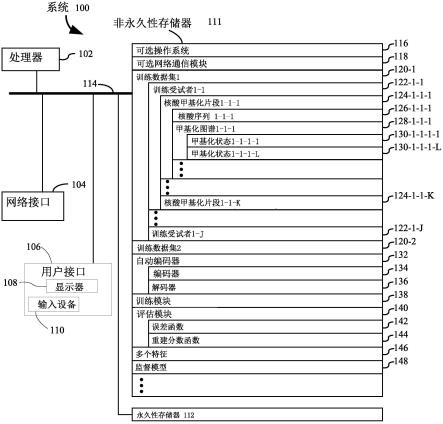
技术特征:
1.一种区分一第一癌症状态和一第二癌症状态的方法,其中所述第一癌症状态不同于所述第二癌症状态,其特征在于:所述方法包括下列步骤:在包括至少一个处理器和一存储器的一计算器系统中,所述存储器存储用于由所述至少一个处理器执行的至少一个程序,所述至少一个程序包括用于以下操作的指令:a)获得电子形式的一第一训练数据集,其中:对于多个第一训练受试者中的每个相应训练受试者,所述第一训练数据集包括在通过对从相应受试者获得的一生物样本中进行一核酸甲基化测序所确定的一对应的多个核酸甲基化片段中,每个相应核酸甲基化片段的一对应的甲基化图谱和一对应的核酸序列;其中所述对应的甲基化图谱包括所述相应核酸甲基化片段中对应的多个cpg位点中每个相应cpg位点的一甲基化状态;其中所述多个第一训练受试者中的每个训练受试者具有所述第一癌症状态;b)训练一未经训练的自动编码器,其中所述未经训练的自动编码器包括1000个或更多权重,并且其中所述未经训练的自动编码包括一编码器和一解码器,对于所述第一训练数据集中的每个对应的多个核酸甲基化片段中的每个相应核酸甲基化片段的每个对应的核酸序列,使用所述第一训练数据集中的每个对应的多个核酸甲基化片段中的每个相应核酸甲基化片段中的所述对应的甲基化图谱和对应的核酸序列作为输入,通过所述对应的核酸甲基化片段中所述对应的甲基化图谱和所述对应的核酸序列来评估所述自动编码器的重建的一误差的一第一误差函数,从而形成一经训练的自动编码器;c)获得电子形式的一第二训练数据集,其中:对于多个第二训练受试者中的每个相应训练受试者,所述第二训练数据集包括通过从各自受试者获得的一生物样本中进行一核酸甲基化测序所确定的一对应的多个核酸甲基化片段中每个相应核酸甲基化片段的一对应的甲基化图谱和一对应的核酸序列,所述对应的甲基化图谱包括相应核酸甲基化片段中对应的多个cpg位点中每个相应cpg位点的一甲基化状态;其中所述多个第二训练受试者中的每个训练受试者具有所述第二癌症状态;d)使用所述第二训练数据集和所述经训练的自动编码器通过计算从所述第二训练数据集表示的多个序列或多个甲基化图谱中识别多个特征,对于所述第二训练数据集中的每个对应的多个核酸甲基化片段中的每个相应核酸甲基化片段,在将相应核酸甲基化片段的对应的甲基化图谱和对应的核酸序列输入到所述经训练的自动编码器中时,由所述自动编码器至少部分地对所述相应核酸甲基化片段的对应的甲基化图谱进行一重建来确定一对应分数;以及e)使用所述多个特征来训练区分所述第一癌症状态和所述第二癌症状态的一监督模型。2.如权利要求1所述的方法,其特征在于:接收满足一误差阈值的一对应分数的由所述第二训练数据集表示的对应于所述第二训练数据集中的一个或多个核酸甲基化片段的每个核酸序列被识别为所述多个特征中的一个特征。3.如权利要求1所述的方法,其特征在于:一相应核酸甲基化片段的所述对应分数:由所述自动编码器对所述相应核酸甲基化片段的对应的甲基化图谱的所述重建的一正确性确定;并且
与通过所述自动编码器对所述相应核酸甲基化片段的对应的核酸序列的所述重建的一正确性无关。4.如权利要求1所述的方法,其特征在于:一相应核酸甲基化片段的所述对应分数:由所述自动编码器对所述相应核酸甲基化片段的对应的甲基化图谱的所述重建的一正确性确定;并且进一步由所述自动编码器对所述相应核酸甲基化片段的对应的核酸序列的所述重建的一正确性确定。5.如权利要求3或4所述的方法,其特征在于:所述相应核酸甲基化片段的对应的甲基化图谱的所述重建的所述正确性至少部分地由所述相应核酸甲基化片段的的对应的甲基化图谱的所述重建与所述相应核酸甲基化片段的实际甲基化图谱之间的一汉明距离确定。6.如权利要求1所述的方法,其特征在于:通过对从所述第一训练数据集或所述第二训练数据集中的各个受试者获得的生物样本中的核酸进行一甲基化测序确定的对应的多个核酸甲基化片段包括一千或更多、一万或更多、十万或更多、一百万或更多、一千万或更多、一亿或更多、五亿或更多、十亿或更多、二十亿或更多、三十亿或更多,四十亿或更多、五十亿或更多、六十亿或更多、七十亿或更多、八十亿或更多、九十亿或更多、或一百亿或更多的核酸甲基化片段。7.如权利要求1所述的方法,其特征在于:所述多个第一训练受试者包括10个或更多、20个或更多、30个或更多、50个或更多、100个或更多、1000个或更多、2000个或更多、3000个或更多、或5000个或更多个训练受试者。8.如权利要求1所述的方法,其特征在于:所述多个第二训练受试者包括30个或更少、50个或更少、100个或更少、或1000个或更少的训练受试者。9.如权利要求1所述的方法,其特征在于:所述至少一个程序还包括用于在步骤a)的所述获得之后和步骤的b)所述训练之前:通过从对应的多个核酸甲基化片段中去除不满足一个或多个选择标准的每个相应的核酸甲基化片段来对每个对应的多个核酸甲基化片段进行过滤。10.如权利要求9所述的方法,其特征在于:当相应核酸甲基化片段的甲基化图谱具有不满足一p值阈值的一输出p值时,相应核酸甲基化片段不满足一个或多个选择标准中的一选择标准;以及至少部分地基于在所述相应核酸甲基化片段的多个cpg位点上的所述相应核酸甲基化片段的甲基化图谱与所述第一训练数据集中具有相应多个cpg位点的所述核酸甲基化片段的甲基化图谱的对应分布的一比较来确定相应核酸甲基化片段的所述输出p值。11.如权利要求9所述的方法,其特征在于:当由一训练的马尔可夫模型提供的一输出p值响应于所述相应核酸甲基化片段的甲基化图谱的输入而未通过一选择标准时,来自所述第一训练数据集的所述相应核酸甲基化片段未能满足一个或多个选择标准中的一选择标准;以及所述训练的马尔可夫模型至少部分地基于在所述第一训练数据集中具有对应的多个cpg位点的所述核酸甲基化片段之间的相应核酸甲基化片段的多个cpg位点中的每个cpg位置的一甲基化状态的评估来训练。12.如权利要求9所述的方法,其特征在于:
当由一训练的马尔可夫模型提供的一输出p值响应于所述相应核酸甲基化片段的甲基化图谱的输入而未达到一选择标准时,来自所述第二训练数据集的所述相应核酸甲基化片段未能满足一个或多个选择标准中的一选择标准;以及所述训练的马尔可夫模型至少部分地基于在所述第二训练数据集中具有对应的多个cpg位点的所述核酸甲基化片段之间的相应核酸甲基化片段的多个cpg位点中的每个cpg位置的一甲基化状态的评估来训练。13.如权利要求10、11或12所述的方法,其特征在于:所述输出p值在0.00001和0.20之间。14.如权利要求10、11或12所述的方法,其特征在于:所述输出p值为0.05。15.如权利要求9所述的方法,其特征在于:当所述相应核酸甲基化片段具有小于一阈值数量的cpg位点时,相应核酸甲基化片段不满足一个或多个选择标准中的一选择标准。16.如权利要求15所述的方法,其特征在于:cpg位点的阈值数量为4、5、6、7、8、9或10。17.如权利要求9所述的方法,其特征在于:当所述相应核酸甲基化片段具有小于一阈值数量的残基时,所述相应核酸甲基化片段不满足一个或多个选择标准中的一选择标准。18.如权利要求17所述的方法,其特征在于:残基的阈值数量为32或64。19.如权利要求17所述的方法,其特征在于:残基的阈值数量是20到90之间的一固定值。20.如权利要求9所述的方法,其特征在于:所述过滤移除所述多个核酸甲基化片段中的一核酸甲基化碎片,所述核酸甲基化碎片与所述多个核酸甲基化片段中的另一核酸甲基化片段具有相同的对应的甲基化图谱和相同的对应的核酸序列。21.如权利要求20所述的方法,其特征在于:所述过滤保留所述多个核酸甲基化片段中的一核酸甲基化碎片,所述核酸甲基化碎片与所述多个核酸甲基化片段中的另一核酸甲基化片段具有相同的对应的甲基化图谱和不同的对应的核酸序列。22.如权利要求20所述的方法,其特征在于:所述过滤保留所述多个核酸甲基化片段中的一核酸甲基化碎片,所述核酸甲基化碎片与所述多个核酸甲基化片段中的另一核酸甲基化片段具有不同的对应的甲基化图谱和相同的对应的核酸序列。23.如权利要求9所述的方法,其特征在于:当所述相应核酸甲基化片段的cpg位点的数量小于一阈值时,所述核酸甲基化片段不能满足一个或多个选择标准中的一选择标准;在步骤a)中训练所述自动编码器之前获得将对应的多个核酸甲基化片段中小于一预定长度的每个核酸甲基化片段填充为一预定长度;以及在步骤a)中通过以一预定步幅跨相应核酸甲基化片段开窗,截断对应的多个核酸甲基化片段中大于预定长度的每个相应核酸甲基化片段,从而将相应核酸甲基化片段截断为两个或多个序列段,其中两个或多个核酸甲基化片段各自具有所述预定长度,并且各自具有至少为所述阈值的数量的cpg位点,并共同替换对应的多个核酸甲基化片段中的相应核酸甲基化片段作为步骤b)中所述训练的所述输入。24.如权利要求23所述的方法,其特征在于:所述片段长度在90个核苷酸到300个核苷酸之间。25.如权利要求23所述的方法,其特征在于:所述片段长度为100个核苷酸、128个核苷
酸或256个核苷酸。26.如权利要求1至25中任一项所述的方法,其特征在于:在步骤a)中,截断多个核酸甲基化片段中的第一核酸甲基化片段,所述第一核酸甲基化片段长于预定长度,位于所述第一核酸甲基化片段内的变异的位点、冲突甲基化调用的位点或不明确调用的位点被截断,从而缩短所述第一核酸甲基化片段以终止于所述位点。27.如权利要求1所述的方法,其特征在于:所述自动编码器是一变分自动编码器、一叠层去噪深度自动编码器、一深度循环自动编码器、一卷积式自动编码器或一变压器网络。28.如权利要求1所述的方法,其特征在于:所述自动编码器是一深度循环自动编码器,并且在步骤b)的所述训练中,对于第一训练数据集中对应的多个序列中的相应序列:向所述深度循环自动编码器的一第一轨道提供被分解成多个k聚体的各个核酸甲基化片段的对应的核酸序列;以及向所述深度循环自动编码器的一第二轨道提供相应核酸甲基化片段的对应的甲基化图谱。29.如权利要求1所述的方法,其特征在于:所述自动编码器是一深度循环自动编码器,并且在步骤b)的所述训练中,对于第一训练数据集中对应的多个核酸甲基化片段中的相应核酸甲基化片段:以残基为基础向所述深度循环自动编码器的第一轨道提供相应核酸甲基化片段的对应的核酸序列;以及向所述深度循环自动编码器的一第二轨道提供提供相应核酸甲基化片段的对应的甲基化图谱。30.如权利要求1所述的方法,其特征在于:所述步骤b)的所述训练中,更包括根据梯度下降算法评估所述自动编码器的重建中的误差的第一误差函数。31.如权利要求1所述的方法,其特征在于:所述编码器对第一训练数据集中每个对应的多个核酸甲基化片段中的对应的甲基化图谱和对应的多个核酸甲基化片段的对应的核酸序列进行编码,从而形成多个潜在特征;以及所述解码器将多个潜在特征解码为对应的核酸甲基化片段的对应的甲基化图谱和对应的核酸序列的重建。32.如权利要求1所述的方法,其特征在于:所述监督模型是逻辑回归模型。33.如权利要求1所述的方法,其特征在于:所述监督模型是神经网络算法、支持向量机算法、朴素贝叶斯算法、最近邻算法、提升树算法、随机森林算法、决策树算法、多项式逻辑回归算法、线性模型或线性回归算法。34.如权利要求1所述的方法,其特征在于:所述监督模型使用(i)所述多个第一训练受试者和所述多个第二训练受试者的多个特征中每个相应核酸甲基化片段的甲基化图谱;以及(ii)每个相应核酸甲基化片段的指示,所述指示有关于所述核酸甲基化片段是来自具有第一癌症状态的一训练受试者或是具有第二癌症状态的一训练受试者。35.如权利要求1所述的方法,其特征在于:所述步骤e)中更包括使用包括利用多个特征中的每个特征的对应分数来计算在多个特征中找到的多个第二cpg位点中每个cpg位点的一对应的cpg平均重建分数,从而计算多个对应的cpg平均重建分数。
36.如权利要求35所述的方法,其特征在于:所述步骤e)中更包括使用多个对应的cpg平均重建分数来选择一参考基因组中的多个低噪声区域、用于定向测序的参考基因组的多个区域或用于区分第一癌症状态和第二癌症状态的多个参考基因组区域。37.如权利要求1所述的方法,其特征在于:所述步骤d)中更包括选择与一对应分数相关联的甲基化图谱,其基于所述甲基化图谱位于所述步骤d)中作为多个特征中的一个特征而获得的前n个对应分数中。38.如权利要求37所述的方法,其特征在于:n介于100和2000之间。39.如权利要求37所述的方法,其特征在于:n为1000。40.如权利要求1至39任一项所述的方法,其特征在于:相应核酸甲基化片段的对应分数被限制在第一数字和第二数字之间。41.如权利要求40所述的方法,其特征在于:第一数字为0,第二个数字为1。42.如权利要求1所述的方法,其特征在于:所述监督模型是第一分布和第二分布之间的kullback
–
leibler距离;所述第一分布包括跨所述第一训练数据集或所述第二训练数据集的核酸甲基化片段的多个特征的多个第一对应分数;以及所述第二分布包括从一受试者的生物样本中获得的多个核酸甲基化片段的多个第二对应分数。43.如权利要求1所述的方法,其特征在于:相应核酸甲基化片段中对应的多个cpg位点中相应cpg位点的甲基化状态为:当相应的cpg位点通过甲基化测序确定为甲基化时被甲基化;当相应的cpg位点通过甲基化测序确定为未甲基化时未被甲基化;以及当甲基化测序无法将相应cpg位点的甲基化状态称为甲基化或未甲基化时标记为“其他”。44.如权利要求1所述的方法,其特征在于:甲基化测序是i)全基因组甲基化测序或ii)使用多个核酸探针的靶向dna甲基化测序。45.如权利要求1所述的方法,其特征在于:甲基化测序检测相应核酸甲基化片段中的一个或多个5-甲基胞嘧啶(5mc)及/或5-羟甲基胞嘧啶(5hmc)。46.如权利要求1所述的方法,其特征在于:核酸的甲基化测序包括将相应核酸甲基化片段中的一种或多种未甲基化胞嘧啶或一种或多种甲基化胞嘧啶转化为对应的一种或多种尿嘧啶。47.如权利要求46所述的方法,其特征在于:一种或多种尿嘧啶在甲基化测序期间被检测为一种或多种对应的胸腺嘧啶。48.如权利要求46所述的方法,其特征在于:一种或多种未甲基化胞嘧啶或一种或多种甲基化胞嘧啶的转化包括化学转化、酶促转化或其组合。49.如权利要求1至48任一项所述的方法,其特征在于:所述第一癌症状态是没有癌症。50.如权利要求1至49任一项所述的方法,其特征在于:所述第二癌症状态是肾上腺癌、胆道癌、膀胱癌、骨髓癌、脑癌、乳腺癌、宫颈癌、结直肠癌、食道癌、胃癌、头颈癌、肝胆癌、肾癌、肝癌、肺癌、卵巢癌、胰腺癌、骨盆癌、胸膜癌、前列腺癌、肾恶性肿瘤、皮肤癌、胃癌、睾丸癌、胸腺癌、甲状腺癌、子宫癌、淋巴瘤、黑色素瘤、多发性骨髓瘤、白血病或其组合。
51.如权利要求1至48任一项所述的方法,其特征在于:所述第一癌症状态是特定癌症的第一阶段;以及所述第二癌症状态是特定癌症的第二阶段。52.如权利要求51所述的方法,其特征在于:所述特定癌症是肾上腺癌、胆道癌、膀胱癌、骨/骨髓癌、脑癌、乳腺癌、宫颈癌、结肠直肠癌、食道癌、胃癌、头颈癌、肝胆癌、肾癌、肝癌、肺癌、卵巢癌、胰腺癌、骨盆癌、胸膜癌、前列腺癌、肾恶性肿瘤、皮肤癌、胃癌、睾丸癌、胸腺癌、甲状腺癌、子宫癌、淋巴瘤、黑色素瘤、多发性骨髓瘤、白血病或其组合。53.如权利要求1至48任一项所述的方法,其特征在于:所述第二癌症状态是肾上腺癌阶段、胆道癌阶段、膀胱癌阶段、骨/骨髓癌阶段、脑癌阶段、乳腺癌阶段、宫颈癌阶段、结直肠癌阶段、食道癌阶段、胃癌阶段、头颈癌阶段、肝胆癌阶段、肾癌阶段、肝癌阶段、肝癌阶段、卵巢癌阶段、胰腺癌阶段、盆腔癌阶段、胸膜癌阶段、前列腺癌阶段、肾恶性肿瘤阶段、皮肤癌阶段、胃癌阶段、睾丸癌阶段、胸腺癌阶段、甲状腺癌阶段、子宫癌阶段、淋巴瘤阶段、黑色素瘤阶段、多发性骨髓瘤阶段或白血病阶段。54.如权利要求1至53任一项所述的方法,其特征在于:从各个受试者获得的生物样本中核酸的甲基化测序是生物样本中无细胞核酸的甲基化测序。55.如权利要求1至54任一项所述的方法,其特征在于:所述生物样本是血液样本。56.如权利要求1至54任一项所述的方法,其特征在于:所述生物样本包括各个训练受试者的血液、全血、血浆、血清、尿液、脑脊液、粪便、唾液、汗液、泪液、胸膜液、心包液或腹膜液。57.如权利要求1至53任一项所述的方法,其特征在于:对于所述第一癌症状态,相应的生物样本是同质的。58.如权利要求1至53任一项所述的方法,其特征在于:相应的生物样本是对于第一癌症状态同质的肿瘤样本。59.如权利要求1所述的方法,其特征在于:所述方法更包括:f)获得电子形式的一测试数据集,其中:对于一测试受试者,所述测试数据集包括通过对从所述测试受试者获得的生物样本中的核酸进行甲基化测序确定的多个测试核酸甲基化片段中的每个相应核酸甲基化片段的对应的甲基化图谱和对应的核酸序列;所述对应的甲基化图谱包括相应测试核酸甲基化片段中对应的多个cpg位点中每个相应cpg位点的一甲基化状态;以及g)将所述测试数据集的全部或部分应用于所述监督模型,从而从所述监督模型获得关于所述测试受试者是否具有所述第一癌症状态或所述第二癌症状态的确定。60.如权利要求1所述的方法,其特征在于:使用第一误差函数计算对应分数。61.如权利要求1所述的方法,其特征在于:使用不同于第一误差函数的一第二误差函数来计算相应核酸甲基化片段的对应分数。62.如权利要求1所述的方法,其特征在于:相应核酸甲基化片段的对应分数计算如下:a(f)=loss(f,f
′
);其中,f是相应核酸甲基化片段的对应的甲基化图谱;
f’是在将对应的甲基化图谱和相应核酸甲基化片段的对应的核酸序列输入到自动编码器后,自动编码器对相应核酸甲酯化片段的对应的甲基化图谱的重建;以及loss是f和f'之间的损失。63.如权利要求62所述的方法,其特征在于:所述loss是f和f'之间的一重建误差、f和f'之间的一汉明距离、f和f'之间的一交叉熵损失、f和f'之间的均方误差或f和f'之间的平均绝对误差。64.如权利要求1所述的方法,其特征在于:相应核酸甲基化片段的对应分数计算如下:a(f)=w1*loss(f,f
′
) w2*距离[e(f),e(f_nc)];其中,w1是第一权重;f是相应核酸甲基化片段的对应的甲基化图谱;f’是在将对应的甲基化图谱和相应核酸甲基化片段的对应的核酸序列输入到自动编码器后,自动编码器对相应核酸甲酯化片段的对应的甲基化图谱的重建;以及w2是第二权重;loss是f和f'之间的损失;e(f)是在将相应核酸甲基化片段的对应的甲基化图谱输入自动编码器时由自动编码器产生的编码;f_nc是核酸甲基化片段的甲基化图谱和核酸序列,其定位于与相应核酸甲基化片段相同的基因组位置并且具有与相应核酸甲基化片段相同的序列;e(f_nc)是自动编码器在将f_nc输入到自动编码器时产生的编码;以及距离是e(f)和e(f_nc)之间的距离度量或相似性度量。65.如权利要求64所述的方法,其特征在于:所述距离是余弦距离、欧几里得距离、曼哈顿距离、雅卡距离、相关距离、卡方距离或马氏距离。66.如权利要求64所述的方法,其特征在于:w1和w2的数值均为1。67.如权利要求64所述的方法,其特征在于:w1和w2各有不同的数值。68.如权利要求1所述的方法,其特征在于:在所述第一训练数据集上为所述经训练的自动编码器所计算的误差满足一误差阈值。69.如权利要求68所述的方法,其特征在于:当误差小于5%时,第一误差函数在第一训练数据集上计算的误差满足所述误差阈值。70.如权利要求1所述的方法,其特征在于:所述第一训练数据集或第二训练数据集包括:通过对从相应的训练受试者获得的生物样本中的核酸进行甲基化测序确定的对应的多个核酸甲基化片段中的第一核酸甲基化片段的第一对应核酸序列。71.如权利要求70所述的方法,其特征在于:所述第一对应核酸序列来自所述第一核酸甲基化片段的正向链或反向链。72.如权利要求71所述的方法,其特征在于:所述第一对应核酸序列是所述第一核酸甲基化片段的反向链并且是反向互补形式,或被标记为所述第一核酸甲基化片段的反向链。73.一种用于区分一第一癌症状态和一第二癌症状态的计算器系统,其中所述第一癌症状态不同于所述第二癌症状态,其特征在于:所述计算器系统包括:
至少一个处理器;以及一存储器,存储用于由所述至少一处理器执行的至少一个程序,所述至少一个程序包括用于以下操作的指令:a)获得电子形式的一第一训练数据集,其中:对于多个第一训练受试者中的每个相应训练受试者,所述第一训练数据集包括多个对应的核酸甲基化片段中的每个相应核酸甲基化片段的一对应的甲基化图谱和一对应的核酸序列,所述对应多个核酸甲基化片段是由从各个受试者获得的一生物样本的核酸进行一甲基化测序确定的;其中所述对应的甲基化图谱包括所述相应核酸甲基化片段中对应的多个cpg位点中每个相应cpg位点的一甲基化状态;其中所述多个第一训练受试者中的每个训练受试者具有所述第一癌症状态;b)训练一未经训练的自动编码器,其中所述未经训练的自动编码器包括1000个或更多权重,并且其中所述未经训练的自动编码包括一编码器和一解码器,对于所述第一训练数据集中的每个对应的多个核酸甲基化片段中的每个相应核酸甲基化片段的每个对应的核酸序列,使用所述第一训练数据集中的每个对应的多个核酸甲基化片段中的每个相应核酸甲基化片段中的所述对应的甲基化图谱和对应的核酸序列作为输入,通过所述对应的核酸甲基化片段中所述对应的甲基化图谱和所述对应的核酸序列来评估所述自动编码器的重建的一误差的一第一误差函数,从而形成一经训练的自动编码器;c)获得电子形式的一第二训练数据集,其中:对于多个第二训练受试者中的每个相应训练受试者,所述第二训练数据集包括通过从各自受试者获得的一生物样本中的核酸进行一甲基化测序所确定的一对应的多个核酸甲基化片段中每个相应核酸甲基化片段的一对应的甲基化图谱和一对应的核酸序列,所述对应的甲基化图谱包括相应核酸甲基化片段中对应的多个cpg位点中每个相应cpg位点的一甲基化状态;其中所述多个第二训练受试者中的每个训练受试者具有所述第二癌症状态;d)使用所述第二训练数据集和所述经训练的自动编码器通过计算从所述第二训练数据集表示的多个序列或多个甲基化图谱中识别多个特征,对于所述第二训练数据集中的每个对应的多个核酸甲基化片段中的每个相应核酸甲基化片段,在将相应核酸甲基化片段的对应的甲基化图谱和对应的核酸序列输入到所述经训练的自动编码器中时,由所述自动编码器至少部分地对所述相应核酸甲基化片段的对应的甲基化图谱进行一重建来确定一对应分数;以及e)使用所述多个特征来训练用于区分所述第一癌症状态和所述第二癌症状态的一监督模型。74.一种非暂时性计算机可读存储介质,其上存储有多个程序代码指令,当由一处理器执行时,所述程序代码指令使处理器执行区分一第一癌症状态和一第二癌症状态的一方法,其中所述第一癌症状态不同于所述第二癌癌状态,其特征在于:所述方法包括:a)获得电子形式的一第一训练数据集,其中:对于多个第一训练受试者中的每个相应训练受试者,所述第一训练数据集包括多个对应的核酸甲基化片段中的每个相应核酸甲基化片段的一对应的甲基化图谱和一对应的核
酸序列,所述对应多个核酸甲基化片段是由从各个受试者获得的一生物样本中的核酸进行一甲基化测序确定的;其中所述对应的甲基化图谱包括所述相应核酸甲基化片段中对应的多个cpg位点中每个相应cpg位点的一甲基化状态;其中所述多个第一训练受试者中的每个训练受试者具有所述第一癌症状态;b)训练一未经训练的自动编码器,其中所述未经训练的自动编码器包括1000个或更多权重,并且其中所述未经训练的自动编码包括一编码器和一解码器,对于所述第一训练数据集中的每个对应的多个核酸甲基化片段中的每个相应核酸甲基化片段的每个对应的核酸序列,使用所述第一训练数据集中的每个对应的多个核酸甲基化片段中的每个相应核酸甲基化片段中的所述对应的甲基化图谱和对应的核酸序列作为输入,通过所述对应的核酸甲基化片段中所述对应的甲基化图谱和所述对应的核酸序列来评估所述自动编码器的重建的一误差的一第一误差函数,从而形成一经训练的自动编码器;c)获得电子形式的一第二训练数据集,其中:对于多个第二训练受试者中的每个相应训练受试者,所述第二训练数据集包括通过从各自受试者获得的一生物样本中的核酸进行一甲基化测序所确定的一对应的多个核酸甲基化片段中每个相应核酸甲基化片段的一对应的甲基化图谱和一对应的核酸序列,所述对应的甲基化图谱包括相应核酸甲基化片段中对应的多个cpg位点中每个相应cpg位点的一甲基化状态;其中所述多个第二训练受试者中的每个训练受试者具有所述第二癌症状态;d)使用所述第二训练数据集和所述经训练的自动编码器通过计算从所述第二训练数据集表示的多个序列或多个甲基化图谱中识别多个特征,对于所述第二训练数据集中的每个对应的多个核酸甲基化片段中的每个相应核酸甲基化片段,在将相应核酸甲基化片段的对应的甲基化图谱和对应的核酸序列输入到所述经训练的自动编码器中时,由所述自动编码器至少部分地对所述相应核酸甲基化片段的对应的甲基化图谱进行一重建来确定一对应分数;以及e)使用所述多个特征来训练用于区分所述第一癌症状态和所述第二癌症状态的一监督模型。75.一种形成用于检测一癌症状态的一分类器的方法,其特征在于:所述方法包括:在包括至少一个处理器和一存储器的一计算器系统中,所述存储器存储用于由所述至少一个处理器执行的至少一个程序,所述至少一个程序包括用于以下的多个指令:a)获得电子形式的一训练数据集,其中:对于多个训练受试者中的每个相应训练受试者,所述训练数据集包括多个对应的核酸甲基化片段中的每个相应核酸甲基化片段的一对应的甲基化图谱和一对应的核酸序列,所述对应多个核酸甲基化片段是由从各个受试者获得的一生物样本中的核酸进行一甲基化测序确定的;其中所述对应的甲基化图谱包括所述相应核酸甲基化片段中对应的多个cpg位点中每个相应cpg位点的一甲基化状态;其中所述多个训练受试者中的每个训练受试者具有所述癌症状态;b)训练一未经训练的自动编码器,其中所述未经训练的自动编码器包括1000个或更多
权重,并且其中所述未经训练的自动编码包括一编码器和一解码器,对于所述训练数据集中的每个对应的多个核酸甲基化片段中的每个相应核酸甲基化片段的每个对应的核酸序列,使用所述训练数据集中的每个对应的多个核酸甲基化片段中的每个相应核酸甲基化片段中的所述对应的甲基化图谱和对应的核酸序列作为输入,其中对于所述训练数据集中每个对应的多个核酸甲基化片段中每个相应核酸甲基化片段的每个对应的核酸序列,所述训练包括通过所述对应的核酸甲基化片段中所述对应的甲基化图谱和所述对应的核酸序列来评估所述自动编码器的重建的一误差的一第一误差函数,从而形成一经训练的自动编码器。76.如权利要求75所述的方法,其特征在于:所述至少一个程序还包括以下指令:c)获得电子形式的一测试数据集,其中:对于一测试受试者,所述测试数据集包括通过从所述测试受试者获得的一生物样本中的核酸进行一甲基化测序所确定的多个测试核酸甲基化片段中每个相应测试核酸甲基化片段的一对应的甲基化图谱和一对应的核酸序列;以及所述对应的甲基化图谱包括相应测试核酸甲基化片段中对应的多个cpg位点中每个相应cpg位点的一甲基化状态;以及d)将所述测试数据集的全部或部分应用到所述经训练的自动编码器,以确定所述测试受试者是否患有所述癌症状态,其中,步骤d)中,对于所述测试数据集中的多个测试核酸甲基化片段中的每个相应测试核酸甲基化片段,在将相应测试核酸甲基化片段的对应的甲基化图谱和对应的核酸序列输入到所述自动编码器中时,通过所述经训练的自动编码器重建相应核酸甲基化片段的对应的甲基化图谱,计算至少部分确定的一对应分数。77.如权利要求76所述的方法,其特征在于:相应核酸甲基化片段的所述对应分数:通过所述经训练的自动编码器对相应核酸甲基化片段的对应的甲基化图谱的所述重建的正确性确定;以及与通过所述经训练的自动编码器重建相应核酸甲基化片段的对应的核酸序列的正确性无关。78.如权利要求76所述的方法,其特征在于:相应核酸甲基化片段的所述对应分数:由所述经训练的自动编码器重建相应核酸甲基化片段的对应的甲基化图谱的正确性决定;以及进一步由所述经训练的自动编码器重建相应核酸甲基化片段的对应的核酸序列的正确性确定。79.如权利要求77或78所述的方法,其特征在于:由自动编码器的重建的相应核酸甲基化片段的对应的甲基化图谱的正确性至少部分由相应核酸甲基化片段的对应的甲基化图谱的重建与相应核酸甲基化片段的实际甲基化图谱之间的汉明距离确定。80.如权利要求76所述的方法,其特征在于:所述对应的多个核酸甲基化片段,由从所述训练数据集中的相应受试者获得的生物样本进行一核酸甲基化序列来确定,并且包括一千以上、一万以上、十万以上、一百万以上、一千万以上、一亿以上、五亿以上、十亿以上、二十亿以上、三十亿以上、五十亿以上、六十亿以上、七十亿以上、八十亿以上、九十亿以上,或一百亿或更多的核酸甲基化片段。81.如权利要求75所述的方法,其特征在于:所述多个训练受试者包括10个或更多、20
个或更多、30个或更多、50个或更多、100个或更多、1000个或更多、2000个或更多、3000个或更多、或5000个或更多个训练受试者。82.如权利要求75所述的方法,其特征在于:所述至少一个程序还包括用于在步骤a)的所述获得之后和步骤的b)所述训练之前:通过从对应的多个核酸甲基化片段中去除不满足一个或多个选择标准的每个相应的核酸甲基化片段来对每个对应的多个核酸甲基化片段进行过滤。83.如权利要求82所述的方法,其特征在于:当相应核酸甲基化片段的甲基化图谱具有不满足一p值阈值的一输出p值时,相应核酸甲基化片段不满足一个或多个选择标准中的一选择标准;以及至少部分地基于在所述相应核酸甲基化片段的多个cpg位点上的所述相应核酸甲基化片段的甲基化图谱与所述训练数据集中具有相应多个cpg位点的所述核酸甲基化片段的甲基化图谱的对应分布的一比较来确定相应核酸甲基化片段的所述输出p值。84.如权利要求82所述的方法,其特征在于:当由一训练的马尔可夫模型提供的一输出p值响应于所述相应核酸甲基化片段的甲基化图谱的输入而未通过一选择标准时,来自所述训练数据集的所述相应核酸甲基化片段未能满足一个或多个选择标准中的一选择标准;以及所述训练的马尔可夫模型至少部分地基于在所述训练数据集中具有对应的多个cpg位点的所述核酸甲基化片段之间的相应核酸甲基化片段的多个cpg位点中的每个cpg位置的一甲基化状态的评估来训练。85.如权利要求83或84所述的方法,其特征在于:所述输出p值在0.00001和0.20之间。86.如权利要求83或84所述的方法,其特征在于:所述输出p值为0.05。87.如权利要求82所述的方法,其特征在于:当所述相应核酸甲基化片段具有小于一阈值数量的cpg位点时,相应核酸甲基化片段不满足一个或多个选择标准中的一选择标准。88.如权利要求87所述的方法,其特征在于:cpg位点的阈值数量为4、5、6、7、8、9或10。89.如权利要求82所述的方法,其特征在于:当所述相应核酸甲基化片段具有小于一阈值数量的残基时,所述相应核酸甲基化片段不满足一个或多个选择标准中的一选择标准。90.如权利要求89所述的方法,其特征在于:残基的阈值数量为32或64。91.如权利要求89所述的方法,其特征在于:残基的阈值数量是20到90之间的一固定值。92.如权利要求82所述的方法,其特征在于:所述过滤移除所述多个核酸甲基化片段中的一核酸甲基化碎片,所述核酸甲基化碎片与所述多个核酸甲基化片段中的另一核酸甲基化片段具有相同的对应的甲基化图谱和相同的对应的核酸序列。93.如权利要求92所述的方法,其特征在于:所述过滤保留所述多个核酸甲基化片段中的一核酸甲基化碎片,所述核酸甲基化碎片与所述多个核酸甲基化片段中的另一核酸甲基化片段具有相同的对应的甲基化图谱和不同的对应的核酸序列。94.如权利要求92所述的方法,其特征在于:所述过滤保留所述多个核酸甲基化片段中的一核酸甲基化碎片,所述核酸甲基化碎片与所述多个核酸甲基化片段中的另一核酸甲基化片段具有不同的对应的甲基化图谱和相同的对应的核酸序列。95.如权利要求82所述的方法,其特征在于:
当所述相应核酸甲基化片段的小于一阈值数量的cpg位点时,所述相应核酸甲基化片段不能满足一个或多个选择标准中的一选择标准;在步骤a)中训练所述自动编码器之前获得将对应的多个核酸甲基化片段中小于一预定长度的每个核酸甲基化片段填充为一预定长度;以及在步骤a)中通过通过以一预定步幅跨相应核酸甲基化片段开窗,截断对应的多个核酸甲基化片段中大于预定长度的每个相应核酸甲基化片段,从而将相应核酸甲基化片段截断为两个或多个序列段,其中两个或多个序列段各自具有所述预定长度,并且各自具有至少为所述阈值数量的cpg位点,并共同替换对应的多个核酸甲基化片段中的相应核酸甲基化片段。96.如权利要求95所述的方法,其特征在于:所述片段长度在90个核苷酸到300个核苷酸之间。97.如权利要求95所述的方法,其特征在于:所述片段长度为100个核苷酸、128个核苷酸或256个核苷酸。98.如权利要求75至97中任一项所述的方法,其特征在于:在步骤a)中,截断多个核酸甲基化片段中的第一核酸甲基化片段,所述第一核酸甲基化片段长于预定长度,位于所述第一核酸甲基化片段内的变异的位点、冲突甲基化调用的位点或不明确调用的位点被截断,从而缩短所述第一核酸甲基化片段以终止于所述位点。99.如权利要求75所述的方法,其特征在于:所述经训练的自动编码器是一变分自动编码器、一叠层去噪深度自动编码器、一深度循环自动编码器、一卷积式自动编码器或一变压器网络。100.如权利要求75所述的方法,其特征在于:所述经训练的自动编码器是一深度循环自动编码器,并且在步骤b)的所述训练中,对于所述训练数据集中对应的多个序列中的一相应核酸甲基化片段:向所述深度循环自动编码器的一第一轨道提供被分解成多个k聚体的各个核酸甲基化片段的对应的核酸序列;以及向所述深度循环自动编码器的一第二轨道提供相应核酸甲基化片段的对应的甲基化图谱。101.如权利要求75所述的方法,其特征在于:所述经训练的自动编码器是一深度循环自动编码器,并且在步骤b)的所述训练中,对于所述训练数据集中对应的核酸甲基化片段中的相应核酸甲基化片段:以残基为基础向所述深度循环自动编码器的第一轨道提供相应核酸甲基化片段的对应的核酸序列;以及向所述深度循环自动编码器的一第二轨道提供提供相应核酸甲基化片段的对应的甲基化图谱。102.如权利要求75所述的方法,其特征在于:所述步骤b)的所述训练中,更包括根据梯度下降算法评估所述自动编码器的重建中的误差的第一误差函数。103.如权利要求75所述的方法,其特征在于:所述经训练的编码器对所述训练数据集中每个对应的多个核酸甲基化片段中的对应的甲基化图谱和对应的多个核酸甲基化片段的对应的核酸序列进行编码,从而形成多个潜
在特征;以及所述解码器将多个潜在特征解码为对应的核酸甲基化片段的对应的甲基化图谱和对应的核酸序列的重建。104.如权利要求75至103中任一项所述的方法,其特征在于:所述重建的分数被限制在第一数字和第二数字之间。105.如权利要求104所述的方法,其特征在于:所述第一数字为0且所述第二数字为1。106.如权利要求75所述的方法,其特征在于:相应核酸甲基化片段中对应的多个cpg位点中相应cpg位点的甲基化状态为:当相应的cpg位点通过甲基化测序确定为甲基化时被甲基化;当相应的cpg位点通过甲基化测序确定为未甲基化时未被甲基化;以及当甲基化测序无法将相应cpg位点的甲基化状态称为甲基化或未甲基化时标记为“其他”。107.如权利要求75所述的方法,其特征在于:所述甲基化测序是i)全基因组甲基化测序或ii)使用多个核酸探针的靶向dna甲基化测序。108.如权利要求75所述的方法,其特征在于:甲基化测序检测相应核酸甲基化片段中的一个或多个5-甲基胞嘧啶(5mc)及/或5-羟甲基胞嘧啶(5hmc)。109.如权利要求75所述的方法,其特征在于:核酸的甲基化测序包括将相应核酸甲基化片段中的一种或多种未甲基化胞嘧啶或一种或多种甲基化胞嘧啶转化为对应的一种或多种尿嘧啶。110.如权利要求109所述的方法,其特征在于:一种或多种尿嘧啶在甲基化测序期间被检测为一种或多种对应的胸腺嘧啶。111.如权利要求109所述的方法,其特征在于:一种或多种未甲基化胞嘧啶或一种或多种甲基化胞嘧啶的转化包括化学转化、酶促转化或其组合。112.如权利要求75至111中任一项所述的方法,其特征在于:所述癌症状态是肾上腺癌、胆道癌、膀胱癌、骨髓癌、脑癌、乳腺癌、宫颈癌、结直肠癌、食道癌、胃癌、头颈癌、肝胆癌、肾癌、肝癌、肺癌、卵巢癌、胰腺癌、骨盆癌、胸膜癌、前列腺癌、肾恶性肿瘤、皮肤癌、胃癌、睾丸癌、胸腺癌、甲状腺癌、子宫癌、淋巴瘤、黑色素瘤、多发性骨髓瘤、白血病或其组合。113.如权利要求75至111中任一项所述的方法,其特征在于:所述癌症状态是一特定癌症的一个阶段。114.如权利要求113所述的方法,其特征在于:所述特定癌症是肾上腺癌、胆道癌、膀胱癌、骨/骨髓癌、脑癌、乳腺癌、宫颈癌、结肠直肠癌、食道癌、胃癌、头颈癌、肝胆癌、肾癌、肝癌、肺癌、卵巢癌、胰腺癌、骨盆癌、胸膜癌、前列腺癌、肾恶性肿瘤、皮肤癌、胃癌、睾丸癌、胸腺癌、甲状腺癌、子宫癌、淋巴瘤、黑色素瘤、多发性骨髓瘤、白血病或其组合。115.如权利要求75至114任一项所述的方法,其特征在于:从各个受试者获得的生物样本中核酸的甲基化测序是生物样本中无细胞核酸的甲基化测序。116.如权利要求75至115任一项所述的方法,其特征在于:所述生物样本是血液样本。117.如权利要求75至115任一项所述的方法,其特征在于:所述生物样本包括各个训练受试者的血液、全血、血浆、血清、尿液、脑脊液、粪便、唾液、汗液、泪液、胸膜液、心包液或腹膜液。
118.如权利要求75至115任一项所述的方法,其特征在于:对于所述癌症状态,相应的生物样本是同质的。119.如权利要求75至115任一项所述的方法,其特征在于:相应的生物样本是对于所述癌症状态同质的肿瘤样本。120.如权利要求76所述的方法,其特征在于:使用第一误差函数计算对应分数。121.如权利要求76所述的方法,其特征在于:使用不同于第一误差函数的一第二误差函数来计算相应核酸甲基化片段的对应分数。122.如权利要求76所述的方法,其特征在于:相应核酸甲基化片段的对应分数计算如下:a(f)=loss(f,f
′
);其中,f是相应核酸甲基化片段的对应的甲基化图谱;f’是在将对应的甲基化图谱和相应核酸甲基化片段的对应的核酸序列输入到自动编码器后,自动编码器对相应核酸甲酯化片段的对应的甲基化图谱的重建;以及loss是f和f'之间的损失。123.如权利要求76所述的方法,其特征在于:所述loss是f和f'之间的一重建误差、f和f'之间的一汉明距离、f和f'之间的一交叉熵损失、f和f'之间的均方误差或f和f'之间的平均绝对误差。124.如权利要求75所述的方法,其特征在于:相应核酸甲基化片段的对应分数计算如下:a(f)=w1*loss(f,f
′
) w2*距离[e(f),e(f_nc)];其中,w1是第一权重;f是相应核酸甲基化片段的对应的甲基化图谱;f’是在将对应的甲基化图谱和相应核酸甲基化片段的对应的核酸序列输入到自动编码器后,自动编码器对相应核酸甲酯化片段的对应的甲基化图谱的重建;以及w2是第二权重;loss是f和f'之间的损失;e(f)是在将相应核酸甲基化片段的对应的甲基化图谱输入自动编码器时由自动编码器产生的编码;f_nc是核酸甲基化片段的甲基化图谱和核酸序列,其定位于与相应核酸甲基化片段相同的基因组位置并且具有与相应核酸甲基化片段相同的序列;e(f_nc)是自动编码器在将f_nc输入到自动编码器时产生的编码;以及距离是e(f)和e(f_nc)之间的距离度量或相似性度量。125.如权利要求124所述的方法,其特征在于:所述距离是余弦距离、欧几里得距离、曼哈顿距离、雅卡距离、相关距离、卡方距离或马氏距离。126.如权利要求124所述的方法,其特征在于:w1和w2的数值均为1。127.如权利要求124所述的方法,其特征在于:w1和w2各有不同的数值。128.如权利要求75所述的方法,其特征在于:在所述第一训练数据集上为所述经训练
的自动编码器所计算的误差满足一误差阈值。129.如权利要求128所述的方法,其特征在于:当误差小于5%时,第一误差函数在第一训练数据集上计算的误差满足所述误差阈值。130.如权利要求75所述的方法,其特征在于:所述训练数据集包括:通过对从相应的训练受试者获得的生物样本中的核酸进行甲基化测序确定的对应的多个核酸甲基化片段中的第一核酸甲基化片段的第一对应核酸序列。131.如权利要求130所述的方法,其特征在于:所述第一对应核酸序列来自所述第一核酸甲基化片段的正向链或反向链。132.如权利要求131所述的方法,其特征在于:所述第一对应核酸序列是所述第一核酸甲基化片段的反向链并且是反向互补形式,或被标记为所述第一核酸甲基化片段的反向链。133.一种用于形成用于检测一癌症状态的一分类器的计算器系统,其特征在于:所述计算器系统包括:至少一个处理器;以及一存储器,存储用于由所述至少一处理器执行的至少一个程序,所述至少一个程序包括用于以下操作的指令:a)获得电子形式的一训练数据集,其中:对于多个训练受试者中的每个相应训练受试者,所述训练数据集包括多个对应的核酸甲基化片段中的每个相应核酸甲基化片段的一对应的甲基化图谱和一对应的核酸序列,所述对应多个核酸甲基化片段是由从各个受试者获得的一生物样本中的核酸进行一甲基化测序确定的;其中所述对应的甲基化图谱包括所述相应核酸甲基化片段中对应的多个cpg位点中每个相应cpg位点的一甲基化状态;其中所述多个训练受试者中的每个训练受试者具有所述癌症状态;b)训练一未经训练的自动编码器,其中所述未经训练的自动编码器包括1000个或更多权重,并且其中所述未经训练的自动编码包括一编码器和一解码器,对于所述训练数据集中的每个对应的多个核酸甲基化片段中的每个相应核酸甲基化片段的每个对应的核酸序列,使用所述训练数据集中的每个对应的多个核酸甲基化片段中的每个相应核酸甲基化片段中的所述对应的甲基化图谱和对应的核酸序列作为输入,其中对于所述训练数据集中每个对应的多个核酸甲基化片段中每个相应核酸甲基化片段的每个对应的核酸序列,所述训练包括通过所述对应的核酸甲基化片段中所述对应的甲基化图谱和所述对应的核酸序列来评估所述自动编码器的重建的一误差的一第一误差函数,从而形成一经训练的自动编码器。134.一种非暂时性计算机可读存储介质,其上存储有多个程序代码指令,当由一处理器执行时,所述程序代码指令使处理器执行一形成用于检测癌症状态的分类器的方法,其特征在于:所述方法包括:a)获得电子形式的一训练数据集,其中:对于多个训练受试者中的每个相应训练受试者,所述训练数据集包括多个对应的核酸甲基化片段中的每个相应核酸甲基化片段的一对应的甲基化图谱和一对应的核酸序列,所
述对应多个核酸甲基化片段是由从各个受试者获得的一生物样本中的核酸进行一甲基化测序确定的;其中所述对应的甲基化图谱包括所述相应核酸甲基化片段中对应的多个cpg位点中每个相应cpg位点的一甲基化状态;其中所述多个训练受试者中的每个训练受试者具有所述癌症状态;b)训练一未经训练的自动编码器,其中所述未经训练的自动编码器包括1000个或更多权重,并且其中所述未经训练的自动编码包括一编码器和一解码器,对于所述训练数据集中的每个对应的多个核酸甲基化片段中的每个相应核酸甲基化片段的每个对应的核酸序列,使用所述训练数据集中的每个对应的多个核酸甲基化片段中的每个相应核酸甲基化片段中的所述对应的甲基化图谱和对应的核酸序列作为输入,其中对于所述训练数据集中每个对应的多个核酸甲基化片段中每个相应核酸甲基化片段的每个对应的核酸序列,所述训练包括通过所述对应的核酸甲基化片段中所述对应的甲基化图谱和所述对应的核酸序列来评估所述自动编码器的重建的一误差的一第一误差函数,从而形成一经训练的自动编码器。135.一种检测一癌症状态的方法,其特征在于:所述方法包括:在包括至少一个处理器和一存储器的一计算器系统中,所述存储器存储用于由所述至少一个处理器执行的至少一个程序,所述至少一个程序包括用于以下的多个指令:a)获得电子形式的一测试数据集,其中:对于一测试受试者,所述测试数据集包括通过从所述测试受试者获得的一生物样本中的核酸进行一甲基化测序所确定的多个核酸甲基化片段中每个相应核酸甲基化片段的一对应的甲基化图谱和一对应的核酸序列;以及所述对应的甲基化图谱包括相应核酸甲基化片段中对应的多个cpg位点中每个相应cpg位点的一甲基化状态;以及b)将多个核酸甲基化片段的全部或部分中的每个相应核酸甲基化片段的对应的甲基化图谱和对应的核酸序列应用到所述经训练的自动编码器,以确定所述测试受试者是否患有所述癌症状态,其中,步骤b)中,对于所述多个核酸甲基化片段的全部或部分中的每个相应核酸甲基化片段,在将相应测试核酸甲基化片段的对应的甲基化图谱和对应的核酸序列输入到所述经训练的自动编码器中时,通过所述经训练的自动编码器重建相应核酸甲基化片段的对应的甲基化图谱来计算至少部分确定的一对应分数,其中所述经训练的自动编码器包括1000个或更多权重。136.如权利要求135所述的方法,其特征在于:相应核酸甲基化片段的所述对应分数:通过所述经训练的自动编码器对相应核酸甲基化片段的对应的甲基化图谱的所述重建的正确性确定;以及与通过所述经训练的自动编码器重建相应核酸甲基化片段的对应的核酸序列的正确性无关。137.如权利要求135所述的方法,其特征在于:相应核酸甲基化片段的所述对应分数:由所述经训练的自动编码器重建相应核酸甲基化片段的对应的甲基化图谱的正确性决定;以及进一步由所述经训练的自动编码器重建相应核酸甲基化片段的对应的核酸序列的正
确性确定。138.如权利要求136或137所述的方法,其特征在于:由所述经训练的自动编码器的重建的相应核酸甲基化片段的对应的甲基化图谱的正确性至少部分由相应核酸甲基化片段的对应的甲基化图谱的重建与相应核酸甲基化片段的实际甲基化图谱之间的汉明距离确定。139.如权利要求135所述的方法,其特征在于:所述多个核酸甲基化片段包括一千以上、一万以上、十万以上、一百万以上、一千万以上、一亿以上、五亿以上、十亿以上、二十亿以上、三十亿以上、五十亿以上、六十亿以上、七十亿以上、八十亿以上、九十亿以上,或一百亿或更多的核酸甲基化片段。140.如权利要求135所述的方法,其特征在于:所述至少一个程序还包括用于在步骤a)的所述获得之后和步骤的b)所述应用之前:通过从多个核酸甲基化片段中去除不满足一个或多个选择标准的每个相应的核酸甲基化片段来对多个核酸甲基化片段进行过滤。141.如权利要求140所述的方法,其特征在于:当相应核酸甲基化片段的甲基化图谱具有不满足一p值阈值的一输出p值时,相应核酸甲基化片段不满足一个或多个选择标准中的一选择标准;以及至少部分地基于在所述相应核酸甲基化片段的多个cpg位点上的所述相应核酸甲基化片段的甲基化图谱与所述训练数据集中具有相应多个cpg位点的所述核酸甲基化片段的甲基化图谱的对应分布的一比较来确定相应核酸甲基化片段的所述输出p值。142.如权利要求140所述的方法,其特征在于:当由一训练的马尔可夫模型提供的一输出p值响应于所述相应核酸甲基化片段的甲基化图谱的输入而未通过一选择标准时,所述相应核酸甲基化片段未能满足一个或多个选择标准中的一选择标准;以及所述训练的马尔可夫模型至少部分地基于在所述训练数据集中具有对应的多个cpg位点的所述核酸甲基化片段之间的相应核酸甲基化片段的多个cpg位点中的每个cpg位置的一甲基化状态的评估来训练。143.如权利要求141或142所述的方法,其特征在于:所述输出p值在0.00001和0.20之间。144.如权利要求141或142所述的方法,其特征在于:所述输出p值为0.05。145.如权利要求140所述的方法,其特征在于:当所述相应核酸甲基化片段具有小于一阈值数量的cpg位点时,相应核酸甲基化片段不满足一个或多个选择标准中的一选择标准。146.如权利要求145所述的方法,其特征在于:cpg位点的阈值数量为4、5、6、7、8、9或10。147.如权利要求140所述的方法,其特征在于:当所述相应核酸甲基化片段具有小于一阈值数量的残基时,所述相应核酸甲基化片段不满足一个或多个选择标准中的一选择标准。148.如权利要求147所述的方法,其特征在于:残基的阈值数量为32或64。149.如权利要求147所述的方法,其特征在于:残基的阈值数量是20到90之间的一固定值。
150.如权利要求140所述的方法,其特征在于:所述过滤移除所述多个核酸甲基化片段中的一核酸甲基化碎片,所述核酸甲基化碎片与所述多个核酸甲基化片段中的另一核酸甲基化片段具有相同的对应的甲基化图谱和相同的对应的核酸序列。151.如权利要求150所述的方法,其特征在于:所述过滤保留所述多个核酸甲基化片段中的一核酸甲基化碎片,所述核酸甲基化碎片与所述多个核酸甲基化片段中的另一核酸甲基化片段具有相同的对应的甲基化图谱和不同的对应的核酸序列。152.如权利要求150所述的方法,其特征在于:所述过滤保留所述多个核酸甲基化片段中的一核酸甲基化碎片,所述核酸甲基化碎片与所述多个核酸甲基化片段中的另一核酸甲基化片段具有不同的对应的甲基化图谱和相同的对应的核酸序列。153.如权利要求140所述的方法,其特征在于:当所述相应核酸甲基化片段的小于一阈值数量的cpg位点时,所述相应核酸甲基化片段不能满足一个或多个选择标准中的一选择标准;在步骤a)中,在将相应核酸甲基化片段的对应的甲基化图谱和对应的核酸序列应用于所述经训练的自动编码器之前,获得将对应的多个核酸甲基化片段中小于一预定长度的每个核酸甲基化片段填充为一预定长度;以及在步骤a)中,通过以一预定步幅跨相应核酸甲基化片段开窗,截断对应的多个核酸甲基化片段中大于预定长度的每个相应核酸甲基化片段,从而将相应核酸甲基化片段截断为两个或多个序列段,其中两个或多个序列段各自具有所述预定长度,并且各自具有至少为所述阈值数量的cpg位点,并共同替换多个核酸甲基化片段中的相应核酸甲基化片段作为步骤b)中所述应用的所述输入。154.如权利要求153所述的方法,其特征在于:所述预定步幅在90个核苷酸到300个核苷酸之间。155.如权利要求153所述的方法,其特征在于:所述预定步幅为100个核苷酸、128个核苷酸或256个核苷酸。156.如权利要求135至155中任一项所述的方法,其特征在于:在步骤a)中,截断多个核酸甲基化片段中的第一核酸甲基化片段,所述第一核酸甲基化片段长于预定长度,位于所述第一核酸甲基化片段内的变异的位点、冲突甲基化调用的位点或不明确调用的位点被截断,从而缩短所述第一核酸甲基化片段以终止于所述位点。157.如权利要求135所述的方法,其特征在于:所述经训练的自动编码器是一变分自动编码器、一叠层去噪深度自动编码器、一深度循环自动编码器、一卷积式自动编码器或一变压器网络。158.如权利要求135所述的方法,其特征在于:所述经训练的自动编码器是一深度循环自动编码器,并且在步骤b)的所述应用中,对于多个核酸甲基化片段中的一相应核酸甲基化片段:以残基为基础向所述深度循环自动编码器的第一轨道提供相应核酸甲基化片段的对应的核酸序列;以及向所述深度循环自动编码器的一第二轨道提供提供相应核酸甲基化片段的对应的甲基化图谱。159.如权利要求135所述的方法,其特征在于:所述经训练的自动编码器是一深度循环
自动编码器,并且在步骤b)的所述应用中,对于多个核酸甲基化片段中的一相应核酸甲基化片段:以残基为基础向所述深度循环自动编码器的第一轨道提供相应核酸甲基化片段的对应的核酸序列;以及向所述深度循环自动编码器的一第二轨道提供提供相应核酸甲基化片段的对应的甲基化图谱。160.如权利要求135所述的方法,其特征在于:所述经训练的自动编码器更包括:一编码器,其对多个核酸甲基化片段中的对应的核酸甲基化片段的对应的甲基化图谱和对应的核酸序列进行编码,从而形成多个潜在特征;以及一解码器,其将所述多个潜在特征解码为对应的核酸甲基化片段的对应的甲基化图谱和对应的核酸序列的重建。161.如权利要求135所述的方法,其特征在于:相应核酸甲基化片段中多个cpg位点中相应cpg位点的甲基化状态为:当相应的cpg位点通过甲基化测序确定为甲基化时被甲基化;当相应的cpg位点通过甲基化测序确定为未甲基化时未被甲基化;以及当甲基化测序无法将相应cpg位点的甲基化状态称为甲基化或未甲基化时标记为“其他”。162.如权利要求135所述的方法,其特征在于:所述甲基化测序是i)全基因组甲基化测序或ii)使用多个核酸探针的靶向dna甲基化测序。163.如权利要求135所述的方法,其特征在于:甲基化测序检测相应核酸甲基化片段中的一个或多个5-甲基胞嘧啶(5mc)及/或5-羟甲基胞嘧啶(5hmc)。164.如权利要求135所述的方法,其特征在于:核酸的甲基化测序包括将相应核酸甲基化片段中的一种或多种未甲基化胞嘧啶或一种或多种甲基化胞嘧啶转化为对应的一种或多种尿嘧啶。165.如权利要求164所述的方法,其特征在于:一种或多种尿嘧啶在甲基化测序期间被检测为一种或多种对应的胸腺嘧啶。166.如权利要求164所述的方法,其特征在于:一种或多种未甲基化胞嘧啶或一种或多种甲基化胞嘧啶的转化包括化学转化、酶促转化或其组合。167.如权利要求135至166中任一项所述的方法,其特征在于:所述癌症状态是不具有癌症。168.如权利要求135至166中任一项所述的方法,其特征在于:所述癌症状态是肾上腺癌、胆道癌、膀胱癌、骨髓癌、脑癌、乳腺癌、宫颈癌、结直肠癌、食道癌、胃癌、头颈癌、肝胆癌、肾癌、肝癌、肺癌、卵巢癌、胰腺癌、骨盆癌、胸膜癌、前列腺癌、肾恶性肿瘤、皮肤癌、胃癌、睾丸癌、胸腺癌、甲状腺癌、子宫癌、淋巴瘤、黑色素瘤、多发性骨髓瘤、白血病或其组合。169.如权利要求135至166中任一项所述的方法,其特征在于:所述癌症状态是一特定癌症的一个阶段。170.如权利要求169所述的方法,其特征在于:所述特定癌症是肾上腺癌、胆道癌、膀胱癌、骨/骨髓癌、脑癌、乳腺癌、宫颈癌、结肠直肠癌、食道癌、胃癌、头颈癌、肝胆癌、肾癌、肝癌、肺癌、卵巢癌、胰腺癌、骨盆癌、胸膜癌、前列腺癌、肾恶性肿瘤、皮肤癌、胃癌、睾丸癌、胸
腺癌、甲状腺癌、子宫癌、淋巴瘤、黑色素瘤、多发性骨髓瘤、白血病或其组合。171.如权利要求135至170任一项所述的方法,其特征在于:从各个受试者获得的生物样本中核酸的甲基化测序是生物样本中无细胞核酸的甲基化测序。172.如权利要求135至170任一项所述的方法,其特征在于:所述生物样本是血液样本。173.如权利要求135至170任一项所述的方法,其特征在于:所述生物样本包括各个训练受试者的血液、全血、血浆、血清、尿液、脑脊液、粪便、唾液、汗液、泪液、胸膜液、心包液或腹膜液。174.如权利要求135所述的方法,其特征在于:相应核酸甲基化片段的对应分数计算如下:a(f)=loss(f,f
′
);其中,f是相应核酸甲基化片段的对应的甲基化图谱;f’是在将对应的甲基化图谱和相应核酸甲基化片段的对应的核酸序列输入到自动编码器后,自动编码器对相应核酸甲酯化片段的对应的甲基化图谱的重建;以及loss是f和f'之间的损失。175.如权利要求174所述的方法,其特征在于:所述loss是f和f'之间的一重建误差、f和f'之间的一汉明距离、f和f'之间的一交叉熵损失、f和f'之间的均方误差或f和f'之间的平均绝对误差。176.如权利要求135所述的方法,其特征在于:相应核酸甲基化片段的对应分数计算如下:a(f)=w1*loss(f,f
′
) w2*距离[e(f),e(f_nc)];其中,w1是第一权重;f是相应核酸甲基化片段的对应的甲基化图谱;f’是在将对应的甲基化图谱和相应核酸甲基化片段的对应的核酸序列输入到自动编码器后,自动编码器对相应核酸甲酯化片段的对应的甲基化图谱的重建;以及w2是第二权重;loss是f和f'之间的损失;e(f)是在将相应核酸甲基化片段的对应的甲基化图谱输入自动编码器时由自动编码器产生的编码;f_nc是核酸甲基化片段的甲基化图谱和核酸序列,其定位于与相应核酸甲基化片段相同的基因组位置并且具有与相应核酸甲基化片段相同的序列;e(f_nc)是自动编码器在将f_nc输入到自动编码器时产生的编码;以及距离是e(f)和e(f_nc)之间的距离度量或相似性度量。177.如权利要求176所述的方法,其特征在于:所述距离是余弦距离、欧几里得距离、曼哈顿距离、雅卡距离、相关距离、卡方距离或马氏距离。178.如权利要求176所述的方法,其特征在于:w1和w2的数值均为1。179.如权利要求176所述的方法,其特征在于:w1和w2各有不同的数值。180.如权利要求135所述的方法,其特征在于:所述测试数据集包括:
通过对从所述测试受试者获得的生物样本中的核酸进行甲基化测序确定的多个核酸甲基化片段中的第一核酸甲基化片段的第一对应核酸序列。181.如权利要求181所述的方法,其特征在于:所述第一对应核酸序列来自所述第一核酸甲基化片段的正向链或反向链。182.如权利要求181所述的方法,其特征在于:所述第一对应核酸序列是所述第一核酸甲基化片段的反向链并且是反向互补形式,或被标记为所述第一核酸甲基化片段的反向链。183.一种用于检测一癌症状态的计算器系统,其特征在于:所述计算器系统包括:至少一个处理器;以及一存储器,存储用于由所述至少一处理器执行的至少一个程序,所述至少一个程序包括用于以下操作的指令:a)获得电子形式的一测试数据集,其中:对于一测试受试者,所述测试数据集包括通过从所述测试受试者获得的一生物样本中的核酸进行一甲基化测序所确定的多个核酸甲基化片段中每个相应核酸甲基化片段的一对应的甲基化图谱和一对应的核酸序列;以及所述对应的甲基化图谱包括相应核酸甲基化片段中对应的多个cpg位点中每个相应cpg位点的一甲基化状态;以及b)将多个核酸甲基化片段的全部或部分中的每个相应核酸甲基化片段的对应的甲基化图谱和对应的核酸序列应用到所述经训练的自动编码器,以确定所述测试受试者是否患有所述癌症状态,其中,步骤b)中,对于所述多个核酸甲基化片段的全部或部分中的每个相应核酸甲基化片段,在将相应测试核酸甲基化片段的对应的甲基化图谱和对应的核酸序列输入到所述经训练的自动编码器中时,通过所述经训练的自动编码器重建相应核酸甲基化片段的对应的甲基化图谱来计算至少部分确定的一对应分数,其中所述经训练的自动编码器包括1000个或更多权重。184.一种非暂时性计算机可读存储介质,其上存储有多个程序代码指令,当由一处理器执行时,所述程序代码指令使处理器执行一检测癌症状态的方法,其特征在于:所述方法包括:a)获得电子形式的一测试数据集,其中:对于一测试受试者,所述测试数据集包括通过从所述测试受试者获得的一生物样本中的核酸进行一甲基化测序所确定的多个核酸甲基化片段中每个相应核酸甲基化片段的一对应的甲基化图谱和一对应的核酸序列;以及所述对应的甲基化图谱包括相应核酸甲基化片段中对应的多个cpg位点中每个相应cpg位点的一甲基化状态;以及b)将多个核酸甲基化片段的全部或部分中的每个相应核酸甲基化片段的对应的甲基化图谱和对应的核酸序列应用到所述经训练的自动编码器,以确定所述测试受试者是否患有所述癌症状态,其中,步骤b)中,对于所述多个核酸甲基化片段的全部或部分中的每个相应核酸甲基化片段,在将相应测试核酸甲基化片段的对应的甲基化图谱和对应的核酸序列输入到所述经训练的自动编码器中时,通过所述经训练的自动编码器重建相应核酸甲基化片段的对应的甲基化图谱来计算至少部分确定的一对应分数,其中所述经训练的自动编码
器包括1000个或更多权重。
技术总结
本发明公开一种用于区分癌症状态的方法。获得具有第一癌症状态的多个受试者的第一数据集。每个受试者具有多个核酸甲基化片段,其甲基化图谱包括CpG位点甲基化状态。通过评估自动编码器的重建中的第一数据集中每个核酸甲基化片段的甲基化图谱和核酸序列的误差,来训练包括编码器和解码器的自动编码器。获得具有第二癌症状态的多个受试者的第二数据集。通过将第二数据集中每个核酸甲基化片段的甲基化图谱和核酸序列输入到经过训练的自动编码器中,并计算自动编码器的重建中由甲基化图谱确定的分数,可以识别多个特征。多个特征用于训练用于判别癌症状态的监督模型。训练用于判别癌症状态的监督模型。训练用于判别癌症状态的监督模型。
技术研发人员:弗吉尔
受保护的技术使用者:格里尔公司
技术研发日:2021.03.04
技术公布日:2023/2/13
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。