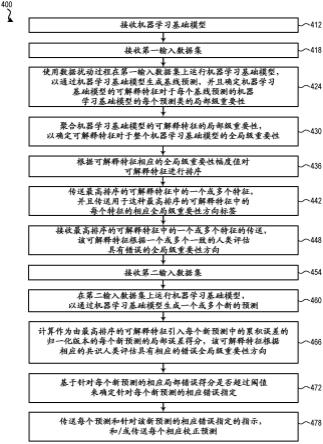
1.本发明属于通信技术领域,具体涉及联合用户与服务多关系的服务质量预测方法。
背景技术:
2.当今时代,信息网络已经成为推动社会发展的巨大动力。自上世纪90年代互联网进入商业化阶段以来,互联网经历了一个迅猛的发展时期,越来越多的 web应用程序被建立和部署在互联网上。互联网web服务就已经进入商业化阶段,此时的互联网发展速度正盛,越来越多的场景会应用到web应用程序。过去几年中已发布的web服务数量快速增长。web服务和面向服务的体系结构 (service-oriented architecture,soa)的流行允许构建不同的面向服务的应用程序,以满足各种用户日益复杂的业务需求。但是,由于移动互联网技术和分布式计算技术在近些年里也发展十分迅速,所以网络环境的复杂程度也越来越大。那么,怎样才能在复杂、动态的网络环境中,准确的预测各个用户在不同情况下使用各种web服务的服务质量(quality of service,qos)属性值是一个具有挑战性的问题。qos一般用来反映web服务的评估标准,通过用户角度的服务评分、响应时间和吞吐量等指标来衡量。为了解决用户需求的差异性,满足用户在不同应用场景获得更好的web服务质量,需要网络根据目标用户的个性化需求分配和调度相关数据,对不同的数据流提供不同的服务质量评估结果。根据历史数据流预测出目标用户的需求服务的服务质量,实现用户在不同场景下获得更好的调用服务体验。直观来看,预测算法精确度得到了显著提高,但是仍旧存在缺陷。例如,数据流应用单一,使得用户的需求没有达到个性化。因此,针对qos值的预测问题,在已有的矩阵分解技术上进行改进:根据已有的数据集多方面考虑数据特征,基于图的形式综合考虑用户与服务之间的直接关系与潜在关系,预测用户未调用服务或者用户下一时刻想要调用某一服务的qos特征需求。基于本方法提高qos值预测的准确度,进而提高用户的体验感。
技术实现要素:
3.有鉴于此,本发明的目的在于提供一种联合用户与服务多关系的服务质量预测方法。
4.为达到上述目的,本发明提供如下技术方案:联合用户与服务多关系的服务质量预测方法,包括以下步骤:
5.步骤1:根据历史数据流,将用户与用户之间的关系以用户图g
uu
来表示、服务与服务之间的关系以服务图g
ss
来表示、用户与服务之间的关系以用户服务图g
us
来表示。
6.步骤2:基于用户图g
uu
、服务图g
ss
和用户服务图g
us
来构建全局图g,并将g中边权值小于阈值θ1的边裁剪掉,形成k个子图g1,g2,
…gk
。
7.步骤3:利用k个子图对应的响应时间qos矩阵来加权原用户与服务之间的响应时间qos矩阵a,从而融合为新的响应时间qos矩阵b。
8.步骤4:将融合的新矩阵b进行矩阵分解求得最小损失函数。
9.步骤5:以平均绝对误差和均方根误差来评估多关系的预测方法性能。
10.本发明的优点及有益效果如下:
11.本发明的创新主要是步骤1、2、3的配合,步骤1将用户数据流,服务数据流,用户与服务的数据流以图的形式展示,避免了传统方法的考虑太片面的问题,在图建立的过程中,不仅考虑用户与服务的直接关系,而且充分考虑用户与服务间的潜在关系。步骤3将处理后的子图与原始图进行融合,使得数据特征更鲜明。综合全局考虑,避免在用户与服务分类考虑单一,以图的形式分类解决了上述问题,再矩阵分解技术预测qos值。基于联合用户与服务多关系的矩阵分解技术(multi relationship matrixfactorization,mrmf)在一定程度上更具有明显优势。总之,本方法结合了图论中图和凸优化中矩阵分解和梯度下降的优势,规避了预测的噪声,通过本方法可以提高服务质量qos预测的准确度,同时提高用户调用服务的体验感。
附图说明
12.为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作优选的详细描述,其中:
13.图1为本发明具体实施方式模拟用户调用服务的关系图;
14.图2为本发明具体实施方式qos值矩阵a;
15.图3为本发明具体实施方式矩阵降阶分解;
16.图4为本发明具体实施方式联合用户与服务多关系的服务质量预测机制的模型;
17.图5为本发明具体实施方式mf算法与mrmf算法loss函数对比图;
18.图6为本发明具体实施方式mf算法与mrmf算法的mae对比;
19.图7为本发明具体实施方式mf算法与mrmf算法的rmse对比。
具体实施方式
20.以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需要说明的是,以下实施例中所提供的图示仅以示意方式说明本发明的基本构想,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。
21.其中,附图仅用于示例性说明,表示的仅是示意图,而非实物图,不能理解为对本发明的限制;为了更好地说明本发明的实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;对本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
22.本发明实施例的附图中相同或相似的标号对应相同或相似的部件;在本发明的描述中,需要理解的是,若有术语“上”、“下”、“左”、“右”、“前”、“后”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此附图中描述
位置关系的用语仅用于示例性说明,不能理解为对本发明的限制,对于本领域的普通技术人员而言,可以根据具体情况理解上述术语的具体含义。
23.一种联合用户与服务多关系的服务质量预测方法的模型图如图1所示,包括以下步骤:
24.步骤1:根据历史数据流,将用户与用户之间的关系以图g
uu
来表示、服务与服务之间的关系以图g
ss
来表示、用户与服务之间的关系以图g
us
来表示;
25.步骤2:基于用户图g
uu
、服务图g
ss
和用户服务图g
us
来构建全局图g,并将g中边权值小于阈值θ1的边裁剪掉,以减少各关系之间的噪声,从而形成k 个子图g1,g2,
…gk
;
26.步骤3:为了综合考虑各节点之间的直接关系与潜在关系,利用k个子图对应的响应时间qos矩阵来加权原用户与服务之间的响应时间qos矩阵a,从而融合为新的响应时间qos矩阵b;
27.步骤4:将融合的新矩阵b进行矩阵分解(matrix factorization,mf)求得最小损失函数;
28.步骤5:以平均绝对误差(mean absolute error,mae)和均方根误差(rootmean squared error,rmse)来评估多关系的服务质量预测方法性能。
29.所述步骤1:根据历史数据流,将用户与用户之间的关系以图g
uu
来表示、服务与服务之间的关系以图g
ss
来表示、用户与服务之间的关系以图g
us
来表示,具体包括:
30.用户与用户的关系:包含用户的经纬度距离关系,用户所在环境自治域的关系,判断综合线性叠加后的结果能否成立关系图。
31.用户图为图g
uu
,用户节点集合视为vu,用户ua与用户ub之间的边联系以权值衡量,表示为e
uu
(属于e
uu
),则g
uu
={vu,e
uu
}。用户的相似关系受网络环境自治域(autonomous system,as)的影响。as域衡量用户相似度关系的公式如(1)所示:
[0032][0033]wasu
(ua,ub)表示网络环境自治域下的相似度,表示用户ua所在的网络环境自治域,表示用户ub所在的网络环境自治域。由公式(1)可知,倘若用户ua与用户ub在同一网络环境自治域下,则衡量相似度的权值为1,否则为0。
[0034]
采用用户所在位置的经纬度计算该部分的相似度关系。由于用户在地球上,计算两个用户之间的实际距离时用公式(2):
[0035]
s(ua,ub)=r
·
arccos[cosβ
1 cosβ2cos(α
1-α2) sinβ
1 sinβ2]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0036]
上述公式中,r是地球半径,用户ua的纬度角为β1,经度角为α1;用户ub的纬度角为β2,经度角为α2。
[0037]
为了归一化用户之间的距离,使得距离的权值衡量合理,归一化的公式如(3) 所示:
[0038][0039]wdis
(ua,ub)表示用户ua与用户ub的距离相似度权值,当实际距离s(ua,ub)越小时,那么,两个用户的相似度权值w
dis
(ua,ub)就越大,其区间为[0,1]。
[0040]
综合考虑影响用户相似关系的因素,充分利用用户所在网络环境自治域与用户所在地理位置的数据流,将两者的权值(包括网络环境自治域下用户的相似权值、归一化用户之间距离下的相似权值)进行线性加权处理,得到公式(4):
[0041][0042]
其中,e(ua,ub)表示用户ua与用户ub之间的相似度值。λ1是调整用户所在网络环境自治域下的相似度权值占整体的权重比例,λ2是调整用户所在地理位置下的相似度权值占整体的权重比例。两者的关系为:λ1 λ2=1,λ1>0,λ2>0。其中χ1为控制用户节点之间边的阈值,倘若加权和大于其阈值,则两节点之间存在边,否则两个用户节点之间不存在边。
[0043]
服务与服务的关系:包含服务界面爬虫得到的词向量之间的相似关系,服务所在环境自治域的关系,判断综合线性叠加后的结果能否成立关系图。
[0044]
服务图为图g
ss
,服务节点集合视为vs,服务sa与服务sb之间的边联系以权值衡量,表示为则g
ss
={vs,e
ss
}。在同一个as域系统的服务有着相似的特性,因此服务的相似性受到as域系统的影响,如公式(5)所示:
[0045][0046]
其中w
ass
(sa,sb)表示服务sa与服务sb在自治域系统下的相似权值,若服务sa与服务sb在同一自治域系统,则权值为1,否则为0。表示服务sa所在的网络环境自治域,表示服务sb所在的网络环境自治域。
[0047]
根据爬虫技术访问每个服务并抓取每个服务网页的内容,首先,找出两个服务网页内容的关键词,每个服务网页各取出若干个关键词,合并成一个集合,计算每个服务网页对于这个集合中的词的词频,生成每个网页的特征向量词,根据余弦相似度计算服务网页的相似度,如公式(6)所示:
[0048][0049]
其中xi和yi分别是服务sa和服务sb的网页关键词的特征向量,取出前z个关键词形成特征向量词,得到服务网页的相似性权值,值越大就表示越相似。
[0050]
综合考虑服务关系的影响因素,研究数据集发现,服务所在的网络环境自治域系统与服务网页本身的内容对服务的相似性起着关键性作用,两者线性叠加求和,如公式(7)所示:
[0051][0052]
上述公式综合考虑两者的关系,其中λ3,λ4为服务所在的网络环境自治域系统与服务网页内容所占服务关系的权重比例。χ2为决定服务之间的阈值,若加权和大于其阈值,则两个服务节点之间存在边,否则两节点之间不存在边。 e
ss
(sa,sb)表示服务sa和服务sb的相
似度权值。
[0053]
用户与服务的关系:包含用户调用服务的响应时间和用户请求服务时的吞吐量。
[0054]
用户服务图为图g
us
,包括三要素:用户节点、服务节点、用户与服务交互的边,即为g
us
={vu,vs,e
us
}。用户与服务的交互信息有响应时间和吞吐量,这种交互信息可以直观的呈现用户调用服务的动态响应情况,一般以qos值的形式体现。响应时间(response time,rt)的值越小,反映出用户调用的服务所需的等待时间越短,意味着用户对此服务的偏好程度越高。吞吐量(through put,tp) 指系统在单位时间内处理请求的数量,tp的值越大,反映出服务响应用户的请求数越多,响应时间越短。对于无并发的应用系统而言,吞吐量与响应时间呈严格的反比关系。由于本发明需要归一化数据,由上文可知用户图的边权值越大用户之间联系越密切,服务图的边权值越大则服务之间联系越密切,tp的值越大,则反映用户与服务的联系越密切。因此本发明使用tp值创建ua与sb之间的边信息,tp
ab
表示为服务sb在单位时间内处理用户ua请求的数量,吞吐量的处理如公式(8)所示:
[0055][0056]
其中tp
ab
为归一化后的值,因此将吞吐量归一化处理如公式(9)-(13)所示:
[0057][0058]
其中,tp
max
,tp
min
分别为所有用户调用所有服务时的最大tp值与最小tp值, tp
ab
'为ua调用sb的吞吐量归一化后的值。每个元素越大,意味着服务响应的用户请求越多,也就代表着用户与服务的关系越密切。
[0059]
所述步骤2:基于用户图g
uu
、服务图g
ss
和用户服务图g
us
来构建全局图g,并将g中边权值小于阈值θ1的边裁剪掉,以减少各关系之间的噪声,从而形成k 个子图g1,g2,
…gk
;具体包括:
[0060]
全局图g:用户图、服务图、用户与服务图构建为一个完整的有权无向图g,那么g={g
uu
,g
ss
,g
us
}。也可以表示为g={vu,vs,e
uu
,e
ss
,e
us
},其中包括用户节点集合为vu,服务节点集合为vs,用户之间关系的边集合为e
uu
,服务之间关系的边集合为e
ss
,用户与服务之间关系的边集合为e
us
。
[0061]
边权值:归一化后的边的权值范围在[0,1],权值越大代表节点联系越密切。
[0062]
噪声:权值小于阈值θ1的边,其边包括用户之间的边,服务之间的边,用户与服务之间的边。
[0063]
子图:为减少各关系之间的噪声,将全局图g的边进行切割,形成子图 g1,g2,
…gk
,每个子图中含有节点和边两个因素。
[0064]
所述步骤3:为了综合考虑各节点之间的直接关系与潜在关系,利用k个子图对应的响应时间qos矩阵来加权原用户与服务之间的响应时间qos矩阵a,从而融合为新的响应时间qos矩阵b,具体包括:
[0065]
直接关系:用户直接调用服务为直接关系。
[0066]
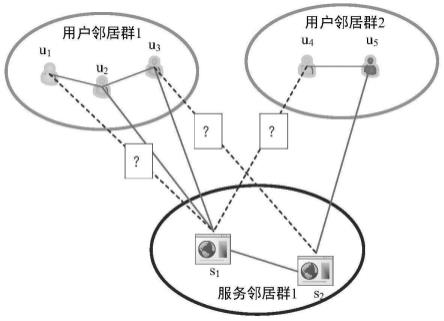
潜在关系:包括联系密切的多个用户和同一个服务的关系,图1中,用户邻居群1中用户u1,u2,u3密切相关,在历史数据中,仅有u2,u3调用过服务s1,那么用户u1与服务s1存在潜在关系,用户u1,u3与服务s2也存在潜在联系。
[0067]
矩阵a:历史数据流中,初始的用户调用服务的响应时间qos矩阵。用户调用服务的
数据可以整理为一个user-service矩阵,矩阵中每一行代表一个用户,而每一列则代表一个服务。若用户调用过服务,则矩阵中处在用户对应的行与服务对应的列交叉的位置表示用户调用服务的响应时间,这个user-service矩阵被称为qos矩a阵。其中“?”表示用户还未调用过服务,如图2所示。
[0068]
矩阵b:将k个子图对应的响应时间qos矩阵来线性加权原用户与服务之间的响应时间qos矩阵a得到矩阵b,如公式(12)所示。
[0069]
所述步骤4:将融合的新矩阵b进行矩阵分解技术求得最小损失函数,具体包括:
[0070]
矩阵分解技术:由于初始矩阵存在矩阵比较稀疏的问题,为了解决这一问题,于是提出了矩阵分解技术,主要思路是将原始评分矩阵m(m*n)分解成两个矩阵p(m*k)和q(k*n),同时仅考察原始矩阵中有调用值的项分解结果是否准确,判别标准则是平均绝对误差和均方根误差。
[0071]
对于原始qos矩阵r,我们假定一共有三类隐含特征,于是将矩阵r(4*5) 分解成用户特征矩阵p(4*3)与服务特征矩阵q(3*5)。考察user1调用service1 的qos值,可以认为user1对三类隐含特征class1、class2、class3的感兴趣程度分别为p11、p12、p13,而这三类隐含特征与service1相关程度则分别为q11、 q21、q31、q41。如图3所示。图3的表达式为公式(11),可以发现用户u对服务s最终调用得到的qos值就是由各个隐含特征维度下u对s感兴趣程度的和,用户u对服务s的感兴趣程度则是由用户u对当前隐含特征的感兴趣程度乘上服务s与当前隐含特征相关程度来表示的。
[0072]
那么,对于矩阵m(m*n),视为该矩阵有k个隐性因子,那么则分解为p(m*k)、 q(k*n),此时对于原始矩阵中有调用qos值的位置m
us
来说,其在分解后矩阵中对应的值m'
us
如公式(10)所示:
[0073][0074]
p
u,k
,q
k,s
为生成的两个低阶的随机正态矩阵,k表示隐性因子
[0075]
那么对于整个服务质量矩阵而言,总的损失函数如公式(11)所示:
[0076]
sse=e
u,s2
=∑
u,s
(m
u,s-m'
u,s
)2ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(11)
[0077]
其中,e
u,s
表示原始qos矩阵m
u,s
与重新构建m'
u,s
之间的误差值。
[0078]
梯度下降法:核心思想是沿梯度下降的方向逐步迭代。梯度是一个向量,表示的是一个函数在该点处沿梯度的方向变化最快,变化率最大,而梯度下降的方向就是指的负梯度方向。随机梯度下降法主要是用来解决求和形式的优化问题,其思想是:既然对于求和式中每一项求梯度较为繁琐,那么就随机选其中一项计算梯度当作总的梯度来使用。
[0079]
具体应用到目标函数,如下公式(12)所示:
[0080][0081]
sse是关于p和q的多元函数,(其中p和q分别表示随机生成的两个低阶矩阵。)当随机选定u和s之后,需要枚举所有的k,并且对p
u,k
以及q
k,s
求偏导数。整个式子中仅有p
u,kqk,s
这一项与之相关,通过链式法则(如公式(13)(14)) 可知:
[0082]
[0083][0084]
在实际的运算中,为了p和q中所有的值都能得到更新,一般是按照在线学习的方式选择qos矩阵中有调用值的点对应的u、s来进行迭代。
[0085]
正则化:加入正则化项,则是防止过拟合的经典处理方法,具体做法就是在损失函数后面加入一个l2正则项,损失函数公式如(15),即:
[0086][0087]
其中,λ为正则化系数,整个求解过程依然可以使用随机梯度下降完成。pu, qs分别用户矩阵和服务矩阵的正则化项。
[0088]
损失函数:包括预测值与真实值的差值累加和,为了防止目标函数过度拟合,在损失函数中加入正则项,如公式(16)(17)所示。
[0089]
b=μ1m
u,s
μ2m
ku,s
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(16)
[0090][0091]
其中,矩阵b为经数据特征处理后新融合的矩阵,λ'为新矩阵损失函数中的正则化系数,为新矩阵的矩阵分解公式。其中,μ1表示原始矩阵a的权值占重系数,μ2表示子矩阵权值占重系数,m
ku,s
表示子矩阵,p'u, q's分别融合后的用户矩阵和服务矩阵的正则化项。
[0092]
所述步骤5:以平均绝对误差和均方根误差评估改进的预测方法性能,具体包括:
[0093]
平均绝对误差:是绝对误差的平均值,它其实更是一般形式的误差均值。表示预测结果与实际值之间的平均差,所有个体差异均加权,mae的具体计算方法如公式(18)所示:
[0094][0095]
其中r(u,s)为初始的响应时间矩阵,r'(u,s)为预测的响应时间矩阵,l为矩阵中元素的总个数。
[0096]
均方根误差:是测量误差的平均大小,它是预测值与实际观测值之间平方差异平均值的平方根。rmse的具体计算方法如公式(19)所示:
[0097][0098]
通过矩阵分解技术与改进的算法进行qos预测准确性的比较,通过评估 qos预测的准确性是平均绝对误差与均方根误差,评估本发明的改进方法的效率和有效性。
[0099]
本发明提出了一种联合用户与服务多关系的服务质量预测方法,联合用户与服务多关系的服务质量预测机制整体流程图如图4所示,在数据集、服务器相同的条件下,矩阵分解(matrix factorization,mf)算法是将原始评分矩阵 m(m*n)分解成两个矩阵p(m*k)和q(k*n),同时仅考察原始矩阵中有调用值的项分解结果是否准确,判别标准则是平均绝对误差和均方根误差。相比传统的mf 算法,联合用户与服务多关系进行矩阵分解的方法在损失函数收敛程度上更具有明显优势,在评判准则平均绝对误差和均方根误差上均具有优势。本方案在不同数据集密度上运行的结果可看出,预测的准确性均提高,如图6,图7所示。
[0100]
图5是mf算法与mrmf算法loss函数对比图,从展示的实验结果看,随着数据集密度的不断增大,mf算法与mrmf算法的损失函数收敛趋势越来越快,是因为在矩阵分解中隐性因子的影响。另外,在迭代初始位置,loss值随着数据集密度的增大而增大,由于矩阵分解是随机生成的低阶矩阵合成造成的,因此需要迭代步长的增加,直至loss函数收敛趋势,此刻对应的两个低阶矩阵便为最佳矩阵。两低阶矩阵相乘后得到满秩矩阵,此矩阵便为预测的矩阵。由上图可知,mrmf算法中的损失函数值一直处于mf算法的损失函数值的下方, mrmf算法的loss值随着迭代步数的增加而越来越小,有助于qos预测精度的提升。
[0101]
图6展示了mf算法得到的qos预测值的平均绝对误差与mrmf算法的比较。由图可知,在不同的数据集密度下运行的结果是mrmf算法的mae均小于mf算法的mae。为了进一步说明mrmf算法的误差减小,图7展示了不同数据集密度时,qos预测值的精确度提升率。在数据集密度10*10时,mrmf 比mf的mae减小了96%,由于数据密度比较小,所以效果比较明显;在数据集密度30*30时,mrmf比mf的mae减小了36%;在数据集密度50*50时, mrmf比mf的mae减小了20%;在数据集密度100*100时,mrmf比mf 的mae减小了20%;在数据集密度200*200时,mrmf比mf的mae减小了 18%。这说明mrmf比mf具有更好的性能,这可以归因于mrmf利用图的模型有效的整合了用户与服务的多关系,不仅仅考虑用户与服务的直接关系,进一步考虑用户与服务的潜在关系,减小了mae,提高了qos预测精度。
[0102]
图7展示了mf与mrmf的rmse指标比较,从图中可以看出,mrmf 算法的性能优于mf算法。在不同的数据集密度下,mrmf的rmse值始终低于mf的rmse值。图7展示了两种算法在rmse指标上的误差减小率,在数据集密度10*10时,mrmf比mf的rmse减小了60%;在数据集密度30*30 时,mrmf比mf的rmse减小了38%;在数据集密度50*50时,mrmf比 mf的rmse减小了22%;在数据集密度100*100时,mrmf比mf的rmse 减小了22%;在数据集密度200*200时,mrmf比mf的rmse减小了18%。从整体结果看,相比mf算法而言,mrmf算法对qos预测精度提升明显,主要归因于综合考虑了联合用户与服务的多关系,挖掘了用户与服务的潜在关系,通过深入研究数据集的特征,重新构建新矩阵,使得潜在关系得到发掘和应用。调整qos值原始矩阵,融合构建为新矩阵,最终在qos预测精确度中体现其价值,精确度在一定程度上提高。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。