1.本发明涉及计算机仿生算法执行领域,具体是涉及一种增强仿生算法的可插拔式框架的实现方法。
背景技术:
2.目前,模拟自然规律、生物现象的智能仿生算法在农业、工业、生物医学、人工智能等领域都有着广泛的应用。众多学者对自然界不同生物体行为或性质的建模衍生了多种仿生算法,例如遗传算法、森林优化算法、鱼群算法、蝙蝠算法等。这些算法被应用到各行各业,为生产难题提供了解决思路。
3.为了保证仿生算法在不同场景下都具有更好的收益,国内外学者们针对这些算法提出了许多优化增强方案。现有技术cn113589811a一种基于黏菌导航针对制造企业物流的寻优算法中陈勇等人基于黏菌导航寻优算法,设置包括边界约束和间距约束的约束条件,针对制造企业物流系统中的物料搬运问题进行寻优处理,通过定制化约束条件增强黏菌算法在企业物流中的应用;现有技术n110782460a基于fcm融合改进蝙蝠算法的图像分割方法中朱素霞等人利用一种新的改进蝙蝠算法与fcm算法相结合的方式,使得改进后的蝙蝠模糊聚类算法耗时更少,图像分割结果更准确。然而,以上两种技术方案都是对某一种特定仿生算法的定制化增强,这类增强方式依赖算法模型特定的应用背景,无法做到在多元仿生算法上的即插即用。这就使得优化增强操作往往要在多个不同的仿生算法上重复实施、交叉验证,这对仿生算法的应用推广是不利的。
4.仿生算法所采用的随机搜索策略使得其算法的稳定性降低。现有增强方法的思路之一就是寻找有效策略尽量抵消仿生算法的随机性带来的负面影响。现有技术约束分数的功能是识别样本中具有更好区分能力的属性,被应用于数据挖掘领域并取得了较好效果,例如现有技术cn114818900a一种半监督特征提取方法及用户信用风险评估方法中张莉等人通过迭代计算特征约束分数,并且在迭代中考虑特征间隔分数、特征之间的关联性和特征的判别性,使得所提取出的特征更具代表性、更具判别能力。但是张莉等人所提类别约束分数的推导需要通过迭代计算直至设定阈值,方案实现过程更复杂,计算成本更高,这对扩展到其他算法上实施是不利的。
5.现有仿生算法的增强大都需要预先获取特定生产流程的所有信息,并通过前置知识进行适应度算法选型,再通过大量实验最终选定某一种仿生算法进行应用。这对于算法的增强代价是巨大的。并且现有的已成熟应用的仿生算法家族庞大,对这些算法的增强无法做到即插即用、高效对比。此外,被应用于特征选择过程中的传统约束分数策略不具备对特定类别样本的判别能力,而经过优化的类别约束分数又需要大量的迭代计算,因此缺乏以轻量化形式融入其他算法的优势。
6.鉴于此,我们提出一种更简单易懂且计算量小的约束分数矩阵方案来筛选属性,并将其融合到仿生算法上以提升算法性能。通过脚本语言设计成小巧轻便的可插拔式框架,该框架适应于各类常见的仿生算法,能够有效的在不同业务模式下增强算法效果,从而
做到在增加技术选型算法稳定性的同时提升算法的分类准确率。
技术实现要素:
7.发明目的:本发明旨在提供一种局部约束分数矩阵策略来优化仿生算法初始种群的生成方法,使用更好的初始种群代替原始仿生算法中的初始种群,以增强仿生算法的整体性能。基于这种策略发明的框架具有很好的扩展性,即插即用的特性使其能轻松地应用在不同的仿生算法上,使仿生算法变得简单高效,从而增强仿生算法的性能。
8.技术方案:一种增强仿生算法的可插拔式框架的实现方法,包括以下步骤:
9.步骤一:读取目标任务数据集,获取数据集中的样本属性和类别信息;
10.步骤二:根据步骤一获取的数据信息,结合约束分数概念(constraint score),解析特定类别上成对强链接约束和成对非强链接约束;
11.步骤三:根据步骤二得到的成对强链接约束和成对非强链接约束,计算与属性相关的成对约束分数,在同一决策类下,同类样本距离越近,不同类样本距离越远,成对约束分数最终取值就会越小,所以更小的约束分数值表示通过属性提供的信息区分样本的能力越高;
12.步骤四:利用步骤三获得属性在不同决策类下的约束分数值,可获得行为类别,列为属性的约束分数矩阵;
13.步骤五:使用步骤四得到的约束分数矩阵,识别具有最小局部约束分数值的属性,并将该属性添加到约简池,完成融合局部约束分数概念的初始化种群步骤;
14.步骤六:将步骤五中得到的属性约简池作为不同仿生算法初始化种群。
15.进一步的,所述步骤一具体为:将数据集表示为决策系统d,用u表示数据集中的样本集合,at表示数据集中条件属性集合,m表示数据的属性个数,ar(1≤r≤m)表示数据的某一个属性,l表示数据集所有的类别集合,集合中共有q个类别且q≥2。
16.进一步的,所述步骤二中特定类别l
p
(l
p
∈l)上的成对强链接约束可表示为:
[0017][0018]
上式中的xi,xj分别表示u中任意两个样本,d(xi)=d(xj)则表示样本xi,xj的类别相同且均等于l
p
;
[0019]
特定类别l
p
上的成对非强链接约束可表示为:
[0020][0021]
上式中的d(xi)=l
p
,d(xj)≠l
p
则表示样本xi,xj的类别不同且xi类别为l
p
而xj的类别不等于l
p
。
[0022]
进一步的,所述步骤三中与属性相关的成对约束分数计算公式为:
[0023][0024]
其中ar(xi),ar(xj)分别表示为样本xi、样本xj的属性。
[0025]
进一步的,所述步骤四中约束分数矩阵用下述公式表示:
[0026]mτ
={τ(ar,l
p
)|1≤r≤m,1≤p≤q}。
[0027]
进一步的,所述不同仿生算法包括遗传算法。
[0028]
进一步的,所述不同仿生算法包括森林优化算法。
[0029]
进一步的,所述不同仿生算法包括鱼群算法。
[0030]
进一步的,所述不同仿生算法包括蝙蝠算法。
[0031]
一种计算机存储介质,包括存储器和处理器,存储器上存储有增强仿生算法的可插拔式框架的实现程序,所述增强仿生算法的可插拔式框架的实现程序被至少一个处理器执行时实现上述方法的步骤。
[0032]
有益效果:本发明提供了一种增强仿生算法的可插拔式框架的实现方法,所述框架能很好的解决仿生算法初始化种群质量不可控造成的稳定性差的问题。相较于现有技术只能针对性的优化某一种仿生算法的缺陷,本发明具备即插即用的鲜明特色,可在初始化种群步骤中轻松集成于各类仿生算法,扩展性高,适配性强。此外,本发明优化了约束分数在属性筛选上的应用,采用了更为简单的局部约束分数矩阵,降低了现有技术的计算成本。设计思路更清晰,生产实现更简便,增益明显。在实际生产应用中,结合仿生算法后续使用的三种不同度量(近似质量、条件熵、邻域鉴别指数),相较于没有插入本发明增强框架的原始仿生算法,插入本发明框架后,遗传算法的稳定性平均提升24.86%,森林优化算法的稳定性平均提升12.86%,鱼群算法的稳定性平均提升29.42%,蝙蝠算法的稳定性平均提升32.46%。除此之外,这些仿生算法后续分类任务的表现也有所提高,遗传算法在cart分类器上和knn分类器上的分类准确率平均提升5.68%和3.84%,森林优化算法在cart分类器上和knn分类器上的分类准确率平均提升4%和2.01%,鱼群算法在cart分类器上和knn分类器上的分类准确率平均提升5.69%和4.65%,蝙蝠算法在cart分类器上和knn分类器上的分类准确率平均提升6.45%和4.13%。因此本发明对不同仿生算法均有增强效果,有很高的应用价值。
附图说明
[0033]
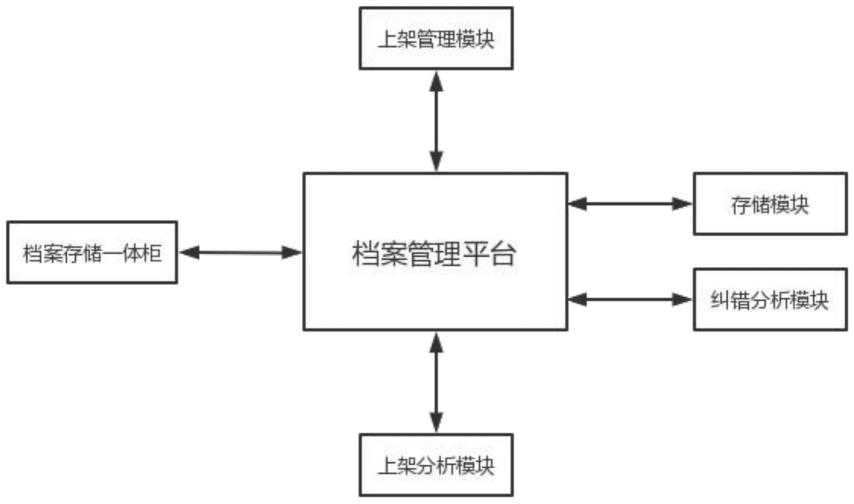
图1为本发明实施例框架设计流程图。
[0034]
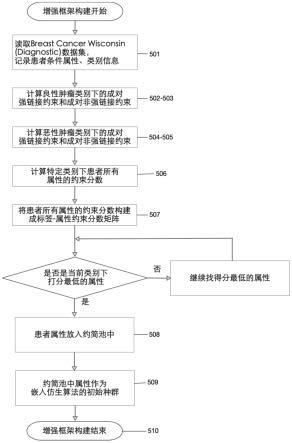
图2为本发明所述构建约束分数矩阵流程图。
[0035]
图3为本发明所述框架集成仿生算法位置示意图。
具体实施方式
[0036]
下面结合附图对本发明的技术方案作进一步说明。
[0037]
本发明提供了一种增强仿生算法的可插拔式框架的实现方法,在所述框架中,对不同的类别依据局部约束分数概念对数据集的属性打分,构建约束分数矩阵,再根据约束分数矩阵筛选数据集中的良好属性作为仿生算法的初始种群。本发明框架使用matlab语言实现,封装成库文件供多种仿生算法使用。初始状态下,仿生算法读取数据集生成初始种群会经过该框架,在此框架的作用下生成表现更好的初始种群用于后续步骤中。考虑到不同的仿生算法适应于不同的应用实例,为了展示本发明可插拔式框架对不同仿生算法的增强效果,以及增强过程的简易便利性。如图1所示,本实施例将使用医学领域乳腺癌患者诊断实例作为示范。展示本发明框架在遗传算法、森林优化算法、鱼群算法、蝙蝠算法这四种常用仿生算法上的增强过程。该数据集breast cancer wisconsin(diagnostic)是由uci机器学习库提供的美国威斯康星州乳腺癌肿瘤患者数据,数据集特征是从患者乳腺肿块的细针
抽吸(fna)的数字化图像计算出来的,其含有总共569个样本,30个特征,良性肿瘤和恶性肿瘤两个类别。
[0038]
选择4种不同仿生算法执行搜索过程前的位置作为框架插入点,由此在该数据集上构建的可插拔式框架的实现流程描述如下:
[0039]
步骤501,读取breast cancer wisconsin(diagnostic)数据集,将其表示为一个决策系统d,其中,u为论域,表示数据集中所有患者样本的集合,at表示数据集中患者条件属性集合、l表示数据集所有的类别集合即良性肿瘤类别l1和恶性肿瘤类别l2;
[0040]
步骤502,根据步骤501解析出的患者信息,对于良性肿瘤类别l1,计算其成对强链接约束:
[0041][0042]
上式中的xi,xj分别表示u中任意两个良性肿瘤患者样本,d(xi)=d(xj)则表示样本xi,xj的类别相同且均等于l1;
[0043]
步骤503,根据步骤501解析出的患者信息,对于良性肿瘤类别l1,计算其成对非强链接约束:
[0044][0045]
上式中的d(xi)=l1,d(xj)≠l1则表示样本xi,xj的类别不同且xi类别为l1而xj的类别不等于l1;
[0046]
步骤504,根据步骤501解析出的患者信息,对于恶性肿瘤类别l2,计算其成对强链接约束:
[0047][0048]
上式中的xi,xj分别表示u中任意两个恶性肿瘤患者样本,d(xi)=d(xj)则表示样本xi,xj的类别相同且均等于l2;
[0049]
步骤505,根据步骤501解析出的患者信息,对于恶性肿瘤类别l2,计算其成对非强链接约束:
[0050][0051]
上式中的d(xi)=l1,d(xj)≠l2则表示样本xi,xj的类别不同且xi类别为l2而xj的类别不等于l2;
[0052]
步骤506,利用以上步骤502和步骤505获得的类别成对强链接约束和类别成对非强链接约束,以l
p
表示某一确定类别,对于乳腺癌患者的所有条件属性ar,计算与ar相关的成对约束分数:
[0053][0054]
步骤507,由步骤506获得的乳腺癌患者所有条件属性分别在良性肿瘤、恶性肿瘤这两种不同决策类下的约束分数值,可获得行为类别,列为属性的约束分数矩阵。该矩阵用下述公式表示:
[0055]mτ
={τ(ar,l
p
)|1≤r≤m,1≤p≤q}
[0056]
并由计算结果构建类别-属性约束分数矩阵;
[0057]
步骤508,在类别-属性约束分数矩阵中选择对应类别得分最低的属性放入约简
池;
[0058]
步骤509,将约简池中的属性作为初始种群传入仿生算法;
[0059]
步骤510,构建增强仿生算法的可插拔式框架过程结束。
[0060]
综上所述,本发明通过考虑仿生算法在属性约简问题求解中的局限性,开发了一种基于约束分数指导的新框架。通过约束得分,可以发现具有更好区分性的潜在属性,从而为后续的元启发式搜索初始化种群。此外,本发明使用的约束分数是通过局部视图设计的,它可以捕捉每个类别上属性的可区分性。因此,通过局部约束分数对属性的评估比传统约束分数更全面。本发明最值得指出的是其可插拔式的设计方案,可轻松嵌入各类仿生算法。本发明在实际应用中集成于经典的遗传算法、森林优化算法、鱼群算法和蝙蝠算法,插入本发明框架的仿生算法在导出约简的稳定性和相关分类性能(即分类稳定性和分类精度)方面都具有竞争力。因此,本技术具有很高的应用价值。
[0061]
本发明提供了一种增强仿生算法的可插拔式框架的实现方法,具体实现该技术方案的方法和途径很多,以上所述仅是本发明的优选实施方式。本发明在作为可插拔式框架同样可以作用于其他仿生算法并获得增强效果。采用本框架对其他仿生算法做出的改进也应视为本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰同样应视为本发明的保护范围。本实施例中未明确的各组成部份均可用现有技术加以实现。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。