1.本技术涉及计算机及电子信息技术领域,特别涉及一种应用于卷积神经网络训练的可重构硬件加速器。
背景技术:
2.近些年来,卷积神经网络(convolutional neural networks,cnn)模型广泛应用在计算机视觉、语音识别和自然语言处理等诸多领域,随着识别准确率的要求逐渐提高,cnn模型的结构越来越庞大,其中包含的参数也越来越多,进而导致cnn模型的训练也变得愈加复杂和耗时,并且因为在线学习和数据隐私方面的考虑,在资源有限的边缘计算平台训练cnn模型具有广泛需求,因此,需要对cnn模型的训练进行加速。
3.cnn模型的训练阶段主要包括前向传播(forward propagation,fp)阶段、反向传播(backward propagation,bp)阶段和权重梯度(weight gradient,wg)计算阶段,在fp阶段,按照从前往后的顺序,将cnn模型中每层的输入激活值(即前一层的输出激活值)与该层对应的卷积核权重进行卷积计算,并通过激活函数得到该层的输出激活值,如此逐层向后计算,最终利用损失函数评估输出的预测标签与真实标签之间的偏差并计算损失;在bp阶段,利用fp阶段计算出的损失,按照从后往前的顺序,将每层的输入误差值(即后一层的误差值)与该层对应的卷积核权重进行卷积计算,得到该层的误差值,如此逐层向前计算,最终得到cnn模型中每一层的误差值;最后在wg阶段,根据链式法则,将前一层的输出激活值与当前层的误差值进行卷积运算,最终得到当前层的权重梯度,如此逐层计算,最终得到整个cnn模型中每层的更新卷积核权重,进而完成整个cnn模型的训练。
4.目前通常可以采用基于fpga(field programmable gatearray,现场可编程逻辑门阵列)开发的硬件加速器对cnn模型进行训练,但是该硬件加速器仅具有结构单一的处理单元,不仅硬件结构较为简单,而且实现的计算功能也较为单一,在训练时通常还需要对计算过程进行额外的拆解重组,并且需要重复读取数据,因而训练效率较低,无法满足cnn模型高效的训练需求。
技术实现要素:
5.本技术提供了一种应用于卷积神经网络训练的可重构硬件加速器,可用于解决现有的硬件架构训练效率较低的技术问题。
6.为了解决上述技术问题,本技术实施例公开了如下技术方案:
7.一种应用于卷积神经网络训练的可重构硬件加速器,包括缓存架构、运算处理阵列、功能模块和主控制器,其中:
8.所述缓存架构包括输入缓存架构和输出缓存架构;所述输入缓存架构用于存储待训练网络层在候选训练阶段的待运算数据,以及将所述待运算数据按预设数据分组方式进行重新排列和分组后,输入到所述运算处理阵列中,所述候选训练阶段为所有训练阶段中任一训练阶段;
9.所述运算处理阵列包括多个以二维数组方式排列的运算处理模块,以及与每行运算处理模块连接的缩放舍入模块;所述运算处理模块用于接收所述输入缓存架构输入的数据,并根据所述主控制器的指令,按预设移动步长进行与所述候选训练阶段相对应的卷积运算处理后,将卷积运算结果输入到对应的缩放舍入模块;所述缩放舍入模块用于对所述卷积运算结果进行数据格式转换后,发送给所述输出缓存架构进行存储;
10.所述功能模块用于对所述输出缓存架构中的数据进行激活操作或池化操作,以及在训练完成后,对所述待训练网络层中的待训练卷积核的权重值进行权值更新;
11.所述主控制器用于根据所述待训练卷积核的数量以及所述候选训练阶段下所述待训练网络层输入通道的数量,确定所述数据分组方式;以及,根据所述候选训练阶段以及所述移动步长,调整所述运算处理模块的内部数据连接方式,以使所述运算处理模块执行与所述移动步长和所述候选训练阶段相对应的卷积运算处理。
12.在一种可实现方式中,所述输入缓存架构包括第一输入架构和第二输入架构;
13.所述第一输入架构包括第一输入缓存模块和第一输入预取模块,所述第一输入缓存模块用于存储所述待运算数据中的第一输入数据,所述第一输入预取模块与所述运算处理阵列中每个运算处理模块连接,用于将所述第一输入数据按所述数据分组方式进行重新排列和分组后,确定每组第一目标数据对应的所述运算处理阵列中的目标列,并将每组第一目标数据发送给对应目标列中的每个运算处理模块;
14.所述第二输入架构包括第二输入缓存模块和第二输入预取模块,所述第二输入缓存模块用于存储所述待运算数据中的第二输入数据,所述第二输入预取模块与所述运算处理阵列中每个运算处理模块连接,用于将所述第二输入数据按所述数据分组方式进行重新排列和分组后,确定每组第二目标数据对应的所述运算处理阵列中的目标行,并将每组第二目标数据发送给对应目标行中的每个运算处理模块。
15.在一种可实现方式中,所述第二输入预取模块将所述第二目标数据发送给对应目标行中的所有运算处理模块时,是按照预设的时钟周期,将所述第二目标数据中每个数据依次发送给对应目标行中的所有运算处理模块。
16.在一种可实现方式中,如果所述候选训练阶段为fp阶段,则所述第一输入数据为所述待训练网络层中多个待训练卷积核的权重值,所述第二输入数据为所述待训练网络层的多通道输入激活值;
17.如果所述候选训练阶段为bp阶段,则所述第一输入数据为所述待训练网络层中多个旋转卷积核的权重值,所述第二输入数据是根据所述待训练网络层的多通道输入误差值确定的,所述旋转卷积核为将所述待训练卷积核旋转一百八十度后得到的矩阵;
18.如果所述候选训练阶段为wg阶段,则所述第一输入数据是根据所述待训练网络层的多通道误差值确定的,所述第二输入数据为所述待训练网络层的多通道输入激活值。
19.在一种可实现方式中,所述运算处理模块包括mac阵列、加法器组、多路选择器组以及部分和fifo队列;
20.所述mac阵列包括多个以二维数组方式排列的mac,所述mac的数量及排列方式与目标权重矩阵的尺寸相同,所述目标权重矩阵为目标待训练卷积核中目标通道的权重矩阵,所述目标待训练卷积核为多个待训练卷积核中任一待训练卷积核,所述目标通道为所述目标待训练卷积核中的任一通道;
21.所述mac包括第一外部端口、第二外部端口、内部端口、乘法器、加法器、多路选择器和寄存器,用于将所述第一外部端口的输入数据与所述第二外部端口的输入数据相乘后,再与所述内部端口的输入数据相加,得到中间结果,并根据所述主控制器的指令,将所述中间结果按与所述候选训练阶段相对应的路径进行传递,其中,所述第一外部端口的输入数据为接收到的第一目标数据中与所述mac的位置相对应的目标位置处的第一目标值,所述第二外部端口的输入数据为接收到的第二目标数据中需与所述第一目标值相乘的所有第二目标值,所述内部端口的输入数据为卷积运算过程中的部分和、前一个mac传递的结果或者所述mac输出的中间结果三者中的一个,所述内部端口的输入数据的选择由所述多路选择器实现;
22.所述加法器组包括两个加法器,用于根据所述主控制器的指令,在卷积运算过程中对多路mac输出的中间结果进行求和,并将结果输出到所述部分和fifo队列;
23.所述多路选择器组包括多个行多路选择器,用于将每个mac输出的中间结果以及所述加法器组输出的结果传送到所述部分和fifo队列中,其中,所述行多路选择器的数量与所述mac阵列的行数量相同;
24.所述部分和fifo队列用于存储卷积运算过程中的所有部分和。
25.在一种可实现方式中,所述对所述卷积运算结果进行数据格式转换,包括:
26.在完成所述待训练网络层在所述候选训练阶段的所有计算后,从目标运算处理模块输出的所有卷积运算结果中,确定第一最大值,并将所述第一最大值确定为局部最大值,所述目标运算处理模块为多个运算处理模块中任一运算处理模块;
27.根据所述第一最大值,确定由int32格式转换为int8格式时的移位位数;
28.按照所述移位位数,将所述目标运算处理模块输出的每个卷积运算结果由int32格式转换为int8格式,得到候选结果;
29.从所述目标运算处理模块所在行的每个运算处理模块对应的局部最大值中,确定第二最大值,并将所述第二最大值确定为全局最大值;
30.获取目标局部最大值对应的第一移位位数,以及所述全局最大值对应的第二移位位数,所述目标局部最大值为所述目标运算处理模块所在行的所有运算处理模块对应的局部最大值中任一局部最大值;
31.确定所述第一移位位数与所述第二移位位数之间的移位差异;
32.根据所述移位差异,对目标候选结果的数据格式进行二次调整,所述目标候选结果为所述目标局部最大值所对应的运算处理模块输出的候选结果。
33.如此,本技术实施例提供的可重构硬件加速器,通过在不同的训练阶段动态调整运算处理阵列中的每个运算处理模块的内部数据连接方式,以使运算处理模块按移动步长进行与候选训练阶段相对应的卷积运算处理,不仅可以有效避免无效计算,而且各运算处理模块之间可以并行处理,极大地提高了硬件的资源利用效率,此外,利用输入缓存架构按预设数据分组方式对待运算数据进行重新排列和分组后,再发送给运算处理模块进行处理,进一步提高了数据的复用效率和处理效率。整个可重构硬件加速器计算方式较为灵活,可以并行处理多通道运算,而且仅采用硬件架构即可满足不同训练阶段的计算需求,因而具有较高的模型训练效率。
附图说明
34.图1为cnn模型在训练过程的不同训练阶段所对应的计算流程示意图;
35.图2为本技术实施例提供的一种应用于卷积神经网络训练的可重构硬件加速器的结构示意图;
36.图3为本技术实施例提供的运算处理模块的结构示意图;
37.图4a为本技术实施例提供的运算处理模块在fp阶段以步长为1的方式进行卷积运算时内部的数据流向示意图;
38.图4b为本技术实施例提供的运算处理模块在fp阶段以步长为2的方式进行卷积运算时内部的数据流向示意图;
39.图5a为本技术实施例提供的运算处理模块在bp阶段以步长为1的方式进行卷积运算时内部的数据流向示意图;
40.图5b为本技术实施例提供的运算处理模块在bp阶段以步长为2的方式进行卷积运算时内部的数据流向示意图;
41.图6a为本技术实施例提供的运算处理模块在wg阶段以步长为1的方式进行卷积运算时内部的数据流向示意图;
42.图6b为本技术实施例提供的运算处理模块在wg阶段以步长为2的方式进行卷积运算时内部的数据流向示意图;
43.图7为本技术实施例提供的缩放舍入模块进行数据格式转换的工作流程示意图;
44.图8为vgg网络一个卷积层中的卷积核尺寸、输入特征图尺寸和输出特征图尺寸的结构示意图;
45.图9为卷积块和卷积核在一个通道下的具体值示意图;
46.图10为本应用示例中运算处理模块在fp阶段以步长为1的方式进行卷积运算时内部的具体数据流向示意图。
具体实施方式
47.为使本技术的目的、技术方案和优点更加清楚,下面将结合附图对本技术实施方式作进一步地详细描述。
48.下面首先结合附图对cnn模型的训练过程进行介绍。
49.图1示例性示出了cnn模型在训练过程的不同训练阶段所对应的计算流程示意图,如图1所示,cnn模型的训练阶段主要包括fp阶段、bp阶段和wg阶段。
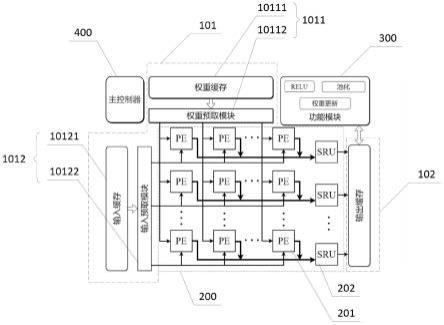
50.在fp阶段(如图1中(a)和(b)所示),训练特征图逐层通过整个cnn网络。根据网络层的类型,通过相应的运算依次计算每一层的输出激活值。例如,对于步长=1的卷积层(假设为第l层),卷积核以1为步长在输入特征图上移动,通过将第l层卷积核(尺寸为3
×
3)的权重(w
l
)与第(l-1)层的输出激活值(a
l-1
)(尺寸为5
×
5)进行卷积计算,然后通过激活函数得到输出激活值(a
l
)(尺寸为3
×
3),计算流程如图1中(a)所示。对于步长=2的卷积层(假设为第l层),卷积核以2为步长在输入特征图上移动,得到输出激活值(a
l
)(尺寸为2
×
2),计算流程如图1中(b)所示。fp阶段的训练过程会将前向传播最终输出的预测标签以及真实标签传递给损失函数,例如交叉熵损失函数,以评估预测标签和真实标签之间的偏差并计算损失(loss)。
51.在bp阶段(如图1中(c)和(d)所示),从fp阶段计算得到的损失开始,按照从后往前的顺序,逐层计算每层激活值的梯度,即误差值(error,e
l
)。例如,对于步长=1的卷积层,计算模式类似于fp阶段的卷积,以1为步长在输入误差图上移动,通过将第l层卷积核(此时的卷积核为将fp阶段中卷积核旋转180度后得到的,尺寸仍为3
×
3)的权重(w
l
)与第(l 1)层的误差值(e
l 1
)(此时的误差值为填充后的矩阵,尺寸由原先的3
×
3变为7
×
7)进行卷积计算,得到第l层的误差值(e
l
)(尺寸为5
×
5),计算流程如图1中,(c)所示。注意,在反向传播期间,输入和输出的通道数与fp阶段相反。对于步长=2的卷积层,将旋转后的卷积核以1为步长在第(l 1)层的误差值(e
l 1
)(此时的误差值为填充后的矩阵,经填充后尺寸由原先的2
×
2变为7
×
7,并且在水平方向和垂直方向两个维度进行了填零)矩阵上滑动,通过卷积计算得到第l层的误差值(e
l
)(尺寸为5
×
5),计算流程如图1中(d)所示。
52.在wg阶段(如图1中(e)和(f)所示),是根据链式法则通过使用前向传播期间的输出激活值(a
l
)和误差值(e
l
)来计算。例如,对于步长=1的卷积层,将第l层的输出激活值(a
l
)与第(l 1)层的误差值(e
l 1
)进行卷积,得到第(l 1)层的权重梯度(g
l 1
),计算流程如图1中(e)所示。对于步长=2的卷积层,将第(l 1)层误差值(e
l 1
)(此时的误差值的尺寸为2
×
2,并且在水平方向和垂直方向两个维度进行了填零)与第l层的输出激活值(a
l
)进行卷积计算,得到第(l 1)层的权重梯度(g
l 1
),计算流程如图1中(f)所示。
53.为了对cnn模型的训练过程进行加速,满足cnn模型高效的训练需求,本技术实施例提供了一种应用于卷积神经网络训练的可重构硬件加速器。图2示例性示出了本技术实施例提供的一种应用于卷积神经网络训练的可重构硬件加速器的结构示意图,如图2所示,本技术实施例提供的可重构硬件加速器包括缓存架构100(图中未示出)、运算处理阵列200、功能模块300和主控制器400,其中:
54.缓存架构100包括输入缓存架构101和输出缓存架构102。输入缓存架构101用于存储待训练网络层在候选训练阶段的待运算数据,以及将待运算数据按预设数据分组方式进行重新排列和分组后,输入到运算处理阵列200中。其中,候选训练阶段为所有训练阶段中任一训练阶段,即fp阶段、bp阶段和wg阶段中任一阶段。输出缓存架构102为图中的输出缓存。
55.运算处理阵列200包括多个以二维数组方式排列的运算处理模块201,以及与每行运算处理模块201连接的缩放舍入模块(scaling and rounding unit,sru)202。运算处理模块202用于接收输入缓存架构101输入的数据,并根据主控制器400的指令,按预设移动步长进行与候选训练阶段相对应的卷积运算处理后,将卷积运算结果输入到对应的缩放舍入模块(scaling and rounding unit,sru)202。缩放舍入模块202用于对卷积运算结果进行数据格式转换后,发送给输出缓存架构102进行存储。
56.需要说明的是,运算处理阵列200包括n
×
m个运算处理模块201,优选地,n
×
m为16
×
16。以16
×
16个运算处理模块201为例,对本技术实施例提供的可重构硬件加速器进行说明。
57.功能模块300用于对输出缓存架构102中的数据进行激活操作或池化操作,以及在训练完成后,对待训练网络层中的待训练卷积核的权重值进行权值更新。具体地,功能模块300中包含训练过程中其他所需的通用计算模块,例如线性激活函数(relu)、池化(pooling)和权重更新(weight update)等。
58.主控制器400用于根据待训练卷积核的数量以及候选训练阶段下待训练网络层输入通道的数量,确定数据分组方式。以及,根据候选训练阶段以及移动步长,调整运算处理模块201的内部数据连接方式,以使运算处理模块201执行按移动步长进行与候选训练阶段相对应的卷积运算处理。也就是说,主控制器400可以用于生成卷积神经网络训练过程中各个模块所需的各种控制信号,比如将上述数据分组方式发送给输入缓存架构101,将内部数据连接方式发送给运算处理模块201等等。
59.如此,本技术实施例提供的可重构硬件加速器,通过在不同的训练阶段动态调整运算处理阵列中的每个运算处理模块的内部数据连接方式,以使运算处理模块按移动步长进行与候选训练阶段相对应的卷积运算处理,不仅可以有效避免无效计算,而且各运算处理模块之间可以并行处理,极大地提高了硬件的资源利用效率,此外,利用输入缓存架构按预设数据分组方式对待运算数据进行重新排列和分组后,再发送给运算处理模块进行处理,进一步提高了数据复用效率和处理效率。整个可重构硬件加速器计算方式较为灵活,可以并行处理多通道运算,而且仅采用硬件架构即可满足不同训练阶段的计算需求,因而具有较高的模型训练效率。
60.进一步地,下面对输入缓存架构101的具体结构进行说明。
61.如图2所示,输入缓存架构101包括第一输入架构1011和第二输入架构1012。
62.第一输入架构1011包括第一输入缓存模块10111和第一输入预取模块10112,第一输入缓存模块10111用于存储待运算数据中的第一输入数据,第一输入预取模块10112与运算处理阵列200中每个运算处理模块201连接,用于将第一输入数据按数据分组方式进行重新排列和分组后,确定每组第一目标数据对应的运算处理阵列200中的目标列,并将每组第一目标数据发送给对应目标列中的每个运算处理模块201。
63.第二输入架构1012包括第二输入缓存模块10121和第二输入预取模块10122,第二输入缓存模块10121用于存储待运算数据中的第二输入数据,第二输入预取模块10122与运算处理阵列200中每个运算处理模块201连接,用于将第二输入数据按数据分组方式进行重新排列和分组后,确定每组第二目标数据对应的运算处理阵列200中的目标行,并将每组第二目标数据发送给对应目标行中的每个运算处理模块201。
64.具体地,如果候选训练阶段为fp阶段,则第一输入数据为待训练网络层中多个待训练卷积核的权重值。第一目标数据为任一待训练卷积核中任一通道的权重值,第一输入预取模块10112分别为每个待训练卷积核中每个通道的权重值分配目标列,并发送给位于目标列中的每个运算处理模块201。第二输入数据为待训练网络层的多通道输入激活值,即输入特征图中每个像素点的激活值,也就是待训练网络层的前一个网络层的输出激活值。第二目标数据为任一通道的输入激活值,第二输入预取模块10122分别为每个通道的输入激活值分配目标行,并发送给位于目标行中的每个运算处理模块201。
65.如果候选训练阶段为bp阶段,则第一输入数据为待训练网络层中多个旋转卷积核的权重值,其中,旋转卷积核为将待训练卷积核旋转一百八十度后得到的矩阵。第一目标数据为任一旋转卷积核中任一通道的权重值,第一输入预取模块10112分别为每个旋转卷积核中每个通道的权重值分配目标列,并发送给位于目标列中的每个运算处理模块201。第二输入数据是根据待训练网络层的多通道输入误差值确定的,即根据待训练网络层的后一个网络层的误差值确定第二输入数据。
66.具体地,在bp阶段,如果步长为1,则对当前网络层的输入误差值(假设用e
l 1
表示)进行填充,得到填充后的误差值(假设用e’l 1
表示),第二输入数据为填充后的误差值(e’l 1
),第二目标数据为填充后任一通道的误差值,第二输入预取模块10122分别为每个通道的误差值分配目标行,并发送给位于目标行中的每个运算处理模块201。如果步长为2,则对当前网络层的输入误差值(假设用e
l 1
表示)进行填充,并且在水平方向和垂直方向两个维度填零,得到填充及填零后的误差值(假设用e”l 1
表示),第二输入数据为填充及填零后的误差值(e”l 1
),第二目标数据为填充及填零后任一通道的误差值,第二输入预取模块10122分别为每个通道的误差值分配目标行,并发送给位于目标行中的每个运算处理模块201。
67.如果候选训练阶段为wg阶段,则第一输入数据是根据待训练网络层的多通道误差值确定的。第二输入数据为待训练网络层的多通道输入激活值。
68.具体地,在wg阶段,如果步长为1,则第一输入数据为待训练网络层(假设为第l 1层)的多通道误差值(e
l 1
),第一目标数据为任一通道的误差值,第一输入预取模块10112分别为每个通道的误差值分配目标列,并发送给位于目标列中的每个运算处理模块201。第二输入数据为待训练网络层的多通道输入激活值,第二目标数据为任一通道的输入激活值,第二输入预取模块10122分别为每个通道的输入激活值分配目标行,并发送给位于目标行中的每个运算处理模块201。如果步长为2,则对待训练网络层(假设为第l 1层)的多通道误差值(e
l 1
)在水平方向和垂直方向两个维度填零后,得到填零后的误差值(假设用e
”’
l 1
表示),第一输入数据为填零后的误差值(e
”’
l 1
),第一目标数据为任一通道的填零后的误差值,第一输入预取模块10112分别为每个通道的填零后的误差值分配目标列,并发送给位于目标列中的每个运算处理模块201。
69.示例性地,以fp阶段为例,假设待训练网络层中包括3个待训练卷积核,则在t0时刻,第一输入预取模块10112将第1个待训练卷积核中第1个通道的权重值发送给位于第1列的每个运算处理模块201,同时将第2个待训练卷积核中第1个通道的权重值发送给位于第2列的每个运算处理模块201,同时将第3个待训练卷积核中第1个通道的权重值发送给位于第3列的每个运算处理模块201;同时,第二输入预取模块10122将第1个通道的输入激活值发送给位于第1行的每个运算处理模块201,进而完成第1通道的卷积运算。在t1时刻,第一输入预取模块10112将第1个待训练卷积核中第2个通道的权重值发送给位于第4列的每个运算处理模块201,同时将第2个待训练卷积核中第2个通道的权重值发送给位于第5列的每个运算处理模块201,同时将第3个待训练卷积核中第2个通道的权重值发送给位于第6列的每个运算处理模块201;同时,第二输入预取模块10122将第2个通道的输入激活值发送给位于第2行的每个运算处理模块201,进而完成第2通道的卷积运算。如此类推,直至完成全部通道的卷积运算,得到待训练网络层在fp阶段的输出激活值。
70.需要说明的是,第二输入预取模块10122将第二目标数据发送给对应目标行中的所有运算处理模块201时,是按照预设的时钟周期,将第二目标数据中每个数据依次发送给对应目标行中的所有运算处理模块201。具体地,第二目标数据中每个数据是以脉动阵列的方式进行发送的。预设的时钟周期不作具体限定,比如1
×
10-8
s或5
×
10-9
s等。
71.如此,采用上述输入缓存架构,可以将来自片上缓存的待运算数据根据运算处理模块的计算模式重新排列,并正确地传递到运算处理阵列中,避免了冗余运算,极大提高了运算效率。
72.下面对运算处理模块201的具体结构进行说明。
73.图3示例性示出了本技术实施例提供的运算处理模块的结构示意图,如图3所示,运算处理模块201,包括mac(multiply-accumulate units,乘累加单元)阵列2011、加法器组2012、多路选择器组2013以及部分和fifo队列2014。
74.mac阵列2011包括多个以二维数组方式排列的mac20111,mac20111的数量及排列方式与目标权重矩阵的尺寸相同,目标权重矩阵为目标待训练卷积核中目标通道的权重矩阵,目标待训练卷积核为多个待训练卷积核中任一待训练卷积核,目标通道为目标待训练卷积核中的任一通道。也就是说,针对3
×
3的目标权重矩阵,mac阵列2011包括9个mac20111,并且以3
×
3的方式进行排列。
75.具体地,以9个mac20111按照3
×
3排列为例,对本技术实施例提供的运算处理模块201进行说明。
76.mac20111包括第一外部端口(端口1)、第二外部端口(端口2)、内部端口(端口3、4或5)、乘法器(a)、加法器(b)、多路选择器(c)和寄存器(d),用于将第一外部端口(端口1)的输入数据与第二外部端口(端口2)的输入数据相乘后,再与内部端口(端口3、4或5)的输入数据相加,得到中间结果,并根据主控制器400的指令,将中间结果按与候选训练阶段相对应的路径进行传递。
77.其中,第一外部端口(端口1)的输入数据为接收到的第一目标数据中与mac20111的位置相对应的目标位置处的第一目标值,第二外部端口(端口2)的输入数据为接收到的第二目标数据中需与第一目标值相乘的所有第二目标值,内部端口(端口3、4或5)的输入数据为卷积运算过程中的部分和(经端口3传输)、前一个mac20111传递的结果(经端口4传输)或者mac20111输出的中间结果(经端口5传输)三者中的一个,所述内部端口的输入数据的选择由多路选择器(c)实现。
78.进一步地,端口3用来接收来自部分和fifo队列2014的部分和,即前面通道的数据卷积的中间结果,比如说第一个通道的卷积,即9个mac20111的结果计算完成后,把结果暂存在部分和fifo队列2014中,在下一个通道的输入数据传过来的第一个时钟周期,通过多路选择器(c)把第一行第一个mac20111(假设表示为mac11)的端口3选通,将部分和传到加法器(b)进行累加,下一个时钟周期,多路选择器(c)又将加法器(b)的输入选择为端口4,mac11的端口4我们设置为0。需要说明的是,在大部分时钟周期,mac11的加法器(b)输入都选通为端口4,即为0。只有在计算需要对不同通道的结果进行累加时,我们才将部分和从部分和fifo队列2014中取出来并通过端口3传递到mac11中。而对于第一行第二个mac20111(假设表示为mac12)和第三个mac20111(假设表示为mac13),端口4都是用来接收前面mac20111的传递值。给其他mac20111,比如mac12
……
mac33也留了端口3的原因是在bp阶段和wg阶段,这些mac20111也要接收部分和。
79.端口4用来接0或者接收来自前面mac20111的传递值,其中,mac11、mac21、mac31接0,mac12、mac13、mac 22、mac 23、mac 32、mac 33接收传递值。
80.端口5用来在wg阶段进行每个mac20111内部自累加。这种计算模式下,乘累加的计算结果不需要在mac20111之间传递,而是送到到自己内部的加法器(b)和后续的乘法结果继续累加。
81.多路选择器(c)用于在不同的计算模式和周期通过控制信号,选择性地将内部端
口(端口3、4或5)的输入数据传递给加法器(b)。寄存器(d)用于存储加法器(b)输出的中间结果。
82.加法器组2012包括两个加法器,用于根据主控制器400的指令,在卷积运算过程中对多路mac20111输出的中间结果进行求和,并将结果输出到部分和fifo队列2014。
83.多路选择器组2013包括多个行多路选择器,用于将每个mac20111输出的中间结果以及加法器组2012输出的结果传送到部分和fifo队列2014中,其中,行多路选择器的数量与mac阵列2011的行数量相同。
84.部分和fifo队列2014用于存储卷积运算过程中的所有部分和。还用于将部分和提供给mac阵列2011继续累加直到得到最终输出。
85.如此,上述每列运算处理模块共享相同的第一输入数据,每行运算处理模块共享相同的第二输入数据,减少了数据反复读取带来的额外开销,同时各运算处理模块之间可以并行处理,提高了吞吐量,而且运算处理模块的内部数据连接方式可以根据训练阶段的不同进行动态调整,计算方式较为灵活,硬件架构可以满足不同训练阶段的计算需求,运算效率较高。
86.下面结合具体附图对不同训练阶段下,本技术实施例提供的运算处理模块201中内部数据流向进行具体说明。
87.需要说明的是,下述具体数据流向说明均是针对运算处理阵列200中单个运算处理模块201进行说明的,并且下述各具体数据流向的运算过程均与图1所述的训练过程中不同训练阶段的计算流程相对应。
88.图4a示例性示出了本技术实施例提供的运算处理模块在fp阶段以步长为1的方式进行卷积运算时内部的数据流向示意图。如图4a所示,当步长为1时,运算处理模块201以权重保持的数据流,像传统的2-d卷积器一样工作。待训练卷积核一个通道的9个权重值(用w
ij
表示,其中i表示权重值的横坐标,j表示权重值的纵坐标)准确地传递给9个mac的端口1,即w
00
传递给第一行第一个mac的端口1,w
01
传递给第一行第二个mac的端口1,
……
,w
22
传递给第三行第三个mac的端口1,这些权重在运算处理模块201中保持不变,直到计算过程移动到下一个通道。与此同时,该通道的输入特征图的输入激活值(用a
ij
表示,其中i表示输入激活值的横坐标,j表示输入激活值的纵坐标)被传递给9个mac的端口2。具体地,在将输入激活值a
ij
传递给每个mac的过程中,首先将所有的输入激活值a
ij
进行重新分组,从中选出需与该mac端口1接收的权重值相乘的所有输入激活值,再按照预设的时钟周期,依次输入给对应的mac端口2。示例性地,以第二行的三个mac为例,端口1接收的权重值分别为w
10
、w
11
和w
12
,在待训练卷积核以步长为1的方式在输入特征图上进行卷积时,需与w
10
、w
11
和w
12
卷积的输入激活值从a
10
开始,也就是输入特征图中第一行的输入激活值a
00
、a
01
……
并不参与w
10
、w
11
和w
12
的卷积运算。同理可得,第一行的三个mac的端口2接收的输入激活值从a
00
开始,按照预设的时钟周期,依次输入;第三行的三个mac的端口2接收的输入激活值从a
20
开始,最终,各行mac的输出结果通过加法器组2012中的一个加法器求和后输出到部分和fifo队列2014中。
89.需要说明的是,在各个部分和进入部分和fifo队列2014之前,控制器400会对运算过程中的无效结果进行删减,比如a
00
×w01
或者a
00
×w02
,此类无效计算并非正常卷积过程中的需求值,因此控制器400会将此类结果去除。本技术实施例的整个运算过程中此无效结果
的去除步骤均存在,后续介绍各阶段运算过程时,此步骤不再赘述。
90.图4b示例性示出了本技术实施例提供的运算处理模块在fp阶段以步长为2的方式进行卷积运算时内部的数据流向示意图。如图4b所示,当步长为2时,每个mac的端口1接收的仍然是待训练卷积核一个通道的9个权重值中对应位置的权重值(用w
ij
表示,其中i表示权重值的横坐标,j表示权重值的纵坐标),端口2如果仍然按照步长为1时的数据流向进行输入,则有一半的计算操作是无效的,因此为了减少这种不必要的计算开销,将该通道的输入特征图的输入激活值(用a
ij
表示,其中i表示输入激活值的横坐标,j表示输入激活值的纵坐标)根据纵坐标j为奇数或者偶数分为两组,即偶数输入组和奇数输入组,其中,奇数输入组的第一位补0,再按照预设的时钟周期,依次输入给对应的mac端口2。示例性地,以第一行的三个mac为例,端口1接收的权重值分别为w
00
、w
01
和w
02
,将输入激活值a
ij
分为偶数输入组(a
00
、a
02
、a
04
、
……
)和奇数输入组(0、a
01
、a
03
、a
05
、
……
)后,将偶数输入组的各个值按照预设时钟周期同时输入给第一个mac和第三个mac,将奇数输入组的各个值按照预设时钟周期输入给第二个mac。同理可得,第二行的三个mac中,将偶数输入组(a
10
、a
12
、a
14
、
……
)的各个值按照预设时钟周期同时输入给第一个mac和第三个mac,将奇数输入组(0、a
11
、a
13
、a
15
、
……
)的各个值按照预设时钟周期输入给第二个mac。第三行的三个mac中,将偶数输入组(a
20
、a
22
、a
24
、
……
)的各个值按照预设时钟周期同时输入给第一个mac和第三个mac,将奇数输入组(0、a
21
、a
23
、a
25
、
……
)的各个值按照预设时钟周期输入给第二个mac,最终,各行mac的输出结果通过加法器组2012中的一个加法器求和后输出到部分和fifo队列2014中。
91.图5a示例性示出了本技术实施例提供的运算处理模块在bp阶段以步长为1的方式进行卷积运算时内部的数据流向示意图。如图5a所示,当步长为1时,运算处理模块201内部的数据流向与fp阶段步长为1时的数据流向相同,区别1在于,9个mac的端口1接收到的并非待训练卷积核一个通道的9个权重值,而是旋转卷积核一个通道的9个权重值,即第一行三个mac的端口1接收到的分别是w
22
(fp阶段为w
00
)、w
21
(fp阶段为w
01
)和w
20
(fp阶段为w
02
),第二行三个mac的端口1接收到的分别是w
12
(fp阶段为w
10
)、w
11
(fp阶段为w
11
)和w
10
(fp阶段为w
12
),第三行三个mac的端口1接收到的分别是w
02
(fp阶段为w
20
)、w
01
(fp阶段为w
21
)和w
00
(fp阶段为w
22
)。区别2在于,9个mac的端口2接收到的并非该通道的输入特征图的输入激活值,而是该通道的填充后的输入误差值(用e
ij
表示,其中i表示填充后的输入误差值的横坐标,j表示填充后的输入误差值的纵坐标)。示例性地,第一行三个mac的端口2接收到的是e
00
、e
01
、e
02
……
,第二行三个mac的端口2接收到的是e
10
、e
11
、e
12
……
,第三行三个mac的端口2接收到的是e
20
、e
21
、e
22
……
。
92.图5b示例性示出了本技术实施例提供的运算处理模块在bp阶段以步长为2的方式进行卷积运算时内部的数据流向示意图。如图5b所示,当步长为2时,计算模式与fp阶段有较大不同,步长为2时需要对填充后的输入误差值(用e
ij
表示,其中i表示填充后的输入误差值的横坐标,j表示填充后的输入误差值的纵坐标)在水平方向和垂直方向两个维度填零后,得到填充及填零后的误差值(e
ij
)。每个mac的端口1输入的是旋转卷积核一个通道的9个权重值中与此时的运算相适应的对应位置的权重值,示例性地,第一行三个mac的端口1接收到的分别是w
02
、w
00
和w
01
,第二行三个mac的端口1接收到的分别是w
12
、w
10
和w
11
,第三行三个mac的端口1接收到的分别是w
22
、w
20
和w
21
。每个mac的端口2输入的是需与该mac端口1接收的权重值相乘的所有输入误差值,即填充及填零后的误差值(e
ij
)。同样地,为了减少不必要
的计算开销,也可以将输入的误差值(用e
ij
表示,其中i表示输入的误差值的横坐标,j表示输入的误差值的纵坐标)根据纵坐标j为奇数或者偶数进行提前分组。示例性地,第一行三个mac的端口2接收到的是0、e
10
、e
11
、e
12
……
;第二行三个mac的端口2接收到的是0、e
10
、e
11
、e
12
……
;第三行三个mac的端口2接收到的是0、e
00
、e
01
、e
02
……
。在步长为2的计算过程中,部分和fifo队列2014需要并行接收四个部分和,分别为第一行第二个mac的输出结果与第三行第二个mac的输出结果之和、第一行第三个mac的输出结果与第三行第三个mac的输出结果之和、第二行第二个mac的输出结果以及第二行第三个mac的输出结果。
93.图6a示例性示出了本技术实施例提供的运算处理模块在wg阶段以步长为1的方式进行卷积运算时内部的数据流向示意图。如图6a所示,当步长为1时,由于不同网络层的误差值矩阵的尺寸较大并且不完全不同,同时卷积核一个通道的权重梯度通常与mac具有相同3
×
3大小的维度。因此,运算处理模块以输出保持的方式工作,计算结果在mac中不断累加,直到得到最终有效结果,以提高mac利用效率。示例性地,第一行三个mac的端口1接收到的分别是e
02
、e
01
和e
00
,第二行三个mac的端口1接收到的分别是e
12
、e
11
和e
10
,第三行三个mac的端口1接收到的分别是e
22
、e
21
和e
20
。第一行三个mac的端口2接收到的是a
00
、a
01
、a
02
……
;第二行三个mac的端口2接收到的是a
10
、a
11
、a
12
……
;第三行三个mac的端口2接收到的是a
20
、a
21
、a
22
……
。图中
③
表示端口3,
⑤
表示端口5。
94.图6b示例性示出了本技术实施例提供的运算处理模块在wg阶段以步长为2的方式进行卷积运算时内部的数据流向示意图。如图6b所示,当步长为2时,每个mac的端口1接收到的误差值矩阵会在水平和垂直方向上填零,此时根据输入激活值(a
ij
)的列坐标j将输入激活值(a
ij
)分为偶数组和奇数组以避免零值的输入,从而减少无效计算。示例性地,每个mac的端口1接收到的误差值与wg阶段步长为1时每个mac的端口1接收到的误差值相同,此处不再赘述。关于每个mac的端口2接收到的数据,以第一行的三个mac为例,将输入激活值a
ij
分为偶数输入组(a
00
、a
02
、a
04
、
……
)和奇数输入组(0、a
01
、a
03
、a
05
、
……
)后,将偶数输入组的各个值按照预设时钟周期同时输入给第一个mac和第三个mac,将奇数输入组的各个值按照预设时钟周期输入给第二个mac。同理可得,第二行的三个mac中,将偶数输入组(a
10
、a
12
、a
14
、
……
)的各个值按照预设时钟周期同时输入给第一个mac和第三个mac,将奇数输入组(0、a
11
、a
13
、a
15
、
……
)的各个值按照预设时钟周期输入给第二个mac。第三行的三个mac中,将偶数输入组(a
20
、a
22
、a
24
、
……
)的各个值按照预设时钟周期同时输入给第一个mac和第三个mac,将奇数输入组(0、a
21
、a
23
、a
25
、
……
)的各个值按照预设时钟周期输入给第二个mac。
95.如此,运算处理模块在不同的训练阶段配置不同的内部数据连接方式,提高了运算过程中数据的复用率,数据以脉动形式在运算处理模块内部流转,同时在步长为2的情况下还避免了乘0的冗余计算,提高了硬件利用率,因而整体卷积运算效率非常高。
96.下面对缩放舍入模块202的具体工作流程进行说明。
97.缩放舍入模块(scaling and rounding unit,sru)202用于对卷积运算结果进行数据格式转换,具体的数据格式转换通过以下方式进行:
98.第一,在完成待训练网络层在候选训练阶段的所有计算后,从目标运算处理模块输出的所有卷积运算结果中,确定第一最大值,并将第一最大值确定为局部最大值,目标运算处理模块为多个运算处理模块中任一运算处理模块。
99.第二,根据第一最大值,确定由int32(32bit integer,32位整数)格式转换为int8
(8bit integer,8位整数)格式时的移位位数。
100.第三,按照移位位数,将目标运算处理模块输出的每个卷积运算结果由int32格式转换为int8格式,得到候选结果。
101.第四,从目标运算处理模块所在行的每个运算处理模块对应的局部最大值中,确定第二最大值,并将第二最大值确定为全局最大值。
102.第五,获取目标局部最大值对应的第一移位位数,以及全局最大值对应的第二移位位数,目标局部最大值为目标运算处理模块所在行的所有运算处理模块对应的局部最大值中任一局部最大值。
103.第六,确定第一移位位数与第二移位位数之间的移位差异。
104.第七,根据移位差异,对目标候选结果的数据格式进行二次调整,目标候选结果为目标局部最大值所对应的运算处理模块输出的候选结果。
105.具体地,缩放舍入模块202所在行中各个运算处理模块201,可以分时段轮流使用该行共用的缩放舍入模块202。
106.图7示例性示出了本技术实施例提供的缩放舍入模块进行数据格式转换的工作流程示意图,如图7所示,缩放舍入模块202进行数据格式转换时,可以分为两个阶段,第一个阶段为局部最大缩放(local maximum scaling,lms)阶段,该阶段基于单个目标运算处理模块输出的所有卷积运算结果中的局部最大值,并根据该局部最大值确定由int32转换为int8的移位位数,将该局部最大值和局部移位位数存储进最大值寄存器堆(max regs,maximum register file,为独立于缩放舍入模块和运算处理模块之外的存储装置)中,sru按照局部移位位数,将每个卷积运算结果由int32格式转换为int8格式,得到候选结果,并将int8格式的候选结果传输到片上的缓存(例如bram,即block ram,块随机存取存储器)中,这一阶段对应于上述第一至第三。第二个阶段为全局最大缩放(global maximum scaling,gms)阶段,当计算完成,得到目标运算处理模块所在行的所有运算处理模块对应的所有卷积运算结果时,可以从不同的运算处理模块所对应的局部最大值中获得全局最大值,将该全局最大值和全局移位位数也存储进最大值寄存器堆中,根据该全局最大值对应的全局移位位数,以及目标运算处理模块对应的局部移位位数,确定移位差异,并按照该移位差异,对片上的缓存中的目标运算处理模块输出的所有候选结果的数据格式进行二次调整,这一阶段对应于上述第四至第七。示例性地,如果移位差异为1位,则需对目标运算处理模块输出的所有候选结果再次移1位。
107.如此,采用上述缩放舍入模块,可以将量化神经网络训练算法的高位宽中间结果映射到低比特最终结果的过程分为局部缩放和全局缩放两个阶段,减少了片上缓冲区大小和数据传输的带宽要求,为在资源有限的边缘计算平台训练卷积神经网络提供了基础。
108.为了更加清楚地说明本技术实施例提供的可重构硬件加速器在卷积神经网络的训练过程中的应用,下面通过具体示例进行说明。
109.以较有代表性的vgg卷积神经网络为例,图8示例性示出了vgg网络一个卷积层中的卷积核尺寸、输入特征图尺寸和输出特征图尺寸的结构示意图,如图8所示,输入特征图的尺寸是128
×
56
×
56(channel
×
height
×
width),卷积核的大小是128
×3×
3(channel
×
height
×
width),卷积核的个数是256,每个卷积核在输入特征图上按照设定的步长移动进行卷积计算,得到输出特征图一个通道的结果,256个卷积核计算得到的输出特征图的尺寸
是256
×
56
×
56(channel
×
height
×
width)。
110.由于输入特征图通常尺寸较大且大小不一,可以将输入特征图在高度和宽度两个维度(height
×
width)提前分割为尺寸较为统一的卷积块(block),例如可以将输入特征图分为7个大小为128
×8×
8(channel
×
height
×
width)的卷积块,各个卷积块与卷积核的运算相对独立。下面以128
×8×
8的卷积块和步长为1的128
×3×
3的卷积核在训练的fp阶段的计算为例,说明本技术实施例提供的可重构硬件加速器在卷积神经网络的训练过程中的运算过程。
111.图9示例性示出了卷积块和卷积核在一个通道下的具体值示意图,如图9所示,大小为8
×
8的卷积块与3
×
3的卷积核按步长为1进行卷积,得到大小为6
×
6的卷积计算结果,其中,o
00
=a
00
×w00
a
01
×w01
a
02
×w02
a
10
×w10
…
a
22
×w22
,o
01
=a
01
×w00
a
02
×w01
a
03
×w02
a
11
×w10
…
a
23
×w22
,以此类推,得到输出特征图中各个值。
112.图9中所示的各值都存储在fpga的片上缓存bram(block ram,块随机存取存储器)中,bram可以实现缓存模块的功能,通过第一输入预取模块将卷积核一个通道的9个权重值传输到一个运算处理模块的9个mac的端口1,通过第二输入预取模块将输入特征图中的激活值传输到mac的端口2。
113.图10示例性示出了本应用示例中运算处理模块在fp阶段以步长为1的方式进行卷积运算时内部的具体数据流向示意图,如图10所示,在一个时钟周期内,同一行的3个mac输入的激活值是相同的,激活值与权重值的乘累加的结果通过内部寄存器向后传递,不同行的乘累加结果在后端相加,得到9个权重值(w
ij
)与9个激活值(a
ij
)的乘累加结果。由于运算处理模块内部采用脉动阵列的结构,运算处理模块可以每个时钟周期得到一个结果,这个结果只是卷积核与输入特征图的一个通道的乘累加结果,只是最终卷积结果的一部分,即部分和,这个部分和还需要与其他通道的计算结果进行累加才能得到最终的卷积结果,暂存在部分和fifo队列中。运算处理模块中的9个权重值在输入特征图一个通道的激活值全部传递完成之前保持不变,直到卷积计算转移到输入特征图和卷积核的下一个通道,此时更新运算处理模块中的权重值,同时运算处理模块接收输入特征图下一个通道的激活值,计算结果与部分和fifo队列中取出的部分和进行累加。所有通道的数据累加完成即可得到最终的卷积结果,该结果可经由部分和fifo队列传递到输出缓存中。
114.为了评估本技术实施例提供的可重构硬件加速器的可行性和性能,首先使用cifar-10数据集训练了vgg-like模型,该模型是在vgg模型的基础上,用一个stride=2的卷积层替换一个最大池化层及其后续stride=1的卷积层,以对输入特征图进行下采样。
115.可重构硬件加速器的硬件设计使用verilog hdl实现,并通过vivado 2018.3design suite进行综合,选择xilinxvc709(virtex7 xc7vx690t)作为目标fpga平台,fpga的资源利用率如表1所示。bram资源用于实现片上数据缓冲区,从表1可以看出,运算处理阵列中的mac占用dsp资源最多。
116.表1:fpga的资源利用率
117.资源lutlutramflipflopbramdsp资源占用量171248247041435658962324资源总量43322017420086640014703600占用率39.53%14.18%16.57%60.95%64.56%
118.在200mhz的频率下工作时,本技术实施例提供的可重构硬件加速器实现了771gops的性能和47.38gops/w的能效。表2为本发明与现有技术在性能和能效方面的对比表。
119.表2:本发明与现有技术在性能和能效方面的对比表
[0120][0121]
如表2所示,对比对象1、对比对象2、对比对象3、对比对象4和对比对象5均为现有技术中常用的应用在不同开发平台上的卷积神经网络训练硬件加速器,与采用浮点数运算的对比对象1、对比对象2以及采用定点数运算的对比对象3、对比对象4相比,本发明实现了更高的性能和更好的能效。对比对象5比本发明实现了更高的性能,但同时消耗了更多的功率,本发明的能效优于对比对象5,本发明的优势得益于完整的8位整数训练算法和可以消除冗余操作的可重构架构,同时,双阶段的缩放和舍入方案也减少了片上内存使用和能耗。
[0122]
如此,本技术实施例提供的可重构硬件加速器,通过在不同的训练阶段动态调整运算处理阵列中的每个运算处理模块的内部数据连接方式,以使运算处理模块按移动步长进行与候选训练阶段相对应的卷积运算处理,不仅可以有效避免无效计算,而且各运算处理模块之间可以并行处理,极大地提高了硬件的资源利用效率,此外,利用输入缓存架构按预设数据分组方式对待运算数据进行重新排列和分组后,再发送给运算处理模块进行处理,进一步提高了数据复用率和处理效率,并且将高比特运算结果转换为低比特最终结果的过程分为了分为局部缩放和全局缩放两个阶段,减少了片上缓冲区大小和数据传输的带宽要求,为在资源有限的边缘计算平台训练卷积神经网络提供了基础。整个可重构硬件加速器计算方式较为灵活,可以并行处理多通道运算,而且仅采用硬件架构即可满足不同训练阶段的计算需求,因而具有较高的模型训练效率。
[0123]
以上结合具体实施方式和范例性实例对本技术进行了详细说明,不过这些说明并不能理解为对本技术的限制。本领域技术人员理解,在不偏离本技术精神和范围的情况下,可以对本技术技术方案及其实施方式进行多种等价替换、修饰或改进,这些均落入本技术的范围内。本技术的保护范围以所附权利要求为准。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。