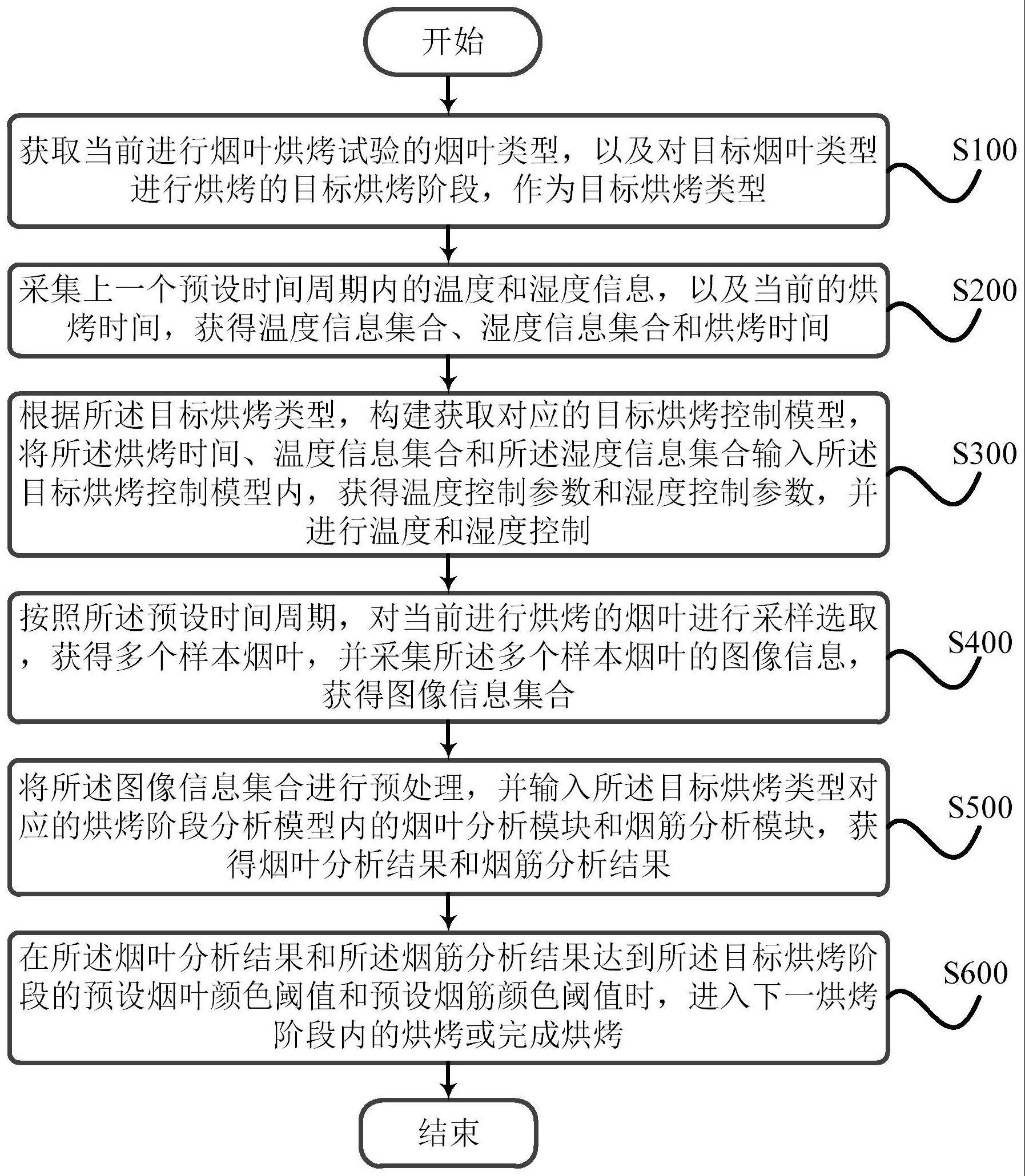
一种基于深度强化学习的溶解氧浓度自适应pid控制方法
技术领域
1.本发明利用基于深度强化学习(drl)的自适应pid控制方法实现污水处理过程中溶解氧(do)浓度的控制,溶解氧(do)浓度的控制作为污水处理的重要环节,既属于污水处理领域,又属于智能控制领域。
背景技术:
2.随着我国工业化、城镇化进程的不断推进,水资源短缺和水污染问题日益突出。中国生态环境部发布的《2021年中国生态环境状态公报》中指出,全国地表水中,iv类~劣v类累计占比达到15%;210个重要湖泊中,iv类~劣v类累计占比达27%,209个监测营养状态的湖库中,27%的重点湖库呈富营养状态。水资源短缺和水污染问题已成为阻碍我国经济和社会发展的主要障碍。如何获取清洁且安全的水资源以及如何及时有效地处理污水,成为当今社会急需解决的问题。因此,污水处理技术迎来了前所未有的发展机遇。研究先进的污水处理控制技术,在保证精确控制的前提下,实现污水处理节能达标是未来污水处理厂的必然发展趋势。
3.溶解氧do浓度是污水处理过程中最重要的一个因素。溶解氧浓度与活性污泥中微生物等有着密切的关系。如果溶解氧浓度过高,会加快微生物的新陈代谢,从而造成池中的悬浮固体的沉降性变差;如果溶解氧浓度过低,会抑制异养微生物和自养微生物的生长,而丝状菌则开始大量繁殖,最终发生污泥膨胀,导致处理失效。同时,溶解氧浓度还对污水处理厂的出水水质和系统运行能耗有着直接的影响。因此,对溶解氧浓度的精确控制是污水处理过程中的重点。
4.传统pid控制由于具有原理结构简单、可靠性高,容易实现的特点,在污水处理厂中得到了广泛的应用。然而在污水处理系统中,由于被控对象具有非线性、时变、大滞后等特点,且受环境温度等外界诸多因素影响较大,导致难以建立精确的数学模型,从而难以确定最佳的控制器参数。此时用传统pid控制则存在控制精度不高、缺乏自学习能力和自适应能力差等问题,故用传统pid控制方法来实现溶解氧do浓度控制具有一定的局限性。因此,寻求一种智能的方法来解决传统pid控制方法在应用于溶解氧do浓度控制时所存在的问题成为亟待解决的问题。
技术实现要素:
5.本发明的目的在于提供一种基于深度强化学习的溶解氧浓度自适应pid控制方法,该方法是利用深度强化学习强大的学习与决策能力实现对pid控制器参数的实时动态调整,从而解决pid控制器应用于溶解氧浓度控制时存在的控制精度不高、自适应能力差等问题。
6.为实现上述目的,本发明采用了如下技术方案及实现步骤:
7.考虑到深度强化学习具有的强大学习与决策能力,将其与传统pid控制相结合,利用深度学习来对pid控制器的参数进行实时动态调整,以弥补传统pid控制的不足。基于深
度强化学习的自适应pid控制方法能够实现对污水处理过程中溶解氧do浓度的精确在线控制,同时还能保障污水处理过程能够高效稳定地运行,具体包括以下步骤:
8.步骤1:根据活性污泥法污水处理过程中的仿真基准1号(bsm1)模型搭建污水处理过程系统wwtps以作为污水处理过程溶解氧浓度pid控制环境;
9.其中,bsm1模型由生化反应池和二沉池构成,而生化反应池又分为5个单元;pid控制器为增量式pid控制器,用于控制生化反应池第五单元的曝气量以实现对第五单元的溶解氧浓度的跟踪控制,具体由以下方程设计:
[0010][0011]
其中,u(k)为k时刻的曝气量为k-1时刻的曝气量,δu(k)为k时刻的曝气量增量;k
p
,ki,kd分别为比例、积分、微分系数;e(k)=r
in
(k)-y
out
(k)为k时刻溶解氧浓度的实际测量值r
in
(k)与k时刻期望的溶解氧浓度y
out
(k)之差,δe(k)=e(k)-e(k-1)表示当前时刻误差与上一时刻误差之差,δ
′
e(k)定义为:
[0012]
δ
′
e(k)=e(k)-2e(k-1) e(k-2)#(2)
[0013]
其中,e(k-1)、e(k-2)分别为在k-1、k-2时刻的溶解氧浓度的实际测量值与期望的溶解氧浓度之差。
[0014]
步骤2:确定状态空间、动作空间以及奖励函数,具体为:
[0015]
步骤2-1:根据溶解氧浓度的控制误差确定状态空间s;
[0016]
其中,状态空间s包含三个元素:溶解氧浓度控制误差e、δe以及δ
′
e,即s=[e,δe,δ
′
e];
[0017]
步骤2-2:根据步骤1中的待优化的pid控制器的参数确定动作空间a;
[0018]
其中,动作空间a包含pid控制器的三个参数:比例系数k
p
、积分系数ki以及微分系数kd,即a=[k
p
,ki,kd];
[0019]
步骤2-3:根据溶解氧浓度的实际测量值与期望的溶解氧浓度之差确定奖励r;
[0020]
其中,k时刻的奖励rk计算如下:
[0021]rk
=-e(k)#(3)
[0022]
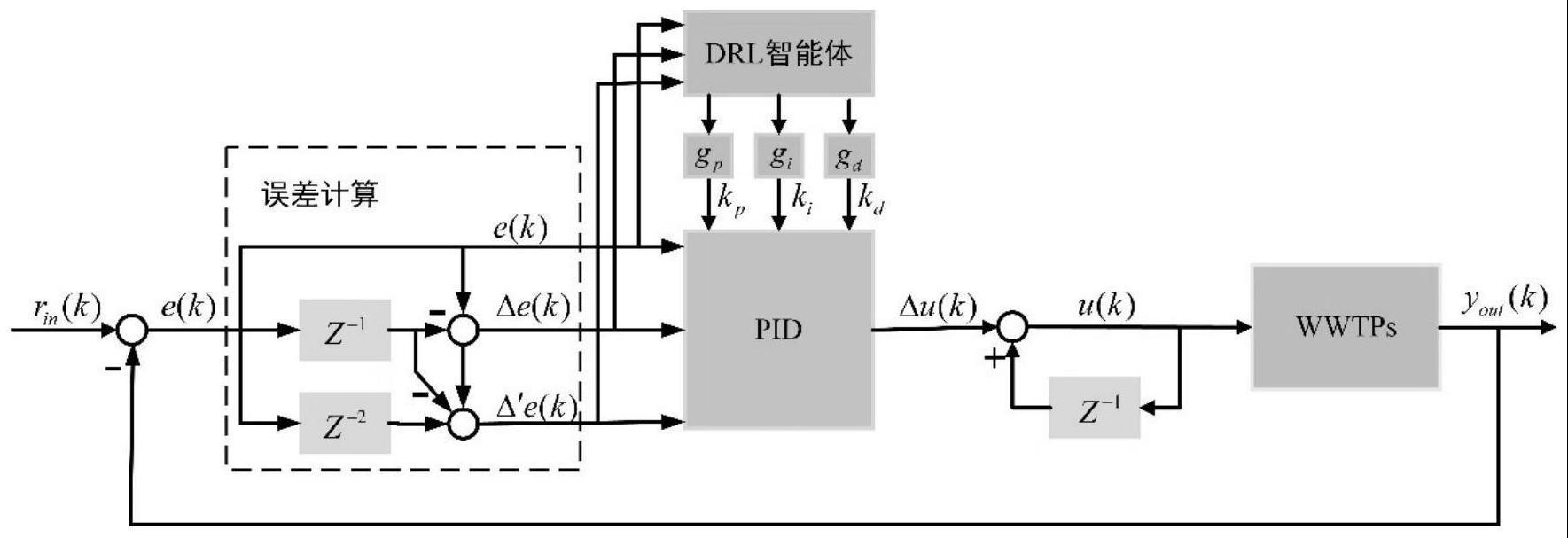
步骤3:在步骤1和2的基础上根据ddpg算法构建深度强化学习drl智能体模型,其中drl智能体模型主要包括评价网络模块、动作网络模块以及经验回放模块三个模块,每个模块的构建步骤如下:
[0023]
步骤3-1:利用深度神经网络构建评价网络模块;
[0024]
其中,评价网络用于拟合q函数q(s,a|θ),网络的参数为θ,输入为步骤2中确定的状态s和动作a,输出为q函数的值,即q=q(s,a|θ);评价网络模块包括实际评价网络q(s,a|θq)和目标评价网络q
′
(s,a|θq)两个网络,并且两个网络的结构相同,都包含四层全连接网络层,分别为一层输入层、两层隐含层和一层输出层;其中隐含层均采用relu函数作为激活函数,并且隐含层节点数目均相同;
[0025]
步骤3-2:利用深度神经网络构建动作网络模块;
[0026]
其中,动作网络用于拟合确定性策略函数μ(s|θ),网络的参数为θ,输入为步骤2中确定的状态s,输出是确定性策略函数μ(s|θ)的值,同时也是步骤2中确定的动作a,即a=μ
(s|θ);动作网络模块包括实际动作网络μ(s|θ
μ
)和目标动作网络μ
′
(s|θ
μ
)两个网络,并且两个网络的结构相同,都包含四层全连接网络层,分别为一层输入层、两层隐含层和一层输出层;其中隐含层均采用relu函数作为激活函数,并且隐含层节点数目均相同,而输出层均采用tanh函数作为激活函数;
[0027]
步骤3-3:构建经验回放模块,用于存储drl智能体在步骤1中搭建的环境中进行训练时生成的经验数据。
[0028]
步骤4:在步骤1中搭建的环境中训练深度强化学习drl智能体,具体包括如下子步骤:
[0029]
步骤4-1:对步骤3中构建的深度强化学习drl智能体进行初始化,具体为:
[0030]
步骤4-1-1:随机初始化实际评价网络q(s,a|θq)和实际动作网络μ(s|θμ)的参数θq、θ
μ
,并通过这两个网络参数来初始化目标评价网络q
′
(s,a|θq)和目标动作网络μ
′
(s|θ
μ
)的参数θq←
θq和θ
μ
←
θ
μ
;初始化四个网络模型的学习率,并选择adam梯度下降算法来更新网络参数;
[0031]
步骤4-1-2:初始化一个空的空间r作为经验回放模块存储经验数据的空间;
[0032]
步骤4-2:设置总的训练轮数为n,每轮的训练时长为d天,当前总训练论数n=0,同时采用bsm1提供的干燥天气下的14天入水数据中的前7天入水数据作为训练时wwtps的入水数据;
[0033]
步骤4-3:初始化步骤1搭建的环境,具体包括:
[0034]
步骤4-3-1:初始化生化反应池、二沉池以及入水,并设置每隔15分钟变换一次入水;
[0035]
步骤4-3-2:初始化增量式pid控制器,具体为:
[0036]
初始化控制器参数以及误差计算模块,其中误差计算模块会对当前时刻、上一时刻以及上上时刻的误差进行采样和记忆,并通过计算得到控制器参数对应的误差e、δe以及δ
′
e;
[0037]
步骤4-4:令k=1,采样时间间隔timestep=15/(60*24*20)天,初始的溶解氧浓度期望值y
out
=2mg/l,溶解氧浓度期望值y
out
更新时间为l小时,当前溶解氧浓度期望值的总使用时间h=1;
[0038]
步骤4-5:若h*timestep>=l,则h=1,并从1.8、1.9、2.0、2.1、2.2这几个溶解氧浓度期望值中选择一个作为接下来的溶解氧浓度期望值y
out
;若h*timestep<l,则h 1;
[0039]
步骤4-6:将k时刻的溶解氧浓度的采样值r
in
(k)与当前的溶解氧浓度期望值y
out
做差,得到k时刻溶解氧浓度的误差值e(k),然后将e(k)输入到误差计算模块中,与k-1和k-2时刻的误差值进行计算,得到一组输出量xk=[e(k),δe(k),δ
′
e(k)];
[0040]
步骤4-7:将步骤4-6得到的xk输入到drl智能体中的实际动作网络μ(s|θ
μ
)中得到智能体输出的动作a
′k=μ(xk|θ
μ
),然后根据式(4)输出pid控制器的新参数k=[k
p
,ki,kd];
[0041]
k=(a
′k nk)
·
g#(4)
[0042]
其中nk是一个高斯扰动,ak=(a
′k nk)∈[0,1],用于调节三个参数的大小;
[0043]
步骤4-8:将步骤4-6得到的xk以及步骤4-7得到的pid控制器的新参数k输入到pid控制器中,并根据式(1)计算生化反应池第五单元的曝气量
[0044]
步骤4-9:将生化反应池第五单元的曝气量设置为然后在下一采样时刻重复步骤4-6得到误差计算模块的输出量x
k 1
,并根据x
k 1
和式(3)计算奖励rk;
[0045]
步骤4-10:将元组(xk,ak,rk,x
k 1
)存储到经验回放模块中;
[0046]
步骤4-11:设定网络模型训练时的批尺寸batch_size=b,当前经验回放模块中的元组数量为m,若b<m,则进入步骤4-12更新drl智能体中的四个网络的参数,否则进入步骤4-13;
[0047]
步骤4-12:从经验回放模块中随机选择b条元组作为训练数据,然后对drl智能体中的四个网络进行训练并更新他们的参数,其中四个网络的参数的更新方法如下:
[0048]
步骤4-12-1:将式(5)作为实际评价网络q(s,a|θq)的损失函数,利用梯度下降算法更新实际评价网络的参数θq:
[0049][0050]
其中,yk=rk γq
′
(s
k 1
,μ
′
(s
k 1
|θ
μ
′
)|θq′
),sk、s
k 1
分别为xk和x
k 1
,γ∈[0,1]为折扣因子;
[0051]
步骤4-12-2:更新完实际评价网络的参数后,再根据式(6)计算策略梯度,并利用梯度下降算法更新实际动作网络μ(s|θ
μ
)的参数θ
μ
:
[0052][0053]
步骤4-12-3:利用更新后的实际评价网络和实际动作网络的参数θq和θ
μ
对目标评价网络和目标动作网络的参数θq和θ
μ
进行更新:
[0054][0055]
其中,ε为更新率;
[0056]
步骤4-13:若(k*timestep)<d,则k 1,进入步骤4-5,继续在此轮内进行训练;若(k*timestep)>=d且n<n-1,则当前总训练轮数n 1,进入步骤4-3,开始下一轮训练;若(k*timestep)>=d且n>=n-1,则完成训练,导出训练后的深度强化学习智能体。
[0057]
步骤5:将训练好的drl智能体与pid控制器相结合实现自适应pid控制器,并将该控制器应用到bsm1基准仿真平台中,实现生化反应池中的第五单元的溶解氧浓度的精确控制,具体控制过程为:
[0058]
步骤5-1:将当前采样时刻的溶解氧浓度的采样值r
in
与当前的溶解氧浓度期望值y
out
做差,得到当前采样时刻的溶解氧浓度的误差值e,然后将e输入到误差计算模块中,与上一采样时刻和上上采样时刻的误差值进行计算,得到一组输出量x=[e,δe,δ
′
e];
[0059]
步骤5-2:将步骤5-1得到的x输入到drl智能体中的实际动作网络μ(s|θ
μ
)中得到智能体输出的动作a=μ(x|θ
μ
),然后根据式(8)输出自适应pid控制器的新参数k=[k
p
,ki,
kd];
[0060]
k=a
·
g#(8)
[0061]
步骤5-3:将步骤5-1得到的x以及步骤5-2得到的自适应pid控制器的新参数k输入到自适应pid控制器中,并根据式(1)得到自适应pid控制器的输出u;
[0062]
步骤5-4:根据自适应pid控制器的输出u调节生化反应池第五单元的曝气量然后在下一采样时刻重复上述步骤,实现溶解氧浓度的精确控制。
[0063]
本发明的创造性主要体现在:
[0064]
(一)本发明针对污水处理过程具有非线性、时变、大滞后等特点,将深度强化学习引入到污水处理过程溶解氧浓度pid控制中。深度强化学习能较好的跟环境交互,具有自学习功能,能够适应不确定系统的动态特性,因此能适应污水处理过程复杂多变的特性并提高pid控制器的自适应能力。
[0065]
(二)本发明采用了基于深度强化学习的溶解氧浓度自适应pid控制方法对污水处理过程溶解氧do浓度进行在线控制,该方法较好地解决了非线性系统难以控制的问题,实现了溶解氧do浓度的精确在线控制,同时还解决了传统pid控制器应用于污水处理过程溶解氧do浓度控制时存在控制精度不高、稳定性不好等问题。
附图说明
[0066]
图1是基于深度强化学习的溶解氧浓度自适应pid控制方法的系统框图;
[0067]
图2是污水处理过程溶解氧浓度pid控制环境wwtps的示意图;
[0068]
图3是基于ddpg算法的深度强化学习drl智能体的结构及更新流程图;
[0069]
图4是动作网络结构图;
[0070]
图5是评价网络结构图;
[0071]
图6是本发明所述实例中基于drl的自适应pid控制器的溶解氧浓度跟踪控制图;
[0072]
图7是本发明所述实例中基于drl的自适应pid控制器的溶解氧浓度跟踪误差图。
具体实施方式
[0073]
为了使本发明的目的,技术方案及要点更加清楚明白,以下结合附图及实施实例,对本发明进行进一步详细说明。应当理解,此处描述的具体实施实例仅用以解释本发明,并不用于限定本发明。
[0074]
本发明提供了一种基于深度强化学习的溶解氧浓度自适应pid控制方法,该自适应pid控制器是基于深度强化学习方法,通过深度强化学习drl智能体实现对pid控制器参数的实时动态调整,从而解决了pid控制器应用于溶解氧浓度控制时存在的控制精度不高、自适应能力差等问题。该方法的系统框图如图l所示。
[0075]
该方法的实施方法如下:
[0076]
步骤1:根据活性污泥法污水处理过程中的仿真基准1号(bsm1)模型搭建图2所示的污水处理过程系统wwtps以作为污水处理过程溶解氧浓度pid控制环境,具体步骤如下:
[0077]
步骤1-1:根据bsm1模型构建生化反应池和二沉池;
[0078]
其中,生化反应池包含5个单元,其中前两个单元为缺氧区,主要进行的是反硝化反应过程:在缺氧环境下,反硝化细菌利用有机碳和硝酸盐为供体,将处理过程中硝态氮还
原为氮气的过程。其中后三个单元为好氧区,主要进行的是硝化反应过程:在好氧环境下,硝化细菌将处理过程中的氨氮氧化成硝酸盐的过程。二沉池划定为10层,主要进行泥水分离过程,经过污水处理后的上清液通过二沉池上层排入到受纳水体,而污泥则通过下层排出,一部分作为剩余污泥进行处理,另一部分经过外回流回到生化反应池作为反应载体,继续参与污水的生物处理过程;
[0079]
步骤1-2:构建pid控制器作为生化反应池第五单元的溶解氧浓度控制器;
[0080]
其中,pid控制器采用增量式pid控制器,具体由以下方程设计:
[0081][0082]
其中,u(k)为k时刻的曝气量为k-1时刻的曝气量,δu(k)为k时刻的曝气量增量;k
p
,ki,kd分别为比例、积分、微分系数;e(k)=r
in
(k)-y
out
(k)为k时刻溶解氧浓度的实际测量值r
in
(k)与k时刻期望的溶解氧浓度y
out
(k)之差,δe(k)=e(k)-e(k-1)表示当前时刻误差与上一时刻误差之差,δ
′
e(k)定义为:
[0083]
δ
′
e(k)=e(k)-2e(k-1) e(k-2)#(10)
[0084]
其中,e(k-1)、e(k-2)分别为在k-1、k-2时刻的溶解氧浓度的实际测量值与期望的溶解氧浓度之差。
[0085]
步骤2:确定状态空间、动作空间以及奖励函数,具体为:
[0086]
步骤2-1:根据溶解氧浓度的控制误差确定状态空间s;
[0087]
其中,状态空间s包含三个元素:溶解氧浓度控制误差e、δe以及δ
′
e,即s=[e,δe,δ
′
e];
[0088]
步骤2-2:根据步骤1中的待优化的pid控制器的参数确定动作空间a;
[0089]
其中,动作空间a包含pid控制器的三个参数:比例系数k
p
、积分系数ki以及微分系数kd,即a=[k
p
,ki,kd];
[0090]
步骤2-3:根据溶解氧浓度的实际测量值与期望的溶解氧浓度之差确定奖励r;
[0091]
其中,k时刻的奖励rk计算如下:
[0092]rk
=-e(k)#(11)
[0093]
步骤3:在步骤1和2的基础上根据ddpg算法构建图3中所示的深度强化学习drl智能体模型,其中drl智能体模型主要包括评价网络模块、动作网络模块以及经验回放模块三个模块,每个模块的构建步骤如下:
[0094]
步骤3-1:利用深度神经网络构建评价网络模块;
[0095]
其中,评价网络的结构如图5所示,输入为步骤2中确定的状态s和动作a,输出为q函数的值,即q=q(s,a|θ);评价网络模块包括实际评价网络q(s,a|θq)和目标评价网络q
′
(s,a|θq)两个网络,并且两个网络的结构相同,都包含四层全连接网络层,分别为一层输入层、两层隐含层和一层输出层;其中隐含层均采用relu函数作为激活函数,并且隐含层节点数目均为256;
[0096]
步骤3-2:利用深度神经网络构建动作网络模块;
[0097]
其中,动作网络的结构如图4所示,输入为步骤2中确定的状态s,输出是步骤2中确定的动作a,即a=μ(s|θ);动作网络模块包括实际动作网络μ(s|θ
μ
)和目标动作网络μ
′
(s|
θ
μ
)两个网络,并且两个网络的结构相同,都包含四层全连接网络层,分别为一层输入层、两层隐含层和一层输出层;其中隐含层均采用relu函数作为激活函数,并且隐含层节点数目均为256,而输出层均采用tanh函数作为激活函数;
[0098]
步骤3-3:构建经验回放模块,用于存储drl智能体在步骤1中搭建的环境中进行训练时形成的经验数据。
[0099]
步骤4:在步骤1中搭建的环境中训练深度强化学习drl智能体,具体包括如下子步骤:
[0100]
步骤4-1:对步骤3中构建的深度强化学习drl智能体进行初始化,具体为:
[0101]
步骤4-1-1:随机初始化实际评价网络q(s,a|θq)和实际动作网络μ(s|θ
μ
)的参数θq、θ
μ
,并通过这两个网络参数来初始化目标评价网络q
′
(s,a|θq)和目标动作网络μ
′
(s|θ
μ
)的参数θq←
θq和θ
μ
←
θ
μ
;初始化四个网络模型的学习率,其中动作网络的学习率为1*10-4
,评价网络的学习率为3*10-4
,并选择adam梯度下降算法来更新网络参数;
[0102]
步骤4-1-2:初始化一个空的容量大小为3*105的空间r作为经验回放模块存储经验数据的空间;
[0103]
步骤4-2:设置总的训练轮数为n=180,每轮的训练时长为d=1天,当前总训练论数n=0,同时采用bsm1提供的干燥天气下的14天入水数据中的前7天入水数据作为训练时wwtps的入水数据;
[0104]
步骤4-3:初始化步骤1搭建的环境,具体包括:
[0105]
步骤4-3-1:初始化生化反应池、二沉池以及入水,并设置每隔15分钟变换一次入水;
[0106]
步骤4-3-2:初始化增量式pid控制器,具体为:
[0107]
初始化控制器参数:k
p
=200,ki=15,kd=2;初始化误差计算模块:当前时刻、上一时刻以及上上时刻误差为0;
[0108]
步骤4-4:令k=1,采样时间间隔timestep=15/(60*24*20)天,初始的溶解氧浓度期望值y
out
=2mg/l,溶解氧浓度期望值y
out
更新时间为l=4小时,当前溶解氧浓度期望值的总使用时间h=1;
[0109]
步骤4-5:若h*timestep>=l,则h=1,并从1.8、1.9、2.0、2.1、2.2这几个溶解氧浓度期望值中选择一个作为接下来的溶解氧浓度期望值y
out
;若h*timestep<l,则h 1;
[0110]
步骤4-6:将k时刻的溶解氧浓度的采样值r
in
(k)与当前的溶解氧浓度期望值y
out
做差,得到k时刻溶解氧浓度的误差值e(k),然后将e(k)输入到误差计算模块中,与k-1和k-2时刻的误差值进行计算,得到一组输出量xk=[e(k),δe(k),δ
′
e(k)];
[0111]
步骤4-7:将步骤4-6得到的xk输入到drl智能体中的实际动作网络μ(s|θ
μ
)中得到智能体输出的动作a
′k=μ(xk|θ
μ
),然后根据式(12)输出pid控制器的新参数k=[k
p
,ki,kd];
[0112]
k=(a
′k nk)
·
g#(12)
[0113]
其中用于调节三个参数的大小;
[0114]
步骤4-8:将步骤4-6得到的xk以及步骤4-7得到的pid控制器的新参数k输入到pid控制器中,并根据式(9)计算生化反应池第五单元的曝气量
[0115]
步骤4-9:将生化反应池第五单元的曝气量设置为然后在下一采样时刻重复步骤4-6得到误差计算模块的输出量x
k 1
,并根据x
k 1
和式(11)计算奖励rk;
[0116]
步骤4-10:将元组(xk,ak,rk,x
k 1
)存储到经验回放模块中;
[0117]
步骤4-11:设定网络模型训练时的批尺寸b=256,当前经验回放模块中的元组数量为m,若b<m,则进入步骤4-12更新drl智能体中的四个网络的参数,否则进入步骤4-13;
[0118]
步骤4-12:从经验回放模块中随机选择b条元组作为训练数据,然后对drl智能体中的四个网络进行训练并更新他们的参数,其中四个网络的参数的更新方法如下:
[0119]
步骤4-12-1:将式(13)作为实际评价网络q(s,a|θq)的损失函数,利用梯度下降算法更新实际评价网络的参数θq:
[0120][0121]
其中,yk=rk γq
′
(s
k 1
,μ
′
(s
k 1
|θ
μ
′
)|θq′
),sk、s
k 1
分别为xk和x
k 1
,γ=0.99为折扣因子;
[0122]
步骤4-12-2:更新完实际评价网络的参数后,再根据式(14)计算策略梯度,并利用梯度下降算法更新实际动作网络μ(s|θ
μ
)的参数θ
μ
:
[0123][0124]
步骤4-12-3:利用更新后的实际评价网络和实际动作网络的参数θq和θ
μ
对目标评价网络和目标动作网络的参数θq和θ
μ
进行更新:
[0125][0126]
其中,ε=0.001为更新率;
[0127]
步骤4-13:若(k*timestep)<d,则k 1,进入步骤4-5,继续在此轮内进行训练;若(k*timestep)>=d且n<n-1,则当前总训练轮数n 1,进入步骤4-3,开始下一轮训练;若(k*timestep)>=d且n>=n-1,则完成训练,导出训练后的深度强化学习智能体。
[0128]
步骤5:将训练好的drl智能体与pid控制器相结合实现自适应pid控制器,并将该控制器应用到bsm1基准仿真平台中,实现生化反应池中的第五单元的溶解氧浓度的精确控制,具体控制过程为:
[0129]
步骤5-1:将当前采样时刻的溶解氧浓度的采样值r
in
与当前的溶解氧浓度期望值y
out
做差,得到当前采样时刻的溶解氧浓度的误差值e,然后将e输入到误差计算模块中,与上一采样时刻和上上采样时刻的误差值进行计算,得到一组输出量x=[e,δe,δ
′
e];
[0130]
步骤5-2:将步骤5-1得到的x输入到drl智能体中的实际动作网络μ(s|θ
μ
)中得到智能体输出的动作a=μ(x|θ
μ
),然后根据式(16)输出自适应pid控制器的新参数k=[k
p
,ki,kd];
[0131]
k=a
·
g#(16)
[0132]
步骤5-3:将步骤5-1得到的x以及步骤5-2得到的自适应pid控制器的新参数k输入到自适应pid控制器中,并根据式(9)得到自适应pid控制器的输出u;
[0133]
步骤5-4:根据自适应pid控制器的输出u调节生化反应池第五单元的曝气量然后在下一采样时刻重复上述步骤,实现溶解氧浓度的精确控制。图6和图7为基于深度强化学习的自适应pid控制器的溶解氧浓度的控制效果图,从图6可以看出该控制器可以对溶解氧浓度进行良好的跟踪,即使溶解氧浓度期望值发生改变也能快速的将溶解氧浓度稳定在新的期望值附近,而从图7可以看出该控制器对溶解氧浓度的控制误差主要位于
±
0.02mg/l,基于此结果可知基于深度强化学习的自适应pid控制器与传统pid控制器相比,不仅具有更好的自适应能力,而且还能快速、精准的控制溶解氧的浓度。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。