1.本发明涉及质谱法和质谱仪。更具体地,本发明涉及质谱法的数据非依赖性分析方法和被配置成执行数据非依赖性分析方法的质谱仪。
背景技术:
2.串联质谱法已成为快速有效地鉴定和/或定量复杂多组分混合物中分析物的首选方法。在一般实践中,串联质谱信息是通过理想地选择和隔离单个离子种类(具有单个质荷比或m/z值或限制范围的m/z值)并使如此隔离的前体离子经受碎片化以产生可用于鉴定单个分析物的产物离子来获得的。离子碎片化可以通过各种方法和机制提供,包含碰撞诱导解离(cid)、红外多光子解离(irmpd)等。在这些解离方法中,将动能或电磁能赋予离子,由此引入的能量可以引发键断裂以形成碎片离子。
3.在一种形式的串联质谱法实验中(称为“ms/ms”或可替代地“ms2”实验),通常但不一定是按顺序隔离(即,通过排出其它离子来纯化)一种或多种特定选定质荷比(m/z)值的离子种类。然后将隔离的离子碎片化,并且对碎片离子进行质量分析。此事件序列可以迭代。具体地,下一个此类“迭代”是选择和隔离特定的碎片离子种类,这些选择的和隔离的碎片离子因此成为新一代的前体离子,并进一步碎片化如此隔离的碎片,然后对所得产物离子进行质量分析。所得产物离子质谱将显示一组碎片化峰,所述碎片化峰可以用于鉴定化合物,并且在许多情况下可以被用作获得与原始分子相关的结构信息的手段,从中生成原始隔离的第一形成的前体离子。
4.通常,复杂或中等复杂结构的电离分子的质谱结构解析通常使用与色谱仪耦接的质谱仪进行。对通过色谱法(例如,液相色谱法(lc)、气相色谱法(gc)、离子色谱法(ic)等)隔离的化合物生成的离子进行质谱法(ms)分析的一般技术用缩写词表示,如“lc-ms”、“gc-ms”和“ic-ms”等。在此类研究中,使用色谱仪将分子的初始混合物至少部分隔离成单独的馏分,并且使用质谱仪尝试鉴定和/或定量每个馏分中的分子。由质谱仪提供的最基本类型的信息是存在于分析的馏分中的离子的质荷比(m/z)和在每个此类m/z值下测量的信号强度的列表。
5.在多肽和蛋白质分子的一般研究中,在某些受控的碎片化条件下,导致碎片离子形成的键断裂基因座被合理地充分理解。因此,可以容易地预测在应用此类受控条件下可能生成的碎片的类型,因此,基本的ms2实验可能足以根据其氨基酸序列鉴定或表征各种蛋白质或多肽分析物。不幸的是,与多肽和蛋白质不同,其它类型的所关注的化合物的碎片化模式无法轻易预测。因此,作为解决此问题的一种方法,已知化合物的质谱数据库,如“mzcloud”(www.mzcloud.org)和“metlin”已经被开发并将继续被开发。因此,如果所需的信息在此类数据库中可用,研究人员或分析员可以通过识别分析物碎片化模式的实验测量值与数据库条目之间的匹配来假设鉴定分析物。
6.开发了一组质谱法分析技术,统称为“数据非依赖性采集”或“数据非依赖性分析”(dia),以试图扩大复杂多组分样品的分析物数量,所述样品可以通过色谱洗脱液的串联质
谱分析进行鉴定和/或定量。近年来,利用dia的质谱法方法越来越重要。自最初的venable实验(venable等人,“从串联质谱定量分析复杂肽混合物的自动方法(automated approach for quantitative analysis of complex peptide mixtures from tandem mass spectra)”,《自然方法(nature methods)》,2004,第1卷(1),第1-7页)以来,基本的dia方案就已为人所知,在所述实验中,连续采集一系列跨越前体范围的ms2扫描以询问样品,所述样品通常从液相色谱法分离装置引入质谱仪。
7.图1是高度示意图,总体以30表示,展示了根据一种称为“swath ms”(gillet等人,数据非依赖性采集生成的ms/ms谱的靶向数据提取:一致和准确蛋白质组分析的新概念(targeted data extraction of the ms/ms spectra generated by data-independent acquisition:a new concept for consistent and accurate proteome analysis,《分子细胞蛋白质组学(mol.cell.proteomics)》,2012,11(6):o111.016717.doi:10.1074/mcp.o111.016717)的数据非依赖性采集方法进行的假设lcms分析期间可能发生的事件的一般顺序,所述方法通常与swath
tm
定量蛋白质组学软件结合使用。在图1中,前体离子或第一代离子的m/z值表示为纵坐标值,并且色谱保留时间值表示为横坐标值。swath ms数据非依赖性程序包含在整个色谱洗脱范围(保留时间范围)内连续获取一系列高分辨率、准确的质量碎片离子谱,方法是在整个所关注的质谱范围(例如400m/z至1200m/z范围)中重复跨过多个(例如三十二个)特定窗口宽度(例如,25da宽度)的离散前体离子隔离窗口。因此,如图1所展示的,所述技术的主要特征是多系列连续的产物离子分析34。每个此类产物离子分析34被表示为阴影框,并且包含以下步骤:在m/z值的限制范围内隔离前体离子,隔离的前体离子的碎片化以生成碎片离子,以及对从隔离的前体离子生成的碎片离子进行质量分析(即碎片化扫描)。前体m/z值的每个限制范围可以被称为“隔离窗口”(或者等效地,“隔离范围”、“隔离的范围”或“隔离箱”)。在已知swath ms技术中使用的隔离窗口的宽度(图1中框34的高度)通常显著大于在标准目标ms2方法中使用的隔离窗口的宽度。例如,从图1的左下位置开始,由前若干个框34表示的隔离范围为400da至430da、420da至450da、440da至470da、460da至490da、480da至510da等。应注意,通过前体离子组的碎片化生成的产物离子本身可以包括不同范围的产物离子m/z值(未通过任何框具体指示)。
8.图1中展示了产物离子分析的两个系列35a和35b。连续隔离窗口(对应于连续产物离子分析)在m/z上彼此部分重叠,以确保在未碎片化的第一代离子的m/z位置上没有m/z空隙。一旦隔离窗口系列覆盖了整个所关注的m/z范围(即一旦达到整个所关注的m/z范围的末端),则以类似的方式从所述范围的相对端开始研究连续产物离子分析的新系列。如本文所使用的,术语“循环时间”是指返回到任何给定前体隔离窗口的采集所需的时间。在每个循环开始时用虚线勾勒的框32描绘了在整个所关注的m/z范围内对前体离子进行高分辨率、准确的质量调查扫描的任选采集。在保留时间范围内对应于任何给定前体质量范围的数据产物离子分析34的总体通常被称为“条带”。一个此类条带在图1中以38示出。
9.在如图1所描绘的收集质谱数据之后,可以通过对数据的数学处理来识别某些目标化合物,其中对质谱库或数据库中列出的条目进行比较和尝试匹配。此类库和数据库可以包含已知化合物的先前确定的参考谱,并且可以包含如质谱线的m/z位置和相对强度以及色谱保留时间和其它相关联的信息等信息。根据已知的dia方法,将相关碎片离子m/z位置、相对强度和洗脱曲线的模式与参考信息相匹配,以识别能够唯一鉴定目标化合物的信
号模式。
10.dia方法因其可重复性而受到高度重视,因为m/z覆盖在所关注的范围内是完整的,并且不需要实时做出依赖于数据的决策。因此,比较大量样品而不可能丢失m/z值的纵向实验是可能的。dia技术也由于其简单被认可——尽管目标ms2实验可能需要用户确定每个化合物在实验中的保留时间以最大化利用仪器资源,但用户进行dia实验需要对样品的了解要少得多。名义上,用户只需要了解要询问的前体m/z范围和典型lc峰值宽度,这将确定在给定时间量内可以用于覆盖所述范围的隔离宽度。例如,如果需要六个数据点来表征化合物从液相色谱仪的洗脱,并且如果lc峰是六秒宽,则表征前体范围的循环时间是一秒,并且扫描范围的大小和质谱仪的速度将决定可以使用什么样的隔离宽度。
11.dia方法也由于其复用能力被认可。尽管如此,数据非依赖性分析的这一重要特征也是其主要弱点。传统上,dia实验需要使用宽m/z隔离窗口(也称为“箱”),以便能够在合理的时间量内扫描给定范围的前体离子m/z。通过使用大隔离宽度,可以一次传输和碎片化多个前体。然而,所得到的多路复用ms2谱的复杂性可能会给碎片离子分配到其对应的前体造成困难。因此,隔离宽度的优化对于最大化dia数据的有用性至关重要。为此,bonner和tate(美国授权前公开第2016/0079047号)描述了一种使用可变隔离宽度作为用户期望分析或以其它方式存在于样品中的化合物密度(在m/z空间中)的函数的方法。bonner和tate方法依赖于对样品中化合物质荷值的概率密度的了解。虽然在许多情况下可以确定这种分布,但更有用的方法是只取决于用户打算分析的化合物,而不取决于样品基质背景中发现的另外的种类的性质。另外,bonner和tate方法对具有低化合物密度的前体使用更大的隔离,这并不一定意味着排除了不同前体过渡之间的干扰。因此,本领域仍然需要提高dia质谱分析的效率。
技术实现要素:
12.在上述背景下,本发明人认为,在某些情况下,可以改进上文描述的传统dia技术。任何dia实验都取决于ms2谱与谱库的比较,无论是在计算机中或实验中生成的。因此,待分析的可能化合物的可行空间通常是已知的。在许多情况下,研究人员关注一个子集或某个类别的化合物。可以利用缩小可行化合物空间来减少询问化合物所需的获取质谱的数量,从而允许使用更小的隔离宽度并提高数据质量。
13.本文公开了执行数据非依赖性采集的方法,所述方法减少了表征一组化合物所需的采集数量,同时维持固定的隔离宽度。根据一些实施例,确定在特定隔离宽度下分析化合物的完整前体范围所需的全套m/z箱。然而,根据各种实施例,在ms2实验中仅包含已知含有一种或多种所关注的化合物的那些箱。与使用传统方法(本文称为“原初”方法,因为其没有对所关注的分析物的数量和m/z分布进行假设)相比,分析具有稀疏前体密度的质量区域更有效,这将包含在不存在预期化合物的质量区域中的采集。可以使用非常窄的前体离子隔离窗口(如宽度在1th至4th范围内的隔离窗口)来隔离具有稀疏前体离子密度的质量区域。
14.因此,在本教导的第一方面,提供了一种对所关注的化合物类别的化合物进行数据非依赖性质谱分析的方法,所述方法包括:
15.确定或检索在所关注的质荷(m/z)比范围内所述化合物类别的成员的初级离子种类的数量分布,所述化合物类别的m/z比在所述所关注的m/z比范围的多个m/z子范围中的
每个相应的子范围内;
16.定义由所述所关注的m/z比范围内的有限宽度箱的数量n
sb
组成的集合的m/z位置,所述箱的集合不包含所述所关注的m/z比范围内的m/z子范围,所述所关注的m/z比范围涵盖小于阈值数量t
sb
的所述初级离子种类,其中所述定义基于所述确定的或接收的分布;以及
17.对所述类别的化合物进行串联质谱分析的一个或多个循环,其中串联质谱分析的每个循环包括多个串联质量分析,每个循环的每个串联质量分析都与所述定义的箱中相应的箱内的初级离子种类有关。
18.在本教导的第二方面,提供了一种质谱仪系统,所述质谱仪系统包括:
19.离子源,所述离子源被配置成接收样品的部分,所述样品包括作为所关注的化合物类别的成员的化合物;
20.质量过滤器,所述质量过滤器被配置成接收由所述离子源生成的初级离子种类,所述生成的离子包括所关注的质荷(m/z)比范围;
21.离子碎片化单元,所述离子碎片化单元被配置成从所述质量过滤器接收所述初级离子种类的多个隔离的子集;
22.质量分析器,所述质量分析器被配置成从所述碎片化单元接收通过所述初级离子种类的所述隔离的子集的碎片化而生成的产物离子;
23.检测器,所述检测器被配置成检测从所述质量分析器排出的离子;以及
24.一个或多个可编程处理器,所述一个或多个可编程处理器电耦接到所述质量过滤器、所述离子碎片化单元、所述质量分析器和所述检测器,并且包括计算机可读指令,所述计算机可读指令适用于:
25.从数据库中检索在所述所关注的m/z比范围内所述化合物类别的成员的初级离子种类的数量分布,所述化合物类别的m/z比在所述所关注的m/z范围的多个m/z子范围中的每个相应子范围内;
26.定义由数量n
sb
个有限宽度箱组成的集合在所述所关注的m/z比范围内的m/z位置,所述箱的集合不包含所述所关注的m/z比范围内涵盖小于阈值数量t
sb
个所述初级离子种类的m/z子范围,其中所述定义基于所述检索的分布;并且
27.使所述质量过滤器、离子碎片化单元和质量分析器对所述类别的化合物进行串联质谱分析的一个或多个循环,其中串联质谱分析的每个循环包括多个串联质量分析,每个循环的每个串联质量分析都与所述定义的箱中相应的箱内的初级离子种类有关。
附图说明
28.本发明的上述和各个其它方面将根据以下描述而变得显而易见,所述以下描述仅通过举例的方式并且参考附图给出,所述附图未必按比例绘制,在附图中:
29.图1是在色谱洗脱分析物的常规数据非依赖性质谱分析期间可能获得的一系列假设碎片质谱和任选调查质谱的测序和m/z范围的示意图;
30.图2是mzcloud数据库中列出的工业化学品类别化合物的质荷(m/z)值分布的直方图;
31.图3是在工业化学品类别化合物的600th至700th范围内的质谱箱的图示,其对应
于常规质谱数据非依赖性分析(dia)方法和本文所描述的选定箱dia方法所需的串联质谱(ms2)分析;
32.图4a是mzcloud数据库中列出的天然毒素类别化合物在m/z值上的分布直方图,示出了使用常规dia箱选择方法在一秒内以3th隔离宽度分析的所述类别化合物的数量与可以在与本文所描述的选定箱dia方法相同的实验限制下分析的所述类别化合物的数量之间的比较;
33.图4b是mzcloud数据库中列出的天然产物/药物类别化合物在m/z值上的分布直方图,示出了使用常规dia箱选择方法在一秒内以3th隔离宽度分析的所述类别化合物的数量与可以在与本文所描述的选定箱dia方法相同的实验限制下分析的所述类别化合物的数量之间的比较;
34.图5a是mzcloud数据库中列出的多个化合物类别的类别覆盖率与质谱隔离宽度(以汤姆森(thomsons)为单位)的可实现百分比图,其中类别覆盖率定义为可分析的类别化合物的数量除以所述类别中化合物的总数量,使用具有各种隔离宽度值和1000毫秒的固定循环时间的本教导的方法;
35.图5b是使用本教导的方法在mzcloud数据库中以各种循环时间值和3th的固定隔离宽度列出的多个化合物类别的可实现类别覆盖率与循环时间(以毫秒为单位)的图;
36.图6是根据本教导的方法进行数据非依赖性质谱分析的方法的流程图;并且
37.图7是用于生成和自动分析色谱法/质谱法谱的系统的示意图,所述系统可以与本教导的方法结合使用。
具体实施方式
38.呈现以下描述以使所属领域的技术人员能够制作并使用本发明,并且在特定应用和其要求的情况下提供以下描述。对所描述的实施例的各种修改对于本领域的技术人员将是显而易见的,并且本文的一般原理可以应用于其它实施例。因此,本发明并不限于所示的实施例和实例,而是根据所示和所述的特征和原理给予尽可能广泛的范围。为了更详细地充分理解本发明的特征,请结合以下描述参考图2、3、4a、4b、5a、5b、6和7。
39.在本文中的本发明描述中,应理解,除非另外隐含地或明确地理解或陈述,否则以单数形式出现的词语涵盖其复数对应物,并且以复数形式出现的词语涵盖其单数对应物。此外,应理解,除非另外隐含地或明确地理解或陈述,否则对于本文中描述的任何给定部件或实施例,针对所述部件列出的任何可能的候选或替代方案一般可个别地使用或彼此组合地使用。此外,应理解,如本文所示的附图未必按比例绘制,其中为了本发明的清楚起见可仅仅绘制一些元件。并且,在各个附图中可以重复附图标记以示出对应或类似的元件。另外,应理解,除非另外隐含地或明确地理解或陈述,否则此类候选或替代方案的任何列表仅是示例性的,而不是限制性的。
40.如此文档中所使用的,术语“扫描”、“质量扫描”和“质量分析”当用作动词时可以互换使用,以表示质谱仪的质量分析器部分在执行其鉴定和报告离子种类的m/z值以及离子种类的任何集合中这些离子种类的相对量的一般功能时的操作。术语“扫描”、“质量扫描”和“质量分析”用作名词时可以互换使用,以表示此类操作的结果。在此文档中,术语“扫描”和“质量扫描”不旨在限于扫描型质量分析器的操作和数据结果;相反,这些术语旨在适
用于任何类型的质量分析器的操作和产生的数据。如此文档中所使用的,术语“初级离子”和“初级离子种类”分别用于表示在任何进一步的有意修改之前(如有意碎片化或与表面、分子或试剂离子的其它反应),质谱仪离子源中产生的离子和离子种类。根据这些定义,初级离子和初级离子种类可以包含离子源内或离子转移组件内的无意或不可避免的碎片化。
41.如此文档中所使用的,术语“类别”是指质谱法分析员希望同时检测和/或定量的任何一组化合物(在样品的单组质谱法分析中),这是因为其彼此的化学相似性,因为期望其在一个或多个单独的样品中同时发生(例如,污染物),因为其预测或诊断医学病状的能力,或因为其在被发现存在于某些环境中时呈现健康或安全危害的能力。通常,此类化合物是合成的工业化学品或代谢物化合物,所述化合物包括色谱保留时间数据和保留时间预测工具稀少、不可靠或不可用的小分子。尽管此类化合物可以使用色谱技术互相分离,但色谱数据的稀少可能需要在整个色谱分离过程中对所有此类化合物进行连续分析。
42.考虑用户关注分析标记为属于工业化学品的化合物的情况(如mzcloud数据库中的所列出的),如图2所示。在此情况下,整个类别由427种化合物组成,最小m/z为72th,并且最大m/z为1172th。为了询问具有3th隔离宽度的整个化合物范围,需要(1172-72)/3=367个单独的箱,每个箱对应于367个独立数据采集程序中的相应的一个,每个数据采集程序包含:(1)隔离箱内具有m/z值的初级离子种类;(2)对隔离的初级离子种类进行碎片化以生成一组产物离子(3)在预定的产物离子m/z范围内对产物离子进行质量分析。给定通常期望的lc条件,其中循环时间(即可用于执行所有367次数据采集的时间)不大于一秒,需要367hz的质谱仪分析重复率。然而,对于所描述的类型的分析,常规质谱仪通常可以实现小于100hz至约200hz范围内的分析重复率。包含静电阱的混合质谱仪的分析重复率甚至更低。面对这种困境,在原初箱定义情况下,用户需要做出妥协,要么增加隔离宽度(窗口或箱宽度),要么对产生m/z大于约650th(虚垂直线21)的初级离子种类的化合物进行前述分析。
43.根据本教导,图2所展示的问题的简单解决方案是将前体m/z范围划分为其组分扫描或质量箱,如在正常dia实验中所做的那样,但不对其中没有对应于化合物类别的前体离子的已知m/z值的任何箱进行扫描。图3是工业化学品类别化合物的ms1谱中稀疏分布的600th至700th区域的放大视图。图3中的垂直虚线25表示离子隔离箱的中心,这将使用传统原初箱定义来确定。应注意,使用上述3th箱宽度和一秒的最大可用循环时间的假设,这些原初箱不会扩展到大于约650th的m/z值(图3中的虚垂直线21)。相反,图3中的垂直虚线26表示根据本教导选择的隔离窗口的中心。注意,与传统定义的箱位置不同,这些后者隔离窗口不一定是连续的。相反,选择m/z隔离窗口的位置,以便仅涵盖m/z区域,所述区域包含正在研究的化合物类别的诊断关注的m/z值,如由化合物的初级离子种类的m/z值的分布所确定的(由图2、3、4a和4b中的直方图表示)。因此,根据本教导选择的隔离箱的数量远小于原初箱的数量。在工业化学品类别的情况下,这将分析100%化合物所需的扫描数量从367减少到155,并且相对于使用3th宽的箱的传统原初箱定义方法,可以询问的化合物(即产生m/z值大于650th的初级离子种类的化合物)的数量增加了约百分之五。用户可以决定用此新发现的效率换取更小的隔离宽度,或可替代地可以减少实验时间和lc峰宽度(例如,通过调节色谱梯度洗脱)以实现通量的增加。为简明起见,本文所教导的隔离箱选择程序称为“选定箱”方法。
44.图4a至4b分别展示了在mzcloud数据库中列出的类别的dia分析期间通过本文所
描述的选定箱方法可以实现的相对于传统dia方法的最大和最小效率改进。图4a示出了如mzcloud数据库中定义的天然毒素类别内的化合物的特征主要(前体)离子的m/z值分布。由于此类别化合物的前体离子m/z值在很宽的范围内稀疏分布,因此原初dia方法浪费了在没有发现此化合物组成员的质量区域中进行的多次扫描。因此,鉴于使用选定箱dia方法能够提供类别的所有成员的诊断数据,如虚垂直线42所表示的,使用3th箱宽度的原初dia方法只能实现化合物的69%覆盖率(实线41)。作为对比实例,天然产物/药物类别(图4b)具有非常密集和广泛的前体质量分布,并且相对于原初dia方法,选定箱方法的效率基本上没有差异。
45.为了进一步研究本文描述的新型选定箱方法的效用,对来自mzcloud数据库的17个不同化合物类别的m/z分布进行了研究,每个类别含有31个至10000个化合物。下表1中列出了各种研究的类别。所述研究包含确定每个类别中化合物的馏分,所述类别可以在给定的循环时间和隔离宽度下进行分析。在图5a、5b中,绘制的符号表示类别覆盖率,即在图中所示的给定条件下可以分析的类别的化合物的数量除以所述类别中化合物的总数。绘制的菱形(图5a和回归线51)和正方形(图5b和回归线61)表示使用传统dia程序的理论类别覆盖率,所述程序包含隔离箱的原初定义。图5a至5b中的绘制的圆和回归线52和62表示使用本文所教导的选定箱dia程序的理论类别覆盖。
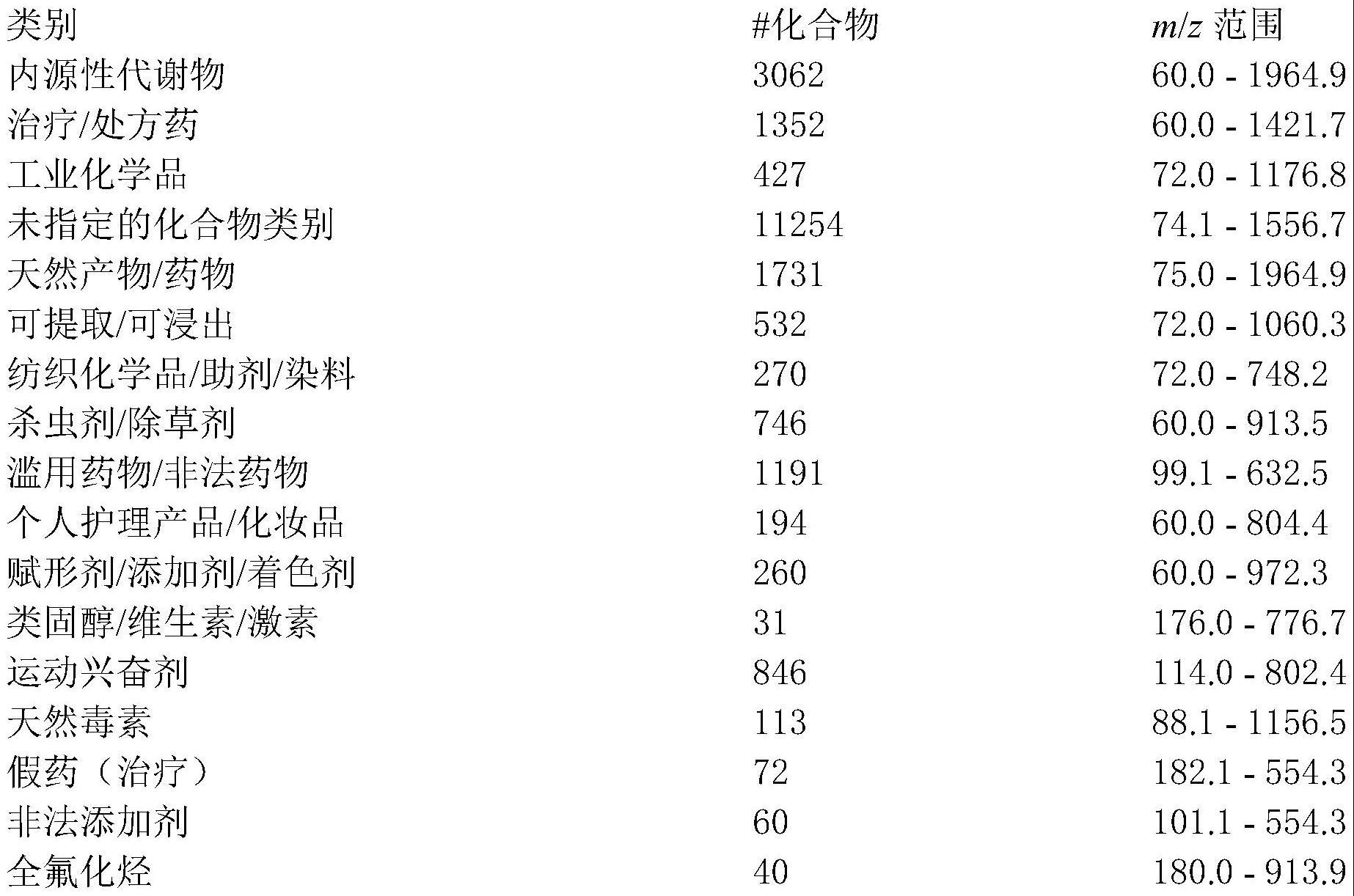
46.表1
[0047][0048]
在第一研究(图5a)中,当隔离宽度变化时,循环时间保持恒定为一秒。随着隔离宽度的增加,分析化合物所需的扫描更少,并且在循环时间内达到了完整类别特征的极限。值得注意的是,在较小的隔离宽度下,方法之间的差异最大,从数据质量的角度来看,这是最有利的。例如,对于1th隔离宽度,选定箱方法的平均类别覆盖率为82%,而原初方法的平均类别覆盖率为29%。在第二研究中,当循环时间变化时,隔离宽度保持恒定为3th,这种情况在实验上对应于lc峰值宽度的增加和更长的实验时间。再次,两种dia方法在长循环时间的
限制下实现了完全类别覆盖,而在最短循环时间内发现了方法之间类别覆盖的最大增加,这从实验通量的角度来看是最期望的。例如,对于500毫秒循环时间,选定箱方法给出了87%的平均类别覆盖率,而原初方法给出了73%的平均类别覆盖率。
[0049]
图6是根据本教导的方法进行数据非依赖性质谱分析的方法的流程图,所述方法采用如本文所教导的隔离箱的选择。在方法650的步骤651中,检索所关注的化合物类别的初级离子种类的质谱位置(即m/z值)的分布(如从数据库或m/z值的其它列表),或通过实验确定。在一些情况下,可以在使用相同的质谱系统执行方法650之前——可能是紧接着之前——进行实验确定。在一些其它情况下,信息可以由用户输入或可以从数据库或其它电子文件中检索。所确定或检索的值的分布通常可以被公式化或表示为直方图,如直方图20(图2至3)、47(图4a)和48(图4b),其分别属于工业化学品、天然毒素和天然产物和药物类别,如mzcloud数据库中所列出的。此类分布通常将被限制(limited to)或限制(restricted to)在某个所关注的或诊断m/z范围,例如质谱仪的测量范围。在一些情况下,步骤651可以包含检索与样品或分析相关的另外的信息,如信息所属的碎片化条件。
[0050]
在方法650的步骤652中,使用在步骤651中确定或检索的m/z分布信息来定义所关注的m/z范围内的箱的总数n
sb
,每个所述箱具有有限宽度,其中所述定义的箱的集合不包含所关注的m/z范围内的m/z值,所述所关注的m/z范围涵盖小于所关注的化合物类别的初级离子种类的m/z值的阈值整数t
sb
。因此,箱的集合被定义为使得在所关注的一般m/z范围内存在不在任何箱内的间隙。每个定义的箱对应于相应的“隔离窗口”,所述隔离窗口包括所关注的m/z范围内的m/z值的受限子集,所述子集随后将被共同隔离(在步骤654中)并同时被碎片化(在步骤655中)。在许多情况下,阈值t
sb
被设置为一(即t
sb
=1),使得箱之间的间隙对应于所关注的化合物类别的初级离子种类的任何质谱线都不存在的m/z区域。尽管如此,可以预期,在一些情况下,阈值可以被设置为大于一的某个整数,由此使得数据非依赖性分析的每个循环(例如,方法650的步骤653至658)优先指向具有特定所关注类别的高密度化合物的m/z区域,同时可能绕过低化合物密度区域的分析。在许多情况下,可以通过将可用于进行串联质谱分析的已知或估计的时间长度te(所述时间长度可用于进行一系列串联质谱分析,例如,串联质谱分析的单个循环,如图1中所示的循环35a、35b之一)除以进行分析的质谱仪的串联质谱分析重复率re来确定箱的数量n
sb
。例如,如果质谱仪接收含有化合物的样品的色谱分离的馏分,则时间te可以对应于已知或预期的色谱洗脱峰宽度。
[0051]
在方法650的步骤652中定义的n
sb
箱由索引变量i(1≤i≤n
sb
)索引,其中箱(1)涵盖在方法650的执行期间分析的最小m/z值,并且箱(n
sb
)涵盖在执行方法650期间分析的最m/z值。根据在步骤652中定义箱的方式,在一对连续索引的箱之间必然存在至少一个m/z间隙,并且事实上可能存在许多此类间隙。此分析策略与已知的常规数据非依赖性分析技术形成对比,其中所关注的分析范围内(或仪器约束的分析范围内)的每个m/z值都包含在至少一个定义的箱内(例如,图1)。传统dia方法非常适合于在m/z空间中关于潜在所关注的化合物的m/z值分布的先验信息很少或没有先验信息的情况。缺乏此类信息,传统dia方法必须在假设潜在所关注的化合物的初级离子种类的m/z值在整个m/z范围内分布均匀的情况下进行。对于生物衍生样品化合物的dia分析,此类假设通常不成立。通过检查各种小分子化合物类别的初级离子种类的m/z分布直方图,如直方图20(图2)、47(图4a)和48(图4b),显然分布不一定均匀。因此,根据本教导的方法通过将串联质量分析限制在预期所有或大部
分所关注的初级离子种类都会出现的m/z区域来利用此m/z分布信息。通过这些方法,使用比使用传统dia分析所需的更少数量的n
sb
个分析箱,由此提高了分析效率。
[0052]
在方法650的步骤652中定义箱中心(m/z)i和任选地箱宽度wi(其中1≤i≤n
sb
)的确切方式可以根据各种程序中的任何一种。例如,根据一个简单程序,整个所关注的m/z范围(例如,100th至1200th)最初可以被划分为初始数量n
初始
个相同的箱,每个箱具有预定宽度w0,在任何一对相邻箱之间没有中间m/z间隙。然后,可以通过简单地丢弃与m/z范围相对应的各个和每个箱,将初始箱的集合减少到最终数量n
sb
,在所述m/z范围内,由类别直方图确定的所关注的类别的化合物的初级离子种类的数量小于阈值t
sb
。
[0053]
根据不同的程序,可以将箱的中心定义为出现在被分析的化合物类别的m/z分布直方图的各个隔离的非零条(例如,图4a的隔离条45)的中心处,或者出现在直方图条的簇或隔离的簇(例如,在图4a中描绘的隔离的簇49)的平均m/z值处。如本文所使用的,直方图“条”是指m/z值的集合和/或集合的图形描述,其中集合的任何一对m/z值之间的最大差值小于或等于在构建直方图期间使用的分箱增量δ(m/z)。此外,如本文所使用的,短语“簇的平均m/z值或直方图条的隔离的簇”可以指平均m/z值、中值m/z值或模式m/z值,这取决于实验要求和分析员的偏好。如果如此定义的箱包括的被分析的所关注的类别的化合物的数量小于阈值数量t
sb
,则可以丢弃此类箱。
[0054]
无论使用何种程序来定义箱位置,如果箱含有的所关注的类别的化合物少于阈值数量t
sb
,则可以丢弃任何箱。然而,作为丢弃不满足阈值标准的箱的替代方案,可以扩展箱的m/z宽度,以便包含所述类别的更多化合物。在相反的情况下,一些定义的箱位置可以包含大量所述类别的化合物,所述化合物超过了每个箱化合物期望的最大数量c
最大
。在此类后一种情况下,一些定义的箱可以在宽度上变窄和/或细分,以将每个箱的化合物数量减少到最大值以下。
[0055]
一旦在步骤652中定义了n
sb
个箱的集合,数据非依赖性分析程序作为步骤653至661的迭代循环进行,如图6所示。步骤653至661的循环的每次迭代对应于产物离子分析34的单个系列或循环35a和35b(图1)。然而,与图1所示的dia分析方案相反,方法650在连续产物离子分析的初级离子隔离窗口之间包含一个或多个m/z间隙,如上所述。任选地,各种箱的宽度可以不均匀。步骤653至657的循环的迭代继续,直到根据预先安排的终止事件完成分析(决策步骤661),如通过色谱仪完成梯度洗脱,所述色谱仪将样品流提供给在方法执行期间使用的质谱仪。
[0056]
方法650的步骤654至661的迭代循环在其自身内包含步骤的嵌套内部循环,例如步骤654至658,其每个迭代对应于单个产物离子分析34。为了准备执行步骤的内部循环,在步骤653中,首先将箱索引变量i设置或重置为其初始值一。随后,在内环的每次迭代期间,使用质量过滤器或其它离子隔离装置隔离(步骤654)与隔离箱中的相应一个隔离箱(即由索引变量的当前值索引的箱)相对应的一组初级离子种类。在步骤655的每次执行期间,在紧接着的前一步骤654中隔离的离子被碎片化,并且生成碎片离子的集合。在步骤655中生成的每个碎片离子集合随后在紧接着执行步骤656的过程中由质量分析器进行质量分析。重复步骤的内部循环,直到在决策步骤657中确定所有定义的n
sb
箱的初级离子种类已经以这种方式被碎片化和隔离。否则,在步骤658中递增箱索引i,并且方法650的执行返回到步骤654。
[0057]
图7是根据本教导的用于生成并自动分析色谱法/质谱法谱的系统100的示意图。根据众所周知的色谱原理,如液相色谱仪、高效液相色谱仪或超高效液相色谱仪等色谱仪133接收分析物混合物的样品132,并将分析物混合物至少部分地分离成单独的化学组分。在不同的各个时间将至少部分分离的化学组分转移到质谱仪134以进行质量分析。当质谱仪接收每个化学组分时,所述化学组分被质谱仪的电离源电离。电离源可以产生包括多个离子(即多个前体离子),所述多个离子包括与每个化学组分不同的电荷或质量。因此,可以针对每个化学组分产生具有不同的质荷比的多个离子,每个此类组分在其自身的特性时间从色谱仪中洗脱。这些各种离子通过质谱仪以及其检测器135进行分析和检测,结果根据其各种质荷比进行适当的鉴定。质谱仪包括隔离某些选定m/z范围内的离子种类的质量过滤设备(未示出)以及用于通过选定离子种类的碎片化生成产物离子的碎片化单元(未示出)。
[0058]
仍然参考图7,系统100的一个或多个可编程处理器137电耦接到质谱仪的检测器,并且在样品的色谱/质谱分析期间接收由检测器产生的数据。一个或多个可编程处理器可以包括单独的独立计算机,或者可以仅包括电路板或由固件或软件操作的任何其它可编程逻辑装置。任选地,可编程处理器也可以电连接到色谱仪和/或质谱仪,以便将电子控制信号传输到这些仪器中的一个或另一个,从而控制其操作。此类控制信号的性质可能响应于从检测器传输到可编程处理器的数据或通过对该数据的分析来确定。可编程处理器也可以电连接到显示器或其它输出138,以将数据或数据分析结果直接输出给用户或电子数据存储器136。
[0059]
图7所示的系统100的一个或多个可编程处理器137可以包括计算机可读指令,所述计算机可读指令通常可操作用于:(a)接收与作为质荷比(m/z)的函数和在m/z值范围内的分布有关的数据,所述分布是通过所关注的类别的化合物的电离而获得的初级离子种类的峰的分布;(b)基于所接收的分布定义m/z箱的集合,由此在m/z值的范围内存在不在任何箱内的间隙;以及(c)使质谱仪134对所述类别的化合物进行一个或多个串联质谱分析循环,其中串联质谱分析的每个循环都包括多个串联质量分析,循环的每个串联质量分析都与相应的箱内的初级离子种类有关。计算机指令可操作用于在每次串联质谱分析期间使质谱仪:隔离相应的箱的初级离子种类;将隔离的初级离子种类碎片化;并且对由隔离的初级离子种类的碎片化生成的碎片离子进行质量分析。
[0060]
本文公开了用于提高质谱数据非依赖性分析效率的方法和设备。包含在本技术中的讨论旨在用作基本描述。本发明不旨在受本文所描述的具体实施例的限制,这些实施例旨在作为本发明个别方面的单一说明。相反,本发明仅由权利要求限制。除了本文所示出和所描述的修改之外,对于所属领域技术人员来说,本发明的各种修改将根据前面的描述和附图而变得显而易见。所有此类变型以及功能上等效的方法和组件均被认为在本发明的范围内。本文提及的任何专利、专利申请、专利申请公开或其它文献特此通过引用以其各自的整体并入本文,如同在本文中完全阐述一样,除了在并入的参考文献与本说明书之间存在任何冲突的情况下要以本说明书的语言为准之外。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。