:
1.本发明涉及糖尿病视网膜领域,尤其涉及一种基于分割和分类相融合的糖尿病性视网膜病变检测方法。
背景技术:
2.目前,糖尿病视网膜病变诊断检测的研究领域已经有了很多重要发现。国外基于全局图像的糖尿病视网膜分类针对全图的整体特征信息来设计不同的特征提取方法进行分类,不需要针对单一的病灶特征信息进行特定的检测方法,避免复杂的特征提取工作。2014年antal提出了一种基于整体的糖尿病视网膜病变筛查方法。该方法是基于从几种视网膜图像处理算法的输出中提取的特征,例如图像级别(质量评估,预筛查,am/fm),病变特定(微动脉瘤,渗出液)和解剖结构(黄斑,视盘)。然后由一组机器学习分类器做出有关疾病存在的最终判断。2016年pratt提出了一种基于cnn的方法,用于从数字眼底图像诊断dr并对其严重性进行准确分类。开发了具有cnn特性的体系结构和数据增强功能的网络,该网络可以识别分类任务中涉及的复杂特征,例如视网膜上的微动脉瘤,渗出液和出血,因此可以自动进行诊断,而无需用户输入。2019年torre等提出了糖尿病性视网膜病深度学习可解释的分类器。一方面,它将视网膜图像分类为具有可分辨特征的不同严重程度。另一方面,该分类器能够通过为隐藏和输入空间中的每个点分配分数来解释分类结果。
3.在我国,已经有很多高等院校进行了糖尿病视网膜分类检测的研究,并且取得很多成果。2012年,哈尔滨工业大学的陈向在分类阶段,针对分辨硬性渗出的需求,分析其图像中的特点后对所有待检验区域抽取了44个特征向量,使用支持向量机(supportvector machine,svm)进行分类,进而获得最终的分类器。2017年,人工智能技术得到了社会各界的广泛关注,深度学习日渐成为人工智能领域的主流学习算法。2017年,北京交通大学的丁蓬莉根据视网膜数据集的特殊性提出了一系列图像预处理方式,设计了紧凑的神经网络模型—compactnet,比较了迭代次数和kappa,可以得出compactnet网络的微调方法要优于其他的网络的结论。先对图像数据集进行了数据预处理,使得不同类别的数量得到均衡。然后在dsn中添加了针对分类的监督信号,使得网络训练的准确率提高,训练时间也由15天减少至2.5天。同年,深圳大学的熊彪使用卷积神经网络对视网膜图像进行分类。在进行数据预处理扩增图像后,使用迁移学习对网络结构进行预训练,最后使用视网膜图像对网络进行训练。2018年周磊为了实现dr分类提出的一种多阶段注意力模型,这种注意力机制与cnn相结合提高分类的准确率。此外,使用稠密条件随机场进行图像分割,并使用多目标的分割算法对病灶进行了分割。
技术实现要素:
4.本发明为了克服现有方法的不足和缺点,提出一种基于分割和分类相融合的糖尿病性视网膜病变检测方法,特别是针对目前该领域数据存在域差异的问题,该发明将病变进行分割,作为分类的主要依据。以解决糖尿病视网膜病变诊断检测数据域差异的问题。
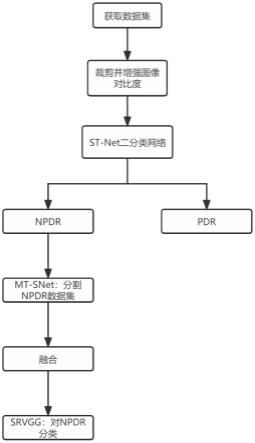
5.一种基于分割和分类相融合的糖尿病性视网膜病变检测方法,其特征在于,包括如下步骤:
6.步骤1:获取idrid和ddr公开的数据集,同时对数据集进行预处理;
7.步骤2:使用设计的st-net对npdr和pdr数据进行分类;
8.步骤3:基于传统的unet网络,对其中的encoder进行改进,并融入vision transformer(构成mt-snet)对npdr的视网膜病变分割。并将分割的病变再融入到对应的原始视网膜图中;
9.步骤4:使用所设计的srvgg对分割后的npdr数据进行分类。
10.步骤1的实现包括:
11.步骤1.1:获取idrid和ddr公开的数据,其中idrid数据集采集431张视网膜图片,其中含有病变的一共81张,54张作为训练集,27张作为测试集,同时对每张图片进行标注了病变等级;
12.步骤1.2:ddr数据集采集了13673张视网膜图片,其中6835张作为训练集,2733张作为验证集,4105张作为测试集,同时对其中的757张图片进行了病变标注;
13.步骤1.3:先对数据进行裁剪,将多余的黑色边框裁剪掉。同时利用直方图均衡化实现数据对比度增强;
14.步骤1.4:通过重采样的方式实现类平衡。先对数据量大的类缩减样本,再通过旋转、裁剪、反转等方式对数据量小的类扩增。
15.步骤2的实现包括:
16.步骤2.1:在resnet-50的基础上添加rga注意力机制,构成新的st-net;
17.步骤2.2:使用st-net对npdr和pdr数据进行分类。
18.步骤3的实现包括:
19.步骤3.1:在unet基础上,将其encoder部分替换为vgg16,同时对卷积进行分块,并去掉最后的全连接层;
20.步骤3.2:在修改后的unet中引入vision transformer;
21.步骤3.2.1:对encoder得到的图像进行序列化:
22.encoder得到的矩阵格式不符合vision transformer的输入格式。按着vision transformer的介绍,需要经过一个图像序列化的过程,将输入的图像形状重塑为2dpatch,patch的表示如公式(1):
[0023][0024]
其中每个patch的大小是p
×
p,是图像patch的数量(即输入序列长度)。
[0025]
步骤3.2.2:获取并添加病变的位置信息:
[0026]
经过图像序列化之后,使用可训练线性投影将矢量化patches xp映射到潜在的d维嵌入空间。为了编码patch的空间信息,我们学习了特定的病变位置信息。这些位置被添加到patch中,以保留位置信息,具体过程如公式(2)。
[0027]
[0028]
其中e是patch的嵌入投影,表示学习到的病变位置。
[0029]
步骤3.2.3:带有病灶位置的序列输入到visiontransformer中进行特征提取,重复十二次:
[0030]
visiontransformer块由l层多头自我注意(msa)和多层感知机(mlp)块组成(公式(3)(4))。因此,第τ
th
层的输出可写入如下。
[0031]q′
ε=msa(ln(qε-1)) qε-1(3)
[0032]
qε=mlp(ln(q
′
ε)) q
′
ε(4)
[0033]
其中ln(~)表示层归一化操作符,qε表示编码图像表示。
[0034]
步骤3.3:利用分割网络将视网膜图像的病变进行分割,并将分割后的图像与原始对应的图像融合。
[0035]
步骤4的实现包括:
[0036]
步骤4.1基repvgg,在此基础上加入空间注意力机制,构成srvgg;
[0037]
步骤4.2利用分割后ddr数据集训练网络;
[0038]
步骤4.3利用srvgg对ddr数据集进行分类,实现npdr的分类。最终结合第一阶段的结果,实现dr五分类,计算过程如公式(5)。
[0039]
附图说明:
[0040]
图1是分割和分类相融合的糖尿病性视网膜病变检测方法流程图。
[0041]
图2基于分割和分类相融合的糖尿病性视网膜病变检测方法的结构图。
具体实施方式:
[0042]
下面将结合本发明实施例中的附图对本发明实施例中的技术方案进行清楚、完整地描述。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0043]
图1是本发明实施的整体流程示意图,如图1所示,该方法包括:
[0044]
步骤1:获取idrid和ddr公开的数据集,同时对数据集进行预处理;
[0045]
步骤2:使用设计的st-net对npdr和pdr数据进行分类;
[0046]
步骤3:基于传统的unet网络,对其中的encoder进行改进,并融入visiontransformer(构成mt-snet)对npdr的视网膜病变分割。并将分割的病变再融入到对应的原始视网膜图中;
[0047]
步骤4:使用所设计的srvgg对分割后的npdr数据进行分类。
[0048]
步骤1的实现包括:
[0049]
步骤1.1:获取idrid和ddr公开的数据,其中idrid数据集采集431张视网膜图片,其中含有病变的一共81张,54张作为训练集,27张作为测试集,同时对每张图片进行标注了病变等级;
[0050]
步骤1.2:ddr数据集采集了13673张视网膜图片,其中6835张作为训练集,2733张
作为验证集,4105张作为测试集,同时对其中的757张图片进行了病变标注;
[0051]
步骤1.3:先对数据进行裁剪,将多余的黑色边框裁剪掉。同时利用直方图均衡化实现数据对比度增强;
[0052]
步骤1.4:通过重采样的方式实现类平衡。先对数据量大的类缩减样本,再通过旋转、裁剪、反转等方式对数据量小的类扩增。
[0053]
步骤2的实现包括:
[0054]
步骤2.1:在resnet-50的基础上添加rga注意力机制,构成新的st-net;
[0055]
步骤2.2:使用st-net对npdr和pdr数据进行分类。
[0056]
步骤3的实现包括:
[0057]
步骤3.1:在unet基础上,将其encoder部分替换为vgg16,同时对卷积进行分块,去掉最后的全连接层;
[0058]
步骤3.2:在修改后的unet中引入visiontransformer;
[0059]
步骤3.2.1:对encoder得到的图像进行序列化:
[0060]
encoder得到的矩阵格式不符合visiontransformer的输入格式。按着visiontransformer的介绍,需要经过一个图像序列化的过程,将输入的图像形状重塑为2dpatch,patch的表示如公式(1):
[0061][0062]
其中每个patch的大小是p
×
p,是图像patch的数量(即输入序列长度)。
[0063]
步骤3.2.2:获取并添加病变的位置信息:
[0064]
经过图像序列化之后,使用可训练线性投影将矢量化patchesxp映射到潜在的d维嵌入空间。为了编码patch的空间信息,我们学习了特定的病变位置信息。这些位置被添加到patch中,以保留位置信息,具体过程如公式(2)。
[0065][0066]
其中e是patch的嵌入投影,表示学习到的病变位置。
[0067]
步骤3.2.3:带有病灶位置的序列输入到visiontransformer中进行特征提取,重复十二次:
[0068]
visiontransformer块由l层多头自我注意(msa)和多层感知机(mlp)块组成(公式(3)(4))。因此,第τ
th
层的输出可写入如下。
[0069]q′
ε=msa(ln(qε-1)) qε-1(3)
[0070]
qε=mlp(ln(q
′
ε)) q
′
ε(4)
[0071]
其中ln(~)表示层归一化操作符,qε表示编码图像表示。
[0072]
步骤3.3:利用分割网络将视网膜图像的病变进行分割,并将分割后的图像与原始对应的图像融合。
[0073]
步骤4的实现包括:
[0074]
步骤4.1基repvgg,在此基础上加入空间注意力机制,构成srvgg;
[0075]
步骤4.2利用分割后ddr数据集训练网络;
[0076]
步骤4.3利用srvgg对ddr数据集进行分类,实现npdr的分类。
[0077][0078]
表1、表2和表三分别是本发明方法与其它先进方法在分割和分类两个领域的对比情况,结果充分表明本发明方法在糖尿病视网膜病变检测任务上的优越性。
[0079]
表1 提出的方法与以往先进研究的比较(多病变分割实验)
[0080][0081]
表2 提出的网络与流行网络的比较(共同使用处理后的的同一个数据集)
[0082][0083]
表3 提出的方法与先进研究在分类指标上的对比
[0084][0085]
应当理解的是,本说明书未详细阐述的部分均属于现有技术。
[0086]
以上结合附图所述,仅为本发明的具体实施方式及流程,但本发明的保护范围并不局限于此,任何熟悉本领域的技术人员应当理解,此仅为举例说明,可以对此实施方式做出多种变化和替换,而不背离本发明的实质内容。本发明的范围仅由所附权利要求书限定。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
