[0124]
由于关系分类模型的roberta模型在结构上与提及识别模型的spanbert相同,将关系分类模型roberta模型的运算用公式概括为如下形式:
[0125]
;
[0126]
其中为模型输出的编码矩阵。
[0127]
将[cls]对应的输出编码向量输入前馈网络层进行分类,得到指定提及是否有指定关系的分类结果。公式表达如下:
[0128]
;
[0129]
其中为是否存在共指关系的预测结果,mlp为前馈神经网络,为[cls]对应的输出编码。
[0130]
关系分类模型对所有提及对之间的关系进行预测之后,根据提及之间的共指关系链可以得到指代同一对象的提及集。对于“我的口袋里装着一个又大又圆的苹果,它肯定很好吃。”,关系分类模型应该得到“苹果”和“它”是指同一对象,与“我”和“口袋”构成句子中三个相互独立的对象。
[0131]
图4是根据实施例示出的一种参考外部知识的指代消解装置流程框图。参照图4,该装置包括以下模块:
[0132]
训练数据生成模块:获取目标文本,标记目标文本句子中的提及作为提及识别模
型的训练数据;所述训练数据包括提及识别训练数据和关系分类训练数据;
[0133]
搭建模块:搭建提及识别模型和关系分类模型;
[0134]
模型训练模块:利用步骤(1)得到的数据训练提及识别模型和关系分类模型;
[0135]
指代消解模块:将训练好的模型用于指代消解;即先利用提及识别模型识别出句子中的提及,指定句子中的任意两个提及,从知识库中检索出指定提及的知识,并拼接到句子中后输入至关系分类模型中,所述关系分类模型预测输入的提及是否有共指关系。
[0136]
关于上述实施例中的装置,其中各个模块执行操作的具体方式已经在有关该方法的实施例中进行了详细描述,此处将不做详细阐述说明。
[0137]
对于装置实施例而言,由于其基本对应于方法实施例,所以相关之处参见方法实施例的部分说明即可。以上所描述的装置实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本技术方案的目的。本领域普通技术人员在不付出创造性劳动的情况下,即可以理解并实施。
[0138]
本领域技术人员在考虑说明书及实践这里公开的内容后,将容易想到本技术的其它实施方案。本技术旨在涵盖本技术的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本技术的一般性原理并包括本技术未公开的本技术领域中的公知常识或惯用技术手段。
[0139]
应当理解的是,本技术并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。