技术特征:
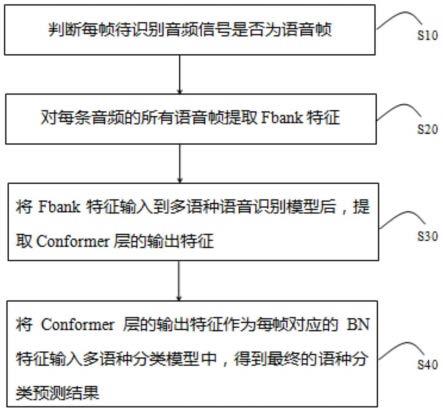
1.一种混杂语种分类识别方法,其特征在于,包括如下步骤:判断每帧待识别音频信号是否为语音帧;对每条音频的所有语音帧提取fbank特征;将fbank特征输入到多语种语音识别模型后,提取conformer层的输出特征;将conformer层的输出特征作为每帧对应的bn特征输入多语种分类模型中,得到最终的语种分类预测结果。2.如权利要求1所述的混杂语种分类识别方法,其特征在于,所述多语种语音识别模型基于如下训练方法获取:获取训练样本,训练样本为音频及其对应的参考文本;对每条音频的所有语音帧提取fbank特征;将fbank特征输入conformer结构中获得bn特征;利用全连接层和ctc对多语种语音识别模型的参数进行更新优化。3.如权利要求1所述的混杂语种分类识别方法,其特征在于,所述多语种分类模型的基于如下训练方法获取:获取训练样本,训练样本为音频及其对应的语种类别标签;对每条音频的所有语音帧提取fbank特征;将fbank特征输入到多语种语音识别模型后,提取conformer层的输出特征;将conformer层的输出特征作为每帧对应的bn特征;将t*n的bn特征输入到3个连续tdnn block中,每个tdnn block输出t*m的特征,将3个t*m的特征拼接得到t*(3*m)的特征,再经过fc层,relu层和batchnorm层,输出t*m的特征f,其中,t为帧数,n为输入特征维数;将t*m的特征f输入到pooling中,计算t帧的均值和方差,将均值和方差拼接,得到1*(2*m)的特征;将1*(2*m)的特征输入到fc层和softmax层,获得1
×
c的语种类别预测向量,其中,c为语种类别数;结合语种类别标签计算ce loss的损失,更新多语种分类模型的参数。4.如权利要求3所述的混杂语种分类识别方法,其特征在于,若已知测试音频只属于一个语种:则将整条音频的bn特征输入到语种分类模型中,输出1
×
c的语种类别预测向量,将概率最大的那维向量对应的语种类别作为最终预测结果;若已知测试音频包含多个语种:取窗长为w帧,窗移为s帧,每次取w帧bn特征输入到语种分类模型,输出1
×
c的语种类别预测向量,将概率最大的那维向量对应的语种类别作为该窗语音帧的预测结果;假设两个相邻窗的语种分别为a和b,若a和b相同,则这两个窗的所有帧都属于语种a;若a和b不同,则将两个窗重叠部分的帧均分给两个语种。5.一种混杂语种分类识别装置,其特征在于,包括:判断模块,用于判断每帧待识别音频信号是否为语音帧;提取模块,用于对每条音频的所有语音帧提取fbank特征;输出模块,用于将fbank特征输入到多语种语音识别模型后,提取conformer层的输出
特征;预测模块,用于将conformer层的输出特征作为每帧对应的bn特征输入多语种分类模型中,得到最终的语种分类预测结果。6.一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1至4任一项所述的混杂语种分类识别方法。7.一种终端设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现如权利要求1至4任一项所述的混杂语种分类识别方法。
技术总结
本发明公开了一种混杂语种分类识别方法、装置、存储介质及终端设备,混杂语种分类识别方法包括如下步骤:判断每帧待识别音频信号是否为语音帧;对每条音频的所有语音帧提取Fbank特征;将Fbank特征输入到多语种语音识别模型后,提取Conformer层的输出特征;将Conformer层的输出特征作为每帧对应的BN特征输入多语种分类模型中,得到最终的语种分类预测结果;本发明通过将待识别音频提取Fbank特征后输入到多语种语音识别模型获得Conformer层的输出特征,将Conformer层的输出特征作为BN特征输入多语种分类模型中预测出语种的分类,不被噪声干扰,快速预测出语种分类,提高语音评测的精准性。音评测的精准性。音评测的精准性。
技术研发人员:薛文韬 孙暐
受保护的技术使用者:苏州驰声信息科技有限公司
技术研发日:2022.10.27
技术公布日:2023/2/3
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。