1.本技术涉及文本处理技术领域,具体而言,本技术涉及一种公证文书生成方法、装置、电子设备及存储介质。
背景技术:
2.作为公证人公证权的体现,公证文书在司法活动和日常证明活动中扮演着极为重要的角色。因此,出具一份形式规范、内容合法有效的公证文书更是公证机构最重要的职责所在。然而,人工编写的公证文书,其质量完全取决于公证员的业务水平和公证机构的严格完备的审核机制和审核能力。为了提高公证文书的编写水平,公证机构不得不投入更多资源在对公证员的编写能力的培训上。即使这样,依然无法确保公证文书质量的稳定性。这就导致现如今出具代表国家赋权证明力的公证文书质量参差不齐。
3.由此可知,如何提高公证文书的编写效率,稳定公证文书的出证质量成为了亟需解决的问题。
技术实现要素:
4.本技术各实施例提供了一种公证文书生成方法、装置、电子设备及存储介质,可以解决相关技术中存在的公证文书的编写依靠人工,效率低下,出具的公证文书的质量不稳定的问题。所述技术方案如下:
5.根据本技术实施例的一个方面,一种公证文书生成方法,所述方法包括:获取案件信息,并基于所述案件信息构建案件信息图谱;将所述案件信息图谱与公证领域图谱进行知识融合,生成公证文书个案图谱;确定公证文书模板中的参数,并在所述公证文书个案图谱中查找与所述参数对应的案件信息;将查找到的所述案件信息,填充至所述公证文书模板中所述参数所在的位置,生成公证文书。
6.在一示例性实施例中,所述获取案件信息,包括:采集证明材料和/或访谈笔录;从所述证明材料和/或所述访谈笔录中,提取得到所述案件信息。
7.在一示例性实施例中,所述采集访谈笔录,包括:查询问题引导策略树,确定当前一个问题节点;获取针对所述当前一个问题节点的答复,在问答知识图谱中查找与所述答复中命名实体匹配的第一实体;根据查找到的所述第一实体,从所述问答知识图谱中得到针对所述当前一个问题节点的答案;接收针对所述答案的反馈消息,基于所述反馈消息继续查询所述问题引导策略树,直至所述问题引导策略树查询完毕;基于查询到的各问题节点中的问题及对应的答复和答案,生成所述访谈笔录。
8.在一示例性实施例中,所述将所述案件信息图谱与公证领域图谱进行知识融合,生成公证文书个案图谱,包括:第二实体第三实体第二实体第三实体获取所述公证领域图谱中的第二实体和所述案件信息图谱中的第三实体,并确定各所述第二实体与各所述第三实体的相似性;基于所确定的相似性,确定相似的所述第二实体和所述第三实体的对应关系;基于所确定的对应关系,将所述案件信息图谱中的案件信息嵌入所述公证领域图谱的
实例层,得到所述公证文书个案图谱。
9.在一示例性实施例中,所述基于所确定的对应关系,将所述案件信息图谱中的案件信息嵌入所述公证领域图谱的实例层,得到所述公证文书个案图谱,包括:基于所述对应关系,对相似的所述第二实体和所述第三实体进行实体对齐和/或共指消解;实体对齐和/或共指消解后,将所述案件信息图谱的所述第二实体链指至所述公证领域图谱对应的所述第三实体,得到所述公证文书个案图谱。
10.在一示例性实施例中,所述在所述公证文书个案图谱中查找与所述参数对应的案件信息,包括:通过正则匹配方式,在所述公证文书个案图谱中查找与所述参数匹配的候选实体;所述候选实体进行实体消歧得到目标实体;在所述公证文书个案图谱的实例层,查询与所述目标实体匹配的案件信息,作为与所述参数对应的案件信息。
11.在一示例性实施例中,训练集包括案件信息、历史公证文书和公证涉及的法律文书,知识图谱包括案件信息图谱和公证领域图谱;所述方法还包括:根据所述训练集构建所述知识图谱;所述根据所述训练集构建所述知识图谱,包括:对所述训练集中的命名实体进行识别,得到多个所述命名实体;命名实体包括所述案件信息中的第二实体、所述历史公证文书中的第三实体;采用基于规则的关系提取算法,提取得到各所述命名实体间的关系;将各所述命名实体分别存储至各节点,并将对应两个所述命名实体间的关系作为连接相邻节点的路径;由各所述节点及路径,构建得到所述知识图谱。
12.根据本技术实施例的一个方面,一种公证文书生成装置,所述装置包括:信息图谱构建模块,用于获取案件信息,并基于所述案件信息构建案件信息图谱;知识融合模块,用于将所述案件信息图谱与公证领域图谱进行知识融合,生成公证文书个案图谱;案件信息查找模块,用于确定公证文书模板中的参数,并在所述公证文书个案图谱中查找与所述参数对应的案件信息;文书生成模块,用于将查找到的所述案件信息,填充至所述公证文书模板中所述参数所在的位置,生成公证文书。
13.根据本技术实施例的一个方面,一种电子设备,包括:至少一个处理器、至少一个存储器、以及至少一条通信总线,其中,所述存储器上存储有计算机程序,所述处理器通过所述通信总线读取所述存储器中的所述计算机程序;所述计算机程序被所述处理器执行时实现如上所述的公证文书生成方法。
14.根据本技术实施例的一个方面,一种存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现如上所述的公证文书生成方法。
15.本技术提供的技术方案带来的有益效果是:
16.在上述技术方案中,获取案件信息并基于案件信息构建案件信息图谱;将案件信息图谱与公证领域图谱进行知识融合,生成公证文书个案图谱;确定公证文书模板中的参数,并从公证文书个案图谱中查找参数对应的案件信息;将案件信息替换到公证文书模板中参数所在的位置,生成公证文书。也就是说,利用公证文书具有范式特点,构建案件信息图谱与公证领域图谱,并通过查询知识融合后的公证文书个案图谱,读取公证文书模板中参数对应的案件信息,将案件信息填充到公证文书模板的参数所在位置,从而快速地自动生成公证文书,由此取代了人工生成公证文书,保证了生成公证文书质量的稳定,从而能够有效地解决相关技术中存在的公证文书的编写依靠人工,效率低下,出具的公证文书的质量不稳定的问题。
附图说明
17.为了更清楚地说明本技术实施例中的技术方案,下面将对本技术实施例描述中所需要使用的附图作简单地介绍。
18.图1是本技术所涉及的实施环境示意图;
19.图2是根据一示例性实施例示出的公证文书生成方法的流程图;
20.图3是根据一示例性实施例示出的案件信息图谱的示意图;
21.图4是根据一示例性实施例示出的命名实体预测模型训练过程的流程图;
22.图5是根据一示例性实施例示出的公证领域图谱的构建过程的流程图;
23.图6是图2对应实施例中步骤230在一个实施例的流程图;
24.图7是图5对应实施例中步骤235在一个实施例的流程图;
25.图8是是根据一示例性实施例示出的链指过程的示意图;
26.图9是图2对应实施例中步骤250在一个实施例的流程图;
27.图10是根据一示例性实施例示出的获取案件信息过程的流程图;
28.图11是根据一示例性实施例示出的采集访谈笔录过程的流程图;
29.图12是根据一示例性实施例示出的问答知识图谱的构建过程的流程图;
30.图13是一应用场景中一种公证文书生成方法的具体实现示意图;
31.图14是根据一示例性实施例示出的一种公证文书生成装置的结构框图;
32.图15是根据一示例性实施例示出的一种服务器的结构示意图;
33.图16是根据一示例性实施例示出的一种电子设备的硬件结构图。
具体实施方式
34.下面详细描述本技术的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本技术,而不能解释为对本技术的限制。
35.本技术领域技术人员可以理解,除非特意声明,这里使用的单数形式“一”、“一个”、“所述”和“该”也可包括复数形式。应该进一步理解的是,本技术的说明书中使用的措辞“包括”是指存在所述特征、整数、步骤、操作、元件和/或组件,但是并不排除存在或添加一个或多个其他特征、整数、步骤、操作、元件、组件和/或它们的组。应该理解,当我们称元件被“连接”或“耦接”到另一元件时,它可以直接连接或耦接到其他元件,或者也可以存在中间元件。此外,这里使用的“连接”或“耦接”可以包括无线连接或无线耦接。这里使用的措辞“和/或”包括一个或更多个相关联的列出项的全部或任一单元和全部组合。
36.如前所述,目前的公证文书生成方法的缺点是公证文书的编写依靠人工,效率低下,出具的公证文书的质量不稳定。
37.在当下依然有很多公证事务需要依靠公证员手动、脑力操作才能完成;例如,撰写公证文书。撰写公证文书是公证员日常业务中必不可少的工作,这里所说的公证文书是指贯穿于公证事务整个流程所产生的过程文件和结果文件,包括但不限于访谈笔录、告知书、受理通知书、公证书等。由于公证事务的多且杂,公证员在编写公证文书时要投入大量精力做着重复性劳动,无疑造成人力资源的极大浪费。
38.此外,公证文书在司法活动和日常证明活动中扮演着极为重要的角色,尤其是具
有特殊司法证明效力的公证书,被视为公证文书的重要种类。因此,出具一份形式规范、内容合法有效的公证文书更是公证机构最重要的职责所在。然而,人工编写的公证文书,其质量完全取决于公证员的业务水平和公证机构的严格完备的审核机制和审核能力,无法确保公证文书质量的稳定性。这就导致现如今出具代表国家赋权证明力的公证文书质量参差不齐。为了提高公证文书的撰写水平,公证机构不得不投入更多资源在对公证员的撰写能力的培训上。即使这样,依然无法确保公证文书质量的稳定性。
39.因此,如果在撰写公证文书时,减少对人工的依赖性,将公证文书的撰写智能化,可以理解,这将大大提高撰写公证文书的效率,并提高公证文书的撰写质量,从而减少人力资源的浪费。
40.由上可知,相关技术中仍存在公证文书的编写依靠人工,效率低下,出具的公证文书的质量不稳定的缺陷。
41.为此,本技术提供的公证文书生成方法能够自动生成公证文书,避免依赖于人工编写公证文书,从而有效地提高公证文书的编写效率,充分地保证公证文书的出证质量,相应地,该公证文书生成方法适用于公证文书生成装置,该公证文书生成装置可部署于电子设备,该电子设备可以是配置冯诺依曼体系结构的计算机设备,例如,该计算机设备可以是台式电脑、笔记本电脑、服务器等等。
42.为使本技术的目的、技术方案和优点更加清楚,下面将结合附图对本技术实施方式作进一步地详细描述。
43.图1为一种公证文书生成方法所涉及的一种实施环境的示意图。需要说明的是,该种实施环境只是一个适配于本发明的示例,不能认为是提供了对本发明的使用范围的任何限制。
44.该实施环境包括采集端110和服务端130。
45.具体地,采集端110,可以是具有采集图片、文本、多媒体中至少一种或多种数据功能的电子设备,在此不构成具体限定。
46.服务端130,该服务端130可以是台式电脑、笔记本电脑、平板电脑、服务器等等电子设备,还可以是由多台服务器构成的计算机设备集群,甚至是由多台服务器构成的云计算中心。其中,服务端130用于提供后台服务,例如,后台服务包括但不限于公证文书生成服务等等。
47.服务端130与采集端110之间通过有线或者无线等方式预先建立网络通信连接,并通过该网络通信连接实现服务端130与采集端110之间的数据传输。传输的数据包括但不限于:案件信息等等。
48.通过采集端110与服务端130的交互,采集端110从证明材料和/或访谈笔录中采集得到案件信息,并将案件信息发送给服务端130,服务端130结合知识图谱对获取到的案件信息进行处理,便能够将公证文书模板转换生成为公证文书的正式文本。
49.当然,根据实际营运的需要,采集端110和服务端130也可以整合在同一台服务器内,以使公证文书的生成由该同一台服务器完成,此处并非构成具体限定。
50.请参阅图2,本技术实施例提供了一种公证文书生成方法。该方法适用于电子设备,例如,该电子设备具体可以是计算机设备。
51.在下述方法实施例中,为了便于描述,以该方法各步骤的执行主体为电子设备为
例进行说明,但是并非对此构成具体限定。
52.如图2所示,该方法可以包括以下步骤:
53.步骤210,获取案件信息,并基于案件信息构建案件信息图谱。
54.其中,案件信息是指基于当事人提供的证明材料、访谈笔录等公证事务相关的信息。也就是说,在一种可能的实现方式,案件信息可以来自于证明材料,还可以来自于访谈笔录。
55.以“房屋买卖合同公证”的公证事务为例,当事人提供包括身份证明、房屋的所有权证明在内的证明材料,以使公证方从证明材料中获取当事人身份信息、房屋信息等案件信息。
56.在获得案件信息后,便能够以案件信息作为训练集,构建案件信息图谱。换而言之,案件信息图谱基于个案的案件信息构建,即案件信息图谱中存储了个案的案件信息。
57.在一种可能的实现方式,案件信息图谱的构建过程,可以包括以下步骤:对案件信息中的命名实体进行识别,得到多个第二实体;采用基于规则的关系提取算法,提取得到各第二实体间的关系;将各第二实体分别存储至节点,并基于各所述命名实体间的关系在对应节点间构建路径;由各节点及路径,构建得到案件信息图谱。其中,命名实体识别可以通过基于规则、无监督学习、有监督学习、深度学习等方法实现,在此不作限定。除了基于规则的关系提取算法,第二实体间的关系还可以通过预定义关系类型、深度学习等方法实现,此处并非构成具体限定。图3展示了案件信息图谱的示意图,在图3中,当事人甲方xxx和当事人乙方yyy,分别提供包含自身身份信息的身份证明(name、id card no.)、与a房屋进行房屋转让的房屋信息证明(property、location)等证明材料,根据上述证明材料构建的案件信息图谱包括多个节点,通过该多个节点以key-value方式存储房屋转让前后的所有人信息及房屋信息等案件信息。
58.步骤230,将案件信息图谱与公证领域图谱进行知识融合,生成公证文书个案图谱。
59.如前所述,案件信息图谱由多个节点及路径构建,该节点用于存储案件信息中的命名实体,该路径用于存储案件信息中各命名实体间的关系。同理,公证领域知识图谱由多个节点及路径构成,该节点用于存储历史公证文书和公证涉及的法律文书中的命名实体,该路径则用于存储历史公证文书和公证涉及的法律文书中各命名实体间的关系。
60.在一种可能的实现方式,公证领域图谱的构建过程,可以包括以下步骤:对历史公证文书和公证涉及的法律文书中的命名实体进行识别,得到多个第三实体;采用基于规则的关系提取算法,提取得到多个第三实体间的关系;将各第三实体分别存储至节点,并基于各第三实体间的关系在对应节点间构建路径;由各节点及路径,构建得到公证领域图谱。其中,命名实体识别可以通过基于规则、无监督学习、有监督学习、深度学习等方法实现,在此不作限定。除了基于规则的关系提取算法,第三实体间的关系还可以通过预定义关系类型、深度学习等方法实现,此处并非构成具体限定。
61.下面结合图4至图5,对公证领域图谱的构建过程进行详细地说明:
62.在一种可能的实现方式,命名实体识别是调用基于深度学习的命名实体预测模型实现的。其中,该命名实体预测模型是由神经网络模型训练得到的,具体训练过程如图4所示。
63.步骤301,获取历史公证文书和公证涉及的法律文书。
64.其中,历史公证文书包括但不限于:通过光学字符识别(ocr,optical characterrecognition)技术由公证纸卷文书获取的非结构化数据,以及通过公证服务平台数据库获取的结构化数据。
65.步骤303,构建语料库。
66.具体地,将ocr技术获取的非结构化数据转化成结构化数据,并结合公证服务平台数据库中的结构化数据,组成语料库。
67.步骤305,根据标注规则,生成标注后的公证文本。
68.具体地,配置标注规则,以基于标注规则对语料库中的历史公证文书和公证涉及的法律文书进行标注,生成标注后的公证文本。应当说明的是,标注规则是依照公证相关的法律(比如《民法典》)、法规、司法解释等进行配置的。
69.其中,标注规则可以是bio标注规则(b-命名实体的前缀,i-命名实体的非前缀,o-非命名实体),也可以是bioes标注规则(b-命名实体的前缀,i-命名实体的非前缀,o-非命名实体,e-命名实体的后缀,s-独立词)等,在此不作限定。以bio标注规则为例,该房屋属于甲某,则标注为“b(该)i(房)i(屋)o(属)o(于)b(甲)i(某)”。
70.步骤307,对标注后的公证文本进行独热编码,并输入embedding层。
71.具体而言,对标注后的公证文本进行独热编码得到独热向量,然后再通过嵌入embedding层的字符嵌入矩阵,将独热向量转换为字符向量。
72.步骤309,将字符向量输入bilstm模块。
73.具体地,将字符向量作为双向长短时记忆bilstm模块的输入,以便于开始bilstm模型的训练。
74.步骤311,将bilstm模块输出的各类标注分数经过处理后输入crf模块,获得参数初始化的命名实体预测模型。
75.具体地,将bilstm模块输出的各类标注分数经过处理后,首先输入crf模块;然后通过crf模块根据相邻词性标注间关系,获取bilstm模块输出的标注序列最优解,即获得参数初始化的命名实体预测模型。
76.步骤313,超参数优化,得到命名实体预测模型。
77.具体而言,在bilstm-crf模型训练中,采用丢弃dropout技术,即每次训练时随机丢弃一部分神经元,被丢弃掉的神经元对于传播不会产生影响,使得网络不过多依赖于神经元权重改变的方法来进行调参,以缓解过拟合问题。
78.收集并保存每次训练获得的最优参数,并将通过测试后的bilstm-crf模型封装成命名实体预测模型。
79.待上述训练过程完成,该命名实体预测模型便具备了适用于历史公证文书的命名实体识别能力,便能够对历史公证文书进行命名实体识别,得到历史公证文书中的第三实体,以进行公证领域图谱的构建。如图5所示,在一种可能的实现方式,公证领域图谱的构建过程可以包括以下步骤:
80.步骤331,获取历史公证文书和公证涉及的法律文书,并对历史公证文书和公证涉及的法律文书进行命名实体识别,得到若干个命名实体。
81.如前所述,可以通过基于规则、无监督学习、有监督学习、深度学习等方法对语料
库中的历史公证文书进行命名实体识别,得到的识别结果为若干个命名实体。
82.在一个可能的实现方式,通过调用步骤313训练得到的命名实体预测模型对历史公证文书中的命名实体进行识别,得到若干个命名实体。
83.值得一提的是,在其他实施例中,该若干个命名实体还可以利用公证实体词典对语料库中的历史公证文书进行分词得到。其中,公证实体词典是通过步骤313训练得到的命名实体预测模型,对语料库中的历史公证文书进行命名实体识别预先构建的。同理,公证法律词典也可以通过命名实体预测模型对公证相关的法律文件(例如《中华人民共和国民法通则》等)进行命名实体识别预先构建,进而利用该公证法律词典对公证相关的法律文件进行分词,得到待提取关联关系的若干个命名实体。
84.步骤333,采用基于规则的关系提取算法,提取得到各命名实体间的关系。
85.首先,通过nlp(natural language processing,自然语言处理)文本标注工具(例如doccano词性标注工具)对若干个命名实体进行词性标注。进一步地,若干个命名实体还将依照公证相关法律法规、司法解释等设置的标注规则进行词性标注。
86.然后,利用《全国公证综合管理信息系统技术规范》配置《关系提取规则》,如表1所示。
87.表1关系提取规则
[0088][0089]
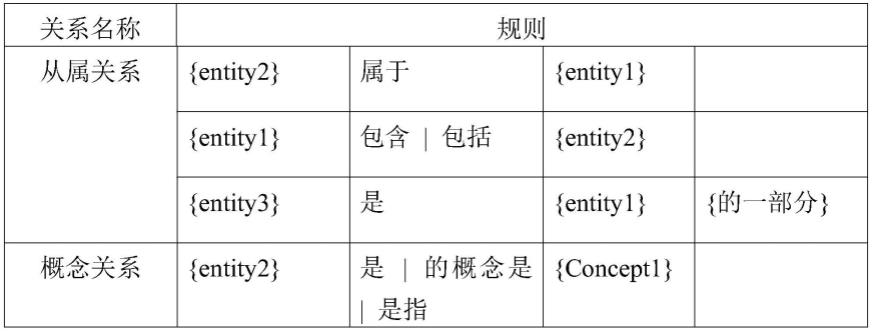
最后,基于《关系提取规则》,利用模式匹配方法对进行了词性标注的若干个命名实体之间的关系进行提取。其中,模式匹配是数据结构中字符串的一种基本运算,给定一个子串,要求在某个字符串中找出与该子串相同的至少一个子串。例如,如表1所示,假设给定一个子串“属于”,若历史公证文书中进行了词性标注的若干个命名实体所构成的字符串中,存在该子串“属于”,则认为该若干个命名实体间的关系为从属关系。
[0090]
步骤335,将各命名实体分别存储至各节点,并基于各命名实体间的关系在对应节点间构建路径。
[0091]
首先说明的是,公证领域知识图谱包含了节点和路径,其中节点用于存储命名实体、以及命名实体的属性信息,如格式属性等,路径用于连接存在关系的对应节点,并存储了对应节点(也就是对应两个命名实体)间的关系,如“属于”“是”等。
[0092]
当对应两个节点之间存在关系,那么就可以基于该关系构建路径,进而将该对应两个节点连接。例如命名实体“李明”和“房屋”之间的关系为房屋属于李明,为两者构建路径,得到“李明《—属于—房屋”。
[0093]
步骤337,由各节点及路径,构建得到公证领域知识图谱。
[0094]
在提取得到各节点间的关系后,便能够基于关系为各节点构建路径,进而通过路径连接各对应两个节点,得到公证领域知识图谱。在一个可能的实现方式,公证领域知识图谱通过neo4j图数据库表示,以将命名实体和关联关系存储于neo4j图数据库并展示,在此不作限定。
[0095]
由此,即完成公证领域图谱的构建。
[0096]
同理,案件信息图谱的构建过程与公证领域知识图谱的构建过程基本一致,差别在于训练集,案件信息图谱的训练集为案件信息,而公证领域知识图谱的训练集为历史公证文书和公证涉及的法律文书,此处不在重复叙述。
[0097]
在得到案件信息图谱和公证领域知识图谱后,便可进一步进行公证文书个案图谱的构建。公证文书个案图谱是指融合了个案的案件信息的公证文书图谱,即公证文书个案图谱中存储了针对个案的案件信息及与适用于个案的公证文书实体及其关系,换而言之,公证文书个案图谱适用于特定的个案。
[0098]
发明人意识到,知识图谱通常包含一定的抽象层知识和大量的实例层知识,基于此,可以将案件信息图谱通过知识融合的方式嵌入到公证领域图谱的实例层,从而形成公证文书个案图谱。
[0099]
如图6所示,在一种可能的实现方式,步骤230可以包括以下步骤:
[0100]
步骤231,获取案件信息图谱中的第二实体和公证领域图谱中的第三实体,并确定各第二实体与各第三实体的相似性。
[0101]
其中,相似性的确定过程包括:将第二实体与第三实体进行词向量化,并计算第二实体与第三实体之间的向量距离,从而根据第二实体与第三实体之间的向量距离确定第二实体与第三实体的相似性。应当理解,向量距离越小,第二实体与第三实体越相似。
[0102]
步骤233,基于所确定的相似性,确定相似的第二实体和第三实体的对应关系。
[0103]
在一种可能的实现方式,第二实体和第三实体的对应关系可以是指相同的对应关系,还可以是指存在上下层概念的对应关系。例如,第二实体为政策性住房,第三实体为不动产,则第二实体与第三实体之间存在上下层概念的对应关系。
[0104]
步骤235,基于所确定的对应关系,将案件信息图谱中的案件信息嵌入公证领域图谱的实例层,得到公证文书个案图谱。
[0105]
具体而言,如图7所示,在一种可能的实现方式,步骤235可以包括以下步骤:
[0106]
步骤2351,基于对应关系,对相似的第二实体和第三实体进行实体对齐和/或共指消解;
[0107]
其中,基于实体间的对应关系对不同知识图谱中相似实体进行处理,可以使处理过程更精准,从而提高公证文书生成的质量。
[0108]
具体地,判断第二实体和第三实体间的对应关系是否为相同。
[0109]
针对对应关系相同的第二实体和第三实体,通过实体对齐的方式对第二实体和第三实体进行融合。
[0110]
例如,若第二实体与第三实体均为“买受人”、“出卖人”、“继承人”、“被继承人”,则通过实体对齐的方式对第二实体和第三实体进行融合。即不同知识图谱中的实体均命名为“买受人”、“出卖人”、“继承人”、“被继承人”。
[0111]
针对对应关系存在上下层概念的第二实体和第三实体,通过共指消解的方式对第
二实体和第三实体进行融合。
[0112]
例如,第二实体为“买受人”、“出卖人”,第三实体为“甲方xxx”、“乙方yyy”,则通过共指消解的方式对第二实体与第三实体进行融合。即不同知识图谱中的实体可以均命名为“买受人”、“出卖人”。也就是说,共指消解是指去除存在上下层概念的对应关系的第二实体、第三实体中的任意一个实体。在一种可能的实现方式,共指消解是指去除存在上下层概念的对应关系的两个实体中的下层概念实体,而保留上层概念实体。
[0113]
步骤2353,实体对齐和/或共指消解后,将案件信息图谱的第二实体链指至公证领域图谱对应的第三实体,得到公证文书个案图谱。
[0114]
其中,链指,具体是指在案件信息图谱的第二实体与公证领域图谱对应的第三实体之间建立链接指向关系。
[0115]
如图8所示,第三实体为“买受人”、“出卖人”,第二实体为“甲方xxx”、“乙方yyy”,在第二实体“xxx”与第三实体“出卖人”之间建立链接指向关系(通过箭头701表示),在第二实体“yyy”与第三实体“买受人”之间建立链接指向关系(通过箭头702表示)。
[0116]
由此,即完成公证文书个案图谱的构建。
[0117]
步骤250,确定公证文书模板中的参数,并在公证文书个案图谱中查找与参数对应的案件信息。
[0118]
首先说明的是,公证文书模板基于用户选择确定。在一种可能的实现方式,用户可以是指需要通过操作生成公证文书的公证员。
[0119]
公证文书模板来自于预先存储的多个公证文书模板。该公证文书模板可以手动制作,还可以自动生成。
[0120]
一方面,手动制作公证文书模板,需要公证员收集各种典型公证文书作为模板样书,基于公证领域经验人工识别公证文书中的案件信息并标识,再将案件信息通过参数进行替换,并为参数配置对应的校验规则,从而形成公证文书模板。
[0121]
另一方面,自动生成公证文书模板,需要构建命名实体预测模型和制定“待填充案件信息”清单,以利用命名实体预测模型识别公证文书样书中的实体,并判断识别到的实体是否符合“待填充案件信息”清单对应的替换规则;若符合替换规则,则将公证文书样书中的实体替换成参数,并配置参数对应的校验规则,从而形成公证文书模板。
[0122]
基于上述过程,可以生成带有可替换参数的公证文书模板,由此,可以更好的进行公证文书的自动编写,保证文书格式的规范性和可靠性。
[0123]
应当理解,公证文书模板和公证文书的区别在于,公证文书模板中的参数对应于公证文书中的案件信息。那么,为了生成公证文书,实质是需要将公证文书模板中的参数替换为案件信息。基于此,在生成公证文书之前,需要得到能够替换公证文书模板中参数的案件信息。
[0124]
具体而言,如图9所示,在一种可能的实现方式,步骤250可以包括以下步骤:
[0125]
步骤251,通过正则匹配方式,在公证文书个案图谱中查找与参数匹配的候选实体。
[0126]
步骤253,对候选实体进行实体消歧得到目标实体。
[0127]
步骤255,在公证文书个案图谱的实例层,查询与目标实体匹配的案件信息,作为与参数对应的案件信息。
[0128]
在确定可替换至公证文书模板中的案件信息后,便可将公证文书模板转换为公证文书的正式文本。
[0129]
步骤270,将查找到的案件信息,填充至公证文书模板中参数所在的位置,生成公证文书。
[0130]
通过上述过程,实现了替代人工生成公证文书,能够避免人工撰写可能因个人原因导致的文书生成质量不一,使文书生成过程标准化,确保生成的公证文书质量稳定。
[0131]
如前所述,案件信息可以来自于证明材料,还可以来自于访谈笔录,下面对案件信息的获取过程进行详细地说明:
[0132]
如图10所示,在一示例性实施例中,获取案件信息包括以下步骤:
[0133]
步骤510,采集证明材料和/或访谈笔录。
[0134]
一方面,证明材料是当事人提交的包含案件信息的文档,其形式可以是纸质材料或电子文档。
[0135]
例如,采集证明材料时,若当事人提交的证明材料为纸质材料,则通过ocr技术对纸质材料进行扫描,生成电子文档,并存储。若证明材料为电子文档,则直接进行存储。
[0136]
另一方面,访谈笔录是当事人针对与公证事务相关的问题所做答复而形成的包含案件信息的文档,其形式可以由公证员基于与当事人接访问询,通过手打记录的方式生成,也可由后台自动生成。
[0137]
现结合图11至图12,对后台自动生成访谈笔录的过程进行详细地说明:
[0138]
如图11所示,在一种可能的实现方式,采集访谈笔录,可以包括以下步骤:
[0139]
步骤511,查询问题引导策略树,确定当前一个问题节点。
[0140]
其中,问题引导策略树用于决定自动生成访谈笔录时的问答过程。
[0141]
在一种可能的实现方式,根据不同的公证事务配置不同的问题引导策略树,以便于针对不同的公证事务进行问答引导。在一种可能的实现方式,问题引导策略树包括若干问题节点,每个问题节点中存储关于公证事务的一个问题。
[0142]
当然,在其他实施例中,也可以为不同的公证事务配置一个问题引导策略树,此处并非构成具体限定。
[0143]
步骤513,获取针对当前一个问题节点的答复,在问答知识图谱中查找与答复中命名实体匹配的第一实体。
[0144]
首先说明的是,问答知识图谱用于在生成访谈笔录时便能够从问答知识图谱中获取到第一实体,为获取答案提供了基础,有利于快速生成访谈笔录。
[0145]
如图12所示,在一种可能的实现方式,问答知识图谱的构建过程可以包括以下步骤:
[0146]
步骤610,收集历史访谈笔录,并结合开源问答语料库,形成问答语料库。
[0147]
其中,历史访谈笔录和开源问答语料库是包含历史问答信息的数据库。应当理解,随着历史访谈笔录和开源问答语料库中历史问答信息的愈发丰富,有利于提高问答知识图谱的质量,进而提高访谈笔录的生成质量。
[0148]
步骤630,对问答语料库中的访谈笔录进行命名实体识别,得到多个第一实体。
[0149]
在一种可能的实现方式,命名实体过程具体是指:通过bert(bidirectional encoder representation from transformers)模型对问答语料库中的问答语料进行预处
理,在对问答语料进行预处理后,便能够通过双向长短期记忆神经网络bi-lstm与条件随机场crf相结合等方法,对问答语料中的命名实体进行识别,得到多个第一实体。
[0150]
步骤650,采用基于规则的关系提取算法,提取得到多个第一实体间的关系。
[0151]
其中,多个第一实体间的关系包括但不限于:属于、包括、是等从属关系;以及是、匹配等概念关系。
[0152]
当然,在其他实施例中,关系提取的方式还可以通过预定义关系类型、深度学习等方式,此处并非构成具体限定。
[0153]
步骤670,基于多个第一实体及其关系,生成问答知识图谱。
[0154]
其中,问答知识图谱由多个节点、以及连接对应节点间的路径形成,各节点用于存储各第一实体,路径用于指示各第一实体间的关系。
[0155]
基于上述过程,实现问答知识图谱的构建,为获取第一实体提供了基础,进而有利于后续快速地自动生成访谈笔录。
[0156]
在构建得到问答知识图谱后,便可基于该问答知识图谱中的第一实体及其关系,查找到与答复中命名实体匹配的第一实体。
[0157]
具体而言,将问答知识图谱中的各第一实体映射到一个向量空间,得到各第一实体的词向量,以计算答复中命名实体与第一实体的相似度,根据计算得到的相似度,便能够查找到匹配的第一实体。应当理解,相似度越高,第一实体与答复中命名实体越匹配。
[0158]
步骤515,根据查找到的第一实体,从问答知识图谱中得到针对当前一个问题节点的答案。
[0159]
具体而言,对当事人的答复进行语义解析,基于语义解析结果对查找到的第一实体进行排序,选取与该答复最相关的第一实体,并基于问答知识图谱确定与该答复最相关的第一实体的实体属性,结合自然语言算法,从而得到针对当前一个问题节点的答案。
[0160]
步骤517,接收针对答案的反馈消息,基于反馈消息继续查询问题引导策略树,直至问题引导策略树查询完毕。
[0161]
也就是说,通过将当前一个问题节点的答案以语音和/或文字的形式展示给当事人,可以获得针对答案的反馈消息。
[0162]
接收当事人针对答案而产生的反馈消息,并解析该反馈消息,由此确定该反馈信息是否符合该事务需要采集的访谈信息标准;。
[0163]
若解析反馈消息的结果显示反馈信息符合该事务需要采集的访谈信息标准,则继续查询问题引导策略树,以跳转至访谈流程的后一个问题节点;即返回步骤511,重复上述问答过程。若解析反馈消息的结果显示反馈信息不符合该事务需要采集的访谈信息标准,则继续查询问题引导策略树,以跳转至访谈流程中该问题节点的下一个问题(即系统作出进一步提问;)
[0164]
当问题引导策略树中不存在后一个问题节点,停止问题引导策略树的查询,此时,可以认为是问题引导策略树查询完毕,即跳转至步骤519。
[0165]
步骤519,基于查询到的各问题节点中的问题及对应的答复和答案,生成访谈笔录。
[0166]
由此可知,结合问题引导策略树和问答知识图谱,每一轮问题引导策略树的问题节点中的问题、问答知识图谱给予的答案、和/或、当事人给予的答复,便能够按照时序顺
序,以文本形式存储为访谈笔录。举例来说,假设当前一个问题节点中的问题是:您要办理什么类型公证事务?针对当前一个问题节点,当事人的答复是:我刚买了房子,尚未过户,要办理什么公证?基于问答知识图谱,便可得到针对该问题节点的答案,并将该答案向当事人展示,若当事人认为该答案并非其想要的答案,则返回针对该答案的反馈消息。
[0167]
在接收到反馈消息后,便继续查询问题引导策略树,跳转至后一个问题节点,假设该后一个问题节点中的问题是:您的房子是期房还是现房?针对该问题节点,当事人的答复是:现房;基于问答知识图谱,便可得到针对该问题节点的答案是“您可以选择办理商品房买卖合同公证”,同时将该答案展示给当事人。
[0168]
假设当事人认为该答案是其想要的答案,则停止问题引导策略树的查询。
[0169]
最终,由上述过程中产生的问题和答案,生成针对该当事人的访谈笔录。
[0170]
步骤530,从证明材料和/或访谈笔录中,提取得到案件信息。
[0171]
在上述实施例的配合下,实现了从证明材料或访谈笔录中自动采集案件信息,实现了案件信息采集过程的标准化,避免人工采集案件信息效率低下,质量不稳定的问题,进而提高生成公证文书的质量与规范性。
[0172]
图13是一应用场景中一种公证文书生成方法的具体实现示意图。
[0173]
该应用场景中,通过步骤801,存储多个公证文书模板,各公证文书模板对应于不同公证事务,各公证文书模板中存储可供替换的参数。
[0174]
通过步骤802,构建公证领域知识图谱(即公证领域图谱),以及构建案件信息知识图谱(案件信息图谱);其中,公证领域知识图谱适用于不同公证事务所对应的各种公证文书模板,案件信息知识图谱是针对具体公证事务的个案。
[0175]
通过步骤803,将公证领域知识图谱与案件信息知识图谱进行知识融合,得到个案公证文书知识图谱。该个案公证文书知识图谱适用于具体公证事务的个案。在获得个案公证文书知识图谱后,便能够使用个案公证文书知识图谱查找针对个案的案件信息。
[0176]
通过步骤804,基于用户选择,得到公证文书模板。应当理解,不同公证文书模板中参数也各不相同;也可以认为是,公证文书模板适用于具体公证事务的个案。
[0177]
通过步骤805,从个案公证文书知识图谱中获取公证文书模板中参数对应的案件信息。
[0178]
通过步骤806,将案件信息填充至公证文书模板中参数所在位置,由此,将公证文书模板转换为公证文书的正式文本。
[0179]
通过步骤807,将公证文书的正式文本推送给用户。例如,通过电子设备所配置的显示屏幕,向用户展示公证文书的正式文本。
[0180]
在本应用场景中,通过构建公证文书模板,并将公证领域图谱与案件信息图谱融合生成公证文书个案图谱,以便于使用公证文书个案图谱将案件信息替换至公证文书模板,得到公证文书的正式文本,避免使用人工编写公证文书正式文本,提高公证文书的编写效率,提高文书质量。
[0181]
此外,基于公证领域图谱,确保能生成符合相关法规的公证文书,提高公证文书生成的规范性和可靠性。
[0182]
下述为本技术装置实施例,可以用于执行本技术所涉及的公证文书生成方法。对于本技术装置实施例中未披露的细节,请参照本技术所涉及的公证文书生成的方法实施
例。
[0183]
请参阅图14,本技术实施例中提供了一种公证文书生成装置900,包括但不限于:信息图谱构建模块910、知识融合模块930、案件信息查找模块950、文书生成模块970。
[0184]
其中,信息图谱构建模块910,用于获取案件信息,并基于案件信息构建案件信息图谱。
[0185]
知识融合模块930,用于将案件信息图谱与公证领域图谱进行知识融合,生成公证文书个案图谱。
[0186]
案件信息查找模块950,用于确定公证文书模板中的参数,并在公证文书个案图谱中查找与参数对应的案件信息。
[0187]
文书生成模块970,用于将查找到的案件信息,填充至公证文书模板中参数所在的位置,生成公证文书。
[0188]
需要说明的是,上述实施例所提供的公证文书生成装置在进行公证文书生成时,仅以上述各功能模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即公证文书生成装置的内部结构将划分为不同的功能模块,以完成以上描述的全部或者部分功能。
[0189]
另外,上述实施例所提供的公证文书生成装置与公证文书生成的实施例属于同一构思,其中各个模块执行操作的具体方式已经在方法实施例中进行了详细描述,此处不再赘述。
[0190]
图15根据一示例性实施例示出的一种服务器的结构示意。该服务器适用于上述实施例所涉及的公证文书生成方法。
[0191]
需要说明的是,该服务器只是一个适配于本技术的示例,不能认为是提供了对本技术的使用范围的任何限制。该服务器也不能解释为需要依赖于或者必须具有图15示出的示例性的服务器2000中的一个或者多个组件。
[0192]
服务器2000的硬件结构可因配置或者性能的不同而产生较大的差异,如图15所示,服务器2000包括:电源210、接口230、至少一存储器250、以及至少一中央处理器(cpu,central processing units)270。
[0193]
具体地,电源210用于为服务器2000上的各硬件设备提供工作电压。
[0194]
接口230包括至少一有线或无线网络接口231,用于与外部设备交互。当然,在其余本技术适配的示例中,接口230还可以进一步包括至少一串并转换接口233、至少一输入输出接口235以及至少一usb接口237等,如图15所示,在此并非对此构成具体限定。
[0195]
存储器250作为资源存储的载体,可以是只读存储器、随机存储器、磁盘或者光盘等,其上所存储的资源包括操作系统251、应用程序253及数据255等,存储方式可以是短暂存储或者永久存储。
[0196]
其中,操作系统251用于管理与控制服务器2000上的各硬件设备以及应用程序253,以实现中央处理器270对存储器250中海量数据255的运算与处理,其可以是windows servertm、mac os xtm、unixtm、linuxtm、freebsdtm等。
[0197]
应用程序253是基于操作系统251之上完成至少一项特定工作的计算机程序,其可以包括至少一模块(图15未示出),每个模块都可以分别包含有对服务器2000的计算机程序。例如,公证文书生成装置可视为部署于服务器2000的应用程序253。
[0198]
数据255可以是存储于磁盘中的照片、图片等,还可以是案件信息等等,存储于存储器250中。
[0199]
中央处理器270可以包括一个或多个以上的处理器,并设置为通过至少一通信总线与存储器250通信,以读取存储器250中存储的计算机程序,进而实现对存储器250中海量数据255的运算与处理。例如,通过中央处理器270读取存储器250中存储的一系列计算机程序的形式来完成公证文书生成方法。
[0200]
此外,通过硬件电路或者硬件电路结合软件也能同样实现本技术,因此,实现本技术并不限于任何特定硬件电路、软件以及两者的组合。
[0201]
请参阅图16,本技术实施例中提供了一种电子设备4000,该电子设备400可以包括:台式电脑、笔记本电脑、平板电脑、服务器等等。
[0202]
在图15中,该电子设备4000包括多个处理器4001、至少一条通信总线4002以及多个存储器4003。
[0203]
其中,处理器4001和存储器4003相连,如通过通信总线4002相连。可选地,电子设备4000还可以包括收发器4004,收发器4004可以用于该电子设备与其他电子设备之间的数据交互,如数据的发送和/或数据的接收等。需要说明的是,实际应用中收发器4004不限于一个,该电子设备4000的结构并不构成对本技术实施例的限定。
[0204]
处理器4001可以是cpu(central processing unit,中央处理器),通用处理器,dsp(digital signal processor,数据信号处理器),asic(application specific integrated circuit,专用集成电路),fpga(field programmable gate array,现场可编程门阵列)或者其他可编程逻辑器件、晶体管逻辑器件、硬件部件或者其任意组合。其可以实现或执行结合本技术公开内容所描述的各种示例性的逻辑方框,模块和电路。处理器4001也可以是实现计算功能的组合,例如包含一个或多个微处理器组合,dsp和微处理器的组合等。
[0205]
通信总线4002可包括一通路,在上述组件之间传送信息。通信总线4002可以是pci(peripheral component interconnect,外设部件互连标准)总线或eisa(extended industry standard architecture,扩展工业标准结构)总线等。通信总线4002可以分为地址总线、数据总线、控制总线等。为便于表示,图16中仅用一条粗线表示,但并不表示仅有一根总线或一种类型的总线。
[0206]
存储器4003可以是rom(read only memory,只读存储器)或可存储静态信息和指令的其他类型的静态存储设备,ram(random access memory,随机存取存储器)或者可存储信息和指令的其他类型的动态存储设备,也可以是eeprom(electrically erasable programmable read only memory,电可擦可编程只读存储器)、cd-rom(compact disc read only memory,只读光盘)或其他光盘存储、光碟存储(包括压缩光碟、激光碟、光碟、数字通用光碟、蓝光光碟等)、磁盘存储介质或者其他磁存储设备、或者能够用于携带或存储具有指令或数据结构形式的期望的程序代码并能够由计算机存取的任何其他介质,但不限于此。
[0207]
存储器4003上存储有计算机程序,处理器4001通过通信总线4002读取存储器4003中存储的计算机程序。
[0208]
该计算机程序被处理器4001执行时实现上述各实施例中的公证文书生成方法。
[0209]
此外,本技术实施例中提供了一种存储介质,该存储介质上存储有计算机程序,该计算机程序被处理器执行时实现上述各实施例中的公证文书生成方法。
[0210]
本技术实施例中提供了一种计算机程序产品,该计算机程序产品包括计算机程序,该计算机程序存储在存储介质中。计算机设备的处理器从存储介质读取该计算机程序,处理器执行该计算机程序,使得该计算机设备执行上述各实施例中的公证文书生成方法。
[0211]
与相关技术相比,本发明利用公证文书具有范式特点,将案件信息图谱与公证领域图谱进行融合,通过查询融合后的知识图谱,读取参数对应的案件信息,将案件信息替换到公证文书模板的参数对应的位置,从而快速地自动生成公证文书的正式文本,由上可知,本发明避免依赖于人工编写公证文书,提高了公证文书的编写效率,稳定了公证文书的出证质量。
[0212]
应该理解的是,虽然附图的流程图中的各个步骤按照箭头的指示依次显示,但是这些步骤并不是必然按照箭头指示的顺序依次执行。除非本文中有明确的说明,这些步骤的执行并没有严格的顺序限制,其可以以其他的顺序执行。而且,附图的流程图中的至少一部分步骤可以包括多个子步骤或者多个阶段,这些子步骤或者阶段并不必然是在同一时刻执行完成,而是可以在不同的时刻执行,其执行顺序也不必然是依次进行,而是可以与其他步骤或者其他步骤的子步骤或者阶段的至少一部分轮流或者交替地执行。
[0213]
以上所述仅是本技术的部分实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本技术原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本技术的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。