技术特征:
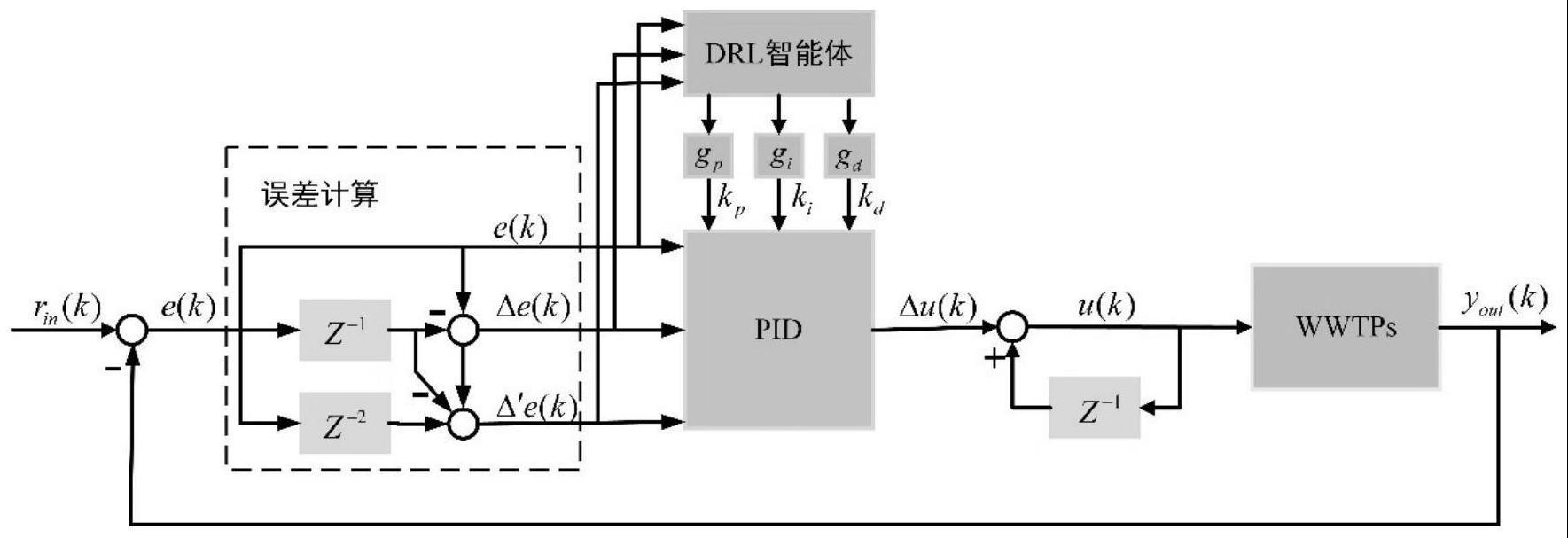
1.一种基于深度强化学习的溶解氧浓度自适应pid控制方法,其特征在于,包括以下步骤:步骤1:根据活性污泥法污水处理过程中的仿真基准1号(bsm1)模型搭建污水处理过程系统wwtps以作为污水处理过程溶解氧浓度pid控制环境;步骤2:确定状态空间、动作空间以及奖励函数;步骤3:在步骤1和2的基础上根据ddpg算法构建深度强化学习drl智能体模型,其中drl智能体模型主要包括评价网络模块、动作网络模块以及经验回放模块三个模块;步骤4:在步骤1中搭建的环境中训练深度强化学习drl智能体;步骤5:将训练好的drl智能体与pid控制器相结合实现自适应pid控制器,并将该控制器应用到bsm1基准仿真平台中,实现生化反应池中的第五单元的溶解氧浓度的精确控制。2.根据权利要求1所述的一种基于深度强化学习的溶解氧浓度自适应pid控制方法,其特征在于,所述步骤1具体包括如下步骤:步骤1-1:根据bsm1模型构建生化反应池和二沉池,其中生化反应池包含五个单元;步骤1-2:构建pid控制器作为生化反应池第五单元的溶解氧浓度控制器,其中pid控制器采用增量式pid控制器,具体由以下方程设计:其中,u(k)为k时刻的曝气量u(k-1)为k-1时刻的曝气量,δu(k)为k时刻的曝气量增量;k
p
,k
i
,k
d
分别为比例、积分、微分系数;e(k)=r
in
(k)-y
out
(k)为k时刻溶解氧浓度的实际测量值r
in
(k)与k时刻期望的溶解氧浓度y
out
(k)之差,δe(k)=e(k)-e(k-1)表示当前时刻误差与上一时刻误差之差,δ
′
e(k)定义为:δe(k)=e(k)-2e(k-1) e(k-2)#(2)其中,e(k-1)、e(k-2)分别为在k-1、k-2时刻的溶解氧浓度的实际测量值与期望的溶解氧浓度之差。3.根据权利要求1所述的一种基于深度强化学习的溶解氧浓度自适应pid控制方法,其特征在于,所述步骤2具体包括如下步骤:步骤2-1:根据溶解氧浓度的控制误差确定状态空间s;其中,状态空间s包含三个元素:溶解氧浓度控制误差e、δe以及δ
′
e,即s=[e,δe,δ
′
e];步骤2-2:根据步骤1中的待优化的pid控制器的参数确定动作空间a;其中,动作空间a包含pid控制器的三个参数:比例系数k
p
、积分系数k
i
以及微分系数k
d
,即a=[k
p
,k
i
,k
d
];步骤2-3:根据溶解氧浓度的实际测量值与期望的溶解氧浓度之差确定奖励r;其中,k时刻的奖励r
k
计算如下:r
k
=-e(k)#(3)。4.根据权利要求1所述的一种基于深度强化学习的溶解氧浓度自适应pid控制方法,其特征在于,所述步骤3中每个模块的构建步骤如下:步骤3-1:利用深度神经网络构建评价网络模块;
其中,评价网络用于拟合q函数q(s,a|θ),网络的参数为θ,输入为步骤2中确定的状态s和动作a,输出为q函数的值,即q=q(s,a|θ);评价网络模块包括实际评价网络q(s,a|θ
q
)和目标评价网络q
′
(s,a|θ
q
′
)两个网络,并且两个网络的结构相同,都包含四层全连接网络层,分别为一层输入层、两层隐含层和一层输出层;其中隐含层均采用relu函数作为激活函数,并且隐含层节点数目均相同;步骤3-2:利用深度神经网络构建动作网络模块;其中,动作网络用于拟合确定性策略函数μ(s|θ),网络的参数为θ,输入为步骤2中确定的状态s,输出是确定性策略函数μ(s|θ)的值,同时也是步骤2中确定的动作a,即a=μ(s|θ);动作网络模块包括实际动作网络μ(s|θ
μ
)和目标动作网络μ
′
(s|θ
μ
′
)两个网络,并且两个网络的结构相同,都包含四层全连接网络层,分别为一层输入层、两层隐含层和一层输出层;其中隐含层均采用relu函数作为激活函数,并且隐含层节点数目均相同,而输出层均采用tanh函数作为激活函数;步骤3-3:构建经验回放模块,用于存储drl智能体在步骤1中搭建的环境中进行训练时生成的经验数据。5.根据权利要求1所述的一种基于深度强化学习的溶解氧浓度自适应pid控制方法,其特征在于,所述步骤4具体包括如下步骤:步骤4-1:对步骤3中构建的深度强化学习drl智能体进行初始化,具体为:步骤4-1-1:随机初始化实际评价网络q(s,a|θ
q
)和实际动作网络μ(s|θ
μ
)的参数θ
q
、θ
μ
,并通过这两个网络参数来初始化目标评价网络q
′
(s,a|θ
q
′
)和目标动作网络μ
′
(s|θ
μ
′
)的参数θ
q
′
←
θ
q
′
和θ
μ
′
←
θ
μ
;初始化四个网络模型的学习率,并选择adam梯度下降算法来更新网络参数;步骤4-1-2:初始化一个空的空间r作为经验回放模块存储经验数据的空间;步骤4-2:设置总的训练轮数为n,每轮的训练时长为d天,当前总训练论数n=0,同时采用bsm1提供的干燥天气下的14天入水数据中的前7天入水数据作为训练时wwtps的入水数据;步骤4-3:初始化步骤1搭建的环境,具体包括:步骤4-3-1:初始化生化反应池、二沉池以及入水,并设置每隔15分钟变换一次入水;步骤4-3-2:初始化增量式pid控制器,具体为:初始化控制器参数以及误差计算模块,其中误差计算模块会对当前时刻、上一时刻以及上上时刻的误差进行采样和记忆,并通过计算得到控制器参数对应的误差e、δe以及δ
′
e;步骤4-4:令初始时刻k=1,采样时间间隔timestep=15/(60*24*20)天,初始的溶解氧浓度期望值y
out
=2mg/l,溶解氧浓度期望值y
out
更新时间为l小时,当前溶解氧浓度期望值的总使用时间h=1;步骤4-5:若h*timestep>=l,则h=1,并从1.8、1.9、2.0、2.1、2.2这几个溶解氧浓度期望值中选择一个作为接下来的溶解氧浓度期望值y
out
;若h*timestep<l,则h 1;步骤4-6:将k时刻的溶解氧浓度的采样值r
in
(k)与当前的溶解氧浓度期望值y
out
做差,得到k时刻溶解氧浓度的误差值e(k),然后将e(k)输入到误差计算模块中,与k-1和k-2时刻的误差值进行计算,得到一组输出量x
k
=[e(k),δe(k),δ
′
e(k)];
步骤4-7:将步骤4-6得到的x
k
输入到drl智能体中的实际动作网络μ(s|θ
μ
)中得到智能体输出的动作a
′
k
=μ(x
k
|θ
μ
),然后根据式(4)输出pid控制器的新参数k=[k
p
,k
i
,k
d
];k=(a
′
k
n
k
)
·
g#(4)其中n
k
是一个高斯扰动,a
k
=(a
′
k
n
k
)∈[0,1],用于调节三个参数的大小;步骤4-8:将步骤4-6得到的x
k
以及步骤4-7得到的pid控制器的新参数k输入到pid控制器中,并根据式(1)计算生化反应池第五单元的曝气量步骤4-9:将生化反应池第五单元的曝气量设置为然后在下一采样时刻重复步骤4-6得到误差计算模块的输出量x
k 1
,并根据x
k 1
和式(3)计算奖励r
k
;步骤4-10:将元组(x
k
,a
k
,r
k
,x
k 1
)存储到经验回放模块中;步骤4-11:设定网络模型训练时的批尺寸batch_size=b,当前经验回放模块中的元组数量为m,若b<m,则进入步骤4-12更新drl智能体中的四个网络的参数,否则进入步骤4-13;步骤4-12:从经验回放模块中随机选择b条元组作为训练数据,然后对drl智能体中的四个网络进行训练并更新他们的参数,其中四个网络的参数的更新方法如下:步骤4-12-1:将式(5)作为实际评价网络q(s,a|θ
q
)的损失函数,利用梯度下降算法更新实际评价网络的参数θ
q
:其中,y
k
=r
k
γq
′
(s
k 1
,μ
′
(s
k 1
∣θ
μ
′
)∣θ
q
′
),s
k
、s
k 1
分别为x
k
和x
k 1
,γ∈[0,1]为折扣因子;步骤4-12-2:更新完实际评价网络的参数后,再根据式(6)计算策略梯度,并利用梯度下降算法更新实际动作网络μ(s|θ
μ
)的参数θ
μ
:步骤4-12-3:利用更新后的实际评价网络和实际动作网络的参数θ
q
和θ
μ
对目标评价网络和目标动作网络的参数θ
q
′
和θ
μ
′
进行更新:其中,ε为更新率;步骤4-13:若(k*timestep)<d,则k 1,进入步骤4-5,继续在此轮内进行训练;若(k*timestep)>=d且n<n-1,则当前总训练轮数n 1,进入步骤4-3,开始下一轮训练;若(k*timestep)>=d且n>=n-1,则完成训练,导出训练后的深度强化学习智能体。6.根据权利要求1所述的一种基于深度强化学习的溶解氧浓度自适应pid控制方法,其特征在于,所述步骤5具体控制过程为:
步骤5-1:将当前采样时刻的溶解氧浓度的采样值r
in
与当前的溶解氧浓度期望值y
out
做差,得到当前采样时刻的溶解氧浓度的误差值e,然后将e输入到误差计算模块中,与上一采样时刻和上上采样时刻的误差值进行计算,得到一组输出量x=[e,δe,δ
′
e];步骤5-2:将步骤5-1得到的x输入到drl智能体中的实际动作网络μ(s|θ
μ
)中得到智能体输出的动作a=μ(x|θ
μ
),然后根据式(8)输出自适应pid控制器的新参数k=[k
p
,k
i
,k
d
];k=a
·
g#(8)步骤5-3:将步骤5-1得到的x以及步骤5-2得到的自适应pid控制器的新参数k输入到自适应pid控制器中,并根据式(1)得到自适应pid控制器的输出u;步骤5-4:根据自适应pid控制器的输出u调节生化反应池第五单元的曝气量然后在下一采样时刻重复上述步骤,实现溶解氧浓度的精确控制。
技术总结
本发明提出了一种基于深度强化学习的溶解氧浓度自适应PID控制方法,实现了污水处理过程中溶解氧DO浓度的精确在线控制;针对污水处理过程中具有不确定性、非线性、强耦合性,控制器参数难以确定,溶解氧DO浓度难以控制的特点,该控制方法将深度强化学习与传统PID控制相结合,通过深度强化学习DRL智能体实现对PID控制器参数的实时动态调整,从而解决了PID控制器应用于溶解氧DO的浓度控制时存在的控制精度不高、自适应能力差等问题;实验结果表明该方法不仅能快速、精准的控制溶解氧DO的浓度以达到精确在线控制的目的,还具有较好的自适应能力,能够在溶解氧DO的浓度期望值发生改变时快速的将溶解氧DO的浓度稳定在新的期望值附近。附近。附近。
技术研发人员:杜胜利 陈培锡 乔俊飞
受保护的技术使用者:北京工业大学
技术研发日:2023.04.20
技术公布日:2023/7/22
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。