1.本发明属于发动机技术领域,具体涉及一种发动机冷试参数限值确定方法。
背景技术:
2.发动机冷试系统是发动机生产线上用于对即将下线的发动机质量进行测试的系统,是发动机批量生产质量的一个重要检测手段。由于产品图纸中并没有规定冷试时各项参数的限值,而是在投入使用后根据实际生产数据来确定限值,因此,从本质上说,冷试系统是一个判别每台发动机之间差异的系统,以识别出差异比较大的发动机,根据差异量判定是否合格,而这就使得如何确定合理的参数限值,成为冷试系统使用过程中最关键的问题。
3.目前限值的确定方法一般是先收集大约2000台生产数据,根据收集的样本计算出均值和标准差σ,设定上下限值为
4.然而,冷试系统对发动机的参数测试多达300多项,实际生产过程中发现每项测试参数的上下限的确定无法做到统一标准,有些测试参数按照
±
3σ的公差范围要求时,几乎很少超限,而有些测试参数即使将公差范围扩大到
±
4σ,仍然出现不合格率较高的现象。究其根本原因是测试数据未呈正态分布,简单地通过计算测试数据的均值和标准差确定的限值较为不合理。
技术实现要素:
5.本发明的目的是提供一种发动机冷试参数限值确定方法,以解决现有技术中的上述技术问题。
6.为实现上述目的,本发明提供了如下技术方案:
7.一种发动机冷试参数限值确定方法,其包括以下步骤:
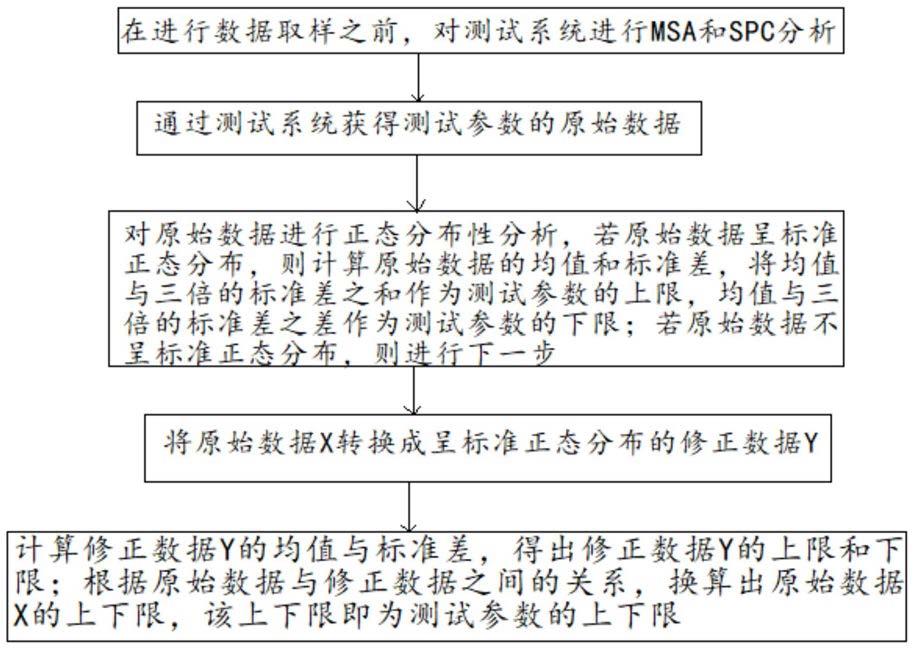
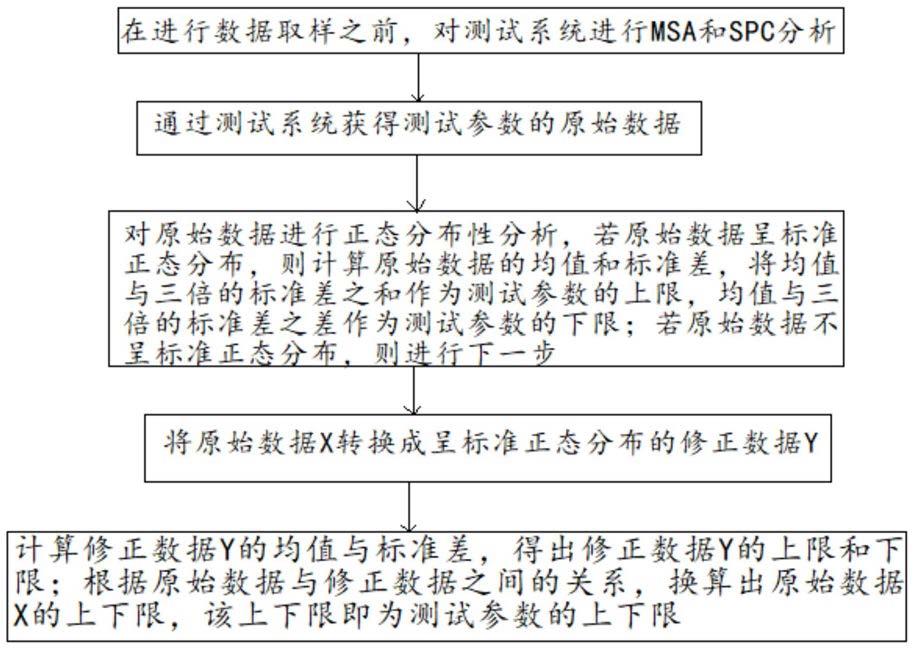
8.步骤s1:在进行数据取样之前,对测试系统进行msa和spc分析;
9.步骤s2:通过测试系统获得测试参数的原始数据;
10.步骤s3:对原始数据x进行正态分布性分析,若原始数据x呈正态分布,则计算原始数据x的均值和标准差σ,将作为测试参数的上下限值;若原始数据x不呈正态分布,则进行步骤s4;
11.步骤s4:将原始数据x转换成呈正态分布的修正数据y;
12.步骤s5:计算修正数据y的均值与标准差σ
y
,得出修正数据y的上限下限根据原始数据与修正数据之间的关系,换算出原始数据x的上下限,该上下限即为测试参数的上下限。
13.优选地,在对原始数据x进行正态分布性分析时,计算原始数据x的偏度和峰度,若该偏度的绝对值与该峰度的绝对值之差小于或等于0.5,则原始数据x呈正态分布;如两者的绝对值之差大于0.5,则原始数据x不呈正态分布。
14.优选地,通过skew函数计算原始数据x的偏度。
15.优选地,通过kurt函数计算原始数据x的峰度。
16.优选地,在对原始数据x进行正态分布性分析时,对原始数据中的单值进行取整,计算该单值取整后的数值的正态分布概率密度;然后计算该该单值出现的频率,将该频率与该正态分布概率密度做成组合图表进行对比,观察该原始数据x的正态分布性。
17.优选地,通过normdist函数可以计算出单值的正态分布概率密度。
18.优选地,通过countif函数计算出该单值出现的频率。
19.优选地,利用多项式曲线拟合的方法将原始数据转换成呈正态分布的修正数据。
20.优选地,在利用多项式曲线拟合的方法将原始数据转换成呈正态分布的修正数据时,具体包括以下步骤:
21.将原始数据中的各单值进行升序排列;
22.对原始数据中的各单值进行取整操作,得到各单值的取整值,将原始数据中的各单值处理为该取整值取整前的最小值,并使处理后的各单值呈线性递增的升序排列;
23.根据原始数据和处理后的各单值组成的数据,得出多项式曲线拟合公式;
24.根据该多项式曲线拟合公式,将原始数据转换成修正数据。
25.优选地,所述多项式曲线拟合为六项式曲线拟合。
26.本发明的有益效果在于:
27.本发明的发动机冷试参数限值确定方法,其在原始数据x呈正态分布时,计算原始数据x的均值和标准差σ,将作为测试参数的上下限值;在原始数据x不呈正态分布时,将原始数据x转换成呈正态分布的修正数据y,并计算修正数据y的均值与标准差σ
y
,得出修正数据y的上限下限而后根据原始数据与修正数据之间的关系,换算出原始数据x的上下限,将该上下限作为测试参数的上下限。可见,本发明较好地避免了简单地通过计算测试数据的均值和标准差来确定的限值,而是在测试数据不呈正态分布时将其转换呈正态分布的数据,而后确定限值,从而使得设置的限值较为合理,避免了产品的合格率过高或过低。
附图说明
28.为了更清楚地说明本技术实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,并将结合附图对本发明的具体实施例作进一步的详细说明,其中
29.图1为本发明实施例提供的发动机冷试参数限值确定方法的流程框图;
30.图2为本发明实施例提供的单值的频率与正态分布概率密度曲线的组合示意图;
31.图3为本发明实施例提供的拟合曲线的示意图。
具体实施方式
32.为了使本领域技术人员更好地理解本发明的技术方案,下面将结合具体实施例对本方案作进一步地详细介绍。
33.如图1所示,本发明的实施例提供了一种发动机冷试参数限值确定方法,其包括以
下步骤:
34.步骤s1:在进行数据取样之前,对测试系统进行msa和spc分析;
35.步骤s2:通过测试系统获得测试参数的原始数据;
36.步骤s3:对原始数据x进行正态分布性分析,若原始数据x呈正态分布,则计算原始数据x的均值和标准差σ,将作为测试参数的上下限值;若原始数据x不呈正态分布,则进行步骤s4;
37.步骤s4:将原始数据x转换成呈正态分布的修正数据y;
38.步骤s5:计算修正数据y的均值与标准差σ
y
,得出修正数据y的上限下限根据原始数据与修正数据之间的关系,换算出原始数据x的上下限,该上下限即为测试参数的上下限。
39.本发明实施例提供的发动机冷试参数限值确定方法,其在原始数据x呈正态分布时,计算原始数据x的均值和标准差σ,将作为测试参数的上下限值;在原始数据x不呈正态分布时,将原始数据x转换成呈正态分布的修正数据y,并计算修正数据y的均值与标准差σ
y
,得出修正数据y的上限下限而后根据原始数据与修正数据之间的关系,换算出原始数据x的上下限,将该上下限作为测试参数的上下限。可见,本发明较好地避免了简单地通过计算测试数据的均值和标准差来确定的限值,而是在测试数据不呈正态分布时将其转换呈正态分布的数据,而后确定限值,从而使得设置的限值较为合理,避免了产品的合格率过高或过低。
40.在本发明提供的一实施例中,在对原始数据x进行正态分布性分析时,计算原始数据x的偏度和峰度,若该偏度的绝对值与该峰度的绝对值之差小于或等于0.5,则原始数据x呈正态分布;如两者的绝对值之差大于0.5,则原始数据x不呈正态分布。采用此方案,能够通过一个较为客观的数值来判定原始数据的正态分布性。
41.可以优选,通过skew函数计算原始数据x的偏度。
42.可以优选,通过kurt函数计算原始数据x的峰度。
43.在本发明提供的另一实施例中,在对原始数据x进行正态分布性分析时,对原始数据中的单值进行取整,计算该单值取整后的数值的正态分布概率密度;然后计算该单值出现的频率,将该频率与该正态分布概率密度做成组合图表进行对比,观察该原始数据x的正态分布性。采用此方案,通过图表能够较为直观地反映出原始数据的正态分布性。
44.可以优选,通过normdist函数可以计算出单值的正态分布概率密度。
45.可以优选,通过countif函数计算出该单值出现的频率。可以理解的是,skew函数、kurt函数、normdist函数、countif函数均为excel中的常用函数,此处不再赘述。
46.进一步地,利用多项式曲线拟合的方法将原始数据转换成呈正态分布的修正数据。
47.具体地,在利用多项式曲线拟合的方法将原始数据转换成呈正态分布的修正数据时,具体包括以下步骤:
48.将原始数据进行升序排列;
49.对原始数据中的各单值进行取整操作,得到各单值的取整值,将原始数据中的各
单值处理为该取整值取整前的最小值,并使处理后的各单值呈线性递增的升序排列;
50.根据原始数据和处理后的各单值组成的数据,得出多项式曲线拟合公式;
51.根据该多项式曲线拟合公式,将原始数据转换成修正数据。
52.具体地,所述多项式曲线拟合为六项式曲线拟合,从而能够有效地提高拟合的精确度。
53.以下以发动机的启动扭矩的测试数据为例,阐述该发动机参数的限值的确定方法:
54.首先,对原始数据进行正态分布性分析:
55.收集约150台发动机的启动扭矩测试数据作为一组原始数据,计算出该组原始数据的均值和标准差,通过normdist函数可以计算出原始数据中各单值的正态分布概率密度,该处单值可以根据测试数据降低1至2个小数精度级别,建议单值的数量为原始数据中总体样本数量的1/7左右,并对单值进行取整操作,例如收集的样本数据中最小值为102.02,最大值为122.51,选取单值为102至123之间的所有整数;可以理解的是,正态分布概率密度代表了在正态分布下,出现某一单值的概率。
56.而后,通过countif函数可以计算出原始数据中某一单值出现的频率,将该频率与正态分布概率密度进行对比,可以观察该组数据的正态分布性,将两组数据做成组合图表能够更加直观地对该原始数据的正态分布性进行观察,如图2。
57.从图2中可以看出,频率分布呈现明显的正偏态,如果按照确定限值是不合适的,将会导致不合格率偏高,因为在左侧的单值依然有较高的出现频率。这种现象是冷试的系统因素造成,并且这些系统因素是稳定的。这里需要补充的一点是,在进行数据取样之前,冷试测试系统必须经过msa和spc分析,以排除冷试测试系统存在的不稳定因素,否则该正态分布性的分析没有任何意义。从图表中可以较为直观地看出原始数据是否呈现正态分布,然而,在实际生产过程中,还需要一个定量的数值来判定该组原始数据的正态分布性,通常情况下,可以用skew函数计算该原始数据x的偏度,用kurt函数计算该原始数据x的峰度,若偏度的绝对值与峰度的绝对值之间的差值等于或小于0.5,可以看作其呈现正态分布,可可以将作为其上下限的限值;若两者的绝对值的差值大于0.5,例如该组启动扭矩数据的偏度为
‑
1.73,峰度为2.67,偏度的绝对值与峰度的绝对值之差大于0.5,即该组启动扭矩数据不呈正态分布,则需要进入下一步,也就是对原始数据进行处理,以将原始数据转换为呈正态分布的修正数据。
58.而后,将原始数据转换为呈正态分布的修正数据:
59.将原始数据经过多项式曲线拟合后转换为呈正态分布的修正数据,具体方法如下:首先将原始数据进行升序排列,此时可以计算每一个单值的在标准正态分布下出现的次数,该次数由正态分布概率密度乘以样本数量得到;然后,对原始数据中的单值进行处理。为了增加拟合的精确度,将单值进行简单地处理,即对单值进行取整操作,相对于取整后的单值,原始数据中的单值可以看作是取整后的单值取整前的最大值,处理后的单值可以看作是取整后的单值取整前的最小值,并且取整前的单值可以是线性递增的,如表1:
60.表1原始数据与处理后的部分数据之间的对照表
61.pqrs
875.837675.5976.357676.1241076.357676.1241176.457676.2441276.557676.3641376.557676.3641476.587676.41576.587676.41676.687776.51776.817776.619391876.917776.711221976.947776.738782076.977776.766332177.047776.830612277.077776.858162377.137776.913272477.467777.216332577.497777.243882677.527777.271432777.567777.308162877.627777.363272977.667777.4
62.其中,p列为行数,q列为升序排列的原始数据,r列为取整后的排列数据,s列为经处理后的数据,r
16
数值由76变为77,则设定s
15
数值为76.4,s
16
数值为76.5,s
17
‑
s
28
之间的数值可以按照q
17
‑
q
28
之间的数值按比例递增计算,按此思路可以得到通用公式s
p
=r
p
‑
0.5 0.9
×
(q
p
‑
q
16
)/(q
29
‑
q
16
),即处理后的单值呈线性递增。而后,即可得到处理前后的详细数据,利用excel的添加趋势线功能,得到拟合曲线,如图3,而后根据该拟合曲线即可获得拟合公式,为提高精确度,使用六项式曲线拟合。
63.得到的拟合公式如下:y=
‑
0.0000179279659917597
×
x6 0.0121716215902595
×
x5‑
3.44000552812273
×
x4 518.058998293959
×
x3‑
43846.8278727107
×
x2 1977505.13169808
×
x1‑
37128851.1558962
×
x0。
64.最后将原始数据x按上述拟合公式转化为修正数据y,如表2所示。
65.表2原始数据与修正数据的对照表
66.原始数据修正数据原始数据修正数据原始数据修正数据原始数据修正数据原始数据修正数据118.91117.7385119.78120.0787119.42119.0321119.36118.8684118.4116.662111.05111.657119.66119.7176118.35116.5677119.16118.345121.63126.9807120.44122.276119.1118.1946117.31115.0155103.71108.6614119.26118.6024120.41122.1687117.69115.4972115.98113.9197107.89109.7768114.66113.358120.86123.8451109.55110.6407120.57122.7486112.54112.5334119.15118.3197114.89113.4389120.77123.4988119.47119.1708119.76120.0177118.43116.7196
119.83120.2327116.63114.3575117.72115.5392119.77120.0481118.32116.5121118.48116.817119.74119.957117.85115.7282119.08118.1452120.5122.4926115.78113.813119.11118.2194120.48122.4201113.32112.8816120.5122.4926115.04113.4983116.16114.0259116.28114.1026119.93120.5471120.03120.8697121.51126.4761119.8120.1401118.41116.6811115.7113.7733119.24118.5502120.37122.0267115.94113.8975118.95117.832115.64113.7445119.47119.1708119.81120.1709119.5119.2551118.95117.832120120.7721120.17121.3351119.1118.1946118.65117.1633119.34118.8145112.04112.2687114.11113.171104.69109.3994120.17121.3351118.58117.0179120.45122.312119.12118.2444116.53114.2796103.18107.709114.41113.2728107.24109.601118.28116.4389119.03118.023115.83113.8387113.68113.0193105.65109.5137103.94108.9304121.12124.8724118.72117.3127120.29121.7463121.96128.3835120.18121.3689114.6113.3374113.96113.1192118.01115.9769112.58112.5532116.84114.5358116.26114.0895111.72112.0825107.19109.5917115.84113.8439105.5109.5119113.87113.0876117.25114.9475120.15121.2676114.9113.4425118.24116.367116.45114.2203118.02115.993119.48119.1988116113.931104.21109.1609119.96120.643118.55116.9568113.43112.925119.42119.0321119.63119.6292119.24118.5502115.48113.6715120.34121.2676119.7119.8366118.93117.7851118.32116.5121114.42113.2762116.53114.2796103.24107.8442117.34115.0503118.67117.2056119.07118.1206112.2112.357115.96113.9086119.92120.5153118.8117.4883119.25118.5763119.36118.7343120.01120.8045118.28116.4389119.02117.9989110.41111.2221115.79113.8181114.84113.421116.17114.0321119.41119.0046119.82120.2018121.3125.6045
ꢀꢀꢀꢀ
67.对该组修正数据进行正态分布性验证,计算得到其偏度为
‑
0.047,峰度为0.042,偏度的绝对值与峰度的绝对值之差小于0.5,因此,该修正数据呈正态分布。
68.然后,进行限值计算:
69.计算修正数据y的均值与标准差σ
y
,修正数据的上下限分别为上限下限对y
usl
和y
lsl
按照上述拟合公式进行单变量求解,得到原始数据x的上限x
usl
和下限x
lsl
,针对该组修正数据,其上限y
usl
=129.52,下限y
lsl
=104.26,原始数据x的上限x
usl
=122.22,下限x
lsl
=102.23,因此,将上限值设定为122.22,下限值设定为102.23,与原始数据的102.02~122.55的范围一致,有效解决了原始数据不呈正态分布的问题。
70.利用本发明确定的上下限具有良好的精确度,为测试系统及时发现异常点提供了有效的帮助,同时能够将产品的合格率控制在合适的范围内,提高了生产线的效率。根据实际生产情况,冷试系统的合格率目前控制在95%~97%左右,剩余不合格产品通过热试系统测试,充分发挥了冷热试系统配合的作用。
71.以上仅是本发明的优选实施方式,需要指出的是,这些实施例仅用于说明本发明而不用于限制本发明的范围,而且,在阅读了本发明的内容之后,本领域相关技术人员可以对本发明做出各种改动或修改,这些等价形式同样落入本技术所附权利要求书所限定的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。