1.本发明属于语种分类识别领域,尤其涉及一种混杂语种分类识别方法、装置、存储介质及终端设备。
背景技术:
2.目前,语音评测系统的流程如下:首先进行前处理,然后通过语种分类器进行语种分类,最后通过评测分类器进行评测分类。
3.语音评测涉及多种题型,如段落朗读,口头翻译,以及开放式表达等,对于非母语表达者表达能力较弱时,时常会表现出母语与目标语言的混杂情况,而由于评测系统中语种分类器的分类方法通常是由单一目标语种数据训练实现,这就会在对目标语言评测时引入语种噪声,由于不同语种音素间的相似性,语种噪声很难被单一语种数据训练的评测模型识别,恶化性能,进而导致语音评测的不准确。
技术实现要素:
4.本发明目的是为了克服现有技术的不足而提供一种实现对混杂语种进行快速精准的语种分类识别预测,便于后续进行语音评测的混杂语种分类识别方法、装置、存储介质及终端设备。
5.为达到上述目的,本发明采用的技术方案是:一种混杂语种分类识别方法,包括如下步骤:
6.判断每帧待识别音频信号是否为语音帧;
7.对每条音频的所有语音帧提取fbank特征;
8.将fbank特征输入到多语种语音识别模型后,提取conformer层的输出特征;
9.将conformer层的输出特征作为每帧对应的bn特征输入多语种分类模型中,得到最终的语种分类预测结果。
10.进一步的,所述多语种语音识别模型基于如下训练方法获取:
11.获取训练样本,训练样本为音频及其对应的参考文本;
12.对每条音频的所有语音帧提取fbank特征;
13.将fbank特征输入conformer结构中获得bn特征;
14.利用全连接层和ctc对多语种语音识别模型的参数进行更新优化。
15.进一步的,所述多语种分类模型基于如下训练方法获取:
16.获取训练样本,训练样本为音频及其对应的语种类别标签;
17.对每条音频的所有语音帧提取fbank特征;
18.将fbank特征输入conformer结构中获得bn特征;
19.将t*n的bn特征输入到3个连续tdnn block中,每个tdnn block输出t*m的特征,将3个t*m的特征拼接得到t*(3*m)的特征,再经过fc层,relu层和batchnorm层,输出t*m的特征f,其中,t为帧数,n为输入特征维数;
20.将t*m的特征f输入到pooling中,计算t帧的均值和方差,将均值和方差拼接,得到1*(2*m)的特征;
21.将1*(2*m)的特征输入到fc层和softmax层,获得1
×
c的语种类别预测向量,其中,c为语种类别数;
22.结合语种类别标签计算ce loss的损失,更新多语种分类模型的参数。
23.进一步的,
24.若已知测试音频只属于一个语种:
25.则将整条音频的bn特征输入到语种分类模型中,输出1
×
c的语种类别预测向量,将概率最大的那维向量对应的语种类别作为最终预测结果;
26.若已知测试音频包含多个语种:
27.取窗长为w帧,窗移为s帧,每次取w帧bn特征输入到语种分类模型,输出1
×
c的语种类别预测向量,将概率最大的那维向量对应的语种类别作为该窗语音帧的预测结果;
28.假设两个相邻窗的语种分别为a和b,若a和b相同,则这两个窗的所有帧都属于语种a;若a和b不同,则将两个窗重叠部分的帧均分给两个语种。
29.一种混杂语种分类识别装置,包括:
30.判断模块,用于判断每帧待识别音频信号是否为语音帧;
31.提取模块,用于对每条音频的所有语音帧提取fbank特征;
32.输出模块,用于将fbank特征输入到多语种语音识别模型后,提取conformer层的输出特征;
33.预测模块,用于将conformer层的输出特征作为每帧对应的bn特征输入多语种分类模型中,得到最终的语种分类预测结果。
34.一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,其所述计算机程序被处理器执行时实现所述的混杂语种分类识别方法。
35.一种终端设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现混杂语种分类识别方法。
36.由于上述技术方案的运用,本发明与现有技术相比具有下列优点:
37.本发明方案的一种混杂语种分类识别方法、装置、存储介质及终端设备,通过将待识别音频中提取的fbank特征输入到多语种语音识别模型后提取conformer层的输出特征,将conformer层的输出特征作为bn特征输入多语种分类模型中,最终能能够快速有效的预测出语种的分类,不会被其它噪声干扰,从而快速精准地得到的语种分类,便于后续的语音评测。
附图说明
38.下面结合附图对本发明技术方案作进一步说明:
39.图1为本发明一实施例的混杂语种分类识别方法的流程示意图;
40.图2为本发明一实施例中多语种语音识别模型训练方法的流程示意图;
41.图3为本发明一实施例中多语种分类模型训练方法的流程示意图。
具体实施方式
42.下面结合附图及具体实施例对本发明作进一步的详细说明。
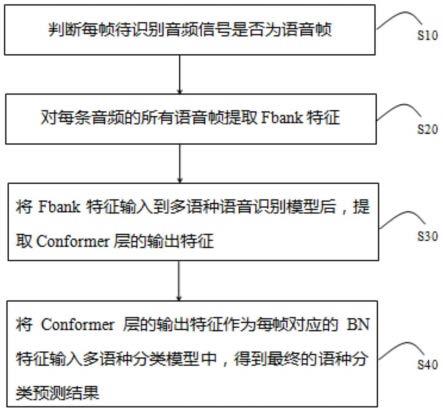
43.参阅图1,本发明一实施例所述的一种混杂语种分类识别方法,包括如下步骤:
44.步骤s10、判断每帧待识别音频信号是否为语音帧;
45.步骤s20、对每条音频的所有语音帧提取fbank特征;
46.步骤s30、将fbank特征输入到多语种语音识别模型后,提取conformer层的输出特征;
47.步骤s40、将conformer层的输出特征作为每帧对应的bn特征输入多语种分类模型中,得到最终的语种分类预测结果。
48.参阅图2,具体的,多语种语音识别模型是为了提取conformer层的输出特征后输入多语种分类模型中,本实施例中的多语种语音识别模型是基于如下训练方法获取:获取训练样本,训练样本为音频及其对应的参考文本;模型结构使用端到端框架,采用conformer(convolution-augmented transformer)结构,结合全连接层和ctc对多语种语音识别模型的参数进行更新优化,其中模型的输入为训练样本得到的fbank特征,输出为多个语种的子词单元集合。
49.对于每个语种,利用各自文本语料训练bpe(byte pair encoding)模型,从而得到每个语种的子词单元;将多个语种的子词单元合并,作为模型输出单元集合。
50.参阅图3,多语种分类模型基于如下训练方法获取:获取训练样本,训练样本为音频及其对应的语种类别标签,训练样本中一条音频只对应一个语种类别;对每条音频的所有语音帧提取fbank特征;将fbank特征输入到多语种语音识别模型后,提取conformer层的输出特征。
51.将conformer层的输出特征作为每帧对应的bn特征,tdnn block为包括tdnn层,relu激活层,batchnorm层的结构;将t*n的bn特征输入到3个连续tdnn block中,每个tdnn block输出t*m的特征,将3个t*m的特征拼接得到t*(3*m)的特征,再经过fc层,relu层和batchnorm层,输出t*m的特征f,其中,t为帧数,n为输入特征维数。
52.将t*m的特征f输入到pooling中,计算t帧的均值和方差,将均值和方差拼接,得到1*(2*m)的特征。
53.将1*(2*m)的特征输入到fc层和softmax层,获得1
×
c的语种类别预测向量,其中,c为语种类别数。
54.结合语种类别标签计算ce loss的损失,更新多语种分类模型的参数。
55.另外,在步骤40中,将conformer层的输出特征作为每帧对应的bn特征输入多语种分类模型中,得到最终的语种分类预测结果,得到最终的语种分类预测结果的具体方式如下:
56.若已知测试音频只属于一个语种:则将整条音频的bn特征输入到语种分类模型中,输出1
×
c的语种类别预测向量,将概率最大的那维向量对应的语种类别作为最终预测结果。
57.若已知测试音频包含多个语种:则取窗长为w帧,窗移为s帧,每次取w帧bn特征输入到语种分类模型,输出1
×
c的语种类别预测向量,将概率最大的那维向量对应的语种类别作为该窗语音帧的预测结果;假设两个相邻窗的语种分别为a和b,若a和b相同,则这两个
窗的所有帧都属于语种a;若a和b不同,则将两个窗重叠部分的帧均分给两个语种。
58.本发明中,通过将待识别音频输入到多语种语音识别模型获得conformer层的输出特征,将conformer层的输出特征作为每帧对应的bn特征输入多语种分类模型中,能够快速有效的预测出语种的分类,不会被其它噪声干扰,从而快速精准的得到的语种分类,便于后续的语音评测。
59.基于上述任一实施例,本发明提供一种混杂语种分类识别装置,包括:
60.判断模块,用于判断每帧待识别音频信号是否为语音帧;
61.提取模块,用于对每条音频的所有语音帧提取fbank特征;
62.输出模块,用于将fbank特征输入到多语种语音识别模型后,提取conformer层的输出特征;
63.预测模块,用于将conformer层的输出特征作为每帧对应的bn特征输入多语种分类模型中,得到最终的语种分类预测结果。
64.另一方面,本发明还提供一种计算机程序产品,所述计算机程序产品包括存储在非暂态计算机可读存储介质上的计算机程序,所述计算机程序包括程序指令,当所述程序指令被计算机执行时,计算机能够执行上述各方法所提供的语种识别方法,该方法包括:判断每帧待识别音频信号是否为语音帧;对每条音频的所有语音帧提取fbank特征;将fbank特征输入到多语种语音识别模型后,提取conformer层的输出特征;将conformer层的输出特征作为每帧对应的bn特征输入多语种分类模型中,得到最终的语种分类预测结果。
65.又一方面,本发明还提供一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现以执行上述各提供的语种识别方法,该方法包括:判断每帧待识别音频信号是否为语音帧;对每条音频的所有语音帧提取fbank特征;将fbank特征输入到多语种语音识别模型后,提取conformer层的输出特征;将conformer层的输出特征作为每帧对应的bn特征输入多语种分类模型中,得到最终的语种分类预测结果。
66.以上仅是本发明的具体应用范例,对本发明的保护范围不构成任何限制。凡采用等同变换或者等效替换而形成的技术方案,均落在本发明权利保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。