一种基于anchor-free的轻量化实时视频姿态估计方法
技术领域
1.本发明涉及模式识别与计算机视觉技术领域,特别是一种基于anchor-free的轻量化实时视频姿态估计方法。
背景技术:
2.随着人工智能技术的发展,计算机视觉在现实生活中有了更多更广的应用,人脸识别、自动化驾驶等层出不穷。神经网络的成熟发展,进一步扩大了人们的想象力,在多种应用场景下,使得计算机视觉相关应用更加实用便捷。视频姿态估计技术在体育竞赛、锻炼健身、学习专注度等场景下都有巨大应用。应用落地要考虑实时性与准确性兼备,目前很多视频姿态估计技术准确率高,但是模型大,耗时高,无法满足实时的需求。为了提升更多用户使用ai应用的舒适度,我们更需要实时性更强的轻量化视频姿态估计技术。
技术实现要素:
3.有鉴于此,本发明的目的在于提供一种基于anchor-free的轻量化实时视频姿态估计方法,能够有效地对视频中的人体姿态进行识别。
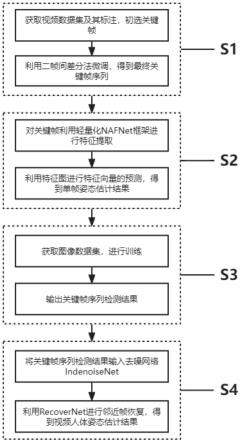
4.为实现上述目的,本发明采用如下技术方案:一种基于anchor-free的轻量化实时视频姿态估计方法,包括以下步骤:
5.步骤s1:获取视频数据集,通过抽选关键帧算法,进行关键帧的选择;
6.步骤s2:利用基于anchor-free框架的轻量化方法nafnet,进行关键帧的姿态估计;
7.步骤s3:获取人体姿态估计数据集,进行轻量化模型训练;
8.步骤s4:利用去噪-恢复-全局特征性算法,对其余帧进行补全,完成整个视频的姿态估计。
9.在一较佳的实施例中,所述步骤s1具体包括以下步骤:
10.步骤s11:从网上获取视频人体姿态估计数据集,并获取其标注;
11.步骤s12:对于数据集中的一个视频,给定代表视频v中共包含t帧,i
t
代表t时刻的视频图像;从视频序列中等距初选出约五分之一的n帧关键帧,关键帧序列为f={f1,f2,
…
,fn};
12.步骤s13:利用二帧间差分法对提取关键帧进行微调,记now为当前时刻,及当前帧f
now
(x,y)以及关键帧序列中下一帧f
now 1
(x,y),其中x和y分别代表着横轴和纵轴上的点,两帧像素差为d
now
(x,y);公式为:
13.d
now
(x,y)=|f
now
(x,y)-f
now 1
(x,y)|
14.令阈值为t,若d
now
(x,y)小于阈值,则将f
n 1
帧替换成f
n 1
帧所对应i
t
的下一帧i
t 1
,最终得到最终关键帧序列s。
15.在一较佳的实施例中,所述步骤s2的具体方法为:
16.步骤s21:基于anchor-free人体姿态估计框架nafnet采用轻量化backbone进行特
征提取,主干网络部分基于micronet网络,并将网络中未被分解的卷积部分替换成轻量ghost卷积块,轻量ghost模块中,第二层开始所有的卷积层的通道数都是输出通道数的1/2,剩下1/2通道的输出特征由之前所有卷积层分别经过廉价操作产生,同时在网络中融合上轻量化全局注意力模块;该注意力模块用1
×
1的深度可分离卷积dw1×1对每组特征fmapk提取通道为新的特征,k代表组数索引值,进行最大池化maxpool后,再通过点卷积pointconv形成通道数为1的注意力特征图,并利用softmax激活函数对注意力特征图进行缩放;公式为:
17.amapk=softmax(pointconv(maxpool(dw1×1(fmapk))))
18.得到注意力矩阵amapk后,再将每组特征fmapk与注意力矩阵逐元素对应相乘,再与原始每组特征相加,得到处理后的该组特征fk,公式为:
19.fk=(amapk·
fmapk) fmapk20.再经过concat操作将k组特征连接后,提取后得到最终的特征图;
21.步骤s22:neck部分采用简化版的pan结构,将原先的pan网络结构中的卷积替换成与步骤s21中相同的轻量ghost模块;
22.步骤s23:检测部分利用中间的一个anchor点以及向量化预测方式对人体关键点进行预测,损失部分采用的是更加能平衡正负样本的高效版的focalloss,公式为:
23.efl(σ)=-|μ-σ|
β
((μ-1)log(1-μ)(1-σ) μ(1-σ)logσ)
24.其中μ为0~1的质量标签,σ为预测值,β是调节因子;先训练出一组初始化特征点,得出一组初始向量v
first
,再使用动态可变形卷积dycconv得到关键点处的另一组向量v
dycconv
,将获取到的两个特征相加,形成最终的关键点特征v
last
,利用这些预测向量,从而得到最后的姿态估计结果。
25.在一较佳的实施例中,所述步骤s3具体包括以下步骤:
26.步骤s31:从网上获取姿态估计数据集coco,并获取其人体关键点标注;
27.步骤s32:采用步骤s2所述我们提出的新型anchor-free人体姿态估计框架nafnet进行训练,得到用于快速检测单帧图像的人体姿态训练模型;
28.步骤s33:在得到训练模型后,将提取出来的关键帧序列s进行检测,得到检测后的结果p
pre
,p
pre
=nafnet(s);
29.在一较佳的实施例中,所述步骤s4中,具体包括以下步骤:
30.步骤s41:将检测后的结果p
pre
输入去噪网络indenoisenet,得到经过去噪处理之后的姿态p
clean
;p
clean
=indenoisenet(p
pre
);去噪网络indenoisenet先将噪声图像转换成低分辨率的图像和高频编码,训练公式为:
[0031][0032]
其中γ代表着有噪声的图像,low代表低频,g(γ)
low
是指网络学习到的低频部分,x
low
是图像真实的低频部分,w
rorw
是整个图像的像素点数量,index表示像素点的索引值,该操作g具有可逆性;
[0033]
步骤s42:在获得去噪后的图像之后,需要根据稀疏帧对整个图像序列进行恢复,利用recovernet进行恢复;训练公式为:
[0034][0035]
其中w
back
代表经过处理后整个图像的像素点数量,p
clean
代表着去噪后的姿态结果,g~n(0,1)是从正态分布中随机抽样的变量,补充高频部分的细节信息;g-1
代表步骤s41中的可逆操作,g和g-1
应同时进行训练;同时时间1d信息也存在于recovernet中,以恢复近邻帧的姿态,公式为:
[0036]
p=recovernet(conv1d(p
clean
),l
recover
(g(γ),x
low
))
[0037]
利用该操作对其余帧序列进行恢复,最终输出视频人体姿态估计结果p。
[0038]
与现有技术相比,本发明具有以下有益效果:
[0039]
1、能够高效地对视频中的人体姿态进行识别,提升了视频人体姿态估计的准确率。
[0040]
2、能够利用多尺度信息进行特征的处理,在少量增加参数量的同时,对远近目标都能有较大的提升。
[0041]
3、相比于传统的top-down姿态估计思路,本发明基于anchor-free思想,提出了轻量化的框架nafnet,更高效的完成姿态估计任务。
[0042]
4、针对视频逐帧检测过慢,耗时过高的问题,提出了去噪-恢复-全局特征性算法,提升了视频人体姿态估计的效率和准确率。
附图说明
[0043]
图1为本发明优选实施例的方法流程图。
具体实施方式
[0044]
下面结合附图及实施例对本发明做进一步说明。
[0045]
应该指出,以下详细说明都是例示性的,旨在对本技术提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本技术所属技术领域的普通技术人员通常理解的相同含义。
[0046]
需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本技术的示例性实施方式;如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。
[0047]
如图1所示,本发明提供了一种基于anchor-free的轻量化实时视频姿态估计识别方法,包括以下步骤:
[0048]
步骤s1:获取视频数据集,通过抽选关键帧算法,进行关键帧的选择;
[0049]
步骤s2:利用基于anchor-free框架的轻量化方法nafnet,进行关键帧的姿态估计;
[0050]
步骤s3:获取人体姿态估计数据集,进行轻量化模型训练;
[0051]
步骤s4:利用去噪-恢复-全局特征性算法,对其余帧进行补全,完成整个视频的姿态估计。
[0052]
进一步地,所述步骤s1具体包括以下步骤:
[0053]
步骤s11:从网上获取视频人体姿态估计数据集,并获取其标注;
[0054]
步骤s12:对于数据集中的一个视频,给定代表视频v中共包含t帧,i
t
代表t时刻的视频图像。从视频序列中等距初选出约五分之一的n帧关键帧,关键帧序列为f={f1,f2,
…
,fn};
[0055]
步骤s13:利用二帧间差分法对提取关键帧进行微调,记now为当前时刻,及当前帧f
now
(x,y)以及关键帧序列中下一帧f
now 1
(x,y),其中x和y分别代表着横轴和纵轴上的点,两帧像素差为d
now
(x,y)。公式为:
[0056]dnow
(x,y)=|f
now
(x,y)-f
now 1
(x,y)|
[0057]
令阈值为t,若d
now
(x,y)小于阈值,则将f
n 1
帧替换成f
n 1
帧所对应i
t
的下一帧i
t 1
,最终得到最终关键帧序列s;
[0058]
进一步地,所述步骤s2具体方法为:
[0059]
步骤s21:我们提出的基于anchor-free人体姿态估计框架nafnet采用了轻量化backbone进行特征提取,主干网络部分基于micronet网络,并将网络中未被分解的卷积部分替换成轻量ghost卷积块,轻量ghost模块中,第二层开始所有的卷积层的通道数都是输出通道数的1/2,剩下1/2通道的输出特征由之前所有卷积层分别经过廉价操作产生,同时在网络中融合上轻量化全局注意力模块。该注意力模块用1
×
1的深度可分离卷积dw1×1对每组特征fmapk提取通道为新的特征,k代表组数索引值,进行最大池化maxpool后,再通过点卷积pointconv形成通道数为1的注意力特征图,并利用softmax激活函数对注意力特征图进行缩放。公式为:
[0060]
amapk=softmax(pointconv(maxpool(dw1×1(fmapk))))
[0061]
得到注意力矩阵amapk后,再将每组特征fmapk与注意力矩阵逐元素对应相乘,再与原始每组特征相加,得到处理后的该组特征fk,公式为:
[0062]fk
=(amapk·
fmapk) fmapk[0063]
再经过concat操作将k组特征连接后,提取后得到最终的特征图。
[0064]
步骤s22:neck部分采用简化版的pan结构,将原先的pan网络结构中的卷积替换成与步骤s21中相同的轻量ghost模块,与传统方法相比,在几乎不降低融合效率的同时减少计算量;
[0065]
步骤s23:检测部分我们是利用中间的一个anchor点以及向量化预测方式对人体关键点进行预测,损失部分采用的是更加能平衡正负样本的高效版的focalloss,公式为:
[0066]
efl(σ)=-|μ-σ|
β
((μ-1)log(1-μ)(1-σ) μ(1-σ)logσ)
[0067]
其中μ为0~1的质量标签,σ为预测值,β是调节因子,一般取2。我们先训练出一组初始化特征点,得出一组初始向量v
first
,再使用动态可变形卷积dycconv得到关键点处的另一组向量v
dycconv
,将获取到的两个特征相加,形成最终的关键点特征v
last
,利用这些预测向量,从而得到最后的姿态估计结果。
[0068]
进一步地,所述步骤s3包括以下步骤:
[0069]
步骤s31:从网上获取姿态估计数据集coco,并获取其人体关键点标注。
[0070]
步骤s32:采用步骤s2所述我们提出的新型anchor-free人体姿态估计框架nafnet进行训练,得到用于快速检测单帧图像的人体姿态训练模型。
[0071]
步骤s33:在得到训练模型后,将提取出来的关键帧序列s进行检测,得到检测后的
结果p
pre
,p
pre
=nafnet(s)。
[0072]
进一步地,所述步骤s4中,具体包括以下步骤:
[0073]
步骤s41:为了降低单帧检测的噪声,将检测后的结果p
pre
输入去噪网络indenoisenet,得到经过去噪处理之后的姿态p
clean
。p
clean
=indenoisenet(p
pre
)。该网络不同于传统神经网络,我们设计的indenoisenet要先将噪声图像转换成低分辨率的图像和高频编码,训练公式为:
[0074][0075]
其中γ代表着有噪声的图像,low代表低频,g(γ)
low
是指网络学习到的低频部分,x
low
是图像真实的低频部分,w
forw
是整个图像的像素点数量,index表示像素点的索引值,该操作g具有可逆性;
[0076]
步骤s42:在获得去噪后的图像之后,需要根据稀疏帧对整个图像序列进行恢复,我们设计了一个recovernet进行恢复。训练公式为:
[0077][0078]
其中w
back
代表经过处理后整个图像的像素点数量,p
clean
代表着去噪后的姿态结果,g~n(0,1)是从正态分布中随机抽样的变量,补充高频部分的细节信息。g-1
代表步骤s41中的可逆操作,g和g-1
应同时进行训练。同时时间1d信息也存在于recovernet中,以恢复近邻帧的姿态,公式为:
[0079]
p=recovernet(conv1d(p
clean
),l
recover
(g(γ),x
low
))
[0080]
利用该操作对其余帧序列进行恢复,最终输出视频人体姿态估计结果p。
[0081]
以上是本发明的较佳实施例,凡依本发明技术方案所作的改变,所产生的功能作用未超出本发明技术方案的范围时,均属于本发明的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
