1.本发明涉及分布式数据库技术领域,具体的说是一种分布式数据库执行哈希连接的方法。
背景技术:
2.哈希连接,是一种数据库中常见的操作,用于分析数据库两个或以上表数据之间的联系;无论在各种交易模型的oltp场景下,还是计算分析模型的olap场景下,都是基础操作,哈希连接算子也都是基础算子。
3.传统的哈希连接算子一般分为两步,对于两表中较小表,在内存中根据连接列建立哈希表;对于较大表,逐个查阅哈希表探测大表中链接列与小表匹配的部分,最后输出结果。传统部署在单机上的哈希连接也遵从以上步骤。
4.对于分布式数据库,尤其是shared-nothing架构的数据库,其运行方式相对于单机的哈希连接有以下不同。大表小表数据的分布不同于单机的情况,其数据可能分布在不同的数据库节点上,每个节点由网络连接,并且各自拥有一部分大表或者小表或者两者的数据。这就意味着在分布式环境下,如果要利用多个节点带来的并行计算能力,就要将原始的大小表数据,通过网重新分布至每个数据库节点;这些节点各自在拿到数据之后,进行哈希连接,最终结果就是这些节点的汇总。基于以上特点,一般的分布式数据库都采用哈希重分布的方式来实现每个节点的并行计算,即按照连接列的哈希值来确定原始数据被分发给哪个节点。然而基于哈希重分布的方式会带来以下问题:由于原始数据中可能存在倾斜值,这些拥有相同哈希值的倾斜值会被分发给同一个节点,会造成节点间任务量不均衡的现象,即某个或某些节点拿到大部分数据的情况,其危害具体体现在,这些拿到数据量较多的节点完成连接时间较长,会造成其余节点等待从而拖慢整个执行过程的情况。因此,在提升分布式数据库中哈希连接执行效率的问题中,如何处理倾斜值是一个关键问题。
5.目前,对于倾斜值的处理,发明专利申请《一种基于spark计算框架的大表连接优化方法》,公开号cn113868230a,其具体提出了一种基于蓄水池采样的倾斜值检测机制,以及一种对数据进行分割,使倾斜数据发送给处理较快的节点的倾斜优化方式,其目的是在spark计算框架中两个大表在连接查询时过滤掉大量无用数据,改进数据倾斜情况,缩短连接查询时间,解决spark集群节点内存溢出问题;
6.公开文献y.xu,p.kostamaa,x.zhou,and l.chen.handling data skew in parallel joins in shared-nothing systems.in sigmod,pages 1043
–
1052,2008.提出了一种广播部分数据的倾斜优化连接方法“prpd”,在prpd中,表中倾斜数据按照哈希重分布,表中倾斜数据留在本地,匹配到相对表(另一个参与连接的表)的倾斜数据的对应数据被广播给所有参与计算的节点。这种方法在原始数据在各个节点上较为理想地均匀分布假设下,能取得较好的结果,但是对更为复杂的数据分布,优化效果较为有限。
技术实现要素:
7.本发明针对目前技术发展的需求和不足之处,提供一种分布式数据库执行哈希连接的方法。
8.本发明的一种分布式数据库执行哈希连接的方法,解决上述技术问题采用的技术方案如下:
9.一种分布式数据库执行哈希连接的方法,包括如下步骤:
10.获取分布式数据库中表统计信息的数据采样量,设定一个相对倾斜率,计算相对倾斜率与表数据采样量的乘积,得到倾斜阈值;
11.获取分布式数据库中表统计信息的热力图,利用热力图筛选表中超出倾斜阈值的元素,被筛选出来的元素称为倾斜值;
12.利用倾斜值拓展分布式数据库的表统计信息,得到新的表统计信息;
13.在分布式数据库中执行包含哈希连接的sql语句,获取两个输入数据表,利用新的表统计信息生成哈希连接物理计划,依据计划对输入数据表中的元组进行哈希分发、平均分发或镜像分发,以将输入数据表的元组按照散列值发送给目的节点、按照平均概率分发给所有节点或复制后发送给所有参与计算的节点;
14.各个节点接收到输入数据表的元组之后,利用数据量小的输入数据表数据建立哈希表,利用数据量大的输入数据表数据进行探测,最后每个节点哈希连接的结果作并集,该并集即为最终的哈希连接结果。
15.可选的,在分布式数据库中执行包含哈希连接的sql语句,获取两个输入数据表,用新的表统计信息生成哈希连接物理计划,具体包括:
16.执行sql语句时,从分布式数据库中获取两个输入数据表,将数据量大的输入数据表称为r表,数据量小的输入数据表称为s表;
17.基于新的表统计信息,确认r表和s表中是否含有倾斜值:
18.(a)r表和s表的倾斜值都不为空,
19.(b)r表倾斜值不为空,s表倾斜值为空,
20.(c)r表倾斜值为空,s表倾斜值不为空,
21.(d)r表和s表的倾斜值都为空;
22.对(a)、(b)两种情况,对r表和s表的非倾斜值进行哈希分发,对r表中的倾斜值进行平均分发,对s表中的倾斜值进行镜像分发;
23.对(c)、(d)两种情况,直接对r表和s表的元组进行哈希分发。
24.进一步可选的,构建哈希分发器、镜像分发器、平均分发器,其中,
25.哈希分发器用于接收r表/s表中的一条元组,并按照元组的散列值发送给目的节点;
26.镜像分发器用于接收s表中的一条元组,并发送给所有参与计算的节点;
27.平均分发器用于接收r表中的一条元组,并将元组按照平均概率随机或轮询分发给参与计算的节点。
28.优选的,对(a)、(b)两种情况,
29.利用r表读取算子顺序读取r表中的一条元组,并基于新的表统计信息判断该条元组是否为r表的倾斜值,若是,则使用平均分发器将该条元组按照平均概率随机或轮询分发
给参与计算的节点,若否,则使用哈希分发器将该条元组按照元组的散列值发送给目的节点;
30.利用s表读取算子顺序读取s表中的一条元组,并基于新的表统计信息判断该条元组是否为r表的倾斜值,若是,则使用镜像分发器将该条元组发送给所有参与计算的节点,若否,则使用哈希分发器将该条元组按照元组的散列值发送给目的节点。
31.优选的,对(c)、(d)两种情况,
32.利用r表读取算子顺序读取r表中的一条元组,随后使用哈希分发器将该条元组按照元组的散列值发送给目的节点;
33.利用s表读取算子顺序读取s表中的一条元组,随后使用哈希分发器将该条元组按照元组的散列值发送给目的节点。
34.可选的,获取数据库表统计信息的热力图,获取热力图的数据采样量n和桶数m,统计桶边界元素数量num
eq
,筛选桶中的元素,α表示设定的相对倾斜率,被筛选出来的元素即为超出倾斜阈值的倾斜值。
35.优选的,将新的表统计信息加入系统表和缓存。
36.优选的,对分布式数据库中的所有表设定一个相同的相对倾斜率,基于分布式数据库中表统计信息的数据采样量,数据采样量不同的表具有不同的倾斜阈值。
37.本发明的一种分布式数据库执行哈希连接的方法,与现有技术相比具有的有益效果是:
38.(1)本发明通过在分布式数据库的表统计信息中拓展倾斜数据,并根据表中是否含有倾斜数据采取不同的分发方式,使各个节点的执行时间大致均衡,避免某几个节点执行时间非常倾斜的情况,提升分布式数据库sql执行性能;
39.(2)本发明在分布式数据库的表统计信息中拓展倾斜数据,这一操作不会对现有数据库增加过多负担。
附图说明
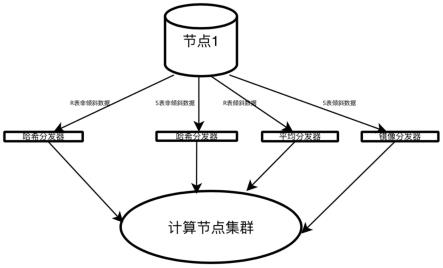
40.附图1是本发明实施例一中步骤(四)的流程示意图。
具体实施方式
41.为使本发明的技术方案、解决的技术问题和技术效果更加清楚明白,以下结合具体实施例,对本发明的技术方案进行清楚、完整的描述。
42.实施例一:
43.本实施例提出一种分布式数据库执行哈希连接的方法,包括如下步骤:
44.(一)获取分布式数据库中表统计信息的数据采样量,设定一个相对倾斜率α,计算相对倾斜率α与表数据采样量的乘积,得到倾斜阈值。
45.(二)获取分布式数据库中表统计信息的热力图,获取热力图的数据采样量n和桶数m,统计桶边界元素数量num
eq
,利用热力图筛选桶中的元素,被筛选出来的元素即为超出倾斜阈值的倾斜值。
46.(三)利用倾斜值拓展分布式数据库的表统计信息,得到新的表统计信息。
47.将新的表统计信息加入系统表和缓存。
48.(四)首先,在分布式数据库中执行包含哈希连接的sql语句,获取两个输入数据表,利用新的表统计信息生成哈希连接物理计划,具体包括:
49.执行sql语句时,从分布式数据库中获取两个输入数据表,将数据量大的输入数据表称为r表,数据量小的输入数据表称为s表;
50.基于新的表统计信息,确认r表和s表中是否含有倾斜值:
51.(a)r表和s表的倾斜值都不为空,
52.(b)r表倾斜值不为空,s表倾斜值为空,
53.(c)r表倾斜值为空,s表倾斜值不为空,
54.(d)r表和s表的倾斜值都为空。
55.随后,结合附图1,对(a)、(b)两种情况,对r表和s表的非倾斜值进行哈希分发,对r表中的倾斜值进行平均分发,对s表中的倾斜值进行镜像分发,对(c)、(d)两种情况,直接对r表和s表的元组进行哈希分发,实现这一步采取的操作如下:
56.(1)构建哈希分发器,用于接收r表/s表中的一条元组,并按照元组的散列值发送给目的节点,
57.构建镜像分发器,用于接收s表中的一条元组,并发送给所有参与计算的节点,
58.构建平均分发器,用于接收r表中的一条元组,并将元组按照平均概率随机或轮询分发给参与计算的节点;
59.(2)对(a)、(b)两种情况,利用r表读取算子顺序读取r表中的一条元组,并基于新的表统计信息判断该条元组是否为r表的倾斜值,若是,则使用平均分发器将该条元组按照平均概率随机或轮询分发给参与计算的节点,若否,则使用哈希分发器将该条元组按照元组的散列值发送给目的节点,
60.利用s表读取算子顺序读取s表中的一条元组,并基于新的表统计信息判断该条元组是否为r表的倾斜值,若是,则使用镜像分发器将该条元组发送给所有参与计算的节点,若否,则使用哈希分发器将该条元组按照元组的散列值发送给目的节点;
61.(3)对(c)、(d)两种情况,
62.利用r表读取算子顺序读取r表中的一条元组,随后使用哈希分发器将该条元组按照元组的散列值发送给目的节点,
63.利用s表读取算子顺序读取s表中的一条元组,随后使用哈希分发器将该条元组按照元组的散列值发送给目的节点。
64.最后,各个节点接收到r表、s表的元组之后,利用s表的元组建立哈希表,利用r表的元组进行探测,最后每个节点哈希连接的结果作并集,该并集即为最终的哈希连接结果。
65.本实施例中,对分布式数据库中的所有表设定一个相同的相对倾斜率,基于分布式数据库中表统计信息的数据采样量,可以知道,数据采样量不同的表具有不同的倾斜阈值。
66.为了方便,将本实施例的实现方法称为均分-广播方法,将cockroachdb数据库广泛采用的哈希连接方法与本实施例的均分-广播方法进行对比,
67.以四个节点为例,设定r表、s表的相对倾斜率为5%,得到表1中的执行时间,
68.节点节点1节点2节点3节点4均分-广播方法4.2s4.5s6s4.6s哈希连接方法517ms585ms9.3s610ms
69.由表1可以知道,均分-广播方法的执行时间更均衡。
70.以四个节点为例,设定r表、s表的相对倾斜率为5%、10%、20%、50%,得到表2中的总执行时间,
71.相对倾斜率5%10%20%50%均分-广播方法6.8s25.6s63.2s98s哈希连接方法10.4s38.9s89s143s
72.由表2可知,相对倾斜率对所有节点的总执行时间有很大影响。
73.综上可知,采用本发明的一种分布式数据库执行哈希连接的方法,可以使各个节点的执行时间大致均衡,避免某几个节点执行时间非常倾斜的情况,提升分布式数据库sql执行性能。
74.以上应用具体个例对本发明的原理及实施方式进行了详细阐述,这些实施例只是用于帮助理解本发明的核心技术内容。基于本发明的上述具体实施例,本技术领域的技术人员在不脱离本发明原理的前提下,对本发明所作出的任何改进和修饰,皆应落入本发明的专利保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。