1.本发明属于图像处理技术领域,具体涉及一种基于深度技术的水下风格化图像生成方法。
背景技术:
2.受限于水下复杂的成像环境以及拍摄手段的限制,所能获取的水下图像资源及其匮乏,且人工成本过高,故水下图像生成技术的研究成为目前的研究热点。水下图像的生成方法主要分为两类:基于传统物理成像模型的生成方法和基于深度模型的生成方法。基于传统物理模型的生成方法主要是依靠特定水域的先验知识(如:特定水深处光的衰减系数等)以及深度信息来模拟水下图像的质量退化过程。深度学习技术在2012年左右被提出,鉴于其强大的非线性建模能力和数据特征学习能力,深度模型在水下图像生成领域有着广阔的应用前景。
3.专利cn202210418314.8公开了一种基于改进cycle gan的图像生成方法,包括从x域图像数据库中获取输入图像;将所述输入图像输入至编码器并输出特征图像;将所述特征图像输入至特征权重自适应模块,对所述特征图像提取背景信息和目标特征信息,并针对提取的背景信息和目标特征信息进行不同权重的特征融合;将处理后的特征图像依次输入至转换器和解码器中还原生成输出图像。
4.专利cn202210536540.6公开了一种场景图像生成方法,应用于客户端,方法包括:获取第一相机参数、第一场景图像及多个第一像素点的第一空间信息,第一场景图像为虚拟相机根据第一相机参数拍摄获得;向服务器输出交互指令以使服务器生成第二相机参数,并控制虚拟相机根据第二相机参数拍摄目标场景获得第二场景图像;获取服务器根据第二场景图像生成的场景图像编码并提取出目标单元编码;解析目标单元编码获取目标单元的第二空间信息,并根据第一空间信息、第二空间信息、第一相机参数及交互指令确定参考像素点;根据第一场景图像与参考像素点确定第二像素点的像素信息;根据多个第二像素点的像素信息生成目标场景图像。
5.以上两种技术方案的目的都是通过对原始图像进行编码处理并最终生成目标图像,前者为基于深度模型的图像生成方法,后者为基于传统模型的图像生成方法。但现有方法存在一定的局限性,具体包括:基于传统物理成像模型的方法高度依赖水下场景中的先验知识,无可避免的存在估计误差,故生成效果与真实样本有较大差异。而基于深度技术的方法受到水下数据短缺的限制,无法满足数据驱动的深度模型训练的需求。
技术实现要素:
6.本发明的目的在于提供一种基于深度技术的水下风格化图像生成方法,该方法有利于生成更具真实性和多样性的水下风格化图像。
7.为实现上述目的,本发明采用的技术方案是:一种基于深度技术的水下风格化图像生成方法,包括以下步骤:
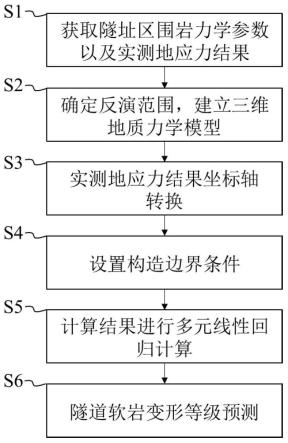
8.s1、利用图像处理技术对原始水下数据集进行数据扩充,扩大其数量规模,得到扩充后数据集;
9.s2、预估扩充后数据集中水下图像所对应的深度图;
10.s3、采用高斯低通滤波器对扩充后数据集中水下图像进行平滑处理,生成相应的光场图并获得水下场景中各像素点处的光强度信息;
11.s4、在u-net模型的基础上增加基于注意力机制的特征融合操作和批量归一化操作,构建改进后的u-net模型;将原始水下图像和深度图输入改进后的u-net模型,结合模型输出和光场图,得到水下风格化图像。
12.进一步地,所述步骤s1中,利用图像处理技术对原始水下数据集进行数据扩充,具体实现方法为:
13.在符合实际和人类认知,以及不改变样本场景分布特性的前提下,通过对uieb数据集中原始图像分别进行包括顺时针或逆时针旋转设定角度、水平翻转以及注入噪声的物理变换的方式得到扩充图像,进而得到扩充后数据集,为后续的生成模型训练以及深度估计工作做准备。
14.进一步地,所述步骤s2中,预估扩充后数据集中水下图像所对应的深度图,具体实现方法为:
15.利用预训练的hourglass网络来预估深度图,并根据预估的深度信息和地面真实的深度信息之间的差异具有放缩不变性,通过放缩不变的损失函数l
si
来对hourglass网络进行联合优化,l
si
的计算式如下式所示:
16.l
si
=l
data
αl
gra
βl
ord (1)
17.其中,l
data
,l
gra
和l
ord
分别为深度数据损失项、多尺度的梯度匹配损失项和鲁棒的有序深度损失项,α和β为模型可自动学习的参数;设预测的深度图为l,地面真实深度图为l
*
,则定义像素点i处的预估差值为故深度数据损失项l
data
如下式所示:
[0018][0019]
其中,n表示深度图中像素点的个数;
[0020]
为了让预测的深度图梯度变化更加平滑,减少尖锐梯度值的出现频率,对于不同尺度下的深度图计算梯度匹配损失项l
gra
如下式所示:
[0021][0022]
其中,k为尺度变换因子,x、y分别表示在像素点i处的横轴方向和纵轴方向;
[0023]
有序深度损失项的表达式如下式所示:
[0024][0025]
其中,p
i,j
为自动标记的有序深度关系变量,c为常量,(i,j)为图像中的一组像素点对,τ=0.25。
[0026]
进一步地,所述步骤s3中,采用高斯低通滤波器对扩充后数据集中水下图像进行平滑处理,生成相应的光场图并获得水下场景中各像素点处的光强度信息,具体实现方法
为:
[0027]
利用一个卷积模板来扫描图像中的每一个像素,并使用模板内所有像素点加权平均的结果代替模板中心像素点处的值,从而消除高频信号的影响,让图像效果更加平滑;高斯低通滤波的二维形式如下式所示:
[0028][0029]
其中,h(i,j)表示卷积模板内索引为(i,j)处的像素点对于中心像素点的影响系数;d(i,j)为索引为(i,j)处的像素点到频率中心,即模板中心像素点的距离,σ=d0,即到频率中心的截止频率;d0值越大,低通滤波器的带宽就越宽,越多的低频分量被保留下来;反之,d0值越小,低通滤波器的带宽就越窄,越少的低频分量被保留下来,导致大量的细节信息的丢失;故选用了三种不同的σ来对输入图像x
in
进行滤波处理再平均,如下式所示:
[0030][0031]
其中,gauss()表示高斯低通滤波处理操作,处理对象为整张输入图像x
in
,xg为生成的光场图。
[0032]
进一步地,所述步骤s4中,在u-net模型的基础上增加基于注意力机制的特征融合操作和批量归一化操作,构建改进后的u-net模型,具体实现方法为:
[0033]
基于u-net模型架构,在u-net模型中的每个卷积操作之后都进行基于注意力机制的特征融合操作,以提取水下图像中整体和局部特征信息,从而避免重要特征信息的丢失,并强化最终生成图像的真实性;为了避免训练过程中出现梯度异常的现象,在各个基于注意力机制的特征融合操作之后,再进行批量归一化操作,以保证数据的稳定性;从而得到改进后的u-net模型。
[0034]
进一步地,所述步骤s4中,将原始水下图像和深度图输入改进后的u-net模型,结合模型输出和光场图,得到水下风格化图像,具体实现方法为:
[0035]
利用改进后的u-net取代原始gan中的生成器部件来实现直接透射衰减分量x
la
的模拟,如下式所示:
[0036]
x
la
=ug(x,xg) (7)
[0037]
其中,ug为改进后的u-net,在编码端子网输入原始水下图像x,在解码端子网还额外输入hourglass网络预估得到的深度信息xg;为了模拟产生反向散射衰减分量x
sa
,引入与x
la
维度大小相同的随机矩阵变量w,进行点乘操作,如下式所示:
[0038]
x
sa
=w*x
la (8)
[0039]
结合所产生的直接透射衰减分量x
la
、反向散射衰减分量x
sa
和光场图xg,利用下式生成水下风格化图像x
us
:
[0040]
x
us
=x
la
xg*x
sa (9)
[0041]
通过上述操作,即实现用深度技术模拟产生逼真的水下风格化图像。
[0042]
与现有技术相比,本发明具有以下有益效果:提供了一种基于深度技术的水下风格化图像生成方法,该方法在u-net模型的基础上增加基于注意力机制的特征融合操作和批量归一化操作来构建改进后的u-net模型;该模型能够有效提取原始水下图像中不同局部区域的特征信息,避免重要特征信息的丢失,还能够自适应的模拟生成直接透射衰减分
量以及反向散射衰减分量;再结合获取的光场信息和深度信息,在ug子网和鉴别器的对抗博弈下,能够实现水下风格化图像的生成。本发明方法较传统方法生成性能更好,生成结果更具真实性和多样性。
附图说明
[0043]
图1是本发明实施例中hourglass网络的架构图;
[0044]
图2是本发明实施例中高斯低通滤波器的架构图;
[0045]
图3是本发明实施例的方法实现原理图。
具体实施方式
[0046]
下面结合附图及实施例对本发明做进一步说明。
[0047]
应该指出,以下详细说明都是示例性的,旨在对本技术提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本技术所属技术领域的普通技术人员通常理解的相同含义。
[0048]
需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本技术的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。
[0049]
如图1-3所示,本实施例提供了一种基于深度技术的水下风格化图像生成方法,包括以下步骤:
[0050]
s1、利用图像处理技术对原始水下数据集进行数据扩充,扩大其数量规模,得到扩充后数据集。
[0051]
在本实施例中,所述步骤s1的具体实现方法为:
[0052]
在符合实际和人类认知,以及不改变样本场景分布特性的前提下,通过对uieb数据集(共890张)中原始图像分别进行包括顺(逆)时针旋转设定角度、水平翻转以及注入噪声等物理变换的方式得到扩充图像,进而得到扩充后数据集,扩充后的数据集样本总量共计8000张,为后续的生成模型训练以及深度估计工作做准备。
[0053]
s2、预估扩充后数据集中水下图像所对应的深度图。
[0054]
在本实施例中,所述步骤s2的具体实现方法为:
[0055]
利用预训练的hourglass网络来预估深度图,并根据预估的深度信息和地面真实的深度信息之间的差异具有放缩不变性,通过放缩不变的损失函数l
si
来对hourglass网络进行联合优化,l
si
的计算式如下式所示:
[0056]
l
si
=l
data
αl
gra
βl
ord (1)
[0057]
其中,l
data
,l
gra
和l
ord
分别为深度数据损失项、多尺度的梯度匹配损失项和鲁棒的有序深度损失项,α和β为模型可自动学习的参数;设预测的深度图为l,地面真实深度图为l
*
,则定义像素点i处的预估差值为故深度数据损失项l
data
如下式所示:
[0058]
[0059]
其中,n表示深度图中像素点的个数。
[0060]
为了让预测的深度图梯度变化更加平滑,减少尖锐梯度值的出现频率,对于不同尺度下的深度图计算梯度匹配损失项l
gra
如下式所示:
[0061][0062]
其中,k为尺度变换因子,x、y分别表示在像素点i处的横轴方向和纵轴方向;借助l
gra
可以使得最终预估的深度图梯度与地面真实的深度图梯度相匹配,并且保证了梯度稳定性。
[0063]
有序深度损失项的表达式如下式所示:
[0064][0065]
其中,p
i,j
为自动标记的有序深度关系变量,c为常量,(i,j)为图像中的一组像素点对,τ=0.25。l
ord
的目的就在于相对减小图像内部像素点之间的相对深度关系对于整个深度图成像效果的影响,从而使得所生成的深度图更具鲁棒性。
[0066]
s3、采用高斯低通滤波器对扩充后数据集中水下图像进行平滑处理,生成相应的光场图并获得水下场景中各像素点处的光强度信息。
[0067]
在本实施例中,所述步骤s3的具体实现方法为:
[0068]
高斯滤波就是对整幅图像进行加权的过程,利用一个卷积模板来扫描图像中的每一个像素,并使用模板内所有像素点加权平均的结果代替模板中心像素点处的值,从而消除高频信号的影响,让图像效果更加平滑;高斯低通滤波的二维形式如下式所示:
[0069][0070]
其中,h(i,j)表示卷积模板内索引为(i,j)处的像素点对于中心像素点的影响系数;d(i,j)为索引为(i,j)处的像素点到频率中心,即模板中心像素点的距离,σ=d0,即到频率中心的截止频率;d0值越大,低通滤波器的带宽就越宽,越多的低频分量被保留下来;反之,d0值越小,低通滤波器的带宽就越窄,越少的低频分量被保留下来,导致大量的细节信息的丢失;故选用了三种不同的σ来对输入图像x
in
进行滤波处理再平均,如下式所示:
[0071][0072]
其中,gauss()表示高斯低通滤波处理操作,处理对象为整张输入图像x
in
,xg为生成的光场图。
[0073]
s4、在u-net模型的基础上增加基于注意力机制的特征融合操作和批量归一化操作,构建改进后的u-net模型,命名为ulpgan模型。将原始水下图像和深度图输入ulpgan模型,结合模型输出和光场图,得到水下风格化图像。
[0074]
ulpgan模型的构建:基于u-net模型架构,在u-net模型中的每个卷积操作之后都进行基于注意力机制的特征融合操作,以提取水下图像中整体和局部特征信息,从而避免重要特征信息的丢失,并强化最终生成图像的真实性;为了避免训练过程中出现梯度异常的现象,在各个基于注意力机制的特征融合操作之后,再进行批量归一化操作,以保证数据
的稳定性;从而得到改进后的u-net模型,即ulpgan模型。
[0075]
由于水下图像中常见的颜色失真和局部区域模糊现象分别是由于不同的因素所所导致的,利用改进后的u-net取代原始gan中的生成器部件来实现直接透射衰减分量x
la
的模拟,如下式所示:
[0076]
x
la
=ug(x,xg) (7)
[0077]
其中,ug为改进后的u-net,在编码端子网输入原始水下图像x,在解码端子网还额外输入hourglass网络预估得到的深度信息xg;为了模拟产生反向散射衰减分量x
sa
,引入与x
la
维度大小相同的随机矩阵变量w,进行点乘操作,如下式所示:
[0078]
x
sa
=w*x
la (8)
[0079]
结合所产生的直接透射衰减分量x
la
、反向散射衰减分量x
sa
和光场图xg,利用下式生成水下风格化图像x
us
:
[0080]
x
us
=x
la
xg*x
sa (9)
[0081]
通过上述操作,即实现用深度技术模拟产生逼真的水下风格化图像。
[0082]
为了能够验证本发明所提出的基于深度技术的水下风格化图像生成方法的有效性,通过采用主观人眼视觉感知判断以及客观指标评估两方面来进行衡量。
[0083]
由于深度技术依赖于硬件设备以及软件设置,故有必要介绍相关的预设条件以及模型参数配置。本次实验所采用的硬件平台为:nvidiageforce gtx 1080ti。编程语言为:python3.6。学习率大小设置为0.002,共训练了200个周期,批量大小设置为32。采用了亚当优化器,一阶动量和二阶动量分别设为0.9和0.999。同时,为了减轻计算成本,还将输入的样本大小都裁剪为256*256*3。
[0084]
评价指标的选取方面,本次实验选用了fid、psnr、ssim和uiqm指标来对生成结果进行客观评估。其中,fid直接测量生成样本与真实样本再特征级别上的距离大小,值越小,就说生成结果与真实样本的特征相似程度越高,生成结果越逼真。uiqm则是为了评估水下图像质量而专门设计的指标,通过对生成图像按像素级别进行计算,在不考虑结构信息的前提下,定量地评估水下图像的色彩属性(uicm)、清晰度属性(uism)以及对比度属性(uiconm)。区别于uiqm指标不需要参考图像就能进行计算,本实验还特定采用了全参考指标psnr和ssim指标来评估生成样本是否有效保留了真实样本中的结构分布。
[0085]
本次实验选用的对比算法算法包括:watergan、ugan、cyclegan、ipmgan以及uwnr,上述算法都是利用深度技术来实现风格化水下图像的生成,且都取得了优越的生成效果。本实验用扩充后的uieb数据集来训练上述模型,并采用fid、psnr、ssim和uiqm指标对ulpgan和对比算法进行定量评估,评估结果如表1所示。
[0086]
表1本方法与气体算法对比
[0087]
对比算法waterganuwnrcycleganuganipmganulpganssim0.730.770.740.570.810.79psnr20.7519.3222.3218.6623.5423.59uiqm0.520.510.530.470.530.55fid233.04221.93225.72220.35226.68221.83
[0088]
从表1可以看出,ulpgan在上述四个指标都取得最好的成绩,这也反应了由ulpgan所生成的图像的真实性和多样性显著优于现有的方法,ulpgan的生成性能优越。
[0089]
以上所述,仅是本发明的较佳实施例而已,并非是对本发明作其它形式的限制,任何熟悉本专业的技术人员可能利用上述揭示的技术内容加以变更或改型为等同变化的等效实施例。但是凡是未脱离本发明技术方案内容,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化与改型,仍属于本发明技术方案的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。