1.本发明涉及人工智能和知识图谱领域,尤其涉及一种基于计算机视觉和知识图谱的辅助方法。
背景技术:
2.计算机视觉在系统中的应用分图像分类和语义分割两大任务。海量数据是完成两大任务的前提与关键。长久以来,卷积神经网络(cnn)凭借优良的特征表达能力成为计算机计算机视觉各项任务的标准配置。然而,transformer在nlp领域横扫千军的战果启发计算机视觉对基础组件的替代。
3.利用cnn进行图像分类,在卷积和上采样的过程中丢失细节信息,即特征图尺寸逐渐变小,所以不能很好地指出物体的具体轮廓、指出每个像素具体属于哪个物体,无法做到精确的分割。
技术实现要素:
4.为了解决以上技术问题,本发明提供了一种基于计算机视觉和知识图谱的辅助方法。摒弃统治已久的cnn,应用并改写transformer结构单元,形成图像和文本处理基于transformer的大一统局面。
5.本发明的技术方案是:
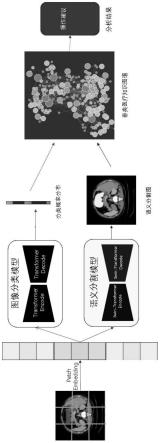
6.一种基于计算机视觉和知识图谱的辅助方法,将自然语言处理技术中的transformer架构应用于计算机视觉中,并改写网络结构,为下游图像分类和图像分割任务提供统一的编解码架构。随后,图像阶段的输出结果输送到知识图谱中,形成分门别类的建议,提供及时准确的辅助决策。
7.进一步的,
8.知识图谱通过前期的数据积累,构建专家知识库,可以将图像模型得到的图像分类和语义分割结果作为输入,完成图搜索匹配,得出图像分析建议。
9.再进一步的,
10.通过大数据技术,构建重大创伤大数据系统,通过对接目前体系下的重大创伤数据、文件系统、hadoop、nosql等各种数据源,快速实现大量库表全量/增量数据同步;面向实时数据,提供高效采集、传输、分发能力,帮助快速构建完备便捷的重大创伤临床数据大数据底座。
11.基于transformer的图像分类任务受self-attention机制启发,在编解码阶段应用multi-head attention,从全局捕获上下文信息,避免cnn堆叠造成的计算量过大、前置偏执归纳等缺陷。通常基于transformer的图像模型需要比基于cnn更多的训练数据,通过大数据湖底座和深度学习gan生成方式使得数据增广,即使在真实影像数据稀缺的情况下就可以学习较好的模型。本发明使用开创性的视觉transformer技术用于图像进行分类,判别程度,在对图像经过patch embedding将视觉问题转化为时序问题,并加入位置编码,输
送到transformer编码单元,此时加入一个特殊的token,该token的输出将预测最终的类别。
12.图像分割模型对图像进行像素级分割,得出患病面积占比数据,本发明改写transformer编解码结构为滑窗式swin-transformer,应用到影像分割网络unet之中,减弱神经网络对数据集的强依赖,降低计算量,得到实时性和精度上的平衡。
13.将人工智能阶段得到的模型输出作为基于数据湖底座构建的知识图谱的输入,通过图匹配机制,得出诊疗建议
14.本发明的有益效果是
15.在人工智能技术方面,图像模型摒弃传统的基于卷积神经网络(cnn),借鉴并改进自然语言处理技术(nlp)中流行的transformer编解码架构,通过专业的创伤训练模型准确实时地得出图像分类和语义分割图,取得速度和精度的平衡,满足系统实时性和高精度要求。知识图谱通过图像分析阶段的结果进行图匹配,精准召回匹配结果。
附图说明
16.图1是本发明的工作流程示意图。
具体实施方式
17.为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例,基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
18.本发明通过大数据湖底座,统一大数据采集标注平台,高效方便地完成图像数据的采集与标注工作。由于影像的稀缺性,本发明使用生成对抗网络(gan)扩充数据集,并使用广泛的数据增强预处理提升模型泛化能力。
19.本发明形成一套闭环解决方案,从数据湖底座完成海量数据的数据采集与数据标注、通过统一图像和文本网络结构为transformer实现精准的模型输出,并提出swin-transformer结构单元,克服数据少的难点,降低模型参数,减少计算量,满足系统实时性要求。以下为各模块设计:
20.1)数据湖底座
21.通过大数据技术,构建重大创伤大数据系统,通过对接目前体系下的重大创伤数据、文件系统、hadoop、nosql等各种数据源,快速实现大量库表全量/增量数据同步;面向实时数据,提供高效采集、传输、分发能力,帮助快速构建完备便捷的重大创伤临床数据大数据底座。
22.2)图像模型
23.基于transformer的图像分类任务受self-attention机制启发,在编解码阶段应用multi-head attention,从全局捕获上下文信息,避免cnn堆叠造成的计算量过大、前置偏执归纳等缺陷。
24.通常基于transformer的图像模型需要比基于cnn更多的训练数据,通过大数据湖底座和深度学习gan生成方式使得数据增广,即使在真实影像数据稀缺的情况下就可以学
习较好的模型。
25.本发明使用开创性的视觉transformer技术用于图像进行分类,判别程度,在对图像经过patch embedding将视觉问题转化为时序问题,并加入位置编码,输送到transformer编码单元,此时加入一个特殊的token,该token的输出将预测最终的类别。
26.图像分割模型对图像进行像素级分割,得出预分析面积的占比数据,本发明改写transformer编解码结构为滑窗式swin-transformer,应用到影像分割网络unet之中,减弱神经网络对数据集的强依赖,降低计算量,得到实时性和精度上的平衡。
27.3)知识图谱
28.将人工智能阶段得到的模型输出作为基于数据湖底座构建的知识图谱的输入,通过图匹配机制,得出结果建议。
29.图像通过patch embedding形成序列输送到模型,得到分类和分割结果,并作为知识图谱的输入,得到最终结果。
30.知识图谱通过前期的数据积累,构建知识库,可以将图像模型得到的图像分类和语义分割结果作为输入,完成图搜索匹配,得出图像分析建议。
31.关于图像分类模型,图像经过patchembedding形成全局均匀大小的patch序列,随后经过linearprojection到目标网络输入维度,后续通过逐层swin-transformerblock获取四阶段全局上下文信息,最后通过averagepooling层获得分类概率。
32.关于图像分割模型。模型整体为u型编解码结构,颜色相同的block输入输出维度相同;transformer单元分阶段捕获全局patch信息;编码阶段的patchmerging单元用于降维,与之对应的patchexpanding在解码阶段升维,便于编解码信息融合;最后通过linearprojection获得逐像素分类。
33.以上所述仅为本发明的较佳实施例,仅用于说明本发明的技术方案,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内所做的任何修改、等同替换、改进等,均包含在本发明的保护范围内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。