1.本发明涉及测序文库构建领域,具体而言,涉及一种平末端双链接头元件、试剂盒及平末端建库方法。
背景技术:
2.在高通量测序过程中,dna片段都需要构建成高通量测序文库才能够在高通量测序仪上进行测序。对普通的遗传突变dna片段,其文库转化效率不必要求太高也能够实现准确检测,但是在低频的体细胞突变检测过程中,文库的转化效率是准确检测的关键影响因素。
3.目前在illumina和mgi的测序平台都是通过ta连接的方式进行文库构建,建库接头是y型或泡状接头,虽然y型接头或泡状接头的所构建的文库都能够被测序仪测序,但是ta建库的文库转化效率受两个因素的影响,主要影响因素之一是加a的效率,由于末端加a的效率在4%~75%之间波动(j.m.brownstein,j.d.carptena andj.r.smith modulation of non-templated nucleotide addition by taq dnapolymerase:primer modifications that facilitate genotyping biotechniques,199620:1004-1010),虽然建库试剂盒都在努力提升加a效率,但是也不能改变加a效率的天花板限制。另一个影响ta连接效率的因素是片段5’端的磷酸化效率,尤其是当有5’端碱基有损伤时,会影响磷酸化效率。life technology的测序仪是通过平端连接的方式进行建库,这种建库接头是ab型,ab型的建库虽然平端连接避免了末端加a效率的限制,但是由于接头末端为避免接头自连而末端未进行磷酸化,连接后通过末端缺刻平移的方式实现双链的连接,由于这种方式有两种接头,有效接头占比只有50%ab接头文库,另一半是25%aa接头文库和25%bb接头文库是不能够被测序仪测序。
4.在解决如何实现平端连接绕开加a和5’端磷酸化限制方面,现有技术也有报道利用腺苷化的接头和突变的t4dna连接酶进行高效的平端连接,这种连接效率很高,但同时腺苷化的接头成本也极高。还有报道是利用分步连接和取代的方法实现接头的高效平端连接建库,该方案需要第二步接头连接采用退火竞争,操作步骤和流程过于繁琐。
5.因此,如何提供一种操作简便且成本低的平末端接头连接建库方案,便成为一个亟待解决的技术问题。
技术实现要素:
6.本发明的主要目的在于提供一种平末端双链接头元件、试剂盒及平末端建库方法,以解决现有技术中ta接头连接效率低的问题。
7.为了实现上述目的,根据本发明的一个方面,提供了一种平末端双链接头元件,该双链接头元件包括:a序列、b序列和c序列,其中,a序列从5’端到3’端依次包括a1段和a2段,c序列从5’端到3’端依次包括c1段、c2段和c3段,b序列与c1段互补配对,a序列通过a2段与c2段互补配对,a1段与c3段形成非配对区域,双链接头元件为a序列、b序列和c序列退火形
成的组合y型接头,b序列的3’端为ddn,c1段的5’端具有磷酸化修饰。
8.进一步地,a1段和c3段的长度各自独立地为13-25bp;优选地,a2段和c2段的长度均为8-15 bp,更优选为13-15bp;优选地,b序列和c1段的长度均为8-15bp,更优选为12-14bp;优选地,b序列包括分子标签序列,分子标签序列的长度为4-8bp,更优选为6-8bp。
9.进一步地,分子标签序列中含有rna碱基,优选rna碱基为u碱基。
10.进一步地,a序列和b序列共价连接形成一条链,并与c序列退火形成组合y型接头。
11.进一步地,双链接头元件的序列选自如下任意一组:第1)组:a序列为seq id no:1:tcgtcggcagcgtcagatgtgtataag,b序列为:agacagn1ddn,c序列为seq idno:2:5
’‑
p-n2ctgtctcttatacacatctccgagcccacgagac,其中,n1表示5-7个n碱基形成的序列,n2表示6-8个n碱基形成的序列,n选自a、c、t或g,ddn选自dda、ddc、ddt或ddg,p表示磷酸化修饰;第2)组:a序列为seq id no:1,c序列为seq id no:3,b序列为:agacagn3un4ddn,其中,n3表示2-3个n碱基形成的序列,n4表示2-3个n碱基形成的序列,n选自a、c、t或g,ddn选自dda、ddc、ddt或ddg,p表示磷酸化修饰;第3)组:双链接头元件用于illumina测序平台上,a序列和b序列共价连接于同一链,记为ab链,ab链的序列为:seq id no:3:acactctttccctacacgacgctcttccgatcun5ddn,c序列为seq id no:4:5
’‑
p-n6agatcggaagagcacacgtctgaactccagtcac;其中,n5表示3-5个n碱基形成的序列,n6表示4-6个n碱基形成的序列,n选自a、c、t或g,ddn选自dda、ddc、ddt或ddg,p表示磷酸化修饰;第4)组:双链接头元件用于mgi测序平台上,a序列和b序列共价连接于同一链,记为ab链,ab链的序列为:seq id no:5:ttgtcttcctaaggaacgacatggctacgatccgactu n7ddn,c序列为seq id no:6:5
’‑
p-n8aagtcggaggccaagcggtcttaggaagacaac,其中,n7表示3-5个n碱基形成的序列,n8表示4-6个n碱基形成的序列,n选自a、c、t或g,ddn选自dda、ddc、ddt或ddg,p表示磷酸化修饰。
12.进一步地,a序列和b序列共价连接于同一链上,且c1段的5’端磷酸化修饰被去除,b序列的3’端ddn修饰被去除;优选地,双链接头元件选自如下任意一组:第5)组:双链接头元件用于mgi测序平台上,a序列和b序列共价连接于同一链,记为ab链,ab链的序列为:seq id no:7:tcgtcggcagcgtcagatgtgtataagagacag,c序列为seq idno:8:ctgtctcttatacacatctccgagcccacgagac;第6)组:双链接头元件用于mgi测序平台上,a序列和b序列共价连接于同一链,记为ab链,ab链的序列为:seq idno:9:acactctttccctacacgacgctcttccgatct,c序列为seq id no:10:agatcggaagagcacacgtctgaactccagtcac。
13.根据本技术的第二个方面,提供了一种试剂盒,包括上述任一种平末端双链接头元件。
14.根据本技术的第三个方面,提供了一种平末端建库方法,该建库方法包括:采用上述任一种双链接头元件与具有平末端的dna连接片段进行接头连接,得到带接头连接片段;对接头连接片段进行pcr扩增,得到平末端扩增文库。
15.进一步地,双链接头元件为前述三条序列且不带rna碱基的双链接头元件,或者为前述第1)组双链接头元件,接头连接的步骤包括:采用t4dna连接酶将双链接头元件与5’端非磷酸化的目的片段进行连接,得到带缺刻的连接片段;再采用dna聚合酶和t4dna连接酶对带缺刻的连接片段进行缺刻平移及平移后的缺刻连接,得到带接头连接片段。
16.进一步地,双链接头元件为前述带有rna碱基的双链接头元件,或者为前述的第2)组至第4)组中的任意一组双链接头元件,接头连接的步骤包括:先采用t4dna连接酶将双链
接头元件与5’端非磷酸化的目的片段进行连接,得到带缺刻的连接片段;采用dna聚合酶、user酶和t4dna连接酶对带缺刻的连接片段进行缺刻平移及对平移后的缺刻连接,得到带接头连接片段。
17.进一步地,双链接头元件为前述5’端和3’端均不带修饰的双链接头元件,接头连接的步骤包括:采用t4dna连接酶将双链接头元件与5’磷酸化的目的片段进行连接,得到带缺刻连接片段;采用dna聚合酶、单个核苷酸单体及t4dna连接酶对带缺刻连接片段进行缺刻平移一个碱基,并对平移一个碱基后的缺刻进行连接,得到带接头连接片段。
18.应用本发明的技术方案,针对at连接受加a效率和磷酸化影响,通过创新的复合接头的形式,实现了y型接头的低成本、简单、高效平端连接建库,且能够与现有测序平台的建库、测序流程兼容,更具应用价值。
附图说明
19.构成本技术的一部分的说明书附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
20.图1示出了现有建库方法中影响ta连接效率的因素;
21.图2示出了现有技术中ab型接头平末端接头连接建库的流程示意图;
22.图3示出了现有技术的y型接头(a)和组合y型接头(b)的区别;
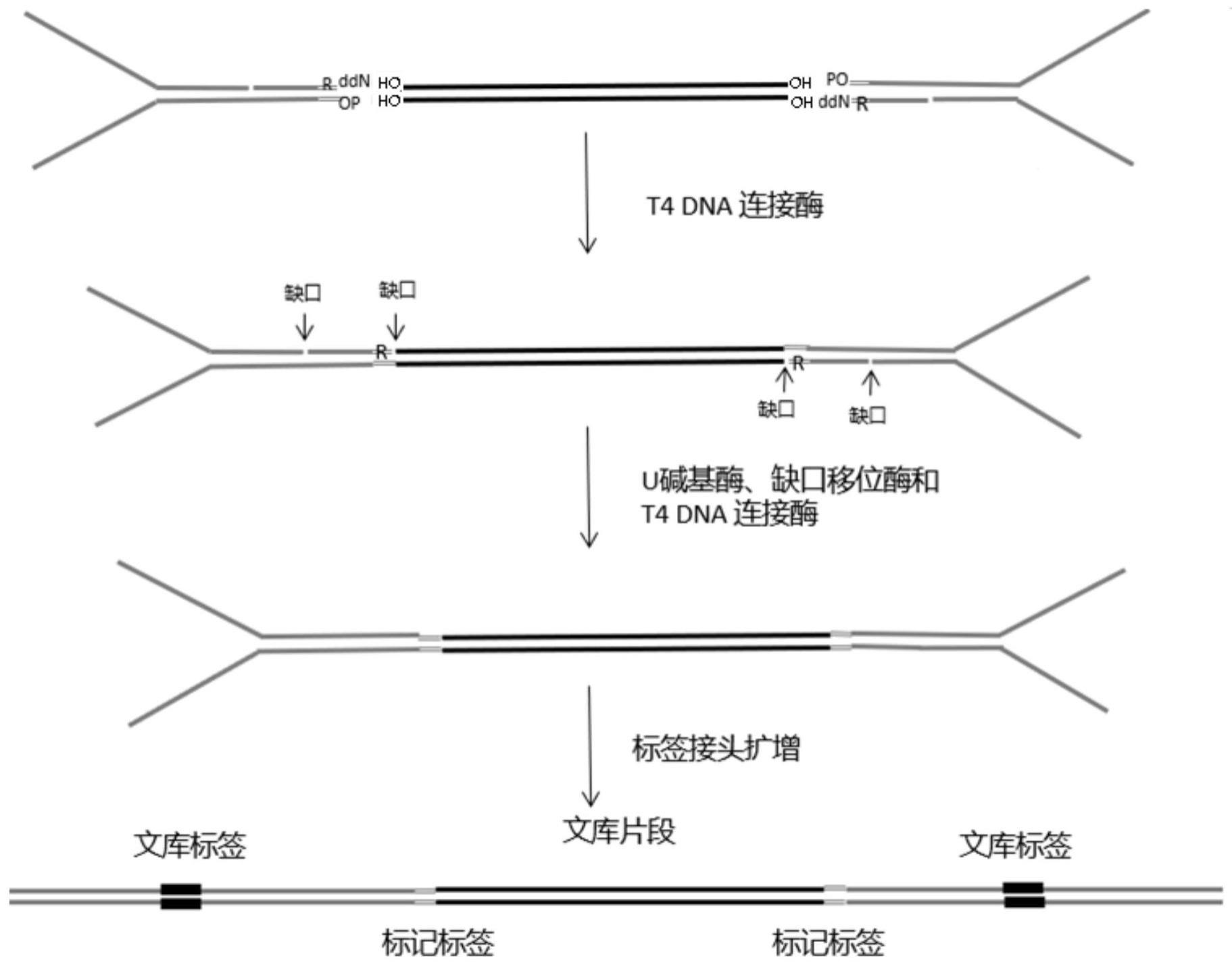
23.图4示出了本技术一种优选实施例提供的组合y型接头实现平末端高效连接的流程示意图;
24.图5示出了本技术一种优选实施例提供的组合y型接头和r碱基实现平末端高效连接的流程示意图;
25.图6示出了本技术另一种优选实施例提供的组合y型接头和r碱基实现平末端高效连接
26.图7示出了本技术另一种优选实施例提供的组合y型非磷酸化接头通过末端转移一个碱基的方式实现平末端高效连接的流程示意图。
具体实施方式
27.需要说明的是,在不冲突的情况下,本技术中的实施例及实施例中的特征可以相互组合。下面将结合实施例来详细说明本发明。
28.术语解释:
29.文库的转化效率:是指投入建库的dna片段两端都能够和接头连接的部分占比总的投入dna片段的比率,文库转化效率高有利于评估低频突变。比如,建库投入的dna片段的总量为50ng,两端都能与双链接头连上的dna片段的量为40ng,则文库转化效率为80%。
30.y型建库接头:接头的两条核酸序列,有一部分是完全互补配对,另一部分不互补配对,经过退火后接头的结构类似y字形状。
31.组合型y字接头:相较于普通y型接头,组合型y字接头的序列有3条序列组成,一条序列和另两条互补形成y型接头。
32.分子标签接头:在接头末端有多组完全互补的不同序列组成,分子标签接头建库可以去掉连接接头后的所有环节引入的干扰突变,能够有效过滤掉假的突变,分析出来真
实突变。
33.如背景技术所提到的,目前高通量测序已经成为重要的精准医疗获取准确信息的手段,在检测低频突变,而样本数量有限或者质量不高的情况下,dna片段构建文库时的转化效率便成为影响低频检出的最重要的因素。mgi和illumina测序平台选择的都是ta连接的接头连接方式,mgi的接头是泡状接头,illumina的接头是y型接头,通过ta连接能够很好的解决dna片段的建库问题。如图1所示的建库流程,通过ta连接可以实现文库的顺利构建,这种方法的弊端是文库转化效率不高,文库的转化效率受到两个环节限制,一个是加a效率,3’末端加a的效率并不是100%,存在一部分序列加不上a,还有一部分加的是g末端(j.m.brownstein,j.d.carptena andj.r.smith modulation ofnon-templated nucleotide addition by taq dnapolymerase:primer modifications that facilitate genotyping biotechniques,199620:1004-1010),这样的序列是不能被t突出的接头成功连接的。另一个影响因素是受5’端的磷酸化影响,5’末端碱基损坏是导致磷酸化效率降低的关键因素。
34.在建库效率方面,dna的来能源主要是血浆cfdna、血液或新鲜组合gdna或者ffpe dna。建库效率的优劣顺序排序如下:cfdna》超声打断的dna》ffpe dna,cfdna的产生是由体内的酶切降解产生,末端dna的完整度最高,超声是强力打断会对dna片段中间和末端有损伤,ffpe的损伤更严重。
35.因而,发明人尝试从绕开ta连接的角度寻找改进方案,并发现现有技术中life的测序建库是通过平端的a和b接头建库形式实现建库,这种建库的好处是避免了加a效率的影响,这种建库也是受5’磷酸化效率的影响。相较y型或泡状的ta连接,这种a和b型的平端连接只有50%的文库是有效文库,如图2所示,只有50%的文库是两端分别连接a型和b型接头的文库才能够被测序,有50%的dna文库两端只连接同一种接头(25%aa和25%bb型文库),是不能够被测序。
36.因而,发明人进一步提出如下问题:是否有既能通过采用y型接头建库,同时又能避免ta连接,进而避免受加a和磷酸化效率影响的改进方案呢?通过进一步研究分析发现,有报道利用腺苷化的接头和突变的t4dna连接酶进行高效的平端连接,这种方法连接效率是很高,但是腺苷化的接头成本也极高,同时连接的第二条链是通过后期加入退火竞争,这种方式第二条链的连接受缓冲液的环境影响较大。也有报道利用分步连接和取代的方法实现接头的高效平端连接建库,该方案中第二步接头连接需要退火竞争,操作步骤和流程过于繁琐,虽然效率高,但是经过多个步骤操作也会影响应用效果。
37.在上述分析结果基础上,为了实现低成本、操作简便且能与现有测序平台匹配,发明人进一步提出了一系列的改进方案,具体如下:
38.方案一:该方案的思路是:通过组合型接头的方式实现y型接头的平端连接建库,与传统的y型接头(如图3中a所示)由两条序列组成不同,组合型的y接头由3条序列组成(如图3中b所示)。
39.a序列:5’端是不互补部分,不互补序列长度是15-25bp,3’端有8-15bp(比如可以是13bp)的序列与c序列中间部分互补,a序列的两端是羟基末端。
40.b序列:长度在8-15bp(比如可以是12-14bp)长度。b序列与c序列的5’端完全互补,并且b序列的3’端是ddn(双脱氧核苷酸)碱基,3’端的序列可以是固定序列,也可以是不固
定的分子标签组合形式存在,b序列和c序列退火在一起后是平齐末端。
41.c序列:5’端是和b序列完全互补,5’端是磷酸化修饰,为平端连接成功创造条件,c序列的中间段和a序列的3’端的序列互补,c序列的3’端是不互补的部分(参见图3中a所示的普通y型接头和b所示的组合型y型的结构组成差异)。
42.也即,该双链接头元件包括:a序列、b序列和c序列,其中,a序列从5’端到3’端依次包括a1段和a2段,c序列从5’端到3’端依次包括c1段、c2段和c3段,b序列与c1段互补配对,a序列通过a2段与c2段互补配对,a1段与c3段形成非配对区域,双链接头元件为a序列、b序列和c序列退火形成的组合y型接头,b序列的3’端为ddn,c1段的5’端具有磷酸化修饰。
43.这种组合型y型接头平齐末端是5’是磷酸化,3’端是ddn碱基(需要说明的是,此处不能改为其他封闭碱基,比如spacer c3等,因为若替换成替他封闭修饰,则会导致该双链接头与目的片段连接时,末端会翘起来或被支起来而难以实现连接。ddn能同时满足避免接头自连和实现双链接头连接的目的),能够在避免接头自连接的同时,通过缺刻平移去除3’末端ddn碱基的封闭作用(b序列与a序列之间的缺刻是为后续采用dna聚合酶进行缺刻平移提供基础的,即从a2段的末端向3’段延伸,从而替代b序列,并在与目的片段待连接的位置形成缺刻,最后通过t4dna连接酶将缺刻连接),从而实现双链连接。这种组合型的y型接头解决的核心问题是在实现高效的平端建库的同时,避免了ta连接的加a效率和磷酸化效率的影响,同时组合型接头也解决了第二端片段的连接需要竞争后退火的方式连接,已经提前一次退火到一起,避免操作程序的繁琐以及需要竞争的方式实现第二链的连接对连接效率和建库效率的影响。
44.为了进一步提高该组合y型接头的稳定型,同时满足针对低频突变所需的高效建库效率,以及消除低频突变的假阳性干扰,组合型y型接头3’末端加入分子标签部分。具体的一种实现方式,如图4所示,a序列和c序列互补部分是13bp互补,b序列和c序列互补是12-14bp。为进一步与现有测序平台的测序通用接头兼容,可以采用现有的tn5的转座酶接头,但并不限于tn5接头,其他任何符合这个逻辑和长度条件的接头都能实现本发明功效。
45.从兼容现有测序流程的角度考虑,下面采用tn5转座酶接头进行示例性说明,用其中b序列和c序列固定互补区域是6bp,可变的分子标签部分是6-8个碱基(下面用nx,x为1或2,表示5-7或6-8个碱基),具体的组合y型接头的三段序列的具体序列如下:
46.a序列:seq id no:1:tcgtcggcagcgtcagatgtgtataag;
47.b1序列:agacagn1ddn,n1表示5-7个n碱基形成的序列;
48.c序列:seq id no:2:5
’‑
p-n2ctgtctcttatacacatctccgagcccacgagac,n2表示6-8个n碱基形成的序列。
49.需要说明的是,如无特殊说明,本技术中的n均表示选自a、c、t或g中的一种,ddn均表示选自dda、ddc、ddt或ddg中的一种,p均表示磷酸化修饰。
50.通过此种组合型接头解决了片段加a和磷酸化两种限制因素对连接效率的影响,组合型y型接头平齐末端是5’端是磷酸化,3’端是ddn碱基,组合型接头不能自身连接,只能和目标片段连接,连接后的片段在聚合酶的作用下进行缺刻平移,然后利用t4dna酶把ddn的缺刻补齐,如果有5’碱基受伤的情况,也可以切掉一个碱基实现连接,因而能够实现组合y型接头的平端高效建库。
51.方案二:在上述应用的过程中,为进一步避免聚合酶进行缺刻移位时,在未有效去
除3’末端的ddn碱基前,被t4dna连接酶连接而难以有效解除3’末端的ddn碱基封闭作用,本发明还提供了另一种优选的解决方案。即在分子标签里面引入一个rna碱基(比如u碱基),这样就不会由于在缺刻移位的过程中就被连接导致的接头只有一段被连接的情况,如图5所示,b序列的分子标签部分的6-8个碱基中间有一个t碱基被u碱基替代,这样用去除u碱基后末端序列比较短,自然脱离双链结合区域,所以这样就不会影响后续缺刻移位和连接的进行。
52.b2序列具体的序列如下:agacagn2un4ddn,n3表示2-3个n碱基形成的序列,n4表示2-3个n碱基形成的序列,n选自a、c、t或g,ddn选自dda、ddc、ddt或ddg。
53.方案三:在实现y型接头平端连接的过程中,主要解决的是高效连接的同时,避免接头自连,这样就需要5’磷酸和3’去羟基,去掉羟基目的是阻止接头自连,这个3’去羟基后续的连接中去掉,所以组合型接头就是为实现这一个目标进行设计。这种方式除了可以上述两种方式实现外,还可以通过把a序列和b序列融合在一起的同时,与c序列互补的部分足够稳定就可以实现。
54.从现有建库和/或测序流程的兼容性考虑,目前的truseq接头兼容性设计能够实现这种高效连接,即固定的互补序列是8-15bp,可变的分子标签是4-8bp,其中在中间位置有一个u碱基,分子标签末端的3’端末尾是ddn碱基,ddn碱基是起到封闭作用防止自连,连接完第一条链后经过u碱基去除酶去掉u碱基解除ddn碱基限制,在聚合酶和连接酶的共同作用下实现第二条链的连接,这种方式就不需要太长的固定序列,这个固定的序列在8-15bp既可以实现,这样illumian测序仪的truseq和mgi的泡状接头都能够实现这种创新型的连接设计。如图6所示,在illumian测序仪平台的具体序列如下:
55.seq id no:3:
56.acactctttccctacacgacgctcttccgatcun5ddn;
57.seq id no:4:
[0058]5’‑
p-n6agatcggaagagcacacgtctgaactccagtcac;
[0059]
n5表示3-5个n碱基形成的序列,n6表示4-6个n碱基形成的序列,n选自a、c、t或g,ddn选自dda、ddc、ddt或ddg,p表示磷酸化修饰。
[0060]
在mgi测序仪平台的具体序列如下:
[0061]
seq id no:5:
[0062]
ttgtcttcctaaggaacgacatggctacgatccgactun7ddn;
[0063]
seq id no:6:
[0064]5’‑
p-n8aagtcggaggccaagcggtcttaggaagacaac;
[0065]
n7表示3-5个n碱基形成的序列,n8表示4-6个n碱基形成的序列,n选自a、c、t或g,ddn选自dda、ddc、ddt或ddg,p表示磷酸化修饰。
[0066]
这种方案的好处是在解决了y型接头的平端连接同时,兼容现有illumina和mgi测序平台的通用接头,还引入了分子标签,对分析低频突变有很大的益处。
[0067]
方案四:还有另一种方式实现y型接头的平端连接,接头是平端,也不磷酸化,依靠连接片段的磷酸化实现双链的一条链连接,连接后的另一条链在聚合酶和接头末端5’端的第一个碱基的单核苷酸一起反应,这样缺刻平移只产生一个碱基的平移之后连接,这样接头的第二条链不会被移除,进而保留了y型接头的完成结构。
[0068]
这种方法的优点是解决了加a效率对连接的影响,如图7所示,缺刻产生的位置在连接片段的3’端,通过控制缺刻一个碱基或少量碱基(比如小于等于5个碱基)平移,产生新的5’磷酸化和3’羟基,经t4dna连接酶实现连接。这种方式加入的是单种核苷酸单体,不能加入分子标签这种多个碱基组成的形式,同时也受连接片段的5’端磷酸化的影响。以tn5接头的方式创建这种连接方式,具体序列如下:
[0069]
seq id no:7:tcgtcggcagcgtcagatgtgtataagagacag;
[0070]
seq id no:8:ctgtctcttatacacatctccgagcccacgagac。
[0071]
经过t4dna连接酶链后,在反应体系中加入了c碱基单体和常温聚合酶,在初次连接时接头的3’末端和目标片段的5’端连接,由于接头5’端没有磷酸化,所以接头本身是平端,不能自连,接头的5’端和目标片段的3’端不能被连接,在常温聚合酶和dctp的存在下,接头seq id no:9的5’端第一个c碱基被缺刻平移一个碱基,出现5’磷酸和3’羟基,之后被连接,和加入四种脱氧核酸单体不同,保留了y型结构,实现了高效的y型平连建库。
[0072]
以illumina测序平台truseq接头蓝本方式创建上述方式的具体序列如下:
[0073]
seq id no:9:acactctttccctacacgacgctcttccgatct;
[0074]
seq id no:10:agatcggaagagcacacgtctgaactccagtcac。
[0075]
经过t4dna连接酶链后,在反应体系中加入了a碱基单体和常温聚合酶,seq id no:12的5’端的第一个碱基a经过缺刻平移后被连接上,这样会实现顺利的连接,本部分只是用tn5和truseq的接头进行举例,y型互补配对部分要在10-20bp之间,在有一个碱基缺刻平移的情况下依然稳定的保证二级结构。
[0076]
综上所述,本发明解决的是提升建库试剂盒的片段连接效率问题,主要是解决y型或泡状接头的ta连接受加a和5’磷酸化效率的限制影响,通过创新的复合接头的形式,实现了高效的y型结构接头的平端连接,其中的实现方式有三段组合形式是起始时就退火在一起,避免后续连接的繁琐和竞争结合效率的影响;同时也引入了分子标签,更有利于分子低频突变。在实现过程还包括引入u碱基的方式去除3’末端的封闭碱基,这样既可以解决缺刻移动过程中提前连接的问题,也可以解决三段复合接头融合在一起,缩短互补序列长度,兼容truseq接头问题。本发明也通用依赖接头3’端先连接,通过控制缺刻平移一个碱基的方式实现y的连接的方式。本发明解决的是通过组合型y型接头或通过控制反应试剂的方式实现高效的建库连接方案。
[0077]
下面将结合具体的实施例来进一步说明本技术的有益效果。本发明在分子标签部分是用n代替,在退火过程中是具体序列单独退火,这里仅用一个代表。
[0078]
实施例1.通过组合型引物实现高效y型接头的高效连接。
[0079]
步骤一:复合接头退火
[0080]
反应体系配置:将三种核酸序列seq id no:1、seq id no:2和b1序列稀释到500μm/l,用5倍退火缓冲液配置100μm/l反应液,具体的配置比例如下:
[0081]
表1:
[0082]
名称体积5倍退火缓冲液10μlseq id no:110μlseq id no:210μl
b1序列10μlh2o10μl总体积50μl
[0083]
在pcr仪上设置退火程序设置如下。
[0084]
表2:
[0085]
温度时间94℃2min94℃1min65℃后降1℃停留1min25℃10min4℃hold
[0086]
稀释到15μm备用。
[0087]
步骤二:使用covaris
tm
m220 focused-ultrasonicator超声打断promega公司的人标准品混合基因组(g3041),打断目标片段主峰控制在200-300bp。
[0088]
步骤三:末端修复和补平
[0089]
1)按照下表,在置于冰上的0.2ml pcr管中进行反应体系配制:
[0090]
表3:
[0091][0092][0093]
2)混合均匀,瞬时离心使全部反应液置于pcr管底部。
[0094]
3)在pcr仪上启动如下反应程序,等温度稳定至20℃时将反应管放进pcr仪:
[0095]
表4:
[0096][0097]
步骤四:接头连接
[0098]
1.用步骤一的组合型接头和步骤三的反应产品连接。
[0099]
2.从pcr仪上取出步骤三pcr反应管,置于冰上,按照以下体系进行接头连接反应体系配制。
[0100]
表5:
[0101][0102]
3.混合均匀,瞬时离心使全部反应液置于pcr管底部。
[0103]
4.在pcr仪上启动如下反应程序,等温度稳定至20℃时将反应管放进pcr仪:
[0104]
表6:
[0105][0106]
5.在反应体系中加入1μl dna聚合酶i(neb,m0209v)。
[0107]
6.按照下列程序启动pcr设计程序,做缺刻平连和第二条链的连接反应。
[0108]
表7:
[0109][0110]
步骤五:磁珠纯化
[0111]
1.提前将nanoprep
tm
sp beads取出涡旋混匀,室温平衡30min后使用。
[0112]
2.向步骤三连接体系pcr管加入40μl nanoprep
tm
sp beads,混合均匀,25℃孵育5-10min。
[0113]
3.将pcr管瞬时离心后放置于磁力架上5min至液体完全澄清,使用移液器吸取移弃上清。
[0114]
4.沿pcr管侧壁缓慢加入150μl 80%乙醇,注意勿扰动磁珠,静置30s,使用移液器吸取移弃上清。
[0115]
5.重复步骤4一次。
[0116]
6.将pcr管瞬时离心后放置于磁力架上,使用10μl吸头移去少量残留乙醇,注意勿吸到磁珠。
[0117]
7.打开pcr管管盖,并于室温静置约5min,至乙醇挥发完全。
[0118]
注意:切勿过分干燥,否则会降低得率。
[0119]
8.移出pcr管,向pcr管中加入21μl nuclease free water,将磁珠悬浮均匀,25℃孵育2min。
[0120]
9.将pcr管瞬时离心后放置于磁力架上2min至液体完全澄清,使用移液器吸取20μl上清,并转移至1个新的0.2ml pcr管中,置于冰上备用。
[0121]
步骤六:pcr扩增
[0122]
1.取出2x hifi pcr master mix和amplification primer mix置于冰上自然解冻,混合均匀,瞬时离心备用。
[0123]
2.按照以下体系在置于冰上的pcr管中进行反应体系配制:
[0124]
表8:
[0125][0126][0127]
将pcr管放入pcr仪中启动以下程序:
[0128]
表9:
[0129][0130]
步骤七:文库纯化、定量和质检
[0131]
1、向pcr管加入60μl的nanoprep
tm
sp beads混合均匀,25℃孵育5-10min。
[0132]
2、将pcr管瞬时离心后放置于磁力架上5min,至液体完全澄清,使用移液器吸取移弃上清。
[0133]
3、沿pcr管侧壁缓慢加入150μl 80%乙醇,注意勿扰动磁珠,静置30s,使用移液器吸取移弃上清。
[0134]
4、重复步骤3一次。
[0135]
5、pcr管瞬时离心,放置于磁力架上,使用10μl吸头移去少量残留乙醇,注意勿吸到磁珠。
[0136]
6、打开pcr管管盖,并于室温静置约5min,至乙醇挥发完全。
[0137]
注意:切勿过分干燥,否则会降低得率。
[0138]
7、向pcr管加入20μl te solution,使用移液器将磁珠悬浮均匀,25℃孵育2min。
[0139]
8、将pcr管瞬时离心后放置于磁力架上2min,至液体完全澄清,使用移液器小心将上清移取至一个新的0.2ml pcr管中进行保存,注意勿吸到磁珠。
[0140]
9、使用qubit对文库进行定量。
[0141]
10、使用bioanalyzer(agilent)、qsep100(bioptic)等相关片段分析仪器进行文库片段分布检测。
[0142]
实施例1是通过组合型接头的方式实现平端连接,通过平端接头的方式,平端接头
末端的5’端是磷酸化,3’端是脱羟基的ddn碱基,这样接头不会自连,在第一轮第一条链连接后,加入聚合酶,会通过缺刻平移把seq id no:2移除掉,解除封闭连接第二条链,通过组合型接头实现高效的平端建库。
[0143]
实施例2.通过组合型引物和r碱基实现高效y型接头的高效连接
[0144]
步骤一:复合接头退火
[0145]
1.反应体系配置:将三种核酸序列seq id no:1、seq id no:2和b2序列稀释到500μm,用5倍退火缓冲液配置100μm反应液,具体的配置比例如下:
[0146]
表10:
[0147]
名称体积5倍退火缓冲液10μlseq id no:110μlseq id no:210μlb2序列10μlh2o10μl总体积50μl
[0148]
2.在pcr仪上设置退火程序设置如下
[0149]
表11:
[0150]
温度时间94℃2min94℃1min65℃后降1℃停留1min25℃10min4℃hold
[0151]
3.稀释到15μm备用。
[0152]
实施例2的大部份步骤和实施例1是一样的,仅在步骤四的第5小步:在反应体系中加入1μl dna聚合酶i(neb,m0209v)同时也加入了user enzyme(neb,m5505s)。实施例2的seq id no:4对比实施例1的seq id no:4的区别是在序列分子标签部分的一个t碱基被u碱基替代,在连接第二条序列时,聚合酶在进行缺刻平移和连接发生时避免连接发生在ddn碱基去除之前,u碱基经过user enzyme去除,解除了ddn的限制,由于u碱基和ddn碱基之间的举例在1-4个碱基之间,去除的u碱基之后,这小段序列失去稳定性会离开结合的区域,这样缺刻平移后接头3’和目标片段的5’顺利连接。通过实施例2的组合型接头方式,在seq id no:4的ddn碱基前端的分子标签部分引物一个u碱基,目的是使平端高效连接。
[0153]
实施例3:通过平末端接头和r碱基实现高效y型接头的高效连接
[0154]
1)illumina的truseq的接头反应体系配置:
[0155]
seq id no:5和seq id no:6两种核酸序列稀释到500μm,用5倍退火缓冲液配置100μm反应液,具体的配置比例如下:
[0156]
表12:
[0157]
名称体积
5倍退火缓冲液10μlseq id no:310μlseq id no:410μlh2o20μl总体积50μl
[0158]
2)mgi的接头反应体系配置:
[0159]
seq id no:7和seq id no:8两种核酸序列稀释到500μm/l,用5倍退火缓冲液配置100μm/l反应液,具体的配置比例如下:
[0160]
表13:
[0161]
名称体积5倍退火缓冲液10μlseq id no:510μlseq id no:610μlh2o20μl总体积50μl
[0162]
3)在pcr仪上设置退火程序设置如下。
[0163]
表14:
[0164][0165][0166]
4)稀释到15μm备用。
[0167]
实施例3的大部份步骤和实施例2是一样的,在步骤四的第5小步:在反应体系中加入1μl dna聚合酶i(neb,m0209v)同时也加入了user enzyme(neb,m5505s)。本实例由于是用两端序列进行y型接头平端连接,这种方式配对长度在8-15bp就可以满足稳定性,因此可以实现在illumina的truseq和mgi的建库接头兼容的操作,在通用接头和分子标签接头之间用u间隔,3’末端由ddn阻止接头自连,连完第一步反应后用u碱基去除酶和缺刻移位的聚合酶补平缺口后被连接酶连接剩余一条链,通过这种方式实现高效的平端连接建库。
[0168]
实施例4:通过末端转移一个碱基的方式提升y型接头的高效连接
[0169]
本实施例在补平反应中加入了t4pnk(neb,m0201s),目的是使目的片段磷酸化,方便后续的接头第一条链连接。
[0170]
1)illumina的tn5的接头反应体系配置:seq id no:8和seq id no:9两种核酸序列稀释到500μm/l,用5倍退火缓冲液配置100μm/l反应液,具体的配置比例如下:
[0171]
表15:
[0172]
名称体积5倍退火缓冲液10μlseq id no:710μlseq id no:810μlh2o20μl总体积50μl
[0173]
2)illumina的truseq接头反应体系配置:seq id no:10和seq id no:11两种核酸序列稀释到500μm/l,用5倍退火缓冲液配置100μm/l反应液,具体的配置比例如下:
[0174]
表16:
[0175][0176][0177]
3)在pcr仪上设置退火程序设置如下。
[0178]
表17:
[0179]
温度时间94℃2min94℃1min65℃后降1℃停留1min25℃10min4℃hold
[0180]
4)稀释到15μm备用。
[0181]
实施例4是通过y型接头的平端末端5’不带磷酸化的方式,通过目标片段的5’磷酸化和接头的平端3’连接,后续加入聚合酶和单个核苷酸单体,在tn5的接头反应中单体加入的是dctp,在truseq接头中加入的单体是datp单体。在第一步连接完后,要进行回收操作,去除体系内dntp,为后续缺刻平移时只加一种核苷酸单体移动一个碱基后就连接,避免缺刻移动过多破环y型接头的一端结构,这样聚合酶只平移一个碱基就在t4dna连接酶的作用下连接上剩余的一条链,这样就解决了y型接头的平端高效连接建库。
[0182]
从上述实施例的描述可以看出,本发明针对文库的建库效率问题,在传统的ta连接过程中由于受到目的片段的3’端加a效率和5’端磷酸化效率的影响,文库转化效率始终受到限制,影响了低频突变的有效应用。本发明通过采用组合型接头连接和控制缺刻平移的方式实现了y型接头的平端连接建库,改进后的建库方案,有助于提升低频突变的检出效率。
[0183]
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技
术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
