一种基于改进yolov5的小目标识别方法
技术领域
1.本发明涉及目标检测技术领域,具体为一种基于改进yolov5的小目标识别方法。
背景技术:
2.目前,基于深度神经网络的目标检测方法主要有一阶段和二阶段两类。2阶段的目标检测算法主要先通过区域提取网络区分前景和背景,然后对前景感兴趣区域进行分类和回归,得到最终的检测结果,其代表模型为faster r-cnn,detectorrs等。一阶段的目标检测算法是直接从网络所提取的特征图中进行分类和回归,然后通过非极大值抑制方法得到最终的检测结果,代表的模型为yolo系列。二阶段的模型检测准确度较高,但模型复杂,计算量较大,不适合在巡检机器人的边缘段进行部署,因此本专利采用yolov5模型作为服务器指示灯的检测基准模型。
3.然而小目标在图像中所占像素较小。在分辨率为1920x1080的标清图像上,一个指示灯所占像素在8x7左右的大小,在图像经过主干网络提取特征,经过多次下采样的情况下,目标的特征信息逐渐丢失,难以被网络检测,易漏检。因此需要对yolov5的模型进行改进优化,提高其对小目标的检测精度。
技术实现要素:
4.(一)解决的技术问题
5.针对现有技术的不足,本发明提供了一种基于改进yolov5的小目标识别方法,能够在保证计算速度的前提下,通过增加检测头,增强模型的多尺度学习能力,同时通过子注意力机制,增加小目标周围的上下文信息,最后通过优化目标的损失函数,提高模型检测目标框的回归能力,从而全面提高模型对小目标的检测精度,解决了背景技术中提出的问题。
6.(二)技术方案
7.为实现上述通过增加检测头,增强模型的多尺度学习能力,同时通过子注意力机制,增加小目标周围的上下文信息,最后通过优化目标的损失函数,提高模型检测目标框的回归能力,从而全面提高模型对小目标的检测精度目的,本发明提供如下技术方案:
8.一种基于改进yolov5的小目标识别方法,包括步骤:
9.s1、构建改进的yolov5模型,所述s1包括:
10.s11、构建通道-空间并行的注意力机制模块;
11.s12、将注意力模块添加至对应网络层中;
12.s13、将主干网络cspdarknet的21层输出的160x160尺寸的特征图与网络的第2层特征图进行concat操作,作为第4个检测头的输入模块;
13.s2、替换yolov5原有的ciou损失函数,训练模型;
14.s3、完成训练后,对模型进行部署。
15.优选的,所述s11包括第一步骤:
16.s111、注意力机制模块对特征图中的二维空间特征进行特征增强,所述s111包括
如下步骤:
17.s1111、采用2个1
×
1卷积生成空间注意力机制模块中的查询权重wsq和键值权重wsk;
18.s1112、对查询权重进行全局最大池化操作;
19.s1113、分别对查询权重和键值权重进行reshape操作,重整权重尺寸的矩阵形式;
20.s1114、采用softmax函数对查询矩阵进行激活操作,将其映射在(0,1)之内;
21.s1115、查询矩阵与键值矩阵进行矩阵相乘、reshape操作和sigmoid函数激活,得到特征图在空间上的权重特征张量;
22.s1116、将空间权重特征张量与输入特征图进行点乘,得到特征图在二维空间增强特征的输出。
23.优选的,所述s11还包括第二步骤:
24.s112、注意力模块对拼接特征图中的一维通道特征进行特征增强,所述s112包括以下步骤:
25.s1121、采用2个1
×
1卷积生成通道注意力机制中的查询权重wcq和键值权重wck;
26.s1122、对查询权重和键值权重进行reshape操作,生成对应的矩阵;
27.s1123、将查询矩阵通过softmax映射到(0,1)之间;
28.s1124、将2矩阵进行矩阵相乘,得到通道的权重矩阵;
29.s1125、通道的权重矩阵经过1
×
1卷积、层归一化操作和sigmoid的特征映射,得到通道特征权重张量;
30.s1126、通道特征权重张量与输入的特征图进行点乘操作,实现特征图中的一维通道特征的特征增强。
31.优选的,所述主干网络的设置有若干注意力机制模块,若干所述注意力机制模块分别位于主干网络的第21、24、27、30层,且所述通道与空间位置进行并行注意力机制模块。
32.优选的,所述改进的yolov5采用iou loss作为计算目标框回归的损失函数。
33.(三)有益效果
34.与现有技术相比,本发明提供了一种基于改进yolov5的小目标识别方法,具备以下有益效果:
35.该基于改进yolov5的小目标识别方法,通过对检测头进行了改进,增加了一个更高分辨率的检测头,从主干网络cspdarknet的21层输出的160x160尺寸的特征图与网络的第2层特征图进行concat操作,以此获得更高分辨率的特征图,作为检测头的输入,则该检测头的输出为10x10的目标,和指示灯的像素尺寸基本相同,从而大大提高目标的检测精度,通过主干网络特征提取部分加入子注意力机制模块,增强小指示灯周围的上下文信息,同时抑制没有指示灯的背景区域权重,达到增强特征图目标权重的目的,对通道和空间位置进行并行注意力机制提取,从而从整体提高网络的表征能力,能够在保证计算速度的前提下,通过增加检测头,增强模型的多尺度学习能力,同时通过子注意力机制,增加小目标周围的上下文信息,最后通过优化目标的损失函数,提高模型检测目标框的回归能力,从而全面提高模型对小目标的检测精度,保证了实用性。
附图说明
36.图1为本发明提出的一种基于改进yolov5的小目标识别方法中改进的yolov5整体架构示意图;
37.图2为本发明提出的一种基于改进yolov5的小目标识别方法中通道和空间位置进行并行注意力机制模块示意图;
38.图3为本发明提出的一种基于改进yolov5的小目标识别方法中损失函数示意图;
39.图4为现有yolov5基本架构示意图。
具体实施方式
40.下面将结合本发明的实施例,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
41.请参阅图1-3,一种基于改进yolov5的小目标识别方法,包括步骤:
42.s1、构建改进的yolov5模型,所述s1包括:
43.s11、构建通道-空间并行的注意力机制模块;
44.s12、将注意力模块添加至对应网络层中;
45.s13、将主干网络cspdarknet的21层输出的160x160尺寸的特征图与网络的第2层特征图进行concat操作,作为第4个检测头的输入模块;
46.s2、替换yolov5原有的ciou损失函数,训练模型;
47.s3、完成训练后,对模型进行部署。
48.进一步地,所述s11包括第一步骤:
49.s111、注意力机制模块对特征图中的二维空间特征进行特征增强,所述s111包括如下步骤:
50.s1111、采用2个1
×
1卷积生成空间注意力机制模块中的查询权重wsq和键值权重wsk;
51.s1112、对查询权重进行全局最大池化操作;
52.s1113、分别对查询权重和键值权重进行reshape操作,重整权重尺寸的矩阵形式;
53.s1114、采用softmax函数对查询矩阵进行激活操作,将其映射在(0,1)之内;
54.s1115、查询矩阵与键值矩阵进行矩阵相乘、reshape操作和sigmoid函数激活,得到特征图在空间上的权重特征张量;
55.s1116、将空间权重特征张量与输入特征图进行点乘,得到特征图在二维空间增强特征的输出。
56.进一步地,所述s11还包括第二步骤:
57.s112、注意力模块对拼接特征图中的一维通道特征进行特征增强,所述s112包括以下步骤:
58.s1121、采用2个1
×
1卷积生成通道注意力机制中的查询权重wcq和键值权重wck;
59.s1122、对查询权重和键值权重进行reshape操作,生成对应的矩阵;
60.s1123、将查询矩阵通过softmax映射到(0,1)之间;
61.s1124、将2矩阵进行矩阵相乘,得到通道的权重矩阵;
62.s1125、通道的权重矩阵经过1
×
1卷积、层归一化操作和sigmoid的特征映射,得到通道特征权重张量;
63.s1126、通道特征权重张量与输入的特征图进行点乘操作,实现特征图中的一维通道特征的特征增强。
64.进一步地,所述主干网络的设置有若干注意力机制模块,若干所述注意力机制模块分别位于主干网络的第21、24、27、30层,即模型提取特征图作为检测头输入的那一层,用于增强主干网络输出特征图的上下文交互信息,从而提高模型对所有目标的检测能力,且所述通道与空间位置进行并行注意力机制模块,能够从整体提高网络的表征能力。
65.进一步地,所述改进的yolov5采用iou loss作为计算目标框回归的损失函数,传统yolov5采用ciou损失函数,传统的目标检测损失函数依赖于边界框回归指标的聚合,例如预测框和真实框(即giou、ciou、iciou等)的距离、重叠区域和纵横比。虽然ciou loss虽然考虑了边界框回归的重叠面积、中心点距离、纵横比。但是通过其公式中的v反映的纵横比的差异,而不是宽高分别与其置信度的真实差异,所以有时会阻碍模型有效的优化相似性,对此本发明采用iou loss作为计算目标框回归的损失函数。
66.具体的实现方案如下:
67.(1)标准的yolov5模型如图4所示。包括提取图像特征的主干网络(backbone),进行多尺度特征融合的金字塔层(neck)和3个采用不同尺度进行预测的检测头(prediction-head);
68.(2)当输入图像的尺寸为640x640时,yolov5模型会得到3个不同尺度的输出:80x80(640/8),40x40(640/16),20x20(640/32),而巡检机器人所要检测的指示灯一般尺寸的长宽在10个像素左右,很难通过标准的yolov5检测模型检测,因此本发明首先对检测头进行了改进,增加了一个更高分辨率的检测头,从主干网络cspdarknet的21层输出的160x160尺寸的特征图与网络的第2层特征图进行concat操作,以此获得更高分辨率的特征图,作为检测头的输入,则该检测头的输出为10x10的目标,和指示灯的像素尺寸基本相同,从而大大提高目标的检测精度;
69.(3)为了进一步提高有遮挡的小指示灯的识别率,本发明在主干网络特征提取部分加入子注意力机制模块,增强小指示灯周围的上下文信息,同时抑制没有指示灯的背景区域权重,达到增强特征图目标权重的目的,具体的子注意力机制模块如图2所示,本发明提出的对通道和空间位置进行并行注意力机制提取,从而从整体提高网络的表征能力。如图2所示,特征图的输入为x,其尺寸高为h,宽为w,通道数为c.分别经过卷积核为1
×
1的卷积操作,生成通道注意力机制的查询(querry)权重wcq,和键值(key)权重wck,以及位置的查询(querry)权重wsq,和键值(key)权重wsk。通道注意力机制的查询(querry)权重wcq经过重整尺寸(reshape)操作,变为一个c/2
×
hw的矩阵。键值(key)权重wck重整尺寸,得到一个wh
×
1的矩阵,然后通过softmax激活函数,将键值权重映射在(0,1)之间,然后2个矩阵进行矩阵乘的操作,得到一个重矩阵,其尺寸为c/2
×
1。该矩阵经过卷积核为1
×
1的卷积操作,然后通过层归一化操作和sigmoid激活函数,得到各个通道的权重特征,其尺寸为c
×1×
1,其值在0~1之间。通道权重特征和输入的原始特征图进行点乘操作(点乘就是2个特征图各个对应位置的值相乘,点乘为深度神经网络的常规操作),就得到特征图各个像素尺寸
在通道方向上的特征信息。位置的查询(querry)权重wsq经过全局池化操作,得到位置信息在各个通道的表达特征c/2
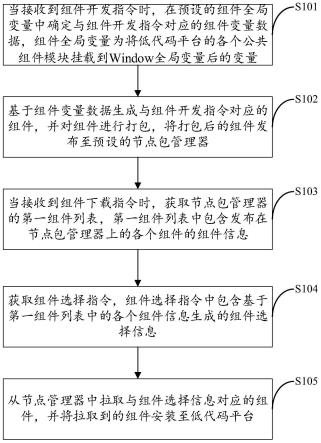
×1×
1,然后通过重整尺寸操作,得到1
×
c/2的矩阵,然后通过softmax激活函数,将位置信息的通道特征权重映射在(0,1)之间。位置的键值和通道的键值类似,都通过1
×
1的卷积操作和重整尺寸操作,将权重转换为矩阵,然后和位置信息的通道特征权重进行矩阵相乘,得到各个位置的权重矩阵,然后通过尺寸重整及sigmoid激活函数,最终得到特征图各个位置的权重特征,其值在(0,1)之间,值越大,表明其对应位置存在目标的概率越大。将位置权重和输入的特征图进行点乘操作,得到最终在位置信息上所获得的注意力特征。将位置注意力特征和通道注意力特征相加,得到最终的注意力机制模块输出结果;
70.(4)由于针对巡检机房的机器人,其目标检测不仅仅针对小指示灯,还要考虑到对设备,大的指示灯、显示面板、仪表等的识别,因此将注意力机制模块加入主干网络的第21、24、27、30层,即模型提取特征图作为检测头输入的那一层,用于增强主干网络输出特征图的上下文交互信息,从而提高模型对所有目标的检测能力,整体的网络结构如图1所示;
71.(5)在训练模型时,优化了yolov5的损失函数,本发明采用以下定义的iou loss作为计算目标框回归的损失函数:
[0072][0073]
上式中α为我们设计的超参,使检测器在实现不同尺寸的目标框回归精度方面具有更大的灵活性;函数ρ(n,m)表示计算n,m两点的欧式距离;上式中b表示模型预测的目标框的中心点;b
gt
表示实际真实的物体框的中心点;w表示预测框的宽度;h表示预测框的高度;相应的h
gt
和w
gt
表示真实的物体框的高和宽;c表示包含预测框和真实物体框的最小矩形框的对角线的距离;ch表示包围预测框和真实框的最小矩形框的高度;cw表示包围预测框和真实框的最小矩形框的宽度。
[0074]
其中iou为目标检测中常用到的目标框交并比计算方式,为公知,不在赘述,其中:
[0075][0076]
上式中d表示预测框和真实物体框中心点之间的距离;c表示包含预测框和真实物体框的最小矩形框的对角线的距离;c和d的表示如图3所示,其中:
[0077][0078][0079]
其中y1,y2,x1,x2为包含预测框和真实物体框的最小矩形框的坐标值,如图3所示;w
pre
表示预测框的宽度值;h
pre
表示预测框的高度值;根据我们现场所收集的服务器机房的数据,设置α=1.65时,模型的收敛速度最快,其精度也最高。
[0080]
进一步的,模型tph-yolov5为iccv 2021workshop下的“vision meets drones:a challenge”所提出的,主要应用在无人机的小目标识别,其注意力机制是采用cbam模型,模型参数大,训练和推理速度慢,无法满足实时性的需求。本发明的注意力机制模型相对参数
少,能达到实时性的需求,且精度优胜于tph-yolov5模型。
[0081]
本发明的有益效果是:
[0082]
1、该基于改进yolov5的小目标识别方法,通过对检测头进行了改进,增加了一个更高分辨率的检测头,从主干网络cspdarknet的21层输出的160x160尺寸的特征图与网络的第2层特征图进行concat操作,以此获得更高分辨率的特征图,作为检测头的输入,则该检测头的输出为10x10的目标,和指示灯的像素尺寸基本相同,从而大大提高目标的检测精度,通过主干网络特征提取部分加入子注意力机制模块,增强小指示灯周围的上下文信息,同时抑制没有指示灯的背景区域权重,达到增强特征图目标权重的目的,通过对通道和空间位置进行并行注意力机制提取,从而从整体提高网络的表征能力,能够在保证计算速度的前提下,通过增加检测头,增强模型的多尺度学习能力,同时通过子注意力机制,增加小目标周围的上下文信息,最后通过优化目标的损失函数,提高模型检测目标框的回归能力,从而全面提高模型对小目标的检测精度,保证了实用性。
[0083]
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。