1.本发明属于语音分离技术领域,涉及一种基于视觉导引的两阶段语音分离方法及系统。
背景技术:
2.本部分的陈述仅仅是提供了与本发明相关的背景技术信息,不必然构成在先技术。
3.语音分离是指从多个说话人产生的混合语音中提取出一个或多个目标语音信号。语音分离问题来自“鸡尾酒会效应”,它描述了一个现象是在嘈杂的室内环境中,比如在鸡尾酒会上同时存在着许多不同类型的声源。但即便如此,人们可以将注意力集中在某一个人的谈话之中而忽略背景中其他的对话或噪音。这是人的一种听力选择能力。我们希望通过机器学习具有这种语音选择并筛选的能力。语音分离具有广泛的应用,是许多语音下游任务中基础且重要的一环,分离出高质量的纯净语音才能更好的应用在语音识别[torfi a,iranmanesh s m,nasrabadi n,et al.3d convolutional neural networks for cross audio-visual matching recognition[j].ieee access,2017][t.afouras j s c,a.senior,o.vinyals,and a.zisserman.deep audio-visual speech recognition[j].ieee transactions on pattern analysis&machine intelligence,2018]、人机交互等场景中。
[0004]
传统的语音分离算法包括计算听觉场景分析(casa,computational auditory scene analysis)、非负矩阵分解以及隐马尔可夫模型等,通常需要一定的假设条件和先验知识[josh h,mcdermott.the cocktail party problem[j].current biology,2009],在分离相似的说话人语音时也存在效果不佳的问题[rivet b,wang w,naqvi s m,et al.audiovisual speech source separation:an overview of key methodologies[j].ieee signal processing magazine,2014,31(3):125-134.]。随着深度学习的发展,神经网络在语音分离领域也取得了较好的效果,神经网络可以学习混合语音信号与目标语音信号之间的复杂映射关系。常见的纯音频方法在训练分离网络时存在标签排列的问题,虽然可以通过排列组合——置换不变训练(pit,permutation invariant training)筛选出正确的匹配项,但计算较为复杂;除此之外,语音受环境和噪声的影响较大,导致分离系统的鲁棒性较差。
[0005]
在现实场景中,人们会通过观察说话者来辅助自己的听觉感知,当看到说话人的面部或唇部的时候,听力更容易。其次,在一些心理学和生理学,以及精神学等领域,也有研究[golumbic e z,cogan g b,schroeder c e,et al.visual input enhances selective speech envelope tracking in auditory cortex at a
‘
cocktail party’[j].journal of neuroscience,2013,33(4):1417-1426.]证明视觉信息是有助于人们对说话的理解。相对于语音,说话人的视觉信息如嘴唇运动和面部外观等信息更加稳定,同时视觉信息具有身份特征,可以在分离混合语音的过程中匹配正确的说话人标签。2017年ephrat提出的分
离模型中只引入了静态图像,虽然降低了数据维度,但丢失了视觉时序上的信息、损失了分离性能。
[0006]
一些研究[afouras t c j s,zisserman a.my lips are concealed audio-visual speech enhancement through obstructions[j].interspeech,2019,4295-9.][ochiai t,delcroix m,kinoshita k,et al.multimodal speakerbeam:single channel target speech extraction with audio-visual speaker clues[m].interspeech 2019.2019:2718-22.][r.gu,s.-x.zhang,y.xu,l.chen,y.zou,and d.yu,“multi-modal multi-channel target speech separation,”ieee journal of selected topics in signal processing,2020]中提出使用说话人额外的参考语音提取特征来提高分离效果。wang等人在分离模型中使用了用于说话人识别的x-vector,luo等人引入说话人的纯净语音的i-vector来辅助分离。但此类方法有两个弊端,一是需要提前录入说话人的纯净的参考语音才能进行分离模型的训练;二是在模型训练完成再应用于实际分离场景中时,必须有待分离说话人的纯净语音才能进行分离,因此在现实应用场景中有很大的限制。
技术实现要素:
[0007]
本发明为了解决上述问题,提出了一种基于视觉导引的两阶段语音分离方法及系统,本发明通过第一阶段的分离语音提取出说话人的具有身份区分性的独立语音特征辅助语音分离,通过视觉和音频两种模态信息的特征提取和融合辅助语音分离,能够提升语音分离性能。
[0008]
根据一些实施例,本发明采用如下技术方案:
[0009]
一种基于视觉导引的两阶段语音分离方法,包括以下步骤:
[0010]
在第一阶段,对获取的混合语音在时域上进行分离,获得粗分离的说话人语音;
[0011]
在第二阶段,借助第一阶段的纯音频分离结果提取具有说话人信息的独立语音特征,然后挖掘视觉和音频两种模态之间的潜在相关特征和互补特征,进行视觉特征和语音时频域特征两种模态的融合后再分离,对两个阶段动态调整权重最终得到纯净的目标语音。
[0012]
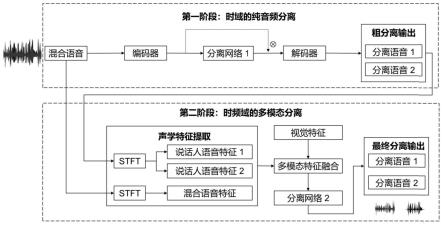
作为可选择的实施方式,所述第一阶段,具体过程包括:
[0013]
利用编码器对获取的混合语音进行编码,提取混合语音特征;
[0014]
对混合语音特征进行分离,得到目标语音的掩码,确定目标语音特征,并对目标语音特征解码,获得粗分离的目标语音时域信号。
[0015]
作为进一步的限定,对混合语音特征进行分离的具体过程包括,利用第一分离网络,处理混合语音特征,所述第一分离网络为时间卷积网络结构,包括一个归一化层,多个相同的栈模块,其中每个栈模块由全卷积、膨胀卷积和残差模块构成,最后一个栈模块的输出经过卷积层和prelu激活层得到分离后的目标掩码。
[0016]
作为进一步的限定,所述目标语音特征为混合语音和目标语音的掩码相乘计算得到。
[0017]
作为可选择的实施方式,所述第二阶段,具体过程包括:
[0018]
对混合语音进行变换,得到混合语音的复谱图,根据其获取真实纯净语音的复谱掩码;
[0019]
对第一阶段获取的目标语音的时域信号进行转换,得到分离后的各个说话人的复谱图;复谱图经过独立语音特征提取网络resnet-18提取各个说话人的独立语音特征。
[0020]
获取与混合语音时间同步的说话人的视觉信息并进行预处理,对预处理后的视觉图像分别提取静态视觉特征和动态视觉特征,其中静态视觉特征包含了具有区分性的说话人的身份信息,与音色等声音特征具有相似性;动态视觉特征包含了语音的内容信息,与音素等声音特征具有相似性,同时结合这两种视觉特征能够在处理较少的维度信息的同时获得更多的语音相关特征;
[0021]
混合语音特征提取网络对混合语音的时频域信息提取语音特征,进行多模态特征融合,分离网络2分离所述多模态特征,得到分离后的目标语音的掩码,将所述掩码和混合语音的复谱图相乘后进行逆变换,通过对两个阶段分离的联合训练和动态优化权重得到目标说话人的时域语音信号。
[0022]
作为进一步的限定,对混合语音进行变换,得到混合语音的复谱图的具体过程包括对混合语音信号进行短时傅里叶变换,然后分别计算其实部和虚部得到复谱图,复谱图包含了语音的幅度和相位信息。
[0023]
作为进一步的限定,对第一阶段的粗分离语音进行时频域转换得到复谱图;然后使用独立语音特征提取网络resnet-18对各个说话人的复谱图提取独立语音特征;接着对独立语音特征进行时间维度转换以实现音频和视频两种模态特征的维度一致性。
[0024]
作为进一步的限定,获取与混合语音时间同步的说话人的视觉信息并进行预处理的具体过程包括读取视频文件,截取设定长度视频获取多帧图像序列,随机选择一帧面部图像作为静态视觉信息;然后对各帧图像序列进行裁剪,选取大小设定的唇部区域以降低数据维度,生成唇部序列的文件,作为动态视觉信息。
[0025]
作为进一步的限定,提取视觉特征的具体过程包括对唇部图像进行归一化和数据填充,预处理后的唇部数据依次经过动态视觉特征提取网络,包括一个3d卷积层、shufflenet v2,和时间卷积网络来提取时间序列特征,能够更多的拟合语音的内容信息,最后获得的唇部特征;
[0026]
对面部图像进行标准化和大小处理,经过静态视觉特征提取网络resnet-18提取包含说话人身份信息的特征,对面部特征在时间维度上进行转换,保证转换后和唇部序列特征具有相同的时间维度。
[0027]
作为进一步的限定,进行多模态特征融合的具体过程包括首先混合声音复谱图经过混合语音特征提取网络得到混合语音特征,然后通过级联的方式对说话人的视觉特征、独立语音特征和混合语音特征做拼接,最后得到融合的多模态特征。
[0028]
作为进一步的限定,利用第二分离网络分离所述多模态特征,所述第二分离网络为u-net的上采样网络层。
[0029]
作为进一步的限定,对于两阶段的分离网络的损失函数权重进行动态调整,以最大程度的利用第一阶段的独立语音特征来辅助第二阶段的分离。
[0030]
一种基于视觉导引的两阶段语音分离系统,包括:
[0031]
第一分离模块,被配置为在第一阶段,对获取的混合语音在时域上进行分离,获得粗分离的说话人语音;
[0032]
第二分离模块,被配置为在第二阶段,借助第一阶段的纯音频分离结果提取具有
说话人信息的声音特征,同时挖掘视觉和音频两种模态之间的潜在相关特征和互补特征,进行视觉特征和语音时频域特征两种模态的融合后再分离,对两个阶段动态调整权重最终得到分离后的目标语音;
[0033]
动态调整权重模块,根据两个阶段的分离模型性能,动态调整其权重,以最大程度的利用第一阶段提取的独立语音特征来辅助第二阶段,实现纯净的目标说话人语音分离。
[0034]
与现有技术相比,本发明的有益效果为:
[0035]
(1)本发明所提出的基于视觉导引的两阶段语音分离方案,可以在只有混合语音的情况下提取出单一说话人的语音特征来辅助语音分离,避免了引入额外的纯净参考语音。
[0036]
(2)本发明同时利用包含语音内容信息的动态视觉特征和包含身份信息的静态视觉特征,挖掘视觉和音频两种模态之间的潜在相关性和互补性,同时解决了纯音频语音分离中的标签排列问题,避免损失函数的计算复杂度,同时提高了分离效果和分离系统的鲁棒性。
[0037]
(3)本发明提出了一种针对两阶段语音分离的动态调整损失函数权重的方法。在同时优化两个训练目标的情况下最大程度的利用第一阶段的语音提取独立语音特征来辅助第二阶段的分离,最终得到性能指标较高的纯净语音。
附图说明
[0038]
构成本发明的一部分的说明书附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。
[0039]
图1为本发明的一种基于视觉导引的两阶段语音分离方法的流程图。
[0040]
图2为本发明的一种提取视觉特征的方法流程图。
[0041]
图3为本发明的一种动态调节损失函数权重系数的方法流程图。
具体实施方式
[0042]
下面结合附图与实施例对本发明作进一步说明。
[0043]
应该指出,以下详细说明都是例示性的,旨在对本发明提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本发明所属技术领域的普通技术人员通常理解的相同含义。
[0044]
需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本发明的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。
[0045]
本发明提出了一种基于视觉导引的两阶段语音分离方法及系统,通过第一阶段的粗分离语音提取出说话人的语音特征辅助语音分离,通过多模态信息的特征提取和融合辅助语音分离。
[0046]
具体过程包括:
[0047]
一、第一阶段的纯音频时域分离
[0048]
1.获取混合语音。随机选择并读取两个说话人(以两人混合语音分离为例)的纯净
语音wav文件,截取固定长度(以2.55s为例),对读取到的时域语音信号进行采样,采样率为16khz,并进行归一化,分别记为xa,xb,对两个纯净语音相加得到混合语音x
mix
=xa xb。
[0049]
2.混合语音x
mix
经过编码器,提取混合语音特征。编码器使用一层一维卷积网络。
[0050]
3.混合语音特征经过分离网络1,得到分离后的目标语音的掩码。分离网络1使用时间卷积网络(tcn,temporal convolutional network)结构。tcn包括一个归一化层(依次进行组归一化和一维卷积),n个相同的栈模块,其中每个栈模块由全卷积、膨胀卷积和残差模块构成。最后一个栈模块的输出经过卷积层和prelu激活层得到分离后的目标掩码。
[0051]
4.将混合语音x
mix
分别和目标语音的掩码相乘,得到对应说话人的目标语音特征。
[0052]
5.将上述获得的目标语音特征经过解码器,获得目标语音的时域信号,记为x’a
,x’b
。解码器使用一层一维转置卷积网络。
[0053]
二、第二阶段的多模态时频域分离
[0054]
6.获取混合语音的时频域信息——复谱图(cirm,complex ideal ratio mask),记为s
mix
。复谱图是复数域的理想比率掩码,它可以用二维平面表示了时间、频率和能量的三维信息,实部和虚部避免单纯幅度谱丢失相位信息而造成的分离质量下降。首先对混合语音信号进行短时傅里叶变换(stft,short-time fourier transform),然后分别计算其实部和虚部得到复谱图。其中stft变换如公式(1)所示。
[0055][0056]
其中x(m)为输入的语音信号,w(m)是窗函数。x(n,ω)是时间n和频率ω的二维函数。在本发明中,可令窗函数的长度window_size为400,相邻stft列之间的音频样本数hop_size为160,即相邻窗之间的重合音频样本数为160,用零填充后加窗信号的长度n_fft为512,最终得到的复谱图的大小为2*f*t,即2*257*256,其中2表示实部和虚部两个维度,f和t分别表示频率和时间维度。
[0057]
7.时域的纯净语音通过stft变换(如公式(1)所示)获得对应的复谱图,根据混合语音的复谱图获取真实纯净语音的复谱掩码ma,mb。
[0058][0059]
其中,yr和yi分别表示混合语音复谱图的实部和虚部分量,sr和si分别表示纯净语音复谱图的实部和虚部分量。根据理想复掩码和混合语音,可以得到纯净语音,公式如下所示:
[0060]
s=m*y
ꢀꢀꢀ
(3)
[0061]
其中,*表示负数乘法。
[0062]
8.提取第一阶段输出的时域信号的独立语音特征。首先对第一阶段的分离语音x’a
,x’b
进行时频域转换,通过stft变换(如公式(1)所示)得到分离后的各个说话人的复谱图s’a
,s’b
,然后经过resnet-18网络获取各个说话人的语音特征,记为αa、αb,维度为128*1。此处提取到的语音特征来自于分离后的语音,所以在一定程度上表示了说话人的身份特性,可以为第二阶段的分离提供有效的身份信息。
[0063]
9.获取与混合语音时间同步的说话人的视觉信息并进行预处理。首先读取视频文件,截取2.55s长度。视频的采样率为75帧/秒,故可以获得64帧图像序列。由于在一段语音
范围内,说话人的面部除唇部区域外不会有太大的变化,为了在保留说话人身份特征的同时降低数据处理的复杂度,因此随机选择一帧面部图像作为静态视觉信息;然后对64帧图像序列进行裁剪,选取大小为88*88的唇部区域,生成唇部序列的h5文件,作为动态视觉信息。
[0064]
10.分别提取包含身份信息的静态视觉特征和包含语音内容信息的动态视觉特征。首先对唇部图像进行归一化和数据填充,来提升特征提取模型的精度和稳定性。预处理后的唇部数据依次经过一个3d卷积层、shufflenet v2网络,再经过tcn来提取时间序列特征,最后获得的唇部特征维度为512*1*64,记为f
lip_a
,f
lip_b
。然后对面部图像进行标准化和大小处理,以加快特征提取模型的收敛速度。由于面部图像为彩色图像有3个通道,故预处理后的面部数据大小为3*224*224,经过一个残差网络resnet-18提取到维度为128*1的特征。为了对唇部特征和面部特征进行融合,需对面部特征在时间维度上进行复制,保证转换后和唇部序列特征具有相同的时间维度,即为128*1*64,记为f
face_a
,f
face_b
。
[0065]
11.获取混合语音的语音特征并进行多模态特征融合。首先混合声音复谱图s
mix
经过u-net下采样网络层得到混合语音特征mix,维度为512*1*64。然后对分离语音提取的语音特征αa、αb在时间维度上进行转换以保持和视觉特征维度相同,通过级联的方式对说话人的视觉特征f
lip_a
,f
lip_b
,f
face_a
,f
face_b
和声音特征αa,αb,α
mix
做拼接,最后得到融合的多模态特征维度为2048*1*64。
[0066]
12.上述多模态特征经过分离网络2,得到分离后的目标语音的掩码m”a
,m”b
。分离网络2由u-net的上采样网络层构成。
[0067]
13.将目标掩码m”a
,m”b
和混合语音复谱图s
mix
分别相乘,获得第二阶段分离后的说话人的复谱图s”a
,s”b
。对s”a
,s”b
进行逆短时傅里叶变换(istft)得到目标说话人的时域语音信号x”a
,x”b
。计算公式如下所示:
[0068]
s”a
=m”a
*s
mix
ꢀꢀꢀ
(4)
[0069]
s”b
=m”b
*s
mix
ꢀꢀꢀ
(5)
[0070]
x”a
=istft(s”a
)
ꢀꢀꢀ
(6)
[0071]
x”b
=istft(s”b
)
ꢀꢀꢀ
(7)
[0072]
三、动态调整两阶段损失函数权重
[0073]
在本发明中,两个阶段的分离过程和各个网络模块同时训练以达到优化目标。定义整体网络架构的损失函数如下:
[0074]
loss=λ1loss1 λ2loss2ꢀꢀꢀ
(8)
[0075][0076]
loss2=||m
a-m’a
|| ||m
b-m’b
||
ꢀꢀꢀ
(10)
[0077]
其中,loss1和loss2分别是两个阶段的训练损失函数,λ1和λ2分别是两个损失函数的训练权重。针对loss1,x
target
定义为x
noise
定义为s
’‑
x
target
,其中s’表示分离的语音信号,s表示纯净语音信号。
[0078]
为了从第一阶段的分离语音中获取有效的说话人语音特征,进一步提升第二阶段
的分离效果,本发明提出了一种动态调节两阶段损失函数权重的方法。由于在训练初始状态下,第一阶段分离的语音质量较差,对应提取到的说话人语音特征的质量也相对较差,因此此时将两个阶段的损失函数权重设置为λ1=λ2=1,同时训练和优化两个阶段的分离网络。随着第一阶段提供的分离语音质量在提高,对应的语音特征更具有区分性,因此此时第二阶段的分离效果能得到显著提升。当两个阶段的分离效果达到一种阈值关系时,设置权重分别为λ1=1,λ2=2,重点训练第二阶段的分离网络。此时的阈值关系可以通过两个阶段的分离损失来进行判断。假设单一阶段纯音频语音分离的损失为源失真比(sdr,source to distortion ratio)的负值,定义为e0,第一阶段的语音分离的损失为分离语音的sdr的负值,定义为e1,第二阶段的语音分离的损失为第二阶段分离的语音的sdr的负值,定义为e2。当e
1-e0《e
1-e2时,表明第一阶段分离出的语音提升了第二阶段的分离效果,此时的语音特征对于第二阶段是有效的,因此进行权重分配调整。sdr的定义如下所示:
[0079][0080]
其中,s
target
,e
interf
,e
noise
和e
artif
分别表示目标说话人的语音、其他说话人产生的干扰、噪声的干扰和其他人为处理时产生的干扰。
[0081]
实施例二
[0082]
一种基于视觉导引的两阶段语音分离系统,包括:
[0083]
第一分离模块,被配置为在第一阶段,对获取的混合语音在时域上进行分离,获得独立的说话人语音;
[0084]
第二分离模块,被配置为在第二阶段,借助第一阶段的纯音频分离结果提取具有说话人信息的独立语音特征,同时挖掘视觉和音频两种模态之间的潜在相关特征和互补特征,进行视觉特征和语音时频域特征两种模态的融合后再分离,最终得到分离后的目标语音;
[0085]
动态调整权重模块,根据两个阶段的分离模型性能,动态调整其权重,以最大程度的利用第一阶段提取的独立语音特征来辅助第二阶段,实现纯净的目标说话人语音分离。
[0086]
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
[0087]
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0088]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指
令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0089]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0090]
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
[0091]
上述虽然结合附图对本发明的具体实施方式进行了描述,但并非对本发明保护范围的限制,所属领域技术人员应该明白,在本发明的技术方案的基础上,本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本发明的保护范围以内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。