1.本发明属于自然语言处理与信息检索技术应用领域,具体涉及一种基于文本内容知识图谱的推荐方法。
背景技术:
2.随着大数据、人工智能等新一代信息技术在各个行业越来越多的应用,在信息检索领域中如何有效、准确的获取文本内容信息,并根据获取到的信息,在海量数据中进行相应的推荐工作,是信息检索领域的一个难点,也是这一领域的未来的发展趋势。
3.现今,在各个领域都存在信息爆炸的问题,电子商务、音乐推荐、广告服务等领域中引入推荐系统来解决信息爆炸的问题。目前,使用较多的推荐技术是基于协同过滤的推荐和基于内容的推荐。基于协同过滤的推荐由于新推荐对象没有历史交互信息,导致存在冷启动的问题;基于内容的推荐是通过内容信息进行相似度计算进行推荐,但在内容信息的获取上存在较大的困难。而上述领域针对推荐功能有较为完整的结构化数据库,在冷启动和内容信息获取上,有较为成功一套方法,有效、准确的获取推荐信息并根据大数据完成推荐目的。但在信息检索领域,尤其是在长文本的推荐问题上,由于文本较长、代词复杂以及信息冗余等问题导致内容信息难以有效获取,文本间的交互信息又很稀疏,因此,我们提出了一种基于知识图谱的推荐方法。
4.目前,在各个领域针对知识图谱的构建都有较为完善的技术支持,通过实体抽取、事件抽取、实体链接,指代消除以及知识图谱本体构建、存储等技术建立知识图谱,本发明针对长文本引入知识图谱技术,通过三元组以及检索实体的子图信息,解决推荐冷启动和推荐信息获取不准确等问题。特别的,运用知识图谱嵌入技术和表示向量融合的方式提高信息的完整性与准确性,最后通过点击预测的方式实现文本推荐方法。
技术实现要素:
5.(一)要解决的技术问题
6.本发明要解决的技术问题是如何提供一种基于文本内容知识图谱的推荐方法,以解决当前信息检索领域文本推荐上存在内容信息提取不完整、冷启动等问题导致的推荐结果不准确的问题。
7.(二)技术方案
8.为了解决上述技术问题,本发明提出一种基于文本内容知识图谱的推荐方法,该方法包括如下步骤:
9.步骤一,对文本内容进行信息加工形成三元组,构建对应文本的知识图谱;
10.步骤二,计算知识图谱向量,采用多向量融合的方式获取文本的知识表示向量;
11.步骤三,针对查询文本与候选文本的知识表示向量使用注意力机制对向量进行加权处理;
12.步骤四,通过神经网络模型计算查询文本与候选文本之间的点击概率,并基于点
击概率进行推荐。
13.(三)有益效果
14.本发明提出一种基于文本内容知识图谱的推荐方法,本发明将文本内容通过自然语言处理技术构建为文本对应的知识图谱,采用知识图谱嵌入技术表示文本内容信息,并融合多源向量,解决了现有技术方案中文本内容过长、且不能有效获取关键推荐信息的问题。
15.本发明针对长文本引入知识图谱技术,通过三元组以及检索实体的子图信息,解决推荐冷启动和推荐信息获取不准确等问题。特别的,运用知识图谱嵌入技术和表示向量融合的方式提高信息的完整性与准确性,最后通过点击预测的方式实现文本推荐方法。
附图说明
16.图1为本发明一种基于文本内容知识图谱的推荐方法的流程图;
17.图2是本发明基于卷积神经网络的多源向量融合技术的流程图。
具体实施方式
18.为使本发明的目的、内容和优点更加清楚,下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。
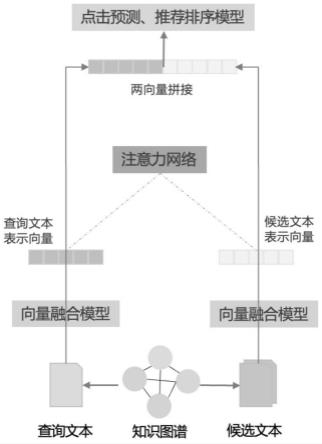
19.本发明提供了一种基于文本内容知识图谱的推荐方法,属于自然语言处理与信息检索领域相结合的应用技术,其中包括:步骤一,对文本内容进行信息加工形成三元组,构建对应文本的知识图谱;步骤二,计算知识图谱向量,采用多向量融合的方式获取文本的知识表示向量;步骤三,针对查询文本与候选文本的知识表示向量使用注意力机制对向量进行加权处理;步骤四,通过神经网络模型计算查询文本与候选文本之间的点击概率,并基于点击概率进行推荐。
20.本发明将文本内容通过自然语言处理技术构建为文本对应的知识图谱,采用知识图谱嵌入技术表示文本内容信息,并融合多源向量,解决了现有技术方案中文本内容过长、且不能有效获取关键推荐信息的问题。
21.本发明旨在解决当前信息检索领域文本推荐上存在内容信息提取不完整、冷启动等问题导致的推荐结果不准确,提出一种基于知识图谱嵌入技术和表示向量融合的文本推荐方法。
22.知识图谱嵌入(knowledge graph embedding,kge)技术是学习知识图谱中实体信息和关系信息的向量表示,在保留原有知识图谱的结构信息上,简化操作,减小针对下游任务信息获取的难度,在知识问答、文本信息增强、语义检索等领域都有运用;表示向量融合是针对上述知识图谱嵌入技术,通过卷积神经网络(convolutional neural networks,cnn)和注意力机制(attent ion mechanism)融合实体向量、实体字向量和实体子图向量等多源表示信息,统一多源表示向量维度,融合转化为知识表示向量,提高提取信息的完整性和完备性。通过知识嵌入技术与向量融合技术建立查询文本知识表示向量与候选文本知识表示向量,经深度神经网络(deep neural networks,dnn)模型计算点击概率并进行推荐排序。
23.本发明所述技术方案需要完成以下步骤:
24.步骤一,对文本内容进行信息加工形成三元组,构建对应文本的知识图谱;
25.步骤二,计算知识图谱向量,采用多向量融合的方式获取文本的知识表示向量;
26.步骤三,针对查询文本与候选文本的知识表示向量使用注意力机制对向量进行加权处理;
27.步骤四,通过神经网络模型计算查询文本与候选文本之间的点击概率,并基于点击概率进行推荐。
28.本发明在文本内容知识图谱的推荐方法的一个实施例中,需要对文本内容进行预处理,删除url、特殊字符等干扰信息,使用实体识别技术获取文本的实体信息,抽取实体间的关系和实体的属性值,生成文本三元组,通过指代消除、实体融合等技术进一步融合信息,形成文本知识图谱。
29.本发明在文本内容知识图谱的推荐方法的一个实施例中,根据文本知识图谱和文本预训练模型,获取实体表示向量、实体字表示向量和实体子图表示向量并将三向量转换为同一空间向量,采用卷积神经网络,使用多种不同尺寸的卷积核,来提取不同的特征,最后按列池化后得到文本的知识表示向量。
30.本发明在文本内容知识图谱的推荐方法的一个实施例中,基于文本知识图谱技术处理查询文本与候选文本,形成相对应的文本知识图谱,通过知识表示模型分别获取查询文本与候选文本的知识表示向量,针对不同文本对推荐结果有不同影响的问题,采用注意力机制对知识表示向量进行权重调整。
31.本发明在文本内容知识图谱的推荐方法的一个实施例中,将上述调整权重的查询文本与候选文本的知识表示向量进行连接,再使用神经网络模型进行点击概率计算,最后使用正则化函数对点击概率进行推荐排序。
32.实施例1:
33.s1:提取文档文本内容,统一文本格式,标注候选文档的推荐点击概率;
34.s2:清洗文本数据,将文本内容中url、特殊字符、表情等非法字符通过规则进行清洗;
35.s3:采用jieba分词工具对非结构化的文本数据进行分词处理,删除介词、语气词等不具有实际含义的字符;
36.s4:实体识别:针对文本内容进行实体抽取,通过自动化脚本对文本数据进行匹配标注,结合人工核查数据标注工作,利用双向循环神经网络模型完成实体识别;
37.s5:实体关系抽取:对文本数据通过依存句法分析实现关系抽取,结合关系模板进行匹配,得到实体、关系、属性的三元组集合;
38.s6:对实体识别和实体关系抽取结果,采用聚类法进行实体消歧,解决同名实体产生的歧义问题和同一实体关系问题,准确建立实体链接;
39.s7:使用图数据库导入生成的文本三元组数据,形成对应的文本知识图谱;
40.s8:使用公开的bert预训练语言模型,获取对应文本中实体的字向量,经均值计算后获取实体的字表示向量w;
41.s9:针对步骤s7的文本知识图谱,使用知识图谱嵌入技术与bert预训练语言模型得到每个实体的表示向量e;
42.s10:针对步骤s7的文本知识图谱,得到与对应文本中实体在一步之内的所有实体
所形成的子图
43.s11:基于步骤s8的实体的字表示向量w,步骤s9的实体表示向量e和步骤s10的子图使用知识图谱嵌入技术提取与某一实体直链接的实体表示向量,通过平均值获取实体子图表示向量
[0044][0045][0046]
s12:使用转换函数k,对步骤s9的实体表示向量e、步骤s11的取实体子图表示向量进行转换,映射到与步骤s8的字表示向量w同一空间:
[0047]e′
=k(e)
[0048][0049]
某个实施例中,针对一篇文本内容表示为:
[0050]e′
1:n
=[e
′1,e
′2,...,e
′n]
[0051][0052]
n表示一篇文本内容中的有效实体数;
[0053]
s13:最终转换完成后的向量输入为:
[0054][0055]
其中,r表示实数空间,d是字表示向量w的长度,这里采用的是预训练模型的输出长度;
[0056]
s14:使用不同尺寸的卷积核,将步骤s13的向量输入w通过卷积神经网络模型进行卷积,采用卷积池化的方式输出多向量融合的知识表示向量w
′
;
[0057]
s15:基于上述步骤s1-s14,获取查询文本的知识表示向量c和候选文本的知识表示向量h;
[0058]
s16:使用注意力机制将查询文本知识表示向量c和候选文本知识表示向量h进行加权计算,分别获得加权后的查询文本知识表示向量c
′
和候选文本知识表示向量h
′
;
[0059]
s17:将步骤s16的查询文本知识表示向量c
′
和候选文本知识表示向量h
′
,通过向量拼接,得到推荐向量:
[0060]
t=[c
′
,h
′
]
[0061]
s18:将步骤s17的推荐向量t作为输入,经深度神经网络模型g,对给定的查询文本知识表示向量c
′
,用户点击候选文本知识表示向量h
′
的概率进行回归预测,其点击率预测p
c,h
:
[0062]
p
c,h
=g(t)=g([c
′
,h
′
])
[0063]
s19:基于上述步骤s15-s18,针对查询文本i,获取一系列候选文本m的点击概率:
[0064]
pi=[p
i,1
,p
i,2
,
…
,p
i,m
]
[0065]
s20:通过对pi进行排序计算,最终获得候选文本针对查询文本的推荐序列。
[0066]
本发明创新点在于将知识图谱技术引入信息检索领域,借助知识图谱嵌入技术提取多源信息表示向量,通过卷积神经网络模型对多源信息表示向量进行统一、融合,并且使用深度神经网络对查询文本和候选文本的知识表示向量进行点击概率,达到推荐的目的。
[0067]
实施例2:
[0068]
一种基于文本内容知识图谱的推荐方法,属于自然语言处理与信息检索领域相结合的应用技术,其中包括:
[0069]
步骤一,对文本内容进行信息加工形成三元组,构建对应文本的知识图谱;
[0070]
步骤二,计算知识图谱向量,采用多向量融合的方式获取文本的知识表示向量;
[0071]
步骤三,针对查询文本与候选文本的知识表示向量使用注意力机制对向量进行加权处理;
[0072]
步骤四,通过神经网络模型计算查询文本与候选文本之间的点击概率,并基于点击概率进行推荐。
[0073]
进一步地,需要对文本内容进行预处理,删除url、特殊字符等干扰信息,使用实体识别技术获取文本的实体信息,抽取实体间的关系和实体的属性值,生成文本三元组,通过指代消除、实体融合等技术进一步融合信息,形成文本知识图谱。
[0074]
进一步地,根据文本知识图谱和文本预训练模型,获取实体表示向量、实体字表示向量和实体子图表示向量并将三向量转换为同一空间向量,采用卷积神经网络,使用多种不同尺寸的卷积核,来提取不同的特征,最后按列池化后得到文本的知识表示向量。
[0075]
进一步地,基于文本知识图谱技术处理查询文本与候选文本,形成相对应的文本知识图谱,通过知识表示模型分别获取查询文本与候选文本的知识表示向量,对于不同的文本内容对推荐结果有不同的影响,采用注意力机制对知识表示向量进行权重调整。
[0076]
进一步地,将上述调整权重的查询文本与候选文本的知识表示向量进行连接,再使用神经网络模型计算点击概率,最后使用正则化函数对点击概率进行推荐排序。
[0077]
本发明将文本内容通过自然语言处理技术构建为文本对应的知识图谱,采用知识图谱嵌入技术表示文本内容信息,并融合多源向量,解决了现有技术方案中文本内容过长、且不能有效获取关键推荐信息的问题。
[0078]
本发明针对长文本引入知识图谱技术,通过三元组以及检索实体的子图信息,解决推荐冷启动和推荐信息获取不准确等问题。特别的,运用知识图谱嵌入技术和表示向量融合的方式提高信息的完整性与准确性,最后通过点击预测的方式实现文本推荐方法。
[0079]
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。