一种基于mic结合余弦相似度的原发性肝癌精准化疗hbv再激活预测方法
技术领域
1.本发明属于计算机和医学技术领域,具体为一种基于mic结合余弦相似度的原发性肝癌精准化疗hbv再激活预测方法。
背景技术:
2.原发性肝癌(primary liver cancer,plc)是一种较为常见恶性肿瘤,其中大部分plc与乙肝病毒(hepatitis b virus,hbv)相关。患者临床发现时多已为晚期,仅有约10%左右能手术切除,大部分患者需要保守治疗。精确化疗是保守治疗常用手段,局部照射能有效摧毁肝癌病灶,患者本身又能通过代偿来修复肝损伤。然而,化疗会除了会引发诸多并发症外,还会引起hbv再激活。目前,尚不清楚plc患者化疗后发生hbv再激活的诱因,正确诊断与分析化疗后发生hbv再激活状态是临床及化疗医生面临的重要任务之一。
技术实现要素:
3.发明目的:为正确诊断与分析出plc患者化疗后发生hbv再激活的诱因,本发明公开了一种基于mic结合余弦相似度的原发性肝癌精准化疗hbv再激活预测方法,提出最大信息系数结合余弦相似度(mic-cs)算法对hbv再激活进行关键因子选择,并结合机器学习分类器对原发性肝癌精准化疗后hbv再激活状态进行预测。
4.技术方案:一种基于mic结合余弦相似度的原发性肝癌精准化疗hbv再激活预测方法,包括以下步骤:
5.步骤1:采集num名接受精准化疗的肝癌患者的临床资料作为研究数据,获取影响患者hbv再激活的n个潜在因子;依据精准化疗后hbv是否再激活对接受精准化疗的肝癌患者添加标签,所述标签包括hbv已激活和hbv未激活;依据潜在因子和患者标签,构建原始数据集d{f1,f2,...,fi,...,fn,l},其中,fi表示具备第i个潜在因子的所有患者的指标数据集合,i=1,2,...,n;l为患者标签;
6.步骤2:计算原始数据集d{f1,f2,...,fi,...,fn,l}中各潜在因子与患者标签之间的最大信息系数,记为mic(fi,l);
7.步骤3:采用余弦相似度算法,计算原始数据集d{f1,f2,...,fi,...,fn,l}中各潜在因子间的余弦相似度;
8.步骤4:利用根据最大信息系数和各潜在因子间的余弦相似度构建的评价函数,表示为:
[0009][0010]
式中,k表示已选子集,similarity
normal
()表示潜在因子间的余弦相似度;fk表示具备第k个潜在因子的所有患者的指标数据集合;
[0011]
利用评价函数,计算原始数据集d{f1,f2,...,fi,...,fn,l}中各潜在因子的评价
值,并基于评价值对原始数据集d{f1,f2,...,fi,...,fn,l}中的潜在因子进行排序,筛选出关键因子集合;
[0012]
步骤5:采用关键因子集合中各关键因子及患者标签,对支持向量机进行训练,并通过对支持向量机中的参数进行调整,得到最终可用的分类模型;
[0013]
步骤6:将待预测的关键因子输入至最终可用的分类模型中,得到肝癌患者接受放疗后,hbv是否激活的预测结果。
[0014]
进一步的,步骤2具体包括:
[0015]
在二维坐标系中,通过在x轴方向划分x份、在y轴方向划分y份,构建得到网格g,原始数据集d{f1,f2,...,fi,...,fn,l}中的fi和l构成坐标点(fi,l),坐标点(fi,l)依次落在网格g中;根据式(1),计算原始数据集d{f1,f2,...,fi,...,fn,l}中每个潜在因子与患者标签之间的互信息:
[0016]
i((fi;l),x,y)=maxi((fi;l)|g)
ꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0017]
式中,i((fi;l),x,y)表示fi和l在网格(x,y)上的互信息,(fi;l)|g表示坐标点(fi;l)在网格g中的分布,坐标点(fi;l)在网格g中的分布由坐标点(fi;l)中的数据落在每个小网格内的概率决定,i((fi;l)|g)表示(fi;l)|g的互信息,x和y取不同的值,表示不同的网格g划分方案;
[0018]
将i((fi;l),x,y)除以log2(min(x,y)),完成对i((fi;l),x,y)的归一化处理:
[0019][0020]
给定多组(x,y),计算每组(x,y)下的m(fi;l)
(x,y)
的值,将所有m(fi;l)
(x,y)
中的最大值作为潜在因子与患者标签之间的最大信息系数mic(fi;l):
[0021][0022]
式中,b(num)是关于num的函数。
[0023]
进一步的,步骤3具体包括:
[0024]
对原始数据集d{f1,f2,...,fi,...,fn,l}中各潜在因子根据式(4)进行余弦变换:
[0025][0026]
式中,f(i)为fi的元素,ct(u)为经过余弦变换后的系数,u是用来补偿余弦变换时的系数,以实现变换后的矩阵为正交矩阵。
[0027]
经过余弦变换后,特征因子的大部分信息都集中上部区域,因此需要对余弦变换后的潜在因子进行采样,采样区域大小为num/4,得到高频分量;
[0028]
计算采样区域内的均值,将大于均值的高频分量置为1,小于均值的高频分量置为0,以此构建潜在因子的hash指纹;
[0029]
计算不同潜在因子的hash指纹间的距离,并将不同潜在因子的hash指纹间的距离与采样大小的比值作为各潜在因子间的余弦相似度。
[0030]
进一步的,所述的潜在因子的hash指纹,表示为:
[0031][0032]
式中,sample为采样大小,means()为采样区域内的均值。
[0033]
进一步的,所述的各潜在因子间的余弦相似度,表示为:
[0034][0035]
式中,distance(xor(hash1,hash2))为指纹hash1和指纹hash2异或后的汉明距离;sample为采样大小。
[0036]
有益效果:本发明与现有技术相比,具有以下优点:
[0037]
(1)本发明解决了医学数据中面临的高维不平衡问题,通过对hbv再激活数据进行特征选择,发掘出关键因子以提高分类任务的精度;
[0038]
(2)本发明抛开传统的统计学分析方法,提出mic-cs算法,将基于信息策略的特征选择方法用于hbv再激活数据的分析中,挖掘出与hbv再激活相关的关键因子。最后结合svm策略进行分类,构建预测模型,在预测hbv再激活精度,对比多个分类器,分类的准确率最高达到84%,auc值达到0.71,这在一定程度上能够辅助医生治疗plc;筛选出的关键因子包括hbv baseline,外放边界,tnm,kps评分,vd,afp,child-pugh等。上述危险因子都能在plc化疗时引起hbv的再激活。整体上看效果更好,实用性强,易于推广;
[0039]
(3)本发明将最大信息系数结合余弦相似度,比只使用信息度量准则的模型具有更好的分类性能;该方法可以对肝癌精准化疗后hbv再激活状态进行预测,及早进行预防治疗,实用性较强。
附图说明
[0040]
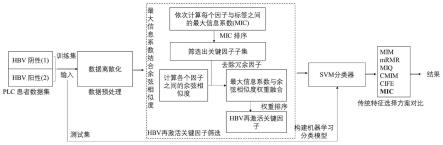
图1为本发明的模型图;
[0041]
图2为最大信息系数筛选出的潜在因子;
[0042]
图3为余弦相似度计算过程示意图;
[0043]
图4为潜在因子与标签之间的关联图;
[0044]
图5为实验结果混淆矩阵;
[0045]
图6为实验结评价指标对比图。
具体实施方式
[0046]
现结合附图和实施例进一步阐述本发明的技术方案。
[0047]
为了找出影响hbv再激活的关键因子,本实施例提出了一种基于mic结合余弦相似度的原发性肝癌精准化疗hbv再激活预测方法,将最大信息系数结合余弦相似度进行特征选择并结合分类器完成分类预测,其主要包括以下步骤:
[0048]
步骤1:采集接受精准化疗的肝癌患者的临床资料作为研究数据,获取能够影响患者hbv再激活的潜在因子,在本实施例中,从医院采集90例接受了精准化疗的plc患者的临床资料作为研究数据。其中,患者年龄在30~74岁,hbv再激活与hbv未激活的患者数量分别为20人和70人。获取每个患者的性别、年龄、kps评分、hbeag、dna水平、化疗剂量等30种信
息,将其作为hbv再激活的潜在因子,也就是说每名患者共计30个潜在因子。详细信息见表1所示。
[0049]
表1 hbv再激活潜在因子的描述
[0050]
[0051][0052]
表1中,vd表示超过一定剂量d的体积占正常肝体积的比值。依据精准化疗后hbv是否再激活对接受精准化疗的肝癌患者添加标签l,该标签l包括hbv已激活和hbv未激活两个类别;
[0053]
设fi为具备第i个潜在因子的所有患者的指标数据集合,本实施例共收集90个患者,即每个f均包括90个患者的指标数据,i=1,2,...,n,n为收集的潜在因子个数,此处n=30,构建得到数据集d{f1,f2,...,fi,...,fn,l};按交叉验证的倍数关系,将数据集d{f1,f2,...,fi,...,fn,l}分为训练数据集和测试数据集;例如5倍交叉验证,则将90例患者样本分成5份,其中训练数据占其中4份,测试数据为1份。
[0054]
步骤2:对数据集d{f1,f2,...,fi,...,fn,l}中的数据进行预处理:不同潜在因子之间量纲差异巨大,为了消除不同潜在因子之间的量纲影响,需要对潜在因子进行归一化处理,使得不同hbv再激活潜在因子之间具有可比性。同时为了计算各个潜在因子与患者标签之间的关联关系,需要对连续特性的潜在因子进行离散化处理。针对表1中具有连续特性的潜在因子,采用离差标准化方法将潜在因子的特征值映射到0~1之间。同时使用距离离散化对连续特性的潜在因子进行离散化处理。
[0055]
步骤3:对经过数据预处理后的潜在因子进行数据编码,具体操作包括:
[0056]
在二维坐标系中,通过在x轴方向划分x份、在y轴方向划分y份,构建得到网格g,原始数据集d{f1,f2,...,fi,...,fn,l}中的fi和l构成坐标点(fi,l),坐标点(fi,l)依次落在网格g中;根据式(1),计算原始数据集d{f1,f2,...,fi,...,fn,l}中每个潜在因子与患者标签之间的互信息:
[0057]
i((fi;l),x,y)=maxi((fi;l)|g)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0058]
式中,i((fi;l),x,y)表示fi和l在网格(x,y)上的互信息,(fi;l)|g表示坐标点(fi;l)在网格g中的分布,坐标点(fi;l)在网格g中的分布由坐标点(fi;l)中的数据落在每个小网格内的概率决定,i((fi;l)|g)表示(fi;l)|g的互信息,x和y取不同的值,可以得出多
种不同的网格化方案,比较哪种方案得到的互信息值最大,即为(x,y)取值下的最大互信息值。
[0059]
为了保证度量的公平性,将i((fi;l),x,y)除以log2(min(x,y)),完成对i((fi;l),x,y)的归一化处理,归一化到0和1之间:
[0060][0061]
给定多组(x,y),计算每组(x,y)下的m(fi;l)
(x,y)
的值,将所有m(fi;l)
(x,y)
中的最大值作为潜在因子与患者标签之间的最大信息系数mic(fi;l):
[0062][0063]
式中,b(num)是关于num的函数,num为患者数量。设经验值为b(num)=num
0.6
,即网格搜索的上界。
[0064]
hbv再激活潜在因子和患者标签之间的最大信息系数体现了hbv再激活潜在因子与患者标签的关联程度。
[0065]
步骤4:如图2所示,只依据hbv再激活潜在因子与患者标签之间的最大信息系数,只能分析出关联特征因子,并不能去除冗余潜在因子间。为了判断各个潜在因子之间的冗余,需要重新度量各个潜在因子间的关联程度。初始数据集中的潜在因子既有离散特性的潜在因子,也有连续特性的潜在因子,很难使用信息度量准则去除冗余。为解决这一问题,本实施例使用余弦相似度分析不同潜在因子间的相似关系,即利用余弦相似度方法计算各潜在因子间的余弦相似度,找出相似的潜在因子,以此为依据去除潜在因子中的冗余潜在因子。余弦相似度的计算过程可图3所示,具体包括:
[0066]
对原始数据集d{f1,f2,...,fi,...,fn,l}中各潜在因子根据式(4)进行余弦变换:
[0067][0068]
式中,f(i)为fi的元素,ct(u)为经过余弦变换后的系数,u是用来补偿余弦变换时的系数,以实现变换后的矩阵为正交矩阵。
[0069]
经过余弦变换后,特征因子的大部分信息都集中上部区域,因此需要对余弦变换后的潜在因子进行采样,采样大小为num/4,得到高频分量;
[0070]
计算采样区域内的均值,将大于均值的高频分量置为1,小于均值的高频分量置为0,以此构建潜在因子的hash指纹,表示为:
[0071][0072]
式中,sample为采样大小,means()为计算区域内的平均数。
[0073]
计算不同潜在因子的hash指纹间的距离,并将不同潜在因子的hash指纹间的距离与采样大小的比值作为各潜在因子间的余弦相似度,表示为:
[0074][0075]
式中,distance(xor(hash1,hash2))为指纹hash1和指纹hash2异或后的汉明距离;sample为采样大小。
[0076]
步骤5:结合最大信息系数和不同潜在因子间的相似度,对关联特征因子集中的关联特征因子进行排序,筛选出最能影响hbv再激活的关键因子;
[0077]
无论是判断潜在因子与患者标签之间的相关性上还是判断潜在因子与潜在因子之间的冗余度上,都依赖信息度量准则。而信息度量需要离散化特征变量,这一过程会丢失很多信息影响效果。为此使用相似度结合最大信息系数作为潜在因子与患者标签之间的评价函数,分析潜在因子与患者标签之间的关联关系。
[0078]
参考公式7依次计算特征因子与标签之间的mic-cs权重,也称之为评价值,根据计算出来的评价值对潜在因子进行排序,筛选出最能影响hbv再激活的关键因子;
[0079][0080]
式中,k表示已选关键特征子集,similarity
normal
()表示潜在因子间的余弦相似度;fk表示具备第k个潜在因子的所有患者的指标数据集合。
[0081]
本实施例在对原始数据集中的潜在因子进行排序和筛选后,选择前8个关键因子进行分类实验。
[0082]
为了直观展示不同关键因子与患者标签之间的联系,本实施例使用散点图显示潜在因子与标签之间的关系,详见图4。
[0083]
步骤6:采用关键因子集合中各关键因子及患者标签,对支持向量机进行训练,并使用3折交叉验证,验证关键因子对hbv再激活的影响,实验结果的混淆矩阵见附图5所示,得到最终可用的分类模型;
[0084]
步骤7:将待预测的关键因子输入至最终可用的分类模型中,得到肝癌患者接受放疗后,hbv是否激活的预测结果。通过实验分析得出,hbv再激活与hbv baseline、化疗时的外放边界、vd(超过一定剂量d的体积占正常肝体积的比值)、总化疗剂量等因素密切相关。在3,5,10倍交叉验证中,使用svm分类器,分类精度最高达到84%,auc最高为0.71。由此可以得出,mic结合相似度能够有效挖掘出hbv再激活的潜在因子,在plc化疗时可以对化疗剂量提供参考。
[0085]
为进一步验证本发明的优势,依次对比了几种较为常见的基于信息度量准则的特征选择方法如mrmr、cmim、miq等进行对照分析。对比了不同方法下的分类结果,通过对比灵敏度和特异性验证方法优势。结果见附图6所示。由图可见最大信息系数结合相似度的特征选择方案要优于其它方案。
[0086]
本实施例通过利用最大信息系数结合相似度策略获得能够影响hbv再激活危险因子,然后利用svm策略对plc患者数据进行分类预测,提出了一种基于最大信息系数的原发性肝癌精准化疗hbv再激活预测方法,产生较好分类效果。不同于医学统计学方法,实验结果比其它特征选择方法进行的预测有很大提高,实用性较强,易于推广。
[0087]
以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛
盾,都应当认为是本说明书记载的范围。
[0088]
以上所述实施例仅表达了本技术的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本技术构思的前提下,还可以做出若干变形和改进,这些都属于本技术的保护范围。因此,本技术专利的保护范围应以所附权利要求为准。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。