1.本技术涉及计算机技术领域,具体涉及一种硬件内存序架构下的代码处理方法及相应装置。
背景技术:
2.处理器在调用线程操作内存时,在一些内存序架构下,实际执行的代码顺序与代码编写顺序一致,不会出现对内存的访问顺序进行重排的情况。而在一些内存序架构下,如一些弱内存序架构(如:高级精简指令集机器架构(advanced risc machine,arm)、基于精简指令集的第五代指令架构(reduced instruction set computing five,risc-v)、基于精简指令集的性能优化增强架构(performance optimization with enhanced risc,power))下,处理器通常会根据执行的情况对内存的访问顺序进行重排,重排可能会导致处理器实际执行的代码顺序与代码的编写顺序不一致,出现非预期行为。
3.在代码迁移的场景中,将在一种内存序架构下正常运行的代码迁移到另外一种内存序架构下,由于处理器对内存的访问重排,导致迁移后的代码在新的内存序架构下运行大概率会出现问题,产生非预期行为,尤其是与并发控制相关的代码,在代码迁移后,出错的概率会更大。
技术实现要素:
4.本技术提供一种硬件内存序架构下的代码处理方法,用于减少代码在硬件内存序架构下运行的非预期行为。本技术实施例还提供了相应设备、计算机可读存储介质及计算机程序产品等。
5.本技术第一方面提供一种硬件内存序架构下的代码处理方法,应用于计算机系统,包括:获取编译流程中的第一文件,第一文件与源文件关联;将第一文件的目标代码中的volatile内存访问代码转换为atomic内存访问代码,以得到第二文件,目标代码为与并发控制相关的内存访问代码;对第二文件进行编译处理,以得到适用于目标架构的执行文件,目标架构为强内存序架构或弱内存序架构。
6.本技术中,该代码处理方法应用于计算机设备,该计算机设备可以是服务器、终端设备或虚拟机(virtual machine,vm)。
7.本技术中,硬件内存序架构通常包括强内存序架构和弱内存序架构,弱内存序架构是相对于强内存序架构来说的,弱内存序架构和强内存序架构都是指令集架构,强内存序架构可以包括x86架构,弱内存序架构可以包括高级精简指令集机器架构(advanced risc machine,arm)架构、基于精简指令集的第五代指令架构(reduced instruction set computing five,risc-v)或基于精简指令集的性能优化增强架构(performance optimization with enhanced risc,power)。
8.本技术所提供的代码处理方法可以适用于代码迁移的场景,代码迁移的场景包括两种,一种是源文件从源架构迁移到目标架构后,由目标架构执行本技术的代码处理过程
得到适用于目标架构的执行文件;另一种是由源架构对源文件执行本技术的代码处理过程得到适用于目标架构的执行文件,然后将执行文件发送给目标架构。
9.本技术所提供的代码处理方法还可以使用于代码修复的场景,即源文件包括的源代码可能存在错误,由运行该源文件的架构执行本技术的代码处理过程进行修复的场景。
10.本技术中,源架构可以为强内存序架构或弱内存序架构,目标架构可以为强内存序架构或弱内存序架构。如:源架构为强内存序架构(x86),目标架构为弱内存序架构(arm);或者,源架构为弱内存序架构(arm),目标架构为强内存序架构(x86);或者,源架构为强内存序架构(x86),目标架构为强内存序架构(可扩充处理器架构第九版(scalable processor architecture version9,sparc v9));或者,源架构为弱内存序架构(arm),目标架构为弱内存序架构(risc-v)。
11.本技术中,该代码处理的方法可以在编译流程中执行,由处理器运行编译器的代码来完成相应的代码处理过程。
12.本技术中,第一文件可以是源文件,也可以是编译流程中的中间表示(intermediate representation,ir)。
13.本技术中,中间表示指编译器对于源程序进行扫描后生成的内部表示,代表源程序的语义结构,编译器中端的各个阶段都在ir上进行分析或优化变换,因而ir对编译器的整体结构、效率和健壮性都有着极大的影响。
14.本技术中,源文件可以为c/c 源文件。
15.本技术中,与并发控制相关的内存访问代码可以理解为是除驱动(driver)之外的代码。
16.本技术中,volatile是c/c 中的一种关键字,该关键字的作用是阻止编译器优化,在处理器运行代码时,volatile memory access的顺序不改变,但其他的memory access的顺序可能改变,无法使代码执行顺序与代码编写顺序保持一致。
17.本技术中,atomic是c/c 版本(c11/c 11)中atomic关键字,声明变量时加上atomic关键字,可以实现对整型(int)、字符型(char)、布尔型(bool)等数据结构的原子性封装。访问被声明为atomic的变量只能通过原子操作进行。在不加内存访问顺序限定关系(如:获得acquire,释放release)的默认情况下,atomic memory access表示顺序一致性的原子性内存访问。
18.由上述第一方面可知,在编译流程中可以将并发控制相关的内存访问代码中的volatile内存访问代码转换为atomic内存访问代码,因为atomic内存访问可以使处理器执行程序时的执行代码与编写代码保持一致,从而减少了代码运行时出现挂死或死锁等非预期行为。
19.在第一方面的一种可能的实现方式中,该方法还包括:删除目标代码中单独的内存屏障,单独的内存屏障为目标代码中单独的一条内嵌汇编指令,且单独的一条内嵌汇编指令是内存屏障指令。
20.该种可能的实现方式中,删除单独的内存屏障,可以进一步提升代码性能。
21.在第一方面的一种可能的实现方式中,第一文件为包含源代码的源文件,源文件包括适用于源架构的内嵌汇编代码,该方法还包括:将适用于源架构的内嵌汇编代码转换为能运行于所述目标架构的内嵌汇编代码或编译器内建函数,所述源架构和所述目标架构
为两个不同的硬件内存序架构。
22.该种可能的实现方式中,编译器内建函数(compiler builtins)是可以适用于多种硬件架构的函数。在代码迁移场景中,适用于源架构的内嵌汇编代码通常不适用于目标架构,通过将适用于源架构的内嵌汇编代码自动转换为能运行于目标架构的内嵌汇编代码或编译器内建函数,可以提高代码转换效率,从而提高代码处理速度。
23.在第一方面的一种可能的实现方式中,第一文件为第一中间表示,第二文件为第二中间表示,上述步骤:获取编译流程中的第一文件,包括:获取与源架构对应的源文件,源文件中包括适用于源架构的内嵌汇编代码;将适用于源架构的内嵌汇编代码转换为能运行于目标架构的内嵌汇编代码或编译器内建函数,以得到中间文件,源架构和目标架构为两个不同的硬件内存序架构;将中间文件转换为第一中间表示。
24.该种可能的实现方式中,编译器内建函数(compiler builtins)是可以适用于多种硬件架构的函数。在代码迁移场景中,适用于源架构的内嵌汇编代码通常不适用于目标架构,通过将适用于源架构的内嵌汇编代码自动转换为能运行于目标架构的内嵌汇编代码或编译器内建函数,可以提高代码转换效率,从而提高代码处理速度。
25.在第一方面的一种可能的实现方式中,上述步骤:将适用于源架构的内嵌汇编代码转换为能运行于目标架构的内嵌汇编代码或编译器内建函数,以得到中间文件,包括:将适用于源架构的内嵌汇编代码转换为抽象语法树(abstract syntax tree,ast);按照抽象语法树中每个分支的语义,将每个分支转换为适用于目标架构的内嵌汇编代码或编译器内建函数,以得到中间文件。
26.该种可能的实现方式中,ast是源代码语法结构的一种抽象表示。它以树状形式表现编程语言的语法结构,树上每个节点都表示源代码中的一种结构。源程序和抽象语法树一一对应。通过ast进行语义等价翻译,可以实现内嵌汇编代码的快速转换。
27.在第一方面的一种可能的实现方式中,所述源文件中的代码规模无限制,可以有很多行,如超过一万行,也可以有几十行,几百行。
28.本技术第二方面提供一种硬件内存序架构下的代码处理装置,该硬件内存序架构下的代码处理装置具有实现上述第一方面或第一方面任意一种可能实现方式的方法的功能。该功能可以通过硬件实现,也可以通过硬件执行相应的软件实现。该硬件或软件包括一个或多个与上述功能相对应的模块,例如:获取单元、第一处理单元和第二处理单元,这三个单元可以通过一个处理单元或多个处理单元来实现。
29.本技术第三方面提供一种计算机设备,该计算机设备包括至少一个处理器、存储器、输入/输出(input/output,i/o)接口以及存储在存储器中并可在处理器上运行的计算机执行指令,当计算机执行指令被处理器执行时,处理器执行如上述第一方面或第一方面任意一种可能的实现方式的方法。
30.本技术第四方面提供一种存储一个或多个计算机执行指令的计算机可读存储介质,当计算机执行指令被处理器执行时,一个或多个处理器执行如上述第一方面或第一方面任意一种可能的实现方式的方法。
31.本技术第五方面提供一种存储一个或多个计算机执行指令的计算机程序产品,当计算机执行指令被一个或多个处理器执行时,一个或多个处理器执行如上述第一方面或第一方面任意一种可能的实现方式的方法。
32.本技术第六方面提供了一种芯片系统,该芯片系统包括至少一个处理器,至少一个处理器用于支持资源管理的装置实现上述第一方面或第一方面任意一种可能的实现方式中所涉及的功能。在一种可能的设计中,芯片系统还可以包括存储器,存储器,用于保存资源管理的装置必要的程序指令和数据。该芯片系统,可以由芯片构成,也可以包含芯片和其他分立器件。
附图说明
33.图1是本技术实施例提供的计算机系统的一结构示意图;
34.图2是本技术实施例提供的代码迁移场景的一示意图;
35.图3是本技术实施例提供的代码顺序与执行顺序的一示例示意图;
36.图4是本技术实施例提供的代码顺序与执行顺序的另一示例示意图;
37.图5是本技术实施例提供的代码迁移场景的另一示意图;
38.图6是本技术实施例提供的代码修复场景的一示意图;
39.图7是本技术实施例提供编译器的一结构示意图;
40.图8是本技术实施例提供编译器的另一结构示意图;
41.图9是本技术实施例提供的硬件内存序架构下代码处理方法的一实施例示意图;
42.图10是本技术实施例提供的硬件内存序架构下代码处理方法的另一实施例示意图;
43.图11a是本技术实施例提供的一示例示意图;
44.图11b是本技术实施例提供的另一示例示意图;
45.图12a是本技术实施例提供的另一示例示意图;
46.图12b是本技术实施例提供的另一示例示意图;
47.图13是本技术实施例提供的硬件内存序架构下代码处理方法的另一实施例示意图;
48.图14a是本技术实施例提供的另一示例示意图;
49.图14b是本技术实施例提供的另一示例示意图;
50.图15是本技术实施例提供的一效果对比图;
51.图16是本技术实施例提供的硬件内存序架构下的代码处理装置的一结构示意图;
52.图17是本技术实施例提供的计算机设备的一结构示意图。
具体实施方式
53.下面结合附图,对本技术的实施例进行描述,显然,所描述的实施例仅仅是本技术一部分的实施例,而不是全部的实施例。本领域普通技术人员可知,随着技术发展和新场景的出现,本技术实施例提供的技术方案对于类似的技术问题,同样适用。
54.本技术的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的实施例能够以除了在这里图示或描述的内容以外的顺序实施。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或
单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
55.本技术实施例提供一种硬件内存序架构下的代码处理方法,用于减少代码在硬件内存序架构下运行的非预期行为。本技术实施例还提供了相应设备、计算机可读存储介质及计算机程序产品等。以下分别进行详细说明。
56.硬件内存序架构通常包括强内存序架构和弱内存序架构,弱内存序架构是相对于强内存序架构来说的,弱内存序架构和强内存序架构都是指令集架构,强内存序架构可以包括x86架构,弱内存序架构可以包括高级精简指令集机器架构(advanced risc machine,arm)架构、基于精简指令集的第五代指令架构(reduced instruction set computing five,risc-v)或基于精简指令集的性能优化增强架构(performance optimization with enhanced risc,power)。
57.计算机系统中的处理器在运行代码时,为了确保最大限度地将流水线充分利用,会根据执行的情况对内存的访问顺序进行重排。如下表1所示,在不同硬件内存序架构下,可以包括不同的重排类型。
58.表1弱内存序硬件平台指令执行重排序类型
59.[0060][0061]
从处理器的角度来看,无数据依赖的内存重排是没有任何问题的,而且适当的重排,对整体执行的效率会有极大的提升。但因为硬件内存序架构通常包括强内存序架构和弱内存序架构,强内存序架构的代码可能会迁移到弱内存序架构下运行,弱内存序架构下也可能会迁移到强内存序架构下运行,重排会导致原本在源架构下能正常运行的代码,迁移到目标架构下会出现挂死或死锁等非预期行为。另外,也有一些代码由于在编程时程序员没有正确处理内存序关系,导致在自身所在架构下代码运行时行为和程序员期望行为不一致。
[0062]
本技术实施例中,源架构可以为强内存序架构或弱内存序架构,目标架构可以为强内存序架构或弱内存序架构。
[0063]
为了解决由于内存存序造成的代码在从源架构迁移到目标架构下运行会产生非预期行为的问题,以及本架构可能存在错误代码造成运行产生非预期行为的问题,本技术实施例提供了一种硬件内存序架构下的代码处理方法,该方法应用于计算机系统,该计算系统可以为服务器、终端设备、虚拟机(virtual machine,vm)或容器(container)。
[0064]
服务器可以是任意形态的物理机。
[0065]
终端设备(也可以称为用户设备(user equipment,ue))是一种具有无线收发功能的设备,可以部署在陆地上,包括室内或室外、手持或车载;也可以部署在水面上(如轮船等);还可以部署在空中(例如飞机、气球和卫星上等)。终端设备可以个人电脑(personal computer,pc)、手机(mobile phone)、平板电脑(pad)、带无线收发功能的电脑、虚拟现实(virtual reality,vr)终端、增强现实(augmented reality,ar)终端、工业控制(industrial control)中的无线终端、无人驾驶(self driving)中的无线终端、远程医疗(remote medical)中的无线终端、智能电网(smart grid)中的无线终端、运输安全(transportation safety)中的无线终端、智慧城市(smart city)中的无线终端、智慧家庭(smart home)中的无线终端、以物联网(internet of things,iot)中的无线终端等。
[0066]
虚拟机可以位于云端,也可以位于本地。
[0067]
本技术实施例提供的计算机系统的架构可以参阅图1进行理解。
[0068]
图1是本技术实施例提供的计算机系统的一架构示意图。
[0069]
如图1所示,该计算机系统10的架构可以包括应用层101、内核层102和硬件层103。
[0070]
应用层101包括操作界面,程序检测的工作人员可以通过该操作界面启动源代码的处理过程。
[0071]
内核层102包括编译器,该编译器用于编译源文件,如:要从源架构迁移到目标架构的源文件,或者,已经从源架构迁移到计算机系统的源文件,或者,编译计算机系统上存在错误的源文件,本技术实施例中,该源文件为c/c 源文件。
[0072]
设备层103包括通信接口1031、处理器1032、内存1033和总线1034等。通信接口1031、处理器1032和内存1033通过总线1034连接。其中,处理器1032可以包括任何类型的通用计算电路或专用逻辑电路,例如:现场可编程门阵列(field-programmable gate array,fpga)或专用集成电路(application specific integrated circuit,asic)。也可以是耦合到一个或多个半导体基板的一个或多个处理器,例如中央处理器(central processing unit,cpu)。
[0073]
计算机系统运行时,可以通过处理器执行本技术实施例提供的用于处理代码的执行流程,通过处理器运行编译器执行本技术实施例中的相应步骤。
[0074]
由以上描述可知,本技术实施例提供的代码处理方法可以适用于代码迁移的场景,还可以使用于代码修复的场景。其中,代码迁移的场景包括两种,一种是源文件从源架构迁移到目标架构后,由目标架构执行本技术的代码处理过程得到适用于目标架构的执行文件;另一种是由源架构对源文件执行本技术的代码处理过程得到适用于目标架构的执行文件,然后将执行文件发送给目标架构。代码修复的场景即源文件包括的源代码可能存在错误,由运行该源文件的架构(本技术实施例中,将该架构称为目标架构,实际上,该架构可以是任意一个硬件内存序架构)执行代码处理过程进行修复的场景。下面分别进行介绍。
[0075]
一、源文件从源架构迁移到目标架构后,由目标架构执行本技术的代码处理过程得到适用于目标架构的执行文件的场景。
[0076]
如图2所示,源架构下可以正常运行的源文件迁移到目标架构,由安装有目标架构的计算机系统生成执行文件。
[0077]
若该源文件直接在目标架构下运行可以会因为重排导致处理器对内存实际执行的代码顺序与代码的编写顺序存在不一致。为了使源架构的代码在迁移到目标架构后,也可以保持和源架构上相同的运行行为。申请实施例会由目标架构对源文件中的内嵌汇编代码进行翻译,将该源文件中的内嵌汇编代码翻译成能适用于目标架构的内嵌汇编代码或编译器内建函数(compiler builtins),还会对编译器编译流程中的源文件或中间表示进行处理,如:将源文件或中间表示中的volatile内存访问(volatile memory access)代码转换为atomic内存访问(atomic memory access)代码,删除并发控制相关的内存访问代码中单独的内存屏障,单独的内存屏障为并发控制相关的内存访问代码中单独的一条内嵌汇编指令,且单独的一条内嵌汇编指令是内存屏障指令。
[0078]
上述内嵌汇编代码翻译的过程可以是人工完成,也可以是计算机系统自动完成。编译器内建函数可以适用于多种硬件内存序架构。
[0079]
volatile是c/c 中的一种关键字,该关键字的作用是阻止编译器优化,在编译器优化时,如图3所示,在处理器运行代码时,volatile memory access的顺序不改变,但其他的memory access的顺序可能改变,所以,通过volatile memory access是不能保证执行代码与编写代码的顺序保持一致的。
[0080]
atomic是c语言版本(c11)中atomic关键字,声明变量时加上atomic关键字,可以实现对整型(int)、字符型(char)、布尔型(bool)等数据结构的原子性封装。访问被声明为atomic的变量只能通过原子操作进行。atomic memory access可以保证顺序一致性。
[0081]
因为memory access包括读(load)和写(store)两种指令,所以顺序一致性的atomic memory access(sequential consistent(sc)atomic memory access)满足如下保序关系:
[0082]
1.对于sc atomic load,类似acquire load,即不允许该条指令后面的(编程顺序意义上的后面)访存指令在编译优化阶段或处理器执行阶段移动到该条指令之前。
[0083]
2.对于sc atomic store,类似release store,即不允许该条指令前面的(编程顺序意义上的前面)访存指令在编译优化阶段或处理器执行阶段移动到该条指令之后。
[0084]
3.对于sc atomic store后面有sc atomic load(编程顺序),并且中间没有其他sc atomic memory access指令,在编译优化阶段或处理器执行阶段禁止交换这两条指令的顺序。
[0085]
如图4所示,在处理器运行代码时,atomic memory access的顺序不改变,在满足上述三种保序关系的情况下还可以使得memory access的执行顺序也不改变,这样处理器运行代码时的执行顺序与代码编写顺序保持一致,保证了顺序一致性。
[0086]
二、由源架构对源文件执行本技术的代码处理过程得到适用于目标架构的执行文件,然后将执行文件发送给目标架构的场景。
[0087]
如图5所示,为了使源架构的代码在迁移到目标架构后,也可以保持和源架构上相同的运行行为。申请实施例会由源架构对源文件中的内嵌汇编代码进行翻译,将该源文件中的内嵌汇编代码翻译成能适用于目标架构的内嵌汇编代码或编译器内建函数,还会对编译器编译流程中的源文件或中间表示进行处理,如:将源文件或中间表示中的volatile内存访问(volatile memory access)代码转换为atomic内存访问(atomic memory access)代码,删除并发控制相关的内存访问代码中单独的内存屏障,单独的内存屏障为并发控制相关的内存访问代码中单独的一条内嵌汇编指令,且单独的一条内嵌汇编指令是内存屏障指令。该场景中由源架构执行代码处理的过程得到执行文件,然后将执行文件发送到目标架构,目标架构运行执行文件。
[0088]
该场景与上述由目标架构执行代码处理的场景只是执行主体不同,其他思想都可以参阅上述有目标架构执行代码处理的场景进行理解。
[0089]
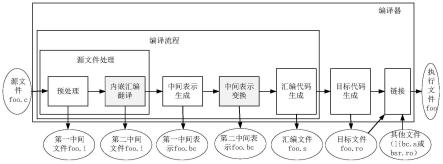
三、代码原本就在目标架构上,但该代码存在错误,需要进行修复的场景。
[0090]
如图6所示,目标架构下的源文件中的代码存在错误,该源文件称为待修复的源文件,为了使该待修复的源文件在运行时可以保持顺序一致性,本技术实施例会对编译器编译流程中的源文件或中间表示进行处理,如:将中间表示中的volatile内存访问代码转换为atomic内存访问代码。
[0091]
本技术实施例中,无论是代码迁移的场景还是代码修复的场景,都由计算机系统中的编译器来完成,结合上述两种场景,本技术实施例提供的编译器可以是:不做内嵌汇编代码自动转换的编译器,或者,做内嵌汇编代码自动转换的编译器。关于编译器是否做汇编代码自动转换也可以是在编译器中设置一个开关,通过该开关来确定该编译器是否执行内嵌汇编代码的自动转换,如:关闭该开关,则该编译器不做内嵌汇编代码自动转换,打开该
开关,则该编译器做内嵌汇编代码自动转换。
[0092]
下面结合编译器中各模块的功能来介绍本技术实施例中的代码处理过程。
[0093]
一、不做内嵌汇编代码自动转换的编译器。
[0094]
如图7所示,该编译器包括源文件处理模块、中间表示生成模块、中间表示变换模块和编译器后端模块。
[0095]
其中,源文件处理模块用于获取源文件,将源文件做宏展开处理,以得到第一中间文件,该源文件为c/c 源文件,该源文件可以是代码迁移场景中源架构的源文件,也可以是代码修复场景中待修复的源文件。
[0096]
该场景中,源文件中的内嵌汇编代码可以通过人工翻译得到的适用于目标架构的内嵌汇编代码或者编译器内建函数。
[0097]
在代码修复的场景中,因为源文件中的内嵌汇编代码或编译器内建函数已经适用于该目标架构,则不需要处理其中的内嵌汇编代码或编译器内建函数。
[0098]
中间表示生成模块用于将第一中间文件转换为第一中间表示(intermediate representation,ir)。
[0099]
ir指编译器对于源程序进行扫描后生成的内部表示,代表源程序的语义和语法结构,编译器的各个阶段都在ir上进行分析或优化变换,因而它对编译器的整体结构、效率和健壮性都有着极大的影响。
[0100]
中间表示变换模块用于将第一中间表示转换为第二中间表示。
[0101]
编译器后端模块用于将第二中间表示处理为适用于目标架构的执行文件。
[0102]
该场景中,可以由源文件处理模块将源文件中的volatile内存访问代码转换为atomic内存访问代码。也可以是由中间表示变换模块将第一中间表示中的volatile内存访问代码转换为atomic内存访问代码。
[0103]
二、做内嵌汇编代码自动转换的编译器。
[0104]
如图8,该编译器包括源文件处理模块、中间表示生成模块、中间表示变换模块和编译器后端模块。该源文件处理模块中包括内嵌汇编翻译模块。
[0105]
其中,源文件处理模块用于获取源文件,将源文件做宏展开处理,以得到第一中间文件,该源文件为c/c 源文件,该源文件中包括适用于源架构的内嵌汇编代码,该源文件可以是代码迁移场景中源架构的源文件,也可以是代码修复场景中待修复的源文件。
[0106]
内嵌汇编翻译模块用于将第一中间文件中的内嵌汇编代码翻译为适用于目标架构的内嵌汇编代码或者编译器内建函数,以得到第二中间文件。
[0107]
中间表示生成模块用于将第二中间文件转换为第一中间表示。
[0108]
中间表示变换模块用于将第一中间表示转换为第二中间表示。
[0109]
编译器后端模块用于将第二中间表示处理为适用于目标架构的执行文件。
[0110]
该场景中,可以由源文件处理模块将源文件中的volatile内存访问代码转换为atomic内存访问代码。也可以是由中间表示变换模块将第一中间表示中的volatile内存访问代码转换为atomic内存访问代码。
[0111]
基于上述计算机系统,如图9所示,本技术实施例提供的硬件内存序架构下的代码处理方法的一实施例包括:
[0112]
201.获取编译流程中的第一文件,第一文件与源文件关联。
[0113]
本技术中,第一文件可以是源文件,也可以是编译流程中的中间表示(intermediate representation,ir)。
[0114]
202.将第一文件的目标代码中的volatile内存访问代码转换为atomic内存访问代码,以得到第二文件,目标代码为与并发控制相关的内存访问代码。
[0115]
与并发控制相关的内存访问代码可以理解为是除驱动(driver)之外的代码。
[0116]
203.对第二文件进行编译处理,以得到适用于目标架构的执行文件,目标架构为强内存序架构或弱内存序架构。
[0117]
对第二文件进行编译处理的过程可以包括根据atomic插入内存屏障(fence),二进制代码生成,以及二进制代码链接等流程。
[0118]
本技术实施例中,在编译流程中可以将并发控制相关的内存访问代码中的volatile内存访问代码转换为atomic内存访问代码,因为atomic内存访问可以使处理器执行程序时的执行代码与编写代码保持一致,从而减少了代码运行时出现挂死或死锁等非预期行为。
[0119]
可选地,在上述步骤202之前或之后,还可以删除目标代码中单独的内存屏障,单独的内存屏障为目标代码中单独的一条内嵌汇编指令,且单独的一条内嵌汇编指令是内存屏障指令。这样有利于进一步优化代码。
[0120]
以上介绍了代码迁移场景和代码修复场景都会涉及到的内容,不同的是,在代码迁移场景会涉及到内嵌汇编代码的转换,代码修复场景不需要做内嵌汇编代码的转换。另外,本技术实施例中,可以在中间表示中做从volatile内存访问代码转换为atomic内存访问代码的转换,也可以在源文件中做从volatile内存访问代码转换为atomic内存访问代码的转换。下面分别进行介绍。
[0121]
一、在中间表示中做从volatile内存访问代码转换为atomic内存访问代码的转换。
[0122]
如图10所示,在代码迁移场景中,该代码处理的过程可以包括:源文件处理过程、中间表示生成过程、中间表示变换过程、汇编代码生成过程、目标代码生成过程和链接过程。
[0123]
在源文件处理过程中编译器从源架构获取源文件,该源文件在该场景示例中为foo.c格式的源文件。该源文件中包括内嵌汇编代码。
[0124]
该源文件处理过程包括预处理过程和内嵌汇编翻译过程。其中,源文件处理过程会将源文件做宏展开处理,得到第一中间文件,该第一中间文件的格式为foo.i格式。
[0125]
内嵌汇编翻译过程会对第一中间文件中的内嵌汇编代码进行翻译。该翻译过程可以包括:将适用于源架构的内嵌汇编代码转换为能运行于目标架构的内嵌汇编代码或编译器内建函数,以得到第二中间文件,该第二中间文件的格式为foo.i格式。具体的翻译过程可以是:将适用于源架构的内嵌汇编代码转换为抽象语法树(abstract syntax tree,ast);按照抽象语法树中每个分支的语义,将每个分支转换为适用于目标架构的内嵌汇编代码或编译器内建函数,以得到第二中间文件。其中,每个分支可以理解为是输入分支和输出分支等。
[0126]
ast是源代码语法结构的一种抽象表示。它以树状形式表现编程语言的语法结构,树上每个节点都表示源代码中的一种结构。源程序和抽象语法树一一对应。
[0127]
该内嵌汇编代码的翻译过程还可以参阅图11a和图11b进行理解。如图11a所示的是适用于源架构(x86)的内嵌汇编代码的示例,该示例中,内嵌汇编代码30包括如下内容:
[0128]
asm volatile(
[0129]
mplocked
[0130]“cmpxchgq%[src],%[dst];”[0131]“sete%(res);”[0132]
:[res]“=a”(res),/*output*/
[0133]
[dst]“=m”(*dst)
[0134]
:[src]“=r”(src),/*input*/
[0135]“a”(exp),
[0136]“m”(*dst)
[0137]
:“memory”);/*no-clobber list*/
[0138]
通过对图11a所示的ast进行静态扫描,可以识别出内嵌汇编的特定代码模式:mplocked;cmpxchgq;sete。该特定代码模式对应于compiler builtins:__atomic_compare_exchange。通过分析ast上内嵌汇编代码的输入参数(:[src]“=r”(src))和输出参数(:[res]“=a”(res),[dst]“=m”(*dst)),得到编译器内建函数的输入(&src,0)和输出(dst,&exp),按照两种架构的语义关系,上述图11a所示的示例可以转换为如图11b所示的示例。图11a中的内嵌汇编代码30会转换为图11b中的编译器内建函数40,即如下的代码内容:
[0139]
res=__atomic_compare_exchange(dst,&exp,&src,0,_atomic_seq_cst,_atomic_seq_cst)。
[0140]
完成上述预处理过程,得到第二中间文件,会通过中间表示生成(llvm ir generation)过程将第二中间文件转换为第一中间表示。第一中间表示的格式可以是foo.bc格式。
[0141]
进一步的,可以通过中间表示变换过程将第一中间表示转换为第二中间表示,第二表示的格式可以是foo.bc格式。
[0142]
从第一中间表示到第二中间表示的转换过程可以包括:将第一中间表示的目标代码中的volatile内存访问代码转换为atomic内存访问代码,以及删除目标代码中单独的内存屏障。该过程可以参阅图12a和图12b进行理解。
[0143]
图12a所示的是以llvm ir为例的一个第一中间表示的一个示例。
[0144]
本技术实施例中,第一中间表示中包含了两处与volatile相关的代码,分别出现在图12a的50a所标记的部分,具体的代码内容如下:
[0145]
store volatile 132 0,132*l,align 4,!tbaa!2
[0146]
tail call void asm sideeffect“mfence”,
“‑
[memory],-[dirflag],-[fpsr],-[flags]”()#2
[0147]
其中,“mfence”,
“‑
[memory],-[dirflag],-[fpsr],-[flags]”()#2为单独的内存屏障,在图12a中用50b标记。
[0148]
本技术实施例中,在中间表示变换过程中,会将与volatile相关的代码转换为atomic相关的代码,并删除其中单独的内存屏障,从而得到如图12b中60所标记的代码:
store atomic 132 0,132*l,align 4,!tbaa!2。
[0149]
通过中间表示变换过程得到第二中间表示后,可以通过汇编代码生成过程,将第二中间表示转换为汇编文件,该汇编文件的格式可以为foo.s,该过程中,可以在识别代码的过程中,每遇到一个atomic就插入一个fence,这样,就不会因为插入过多的fence而影响性能。
[0150]
进一步的,还可以将汇编文件转换为目标文件foo.ro,然后再执行链接过程,将该目标文件foo.ro与其他文件,如libc.a格式的文件或/和bar.ro格式的文件链接起来,得到目标架构的执行文件。
[0151]
以上汇编文件、目标文件和执行文件都是适用于目标架构的不同格式的文件。
[0152]
二、在源文件中做从volatile内存访问代码转换为atomic内存访问代码的转换。
[0153]
如图13所示,在代码迁移场景中,该代码处理的过程可以包括:源文件处理过程、中间表示生成过程、汇编代码生成过程、目标代码生成过程和链接过程。
[0154]
在源文件处理过程中编译器从源架构获取源文件,该源文件在该场景示例中为foo.c格式的源文件。该源文件中包括内嵌汇编代码。
[0155]
该源文件处理过程包括预处理过程、内嵌汇编翻译过程和代码变换过程。其中,源文件处理过程会将源文件做宏展开处理,得到第一中间文件,该第一中间文件的格式为foo.i格式。内嵌汇编翻译过程可以参阅图10、图11a和图11b所对应的内嵌汇编翻译过程进行理解。代码变换过程包括将第二中间文件中的volatile内存访问代码转换为atomic内存访问代码,以及删除目标代码中单独的内存屏障,得到第三中间文件。该过程可以参阅前述的图12a和图12b进行理解。
[0156]
中间表示生成过程可以将第三中间文件转换为中间表示。
[0157]
其他的汇编代码生成过程、目标代码生成过程和链接过程都可以参阅图10部分的相应内容进行理解,此处不做过多赘述。
[0158]
以上描述了代码迁移场景中编译器对代码的处理过程,在代码修复场景,只需要在上述代码迁移场景中,去掉内嵌汇编翻译过程。
[0159]
本技术的工程人员在确定本技术方案的过程中,做过多次测试,下面以将x86架构上的ringbuffer编译为aarch64的场景为例进行说明。
[0160]
如图14a所示,直接将数据面编程工具包(data plane development kit,dpdk)中x86架构上的ringbuffer编译为aarch64的二进制的执行结果显示,出现了多行代码运行失败(failed)。
[0161]
如图14b所示,应用本技术实施例所提供的方案,将dpdk中x86架构上的ringbuffer编译为aarch64的二进制的执行结果显示,运行成功(successful)。
[0162]
本技术实施例提供的方案,可以自动翻译内嵌汇编代码,以及在中间表示的优化环节,通过将volatile memory access修改为atomic memory access来保证代码的顺序一致性,该方案可以适用于任何行数代码的程序,其效果在代码行数越多时表现的越明显,如果代码行数超过一万行,相对于现有技术,可以明显提高代码的处理效率。
[0163]
另外,本技术实施例中,还通过图15示意了将dpdk中x86架构上的ringbuffer,通过人工专家修改的代码的运行结果70a,以及应用本技术的方案迁移dpdk ring buffer到aarch64后的运行结果70b。图15中,横坐标是写者个数,纵坐标是吞吐率,读者个数是16个,
本技术中,写者和读者都为线程。通过曲线70a和曲线70b的对比可以看出,采用本技术的方案迁移后的代码在吞吐率上更具有优势。
[0164]
以上描述了在硬件内存序架构下的代码处理方法,下面结合附图介绍本技术实施例提供的一种硬件内存序架构下的代码处理装置80。
[0165]
如图16所示,本技术实施例提供的硬件内存序架构下的代码处理装置80的一实施例包括:
[0166]
获取单元801,用于获取编译流程中的第一文件,第一文件与源文件关联。该获取单元801可以执行上述方法实施例中的步骤201。
[0167]
第一处理单元802,用于将获取单元801获取的第一文件的目标代码中的volatile内存访问代码转换为原子性的atomic内存访问代码,以得到第二文件,目标代码为与并发控制相关的内存访问代码。该第一处理单元802可以执行上述方法实施例中的步骤202。
[0168]
第二处理单元803,用于对第一处理单元802处理得到的第二文件进行编译处理,以得到适用于目标架构的执行文件,目标架构为强内存序架构或弱内存序架构。该第二处理单元803可以执行上述方法实施例中的步骤203。
[0169]
本技术实施例中,在编译流程中可以将并发控制相关的内存访问代码中的volatile内存访问代码转换为atomic内存访问代码,因为atomic内存访问可以使处理器执行程序时的执行代码与编写代码保持一致,从而减少了代码运行时出现挂死或死锁等非预期行为。
[0170]
可选地,第一处理单元802,还用于删除目标代码中单独的内存屏障,单独的内存屏障为目标代码中单独的一条内嵌汇编指令,且单独的一条内嵌汇编指令是内存屏障指令。
[0171]
可选地,第一文件为包含源代码的源文件,源文件包括适用于源架构的内嵌汇编代码,第一处理单元802,还用于将适用于源架构的内嵌汇编代码转换为能运行于目标架构的内嵌汇编代码或编译器内建函数,源架构和目标架构为两个不同的硬件内存序架构。
[0172]
可选地,第一文件为第一中间表示,第二文件为第二中间表示,获取单元801用于:获取与源架构对应的源文件,源文件中包括适用于源架构的内嵌汇编代码;将适用于源架构的内嵌汇编代码转换为能运行于目标架构的内嵌汇编代码或编译器内建函数,以得到中间文件,源架构和目标架构为两个不同的硬件内存序架构;将中间文件转换为第一中间表示。
[0173]
可选地,获取单元801用于:将适用于源架构的内嵌汇编代码转换为抽象语法树;按照抽象语法树中每个分支的语义,将每个分支转换为适用于目标架构的内嵌汇编代码或编译器内建函数,以得到中间文件。
[0174]
本技术实施例中,获取单元801可以对应上述图7和图8中的源文件处理模块,以及中间表示生成模块,第一处理单元802可以对应上述图7和图8中的中间表示变换模块,第二处理单元803可以对应上述图7和图8中的编译器后端模块。
[0175]
以上所描述的装置80可以参阅前面方法实施例的相应内容进行理解,此处不在重复赘述。
[0176]
图17所示,为本技术的实施例提供的计算机设备90的一种可能的逻辑结构示意图。计算机设备90包括:处理器901、通信接口902、存储器903以及总线904。处理器901、通信
接口902以及存储器903通过总线904相互连接。在本技术的实施例中,处理器901用于对计算机设备90的动作进行控制管理,例如,处理器901用于执行图9中方法实施例中的步骤。通信接口902用于支持计算机设备90进行通信。存储器903,用于存储计算机设备90的程序代码和数据,并为进程组提供内存空间。
[0177]
其中,处理器901可以是中央处理器单元,通用处理器,数字信号处理器,专用集成电路,现场可编程门阵列或者其他可编程逻辑器件、晶体管逻辑器件、硬件部件或者其任意组合。其可以实现或执行结合本技术公开内容所描述的各种示例性的逻辑方框,模块和电路。处理器901也可以是实现计算功能的组合,例如包含一个或多个微处理器组合,数字信号处理器和微处理器的组合等等。总线904可以是外设部件互连标准(peripheral component interconnect,pci)总线或扩展工业标准结构(extended industry standard architecture,eisa)总线等。总线可以分为地址总线、数据总线、控制总线等。为便于表示,图17中仅用一条粗线表示,但并不表示仅有一根总线或一种类型的总线。
[0178]
在本技术的另一实施例中,还提供一种计算机可读存储介质,计算机可读存储介质中存储有计算机执行指令,当设备的处理器执行该计算机执行指令时,设备执行上述图1至图15中处理器所执行的步骤。
[0179]
在本技术的另一实施例中,还提供一种计算机程序产品,该计算机程序产品包括计算机执行指令,该计算机执行指令存储在计算机可读存储介质中;当设备的处理器执行该计算机执行指令时,设备执行上述图1至图15中处理器所执行的步骤。
[0180]
在本技术的另一实施例中,还提供一种芯片系统,该芯片系统包括处理器,该处理器用于支持内存管理的装置实现上述图1至图15中处理器所执行的步骤。在一种可能的设计中,芯片系统还可以包括存储器,存储器,用于保存数据写入的装置必要的程序指令和数据。该芯片系统,可以由芯片构成,也可以包含芯片和其他分立器件。
[0181]
本领域普通技术人员可以意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、或者计算机软件和电子硬件的结合来实现。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本技术实施例的范围。
[0182]
所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的系统、装置和单元的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。
[0183]
在本技术实施例所提供的几个实施例中,应该理解到,所揭露的系统、装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。
[0184]
作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
[0185]
另外,在本技术实施例各个实施例中的各功能单元可以集成在一个处理单元中,
也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。
[0186]
功能如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本技术实施例的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本技术实施例各个实施例方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(read-only memory,rom)、随机存取存储器(random access memory,ram)、磁碟或者光盘等各种可以存储程序代码的介质。
[0187]
以上,仅为本技术实施例的具体实施方式,但本技术实施例的保护范围并不局限于此。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
