1.本发明涉及语意理解技术领域,尤其涉及一种基于自监督深度学习的地址识别方法。
背景技术:
2.得益于计算机算力的不断突破,深度学习在机器学习领域取得了迅猛的发展,其去特征工程的巨大优势使其可以胜任更多的端到端任务,而不用手动设计规则从而适配更多的应用场景。而其挖掘数据潜在特征的能力使深度学习可以应用到更多的跨领域场景。但深度学习往往需要从大量的样本中学习特征,而海量数据的人工标注工作带来的人力成本依然限制了深度学习在一些场景的应用,特别人工标注过程使自动化学习新知识成为深度学习难点。
3.地址识别任务方面,其一:现有的主流地址识别方法多采用 rnn crf模型的方式来实现,可其难以解决待识别内容中有嵌套描述的情况;其二:在工业应用中往往不但需要地址识别的能力,而且需要得到准确的地址识别结果。但在实际的地址识别场景中,由于来源数据的参差不齐,往往会遇到地址输入错误,异常字符,地址信息不全等情况而导致难以得到准确的地址结果。
技术实现要素:
4.本发明的目的是为了解决现有技术中的问题,而提出的一种基于自监督深度学习的地址识别方法。
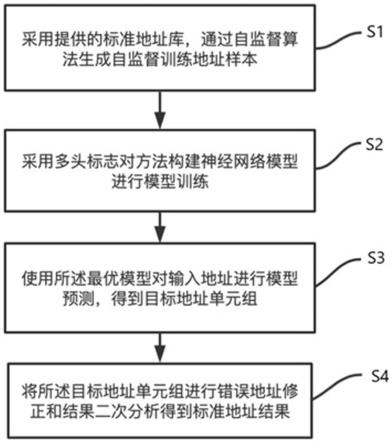
5.为了实现上述目的,本发明采用了如下技术方案:一种基于自监督深度学习的地址识别方法,包括以下步骤:
6.s1、采用提供的标准地址库,通过自监督算法生成自监督训练地址样本;
7.s2、采用多头标志对方法构建神经网络模型进行模型训练;
8.s3、使用训练动态终结方法终止训练得到最优模型;
9.s4、将预测出的地址单元组进行错误地址修正和结果二次分析得到标准地址结果。
10.在上述的基于自监督深度学习的地址识别方法中,所述步骤s1 包括:
11.1)、使用标准地址单元划分定义标准地址结构,并填充标准地址数据;使用标准地址数据为基准训练数据;
12.2)、对基准训练数据使用自监督算法生成自监督训练地址样本;
13.2.1)、首先对所述基准训练数据进行数据增强:
14.(1)、以(30~50%)概率对地址单元类型描述进行mask,并记录mask索引;
15.(2)、以(30~50%)概率对地址单元类型描述进行扩展,并记录扩展索引;
16.2.2)、自动生成训练数据负样本:
17.(1)、对基准训练数据进行字频统计,过滤高频字及停用字,生成字频字典;
18.(2)、利用字频字典基于字频以(30~50%)概率在地址单元前后添加地址单元负样本,负样本中高频字的使用概率高于低频字的使用概率,并记录负样本索引;
19.(3)、使用全中文字库、符号库、英文字母组成(5~20%)概率负样本字库,利用此概率(5~20%)负样本字库以(5~20%)概率在地址单元内添加负样本,并记录负样本索引;
20.2.3)、以数据增强后的基准训练数据作为正样本,以自动生成的训练数据负样本作为负样本来构建自监督训练地址样本;
21.3)、对所述自监督训练地址样本生成样本标签:
22.3.1)、训练标签分为五个类别:单字地址、地址开始、地址中间、地址结束、非地址;
23.3.2)、依照自监督训练地址样本,结合训练标签生成地址识别标签;
24.3.3)、对自监督训练地址样本进行数据映射生成样本-索引映射及索引-样本映射,映射长度等于训练数据所使用的所有字符枚举总数量;
25.3.4)、对上述标签数据进行数据映射生成标签-索引映射及索引
‑ꢀ
标签映射,映射长度等于标签数据所使用的所有标签枚举总数量加1,其中加1为padding标签。
26.在上述的基于自监督深度学习的地址识别方法中,所述步骤s2 包括:
27.1)、使用序列特征抽取网络对训练样本进行特征提取,提取出的特征表征为:
28.h1,h2,h3,h4,
…hs
29.其中h表示序列中每个字符抽取出的隐层特征,s表示序列长度;
30.2)、构建样本标签矩阵y其形状为(s,s,β)
31.其中:s为序列长度,β为地址单元类别数也就是head数;
32.如图所示,由多头标志对方法构建的标签可以优雅的解决实体嵌套问题,实现对嵌套样本的训练;
33.3)、通过序列特征生成多头标志对矩阵:
34.序列特征:h1,h2,h3,h4,
…hs
35.通过序列特征生成特征矩阵v,r:
[0036]vi,β
=w
ν,βhi
十b
v,β
[0037]ri,β
=w
r,βhi
十b
r,β
[0038]
得到:多头矩阵
[0039][0040]
其中:(i,j∈s),w、b为可学习参数,w为权重、b为偏置;
[0041]
4)、由于多头矩阵缺乏位置的敏感性,故在隐层加上相对位置信息p(i,j),其编码规则为:
[0042]
c-r
…
c-2、c-1、c、c 1、c 2
…
c r
[0043]
其中c=ceil(s/2)
[0044]
则特征矩阵v,r变为:
[0045]vi,β
=w
ν,β
(hi十pi) b
ν,β
[0046]ri,β
=w
r,β
(hi十pj)十b
r,β
[0047]
此时多头矩阵为:
[0048]mβ
=(w
ν,βhi
w
r,β
pi)
t
(w
ν,βhi
w
r,β
pi)
[0049]
最后使用一个线性层d将m
β
映射为形状为(s,s,β)的输出o;
[0050][0051]
5)、预测概率及损失函数
[0052]
o矩阵中的元素c
β(i,j)
是地址类型为β的地址单元的打分,再通过sigmoid()得到元素c
β(i,j)
对应序列是的类型为β的地址单元的概率:p
β(i,j)
=sigmoid(c
β(i,j)
)
[0053]
最终得到损失函数为:
[0054][0055]
在上述的基于自监督深度学习的地址识别方法中,所述步骤s3 包括:
[0056]
记录每个mini-batch的训练损失,并对一轮训练中所有的 mini-batch训练损失进行累加作为此轮训练的训练损失;
[0057]
在模型更新参数后使用最新模型参数依据测试集数据对模型进行测试并计算测试损失,将训练损失与测试损失进行相加作为总损失,并将总损失进行记录;
[0058]
每完成一轮训练都将本轮训练的总损失与上轮训练的总损失进行比较,如果本轮训练损失大于上轮训练损失,则触发训练终结事件,累计触发5次训练终结事件,则视为训练结束;将训练完成的模型进行保存。
[0059]
在上述的基于自监督深度学习的地址识别方法中,所述步骤s4 包括:
[0060]
1)、以基准训练数据作为数据基础,生成标准地址查找缓存,已实现快速查找及匹配;
[0061]
2)、按地址单元类型对识别结果进行增强:
[0062]
根据先验知识,由于地址单元类型描述中包含一定含义近似但内容不同的描述,为了能将识别中的地址匹配到标准地址,首先按地址单元类型对识别结果进行增强,将地址单元类型修正为标准地址中统一的地址描述;
[0063]
3)、去除识别出的异常和重复地址:
[0064]
根据先验知识,当地址描述为'市'、'区'、'镇'、'街道'等仅有地址单元类型的表述时为无意义地址表述,通过字符枚举匹配的方式将此类无意义地址表述检索出并在识别结果中去除,同时将重复识别的地址单元去除;
[0065]
4)、对识别出的地址单元进行错误修正;
[0066]
由于部分识别出的地址单元在描述中出现错误,导致无法与标准地址单元匹配上,需要对其进行修正;首先通过此错误地址单元的上级地址单元在标准地址查找缓存中查找出其所有的下级地址单元作为待匹配单元;将错误的地址单元和所有的待匹配地址单元先转换为字向量,再通过字向量的累加生成地址单元向量;通过向量余弦相似度算法与levenshtein距离算法相结合的方法分别计算待匹配单元向量与错误地址向量间的相似度,取其相似度最大者且与错误地址字符长度差最小为最相似地址单元,从而完成地址单元修正;
[0067]
5)、将匹配出的标准地址单元拼接为完整地址单元组并按层级进行排列,并在标准地址查找缓存中查找标准地址结果。
[0068]
与现有的技术相比,本发明的优点在于:
[0069]
1.本技术通过使用自监督样本标签生成算法,大幅降低了地址识别任务中的数据标注成本;
[0070]
2.本技术通过使用多头标识对模型,实现了对地址描述中包含嵌套情况的识别;
[0071]
3.本技术通过训练动态终结方法终止方法提升了训练效率;
[0072]
4.本技术通过地址修正方法提高了地址识别准确率。
附图说明
[0073]
图1为本发明提出的一种基于自监督深度学习的地址识别方法的示意图;
[0074]
图2为本发明提出的一种基于自监督深度学习的地址识别方法中多头标志对模型标签矩阵示例图。
具体实施方式
[0075]
以下实施例仅处于说明性目的,而不是想要限制本发明的范围。
[0076]
实施例
[0077]
参照图1,一种基于自监督深度学习的地址识别方法,包括以下步骤:
[0078]
s1、采用提供的标准地址库,通过自监督算法生成自监督训练地址样本;
[0079]
本步骤包括:
[0080]
1)、使用标准地址单元划分定义标准地址结构,并填充标准地址数据;使用标准地址数据为基准训练数据;
[0081]
2)、对基准训练数据使用自监督算法生成自监督训练地址样本;
[0082]
2.1)、首先对所述基准训练数据进行数据增强:
[0083]
(1)、以(30~50%)概率对地址单元类型描述进行mask,并记录mask索引;
[0084]
(2)、以(30~50%)概率对地址单元类型描述进行扩展,并记录扩展索引;
[0085]
2.2)、自动生成训练数据负样本:
[0086]
(1)、对基准训练数据进行字频统计,过滤高频字及停用字,生成字频字典;
[0087]
(2)、利用字频字典基于字频以(30~50%)概率在地址单元前后添加地址单元负样本,负样本中高频字的使用概率高于低频字的使用概率,并记录负样本索引;
[0088]
(3)、使用全中文字库、符号库、英文字母组成(5~20%)概率负样本字库,利用此(5~20%)概率负样本字库以(5~20%)概率在地址单元内添加负样本,并记录负样本索引;
[0089]
2.3)、以数据增强后的基准训练数据作为正样本,以自动生成的训练数据负样本作为负样本来构建自监督训练地址样本;
[0090]
3)、对所述自监督训练地址样本生成样本标签:
[0091]
3.1)、训练标签分为五个类别:单字地址、地址开始、地址中间、地址结束、非地址;
[0092]
3.2)、依照自监督训练地址样本,结合训练标签生成地址识别标签;
[0093]
3.3)、对自监督训练地址样本进行数据映射生成样本-索引映射及索引-样本映射,映射长度等于训练数据所使用的所有字符枚举总数量;
[0094]
3.4)、对上述标签数据进行数据映射生成标签-索引映射及索引
‑ꢀ
标签映射,映射
长度等于标签数据所使用的所有标签枚举总数量加1,其中加1为padding标签。
[0095]
本步骤中首先建立所述标准地址库,并在mysql中实现此标准地址库的实例,并使用调用方提供的标准地址数据进行填充。从mysql 中读取标准地址数据为基准训练数据;将基准训练数据进行字频统计,过滤高频字及停用字,生成字频字典;
[0096]
进一步的,对所述基准训练数据进行数据增强:以45%概率对地址单元类型描述进行mask,并记录mask索引;以30%概率对地址单元类型描述进行扩展,并记录扩展索引;利用上述字频字典基于字频以10%概率在地址单元内添加负样本,负样本中高频字的使用概率高于低频字的使用概率,并记录负样本索引。数据增强完成后再进行训练数据负样本生成:利用所述字频字典基于字频以30%概率在地址单元前后添加地址单元负样本,负样本中高频字的使用概率高于低频字的使用概率,并记录负样本索引:使用全中文字库、符号库、英文字母组成(5~20%)概率负样本字库,利用此(5~20%)概率负样本字库以10%低概率在地址单元内添加负样本,并记录负样本索引。将上述数据增强后的基准训练数据作为正样本,以自动生成的训练数据负样本作为负样本来构建自监督训练地址样本;
[0097]
进一步的将基准训练数据随机打乱,按照9:1的比例将训练数据切分为训练集和测试集。对所述自监督训练地址样本生成样本标签;最后将训练地址数据样本及样本标签打包为json格式在本地进行存储。
[0098]
s2、采用多头标志对方法构建神经网络模型进行模型训练
[0099]
本步骤包括:
[0100]
1)、使用序列特征抽取网络对训练样本进行特征提取,提取出的特征表征为:
[0101]
h1,h2,h3,h4,
…hs
[0102]
其中h表示序列中每个字符抽取出的隐层特征,s表示序列长度;
[0103]
2)、构建样本标签矩阵y其形状为(s,s,β)
[0104]
以“经过ab市cd区efgh及周边”举例,如图2所示,
[0105]
其中:s为序列长度,β为地址单元类别数也就是head数。
[0106]
如该图所示,由多头标志对方法构建的标签可以优雅的解决实体嵌套问题,实现对嵌套样本的训练。
[0107]
3)、通过序列特征生成多头标志对矩阵:
[0108]
序列特征:h1,h2,h3,h4,
…hs
[0109]
通过序列特征生成特征矩阵v,r:
[0110]vi,β
=w
v,βhi
十b
ν,β
[0111]ri,β
=w
r,βhi
b
r,β
[0112]
得到:多头矩阵
[0113][0114]
其中:(i,j∈s),w、b为可学习参数,w为权重、b为偏置; 4)、由于多头矩阵缺乏位置的敏感性,故在隐层加上相对位置信息 p(i,j),其编码规则为:
[0115]
c-r
…
c-2、c-1、c、c十1、c十2
…
c十r
[0116]
其中c=ceil(s/2)
[0117]
则特征矩阵v,r变为:
[0118]vi,β
=w
v,β
(hi十pi)十b
v,β
[0119]ri,β
=w
r,β
(hi pj) b
r,β
[0120]
此时多头矩阵为:
[0121]mβ
=(w
ν,βhi
w
r,β
pi)
t
(w
v,βhi
w
r,β
pi)
[0122]
最后使用一个线性层d将m
β
映射为形状为(s,s,β)的输出0。
[0123][0124]
5)、预测概率及损失函数
[0125]
o矩阵中的元素c
β(i,j)
是地址类型为β的地址单元的打分,再通过sigmoid()得到元素c
β(i,j)
对应序列是的类型为β的地址单元的概率:p
β(i,j)
=sigmoid(c
β(i,j)
)
[0126]
最终得到损失函数为:
[0127][0128]
本步骤中使用基于python语言实现的pytorch框架搭建模型。使用序列特征抽取网络对训练样本进行特征提取,本例中序列特征提取网络使用lstm来实现,在实践中也可实现目前使用较广的 transformer来实现。亦可在特征提取网络前加入如bert等预训练模型,来增加特征提取效果。提取出特征后构建样本标签矩阵,再通过序列特征生成多头标志对矩阵,由于多头矩阵缺乏位置的敏感性,在隐层加上相对位置信息,最后生成多头标志对矩阵,由于预测值在 0,1之间,故损失函数使用二元交叉熵损失来实现。模型训练时采用mini-batch sgd优化器对模型训练参数进行更新优化,初始学习率设置为0.00005,动量比例设置为0.95;使用steplr学习率策略来控制学习率变化,更新步长设置为10个mini-batch,gamma设置为 0.9;
[0129]
进一步的,为了便于训练过程中超参的调整,以及对超参调整效果进行记录,使用pickle对超参进行打包,记录每次训练所使用的超参。
[0130]
进一步的,每个训练mini-batch的预测值与真实值使用二元交叉熵损失函数来对预测效果进行评估并计算损失;通过模型的反向传播依据损失值对模型进行参数更新。
[0131]
进一步的,训练动态终结方法包括:在训练过程中记录每个 mini-batch的训练损失,并对一轮训练中所有的mini-batch训练损失进行累加作为此轮训练的训练损失;在模型更新参数后使用最新模型参数依据测试集数据对模型进行测试并计算测试损失,将训练损失与测试损失进行相加作为总损失,并将总损失进行记录;每完成一轮训练都将本轮训练的总损失与上轮训练的总损失进行比较,如果本轮训练损失大于上轮训练损失,则触发训练终结事件,累计触发5次训练终结事件,则视为训练结束;将训练完成的模型进行保存。在实际操作过程中,损失最小的模型,不一定为最优的模型,有可能产生过拟合的现象。为了获得最优模型,避免最优模型中有较明显的过拟合现象,在每次触发训练终结事件时都对模型进行保存,然后取损失最小的三个模型分别进行测试,选取测试指标最优的模型作为预测模型。
[0132]
s3、使用训练动态终结方法终止训练得到最优模型
[0133]
本步骤包括:
[0134]
记录每个mini-batch的训练损失,并对一轮训练中所有的 mini-batch训练损失
进行累加作为此轮训练的训练损失;
[0135]
在模型更新参数后使用最新模型参数依据测试集数据对模型进行测试并计算测试损失,将训练损失与测试损失进行相加作为总损失,并将总损失进行记录;
[0136]
每完成一轮训练都将本轮训练的总损失与上轮训练的总损失进行比较,如果本轮训练损失大于上轮训练损失,则触发训练终结事件,累计触发5次训练终结事件,则视为训练结束;将训练完成的模型进行保存。
[0137]
本步骤中首先将待识别的地址文本输入模型,先使用序列特征提取网络对地址序列特征进行提取,后将序列特征使用训练完成的多头标识对模型转换到m
β
,得到地址单元的打分,最后使用sigmoid() 函数将分值映射到概率,概率大于0.5的序列即为预测的地址单元
[0138]
s4、将预测出的地址单元组进行错误地址修正和结果二次分析得到标准地址结果。
[0139]
本步骤包括:
[0140]
1)、以基准训练数据作为数据基础,生成标准地址查找缓存,已实现快速查找及匹配;
[0141]
2)、按地址单元类型对识别结果进行增强:
[0142]
根据先验知识,由于地址单元类型描述中包含一定含义近似但内容不同的描述,为了能将识别中的地址匹配到标准地址,首先按地址单元类型对识别结果进行增强,将地址单元类型修正为标准地址中统一的地址描述。比如将“栋”修正为“幢”、给“号门”增加“单元”描述等等,以期在标准地址查找缓存中完成地址匹配。
[0143]
3)、去除识别出的异常和重复地址:
[0144]
根据先验知识,当地址描述为'市'、'区'、'镇'、'街道'等仅有地址单元类型的表述时为无意义地址表述,通过字符枚举匹配的方式将此类无意义地址表述检索出并在识别结果中去除,同时将重复识别的地址单元去除。
[0145]
4)、对识别出的地址单元进行错误修正;
[0146]
由于部分识别出的地址单元在描述中出现错误,导致无法与标准地址单元匹配上,需要对其进行修正。首先通过此错误地址单元的上级地址单元在标准地址查找缓存中查找出其所有的下级地址单元作为待匹配单元;将错误的地址单元和所有的待匹配地址单元先转换为字向量,再通过字向量的累加生成地址单元向量;通过向量余弦相似度算法与levenshtein距离算法相结合的方法分别计算待匹配单元向量与错误地址向量间的相似度,取其相似度最大者且与错误地址字符长度差最小为最相似地址单元,从而完成地址单元修正。
[0147]
5)、将匹配出的标准地址单元拼接为完整地址单元组并按层级进行排列,并在标准地址查找缓存中查找标准地址结果。
[0148]
本步骤中首先以步骤s1所述的基准训练数据以内存模式存入 sqlite3生成标准地址查找缓存,内存模式可以让所有的查找及索引的使用都在内存中进行,用以实现快速查找及匹配;
[0149]
进一步的,获得识别结果后,按地址单元类型对识别结果进行增强,将识别结果中地址单元类型修正为标准地址中统一的地址描述。比如将“栋”修正为“幢”、给“号门”增加“单元”描述等等,并且通过字符枚举匹配的方式去除识别结果中仅有“市”、“区”、“镇”、“街道”等无意义地址的识别结果。
[0150]
进一步的,由于部分识别出的地址单元在描述中出现错误,导致无法与标准地址单元匹配上,需要对其进行修正。修正的基本思想就是先圈定错误地址单元描述的正确值范围,然后通过文本相似度算法获得与错误地址单元描述最接近的正确地址描述,使用此正确地址描述作为修正值。
[0151]
在文本相似度算法中常用的有levenshtein距离,其特点是对短文本速度较快,但其缺点是只比较编辑距离,完全不考虑语意相似度,如果不考虑上下文含义levenshtein距离是较优的选择;另一种是余弦相似度,此方法基于两个文本所对应的向量间的余弦距离,由于使用的是向量,且在训练时已经对文本向量进行更新,所以两个文本向量间的余弦距离在一定程度上反应了其语意相似度,而这在地址识别任务中是需要的特性。在本实例中,结合了以上两种算法,在分别计算出levenshtein距离和余弦距离后选取两种距离的最佳匹配词,然后选择其中与被匹配词长度差最小的作为最终结果。经实验此种方法得到的修正结果准确率最高。
[0152]
具体做法是:通过错误地址单元的上级地址单元在标准地址查找缓存中查找出其所有的下级地址单元作为待匹配单元;将错误的地址单元和所有的待匹配地址单元先转换为字向量,再通过字向量的累加生成地址单元向量;通过向量余弦相似度方法和levenshtein距离算法分别计算待匹配单元向量与错误地址向量间的相似度,取两者中相似度最高且与错误地址字符长度差最小的结果作为最相似地址单元,从而完成地址单元修正。完成地址单元修正后,将修正结果进行输出,作为最终地址识别结果
[0153]
本技术中,首先通过提供的标准地址库,使用自监督算法生成自监督训练地址样本。然后采用多头标志对方法构建神经网络模型进行模型训练。为了寻找得到最优模型,并提高训练效率,使用训练动态终结方法终止训练得到最优模型。模型行训练完成后,使用最优模型对输入地址进行模型预测,得到目标地址单元组。为得到更加精确的地址识别结果,并能够对错误的地址进行一定修正,将所述目标地址单元组进行错误地址修正和结果二次分析最后得到标准地址结果。
[0154]
标准地址库的字段按标准地址双体系建立,其一是街路巷体系,其二是路号体系,两体系共有15个地址单元字段,数据由有地址识别需求的需求方提供。提供方可提供街路巷或路号体系地址数据的其中之一,或者可以都提供。如果都提供有利于识别率的提升。由于训练地址样本的生成基于此标准地址库,故在提供标准地址数据时需保证每条地址的唯一性和正确性,且不同的标准地址中不得包含可能产生歧义的地址描述。提供的数据采用mysql数据库进行存储,如此存储能够便于数据的读取访问,也便于发现问题数据时的更新。而且作为关系型数据库mysql便于数据结构的扩展。
[0155]
自监督训练地址样本存储为json结构。json结构具有良好的自我描述性,便于阅读,且json结构可以实现清晰的数据层次,可以将训练数据与训练标签放在同一文件中且能够清晰快速的区分,在主程序基于python语言实现时,还可以将json文件直接加载为数据对象,更便于训练数据的存储和读取,以及便于训练数据的更新。
[0156]
实现所述标准地址查找缓存用以实现快速地址查找匹配,此处使用sqlite3实现,sqlite3支持原生sql语句,可以实现较复杂的查找逻辑,sqlite3的内存表模式还可实现全
表内存缓存,全表内存缓存使原始数据和数据索引都缓存到内存,能够快速的获得查询结果,本地化部署的特性使查询的过程也免去了网络访问的过程,相较于直接在mysql中查询,使用sqlite3实现查询缓存后使每次地址匹配都控制在秒级返回内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
