1.本发明属于机器视觉领域,具体说是一种基于深度学习的点阵字符识别方法。
背景技术:
2.食品的产品信息很多都是以点阵字符的形式打印在包装上。为了保证食品安全,就必须确保产地、批次、生产日期等生产信息的准确性。食品工厂为了提高自己的产品质量,减少市场投诉,采用人工的方式检测打印信息,存在准确率低、效率差、用工成本高、数据无法跟踪等问题。因此研究一种快速准确的点阵字符识别方法既可以提高产品质量,又可以降低企业成本。
3.目前,对于点阵字符识别方法主要分为三类:基于模板匹配的识别方法、基于机器学习的识别方法和基于深度学习的识别方法。基于模板匹配和支持向量机的点阵字符识别方法,首先进行灰度模板匹配和特征模板匹配,如果匹配结果有差异,再通过svm支持向量机进行判定,得到最终结果,但该方法在背景复杂的情况下表现不理想。基于机器学习的识别方法利用bp神经网络识别字符,在一定程度上提高了复杂背景下字符识别的准确性,但bp神经网络存在学习速度慢、推广能力有限等问题。基于深度学习的识别方法使用卷积神经网络进行字符识别,进一步提高了算法的识别能力,但仍然存在字符分割效果差,过程复杂、耗时长,准确率不高等问题。
4.食品外包装因为褶皱、接缝、打印机性能等原因,点阵字符有可能产生局部形变、模糊、倾斜、或者呈现波浪形,点阵字符的这些特点进一步增加了字符识别的难度,使得一些常用的传统字符识别方法准确率低,适用性差,无法满足用户需求。
技术实现要素:
5.针对上述技术不足,本发明提出了一种基于深度学习的点阵字符识别方法。该方法能够在复杂图案背景下快速准确地识别点阵字符,可以克服背景图案复杂、字符尺寸差别大、字符变形、字体不同等问题,实现速度快、精度高的点阵字符识别。同时提出一种点阵字符生成方法,可以自动生成大量字符数据,扩展了数据集以便于网络训练,实现了基于深度学习点阵字符识别方法的快速应用。
6.本发明为实现上述目的所采用的技术方案是:一种基于深度学习的点阵字符识别方法,包括以下步骤:
7.1)获取喷码机字符字体以及字符大小,通过halcon软件创建点阵序列,并按照点阵序列在新建的背景图像中生成点阵字符图像;
8.2)对点阵字符图像中每个字符图像添加随机弹性形变,得到包含多个字符图像的数据集;
9.3)将每个字符图像作为前景图像与背景图像相融合,得到融合后的图像;
10.4)用融合后的图像建立图像数据集,构建网络训练模型,并根据图像数据集训练网络模型,将待识别图片输入至网络训练模型进行文本检测与识别,得到字符。
11.所述步骤2),具体为:
12.2-1)对于每个字符图像中字符,添加随机弹性形变,通过控制因子β与随机函数,建立随机位移场(pr,pc),即:
13.pr=(rand(1)-0.5)*2*β
ꢀꢀꢀ
(1)
14.pc=(rand(1)-0.5)*2*β
ꢀꢀꢀ
(2)
15.其中,rand(1)为生成一个0-1的随机函数,pr为像素点在行方向的随机偏移量,pc为像素点在列方向的随机偏移量;
16.2-2)通过高斯滤波对图像进行平滑处理,得到最终位移场,即:
[0017][0018]
其中,g
σ
(x)为最终位移场,σ为标准差,x为添加随机弹性形变后像素点横坐标,y为添加随机弹性形变后像素点纵坐标;
[0019]
2-3)通过双线性插值法填充弹性形变后图像中邻域处空缺的像素点后,为字符图像中每一个连通域设置一个相同的偏移量,即:
[0020]
prn=max(pr),pr∈regionr
ꢀꢀꢀ
(4)
[0021]
pcn=max(pc),pc∈regionc
ꢀꢀꢀ
(5)
[0022]
其中,regionr,regionc表示的是第n个黑点区域内所有像素点的偏移量; max(pr)表示取最大值;prn为第n个黑点区域内所有像素点行方向偏移量的最大值,作为第n个黑点的行方向偏移量;pcn为第n个黑点区域内所有像素点列方向偏移量的最大值,作为第n个黑点的列方向偏移量;
[0023]
2-4)对于字符图像发生前倾或后倾情况,则采用下式添加随机前倾或后倾形变:
[0024]
pc=(height-r)*β
ꢀꢀꢀ
(6)
[0025]
其中,pc为列方向偏移量,height为图像高度,r为行向量。
[0026]
所述步骤3),具体为:
[0027]
根据像素点和黑点区域中心的空间位置关系,创建阿尔法通道图像,距离黑点区域中心越近,α越大,前景图像像素所占比例越大,利用阿尔法通道图像对多个字符图像进行图像融合,即:
[0028]gdst
=gc*α gb*(1-α) δ
ꢀꢀꢀ
(7)
[0029]
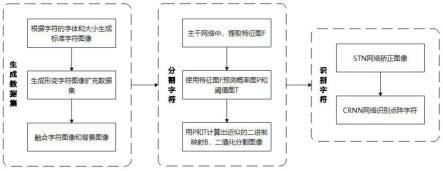
其中,g
dst
为融合后图像,gc为字符图像,α为字符图像的加权系数,gb为背景图像,δ为偏移量。
[0030]
所述构建网络训练模型包括以下步骤:
[0031]
生成每个融合图像时,生成对应的字符目标框,构成图像数据集;采用图像数据集,通过dbnet进行训练,得到训练后的dbnet网络模型;通过dbnet 网络模型对输入图像进行检测,得到字符框的位置,截取字符框区域作为字符框图像;
[0032]
采用字符框图像以及标注的字符所构成的数据集,传入到识别网络,进行训练,得到网络训练模型。
[0033]
步骤4),根据训练模型,对识别图片进行文本检测与识别,得到字符,包括以下步骤:
[0034]
将待识别图片输入至dbnet网络模型,得到分割后的含有字符的字符框图像;
[0035]
将字符框图像输入至识别网络,获取识别网络识别出的字符。
[0036]
所述识别网络,通过以下步骤构建:
[0037]
识别网络主要由顺序连接的cnn和rnn构成,将空间变化网络stn插入到输入的图像和cnn之间,用于将输入的图像进行校正,或者插入到cnn内部用于将特征图进行校正,最终输出为去除随机形变和特定形变的图像或者特征图, rnn对特征序列的每一帧进行预测,并转化为最终的标签字符序列,即最终的识别点阵字符。
[0038]
本发明具有以下有益效果及优点:
[0039]
1.本发明采用dbnet进行文本检测,不仅检测速度更快,而且可以检测到任意形状的点阵字符文本实例;
[0040]
2.本发明通过将空间变化网络stn插入到空间卷积递归神经网络crnn 中,建立新的网络结构,能够实现对点阵字符的精准识别。
[0041]
3.本发明提出了一种合成点阵字符的新方法,和实际生产过程中采集的图像非常相似,可以快速扩展数据集,节省标注时间,以便于网络训练,实现了基于深度学习点阵字符识别方法的快速应用。提出了一种改进crnn点阵字符识别方法,首先采用dbnet进行文本检测,然后综合crnn和stn优点,将stn 插入到crnn完成字符识别。能够在复杂图案背景下快速准确地识别点阵字符,识别准确率可达99.5%。
附图说明
[0042]
图1为本发明的总体方法流程图;
[0043]
图2a为本发明生成的点阵字符图像;
[0044]
图2b为本发明建立的随机向量场;
[0045]
图2c为本发明按照图2b随机向量场进行随机弹性形变的字符图像;
[0046]
图2d为本发明建立的后倾向量场;
[0047]
图2e为本发明按照2d后倾向量场进行后倾形变的字符图像;
[0048]
图3a为本发明的实施例中实际生产过程中采集的图像;
[0049]
图3b为本发明为与图3a不同背景相同字符的图像;
[0050]
图3c为本发明为与图3b相同背景不同字符的图像;
[0051]
图4是本发明的dbnet文本检测流程图;
[0052]
图5是本发明的dbnet文本检测结果;
[0053]
图6为本发明提出深度学习网络识别结果。
具体实施方式
[0054]
下面结合附图及实施例对本发明做进一步的详细说明。
[0055]
本发明各模块关系如图1所示,提出的框架主要包括三个步骤。第一步是生成数据集,第二步是分割字符,第三步是识别字符。
[0056]
本发明具体包括以下步骤:
[0057]
1)获取喷码机字符字体以及字符大小,通过halcon软件创建点阵序列,并按照点阵序列在新建的背景图像中生成点阵字符图像;
[0058]
2)对点阵字符图像中每个字符图像添加随机弹性形变,得到包含多个字符图像的
数据集;
[0059]
3)将每个字符图像作为前景图像与背景图像相融合,得到融合后的图像;
[0060]
4)用融合后的图像建立图像数据集,构建网络训练模型,并根据图像数据集训练网络模型,将待识别图片输入至网络训练模型进行文本检测与识别,得到字符。
[0061]
如步骤1)~步骤3)中,具体步骤如下:
[0062]
步骤1.1,根据需要识别的字符字体和字符大小,生成标准点阵字符图像,如图2a所示。
[0063]
步骤1.2,为了可以更好地近似表示包装凹凸不平等原因产生的形变,添加随机弹性形变,根据公式1、2创建随机位移场,控制因子β与随机位移场相乘,得到位移场(pr,pc),用以控制其变形强度。公式3高斯滤波平滑图像,得到最终的位移场,σ越大,产生的图像越平滑。弹性形变后图像会存在一些位置没有适当的像素值,然后通过双线性插值填充这些像素点,使得图像在邻域处是吻合的。
[0064]
pr=(rand(1)-0.5)*2*β
ꢀꢀꢀ
(1)
[0065]
pc=(rand(1)-0.5)*2*β
ꢀꢀꢀ
(2)
[0066][0067]
其中,rand(1)为生成一个0-1的随机函数,pr为像素点在行方向的随机偏移量,pc为像素点在列方向的随机偏移量,g
σ
(x)为最终位移场,σ为标准差,x为添加随机弹性形变后像素点横坐标,y为添加随机弹性形变后像素点纵坐标;
[0068]
采用上述方法对整幅图像进行弹性形变,常规字符会取得很好的效果,但是对于点阵字符,使用该方法会使打印黑点发生严重畸变,针对上述存在的问题,提出了一种基于改进弹性形变算法的点阵字符自动生产方法,为每一个连通域设置一个相同的偏离量,如公式4、5所示。regionr,regionc表示的是第n个黑点区域内所有像素点的偏移量。这样的随机弹性形变可以很好地近似表示包装凹凸不平等原因产生的形变,图2b随机向量场,图2c是按照图2b随机向量场进行随机弹性形变的字符图像。为了表示字符发生前倾或者后倾的情况,可以添加倾斜形变,为了提高训练效果,可以把特有的形变加入到训练集中,如公式6所示,图2d后倾向量场,图2e是按照2d后倾向量场进行后倾形变的点阵字符图像。这样做不仅增加了数据量,也能更好的模拟实际情况,使生成数据集和真实数据集尽可能的接近。
[0069]
prn=max(pr),pr∈regionr
ꢀꢀꢀ
(4)
[0070]
pcn=max(pc),pc∈regionc
ꢀꢀꢀ
(5)
[0071]
pc=(height-r)*β
ꢀꢀꢀ
(6)
[0072]
其中,regionr,regionc表示的是第n个黑点区域内所有像素点的偏移量; max(pr)表示取最大值;prn为第n个黑点区域内所有像素点行方向偏移量的最大值,作为第n个黑点的行方向偏移量;pcn为第n个黑点区域内所有像素点列方向偏移量的最大值,作为第n个黑点的列方向偏移量,pc为列方向偏移量, height为图像高度,r为行向量。
[0073]
为实现创建贴近实际生产情况的数据集目标,还需要把前景图像和背景图像融合在一起。由于字符图像是通过算法自动生成的,所以在生成字符图像的过程中,根据像素点和最近打印圆心的空间位置关系,创建阿尔法通道图像,利用阿尔法通道图像进行图像融合计算,如公式7所示,生成图像和真实图像高度相似,其中点阵图像添加了随机形变和后
倾形变,取得了非常好的效果。图2b随机向量场,图2c是按照图2b随机向量场进行随机弹性形变的点阵字符图像。为了表示字符发生前倾或者后倾的情况,可以添加倾斜形变,图2d后倾向量场,图2e是按照2d后倾向量场进行后倾形变的点阵字符图像。这样做不仅增加了数据量,也能更好的模拟实际情况,使生成数据集和真实数据集尽可能的接近。
[0074]gdst
=gc*α gb*(1-α) δ
ꢀꢀꢀꢀ
(7)
[0075]
其中,g
dst
为融合后图像,gc为字符图像,α为字符图像的加权系数,gb为背景图像,δ为偏移量。
[0076]
步骤1.3,在准备好字符图像,也就是前景图像之后,采集食品外包装图像作为背景图像,然后把前景图像和背景图像融合在一起。由于字符图像是通过算法自动生成的,所以在生成字符图像的过程中,根据像素点和最近打印圆心的空间位置关系,创建阿尔法通道图像,利用阿尔法通道图像进行图像融合计算。融合图像结果如图3所示,图3a是实际生产过程中采集的图像,生成的图 3b是和图3a不同背景相同字符的图像,生成的图3c是和图3b相同背景不同字符的图像。从图3中可以看到,生成图像和真实图像高度相似,取得了非常好的效果。因此采用生成数据集训练的模型可以完美适用于实际生产过程。
[0077]
在步骤2中,采用dbnet进行文本检测,具体为:
[0078]
构建网络训练模型包括以下步骤:
[0079]
生成每个融合图像时,生成对应的字符目标框,构成图像数据集;采用图像数据集,通过dbnet进行训练,得到训练后的dbnet网络模型;通过dbnet 网络模型对输入图像进行检测,得到字符框的位置,截取字符框区域作为字符框图像;
[0080]
采用字符框图像以及标注的字符所构成的数据集,传入到识别网络,进行训练,得到训练好的识别网络。
[0081]
dbnet网络模型通过结合一个简单的语义分割网络和所提出的db模块,提出了一个鲁棒、快速的场景文本检测器。db模块的目的是将二值化操作插入到一个分割网络中,以进行联合优化。然而标准的二值化函数是不可微的,公式8所示是一个可微的二值化(db)模块,将标准二值化进行近似,使其可导,融入训练,从而获取更准确的边界,大大降低了后处理的耗时。在场景文本的多个标准数据集上取得了更好的效果,包括各种不同形状的文本,同时效率也要快得多。
[0082][0083]
其中,k是膨胀因子,p
i,j
是指概率图的像素点,t
i,j
是指阈值图的像素点,b
i,j
是指二值化图的像素点;
[0084]
4-1)对融合后的图像提取特征图f:将融合后的图像输入至特征金字塔主干网络中,将金字塔特征上采样到相同的尺度,并进行级联生成特征f。
[0085]
首先将图像输入到一个具有fpn结构的resnet50_vd的主干网络中,提取特征图,然后顶层特征上采样和底层特征融合,再上采样到1/4,最后将得到所有1/4特征图进行融合,得到特征图f,如图4所示。
[0086]
4-2)通过特征图f预测概率图p和阈值图t,即:深度学习一般分为三步,第一步,准备数据集,第二部建立自己的网络,第三步训练自己的模型。现在我们利用数据集已经训练好模型了,这里介绍的是适用过程,输入图像,提取特征,训练好的网络预测概率图p和阈值
图t。
[0087]
然后使用特征图f预测概率图p和阈值图t,最后用p和t计算出近似的二进制映射(b)。在训练阶段:对p、t、b进行监督训练,p和b是用的相同的监督信号。在推理阶段,通过p或b就可以得到文本框。图5是本文算法的检测结果,可以看出,算法克服了背景复杂图案和文字的干扰,准确地检测出待识别字符的具体位置。
[0088]
4-3)并根据概率图p和阈值图t获取二进制映射b,如公式8所示,当 p
i,j
》t
i,j
时,b
i,j
≈1,认为该像素点是目标,当p
i,j
《t
i,j
时,b
i,j
≈0,认为该像素点是背景。
[0089]
在步骤4)中,将空间变化网络stn插入到空间卷积递归神经网络crnn 中,建立新的网络结构,具体为:
[0090]
识别网络主要由顺序连接的cnn和rnn构成,将空间变化网络stn插入到输入的图像和cnn之间,用于将输入的图像进行校正,或者插入到cnn内部用于将特征图进行校正,最终输出为去除随机形变和特定形变的图像或者特征图,rnn对特征序列的每一帧进行预测,并转化为最终的标签字符序列,即最终的识别点阵字符。
[0091]
crnn字符识别网络集成了卷积神经网络(cnn)和递归神经网络(rnn)的优点,与传统方法以及其他基于cnn和rnn的算法相比,crnn具有更优越的性能,在文本识别获得了广泛的应用,在很多数据集上有着出色的表现。crnn 关键技术包括三部分:利用cnn提取图像卷积特征;利用深层双向lstm网络,在卷积特征的基础上继续提取文字序列特征;利用ctc(connectionist temporalclassification)解决训练时字符无法对齐的问题。
[0092]
常规字符作为一个整体,它的所有区域是一个连通域,在学习的过程中,更容易被当作一个字符。但是点阵字符是由多个孤立的点组成,尤其当存在倾斜或者弹性形变的时候,容易产生误分割和误识别,所以本发明利用stn的优点,先进行图像矫正,再提取特征识别字符。
[0093]
stn空间变换网络具有以下优点:可以插入到任何现有的卷积结构中;无监督训练,神经网络能够根据特征图本身的特点,主动地对特征图进行空间转换。空间变换网络会使模型具有学习空间变换不变性(包括平移、缩放、旋转和扭曲变形)的能力,提升神经网络性能。stn空间变换网络主要分为三部分:参数预测,根据特征图本身的特点,生成变换参数θ;坐标映射,利用上一步得到的变换参数计算像素点坐标的对应关系;像素采样计算,利用双线性插值方法,计算输出特征图每个坐标点的像素值。
[0094]
为了清楚的解释这个网络,假设空间变换只包含仿射变换。在线性代数里,图像的平移h(t),旋转h(θ)和缩放h(s)这些仿射变换都可以用矩阵运算来表示,如公式9、10所示。经过计算得到矩阵h,其中ε={ω
11
,ω
12
,ω
13
,ω
21
,ω
22
,ω
23
}中的这6个变量就是用来映射输入图和输出图之间的坐标点的关系的参数。
[0095][0096][0097]
公式11表示的是grid generator过程,计算像素点坐标的对应关系。
[0098][0099]
其中,为输入特征图像素点的坐标,为输出特征图像素点的坐标。
[0100]
公式12表示的是sample过程,是输入特征图在位置标(n,m)处c通道的像素值,是输出特征图在位置处c通道的像素值。使用双线性插值方法,计算输出特征图v。
[0101][0102][0103]
其中,i为像素点序号,c为通道序号,是输入特征图在位置(n,m)处c 通道的像素值,是输出特征图在位置处c通道的像素值,对应到输入特征图处c通道的像素值,由于坐标都是整数,在输入特征图中无对应点,所以按照双线性插值方法,搜索满足条件的点(n,m),计算最终像素值。
[0104]
结合stn和crnn的特性,本发明把stn插入到crnn中,输入图像经过stn矫正形变,主干网络提取特征,传入循环层,使用双向rnn(blstm) 对特征序列进行预测,对序列中的每个特征向量进行学习,并输出预测标签分布,最后传给转录层,使用ctc损失,把从循环层获取的一系列标签分布转换成最终的标签序列。
[0105]
综上,具备识别速度快,精度高等优点,并且针对背景图案复杂、字符大小和字体不一致等复杂问题表现优异。主要步骤包含:提出一种合成点阵字符的新方法,该方法可以在不需要标注和数据集的情况下,人工合成大量的数据集和标注文件,对于一种新的产品可以快速应用,解决数据集匮乏的问题;采用dbnet进行点阵字符文本检测,不仅运行速度快,而且可以检测到任意形状的点阵字符文本实例;通过将空间变化网络stn插入到空间卷积递归神经网络 crnn中,建立新的网络结构,能够实现对点阵字符的精准识别,在保证效率的同时,达到了很高的精度。
[0106]
以上所述仅为本发明的实施方式,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内所作的任何修改、等同替换、改进、扩展等,均包含在本发明的保护范围内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。