1.本发明涉及计算机视觉技术领域,具体为基于动态时序多维自适应图卷积网络的骨架行为识别方法。
背景技术:
2.行为识别作为计算机视觉领域研究的热点,在当今社会的智能安防、智能监控、智慧医疗等领域有着广泛的应用,随着深度学习技术在计算机视觉领域的发展与应用,其在行为识别研究上也取得更加显著的效果。骨架信息是人体的高级特征,与rgb数据和深度数据相比,它具有受外观影响小,能够有效避免背景遮挡、光照变化以及视角变化产生的噪声影响,方便存储与计算的优点。因此,基于骨架的行为识别方法成为当下的热门研究领域之一。由于人体骨架关节本身是一种拓扑图,而图卷积神经网络在处理这种拓扑图方面具有优越的性能,有学者将图卷积与骨架行为识别相结合,提出了基于图卷积的骨架行为识别技术。然而,现有的用于骨架行为识别的图卷积网络在针对空间特征进行建模时,虽然考虑了时间特征,但是对于时间特征进行建模时表示能力较弱,导致识别准确率较低和泛化性能较差。
技术实现要素:
3.为了解决现有的骨架行为识别方法识别准确率较低和泛化性能较差的问题,本发明提供一种基于动态时序多维自适应图卷积网络的骨架行为识别方法,其可以在骨架时空图中充分提取多维、动态、有效的时空特征信息,不但有较高的识别准确率,同时具备有良好的泛化性能。
4.本发明的技术方案是这样的:基于动态时序多维自适应图卷积网络的骨架行为识别方法,其包括以下步骤:
5.s1:获取原始视频样本,对所述原始视频样本进行预处理,并获取所述原始视频样本中骨架信息数据;
6.s2:将原始视频样本的骨架信息数据建模成骨架时空图;
7.s3:基于获取的骨架信息数据,进行数据处理后,提取骨架行为特征数据,基于所述骨架行为特征数据获得多支流的训练数据,记作:多支流训练用特征数据;
8.其特征在于,其还包括以下步骤:
9.s4:基于自适应图卷积方法和动态卷积,构建动态时序多维自适应图卷积网络模型,作为骨架行为识别模型;所述骨架行为识别模型包括:骨架行为识别支流模型;
10.s5:设置并调整所述骨架行为识别模型的超参数,使用所述多支流训练用特征数据,对所述骨架行为识别模型中的每一个所述骨架行为识别支流模型进行训练,获得训练好的所述骨架行为识别支流模型;
11.s6:获取待识别视频数据,提取待识别视频数据组中的骨架信息数据,基于骨架信息数据提取待识别骨架时空图,将所述待识别骨架时空图并分别输入到每一个训练好的所
述人体骨架行为识别支流模型中,将各支流模型的输出进行融合,得到最终的骨架行为识别结果;
12.步骤s4中,构建动态时序多维自适应图卷积网络模型,包括以下步骤:
13.s4-1:将所述骨架时空图中每一个节点的邻域进行子集划分,得到所述骨架时空图对应的骨架节点子集;所述骨架节点子集包括:节点自身子集、向心邻居节点子集、离心邻居节点子集;
14.所述节点自身子集中包括节点自身;
15.所述向心邻居节点子集中包括:靠近骨架重心的向心邻居节点;
16.所述离心邻居节点子集中包括:远离骨架重心的离心邻居节点;
17.s4-2:基于所述骨架时空图,构建多维度自适应图,所述多维度自适应图包括:空间自适应图、时间自适应图和通道自适应图;
18.所述空间自适应图为基于所述骨架时空图提取的空间图;
19.所述时间自适应图为基于所述骨架时空图提取的时间图经过维度变换后生成;
20.所述通道自适应图为基于所述骨架时空图提取的通道图经过维度变换后生成;
21.将所述多维度自适应图和初始邻接矩阵及掩码矩阵相结合得到多维自适应邻接矩阵,将所述多维自适应邻接矩阵进行图卷积,并与所述骨架节点子集一起构建空间图卷积层,记作:多维自适应图卷积模块;
22.s4-3:基于所述骨架时空图,引入对二维卷积权重和偏置的注意力机制,构造9
×
1的动态时序卷积提取所述骨架时空图的时间特征,构建时序图卷积层,记作:动态时序卷积模块;
23.s4-4:将所述多维自适应图卷积模块和所述动态时序卷积模块相结合,构建动态时序多维自适应图卷积块;
24.所述动态时序多维自适应图卷积块包括:依次连接的多维自适应图卷积层、bn层、relu和动态时序卷积层;
25.s4-5:构建所述骨架行为识别模型;
26.所述骨架行为识别模型包括:依次连接的bn层、10个动态时序多维自适应图卷积块、gap层和softmax层。
27.其进一步特征在于:
28.步骤s3中,所述多支流训练用特征数据包括:节点信息joint、骨骼信息bone、节点运动信息joint_motion、骨骼运动信息bone_motion;
29.步骤s3中,基于骨架信息数据,提取骨架行为特征数据,对所述骨架行为特征数据进行建模的方法,包括以下步骤:
30.s3-1:以节点自身建模作为关节信息,假设t帧的节点信息joint表示为jt;
31.s3-2:以靠近骨骼重心的节点为源节点以远离骨骼重心的节点为目标节点骨骼信息bone表示源节点指向目标节点的向量由于节点数比骨骼数多1,将中心节点设置为空骨骼即值为0;
32.s3-3:节点运动信息和骨骼运动信息以各自相邻两帧之间的坐标差表示,因此节点运动信息joint_motion计算公式为骨骼运动信息bone_motion的计算公
式为由于时间帧数比运动信息多1,将最后一帧的值设为0;
33.步骤s4-2中,构造多维自适应图卷积模块的步骤包括:
34.s4201:定义节点、时间帧和通道为各自维度的维度节点,使用归一化的嵌入高斯函数来计算两个维度节点vi和vj的相似度f(vi,vj):
[0035][0036]
其中:n为维度节点的个数,θ(vi)、φ(vj)选用两个并行的1
×
1卷积运算,作为维度节点i和维度节点j的嵌入函数;
[0037]
s4202:结合softmax函数计算空间图sk、时间图tk、通道图ck,计算公式分别为:
[0038][0039][0040][0041]
式中f
in
代表输入的骨架行为特征数据,w
θ
、w
φ
分别表示嵌入高斯函数θ和φ;
[0042]
其中空间图sk∈rv×v即空间自适应图,对时间图tk∈r
t
×
t
和通道图进行维度变换,生成时间自适应图和通道自适应图
[0043]
s4203:结合各维度自适应图和初始邻接矩阵生成多维自适应邻接矩阵,进行图卷积操作:
[0044][0045]
其中,分别为输入特征和多维自适应图卷积的输出,c
in
表示输入通道,c
out
表示输出通道;wk为卷积核函数,kv代表预定义的最大距离;ak是初始邻接矩阵,bk是一种增强数据掩码矩阵,sk、分别是通过非局部网络生成的空间自适应图、时间自适应图和通道自适应图;
[0046]
步骤s4-3中,构造所述动态时序卷积模块的步骤包括:
[0047]
s4301:挤压阶段;
[0048]
通过全局平均池化将特征的维度压缩到通道所表示的维度;挤压过程表示为:
[0049][0050]
式中,t代表帧数,v代表节点数,i和j表示时域中第i帧和空域第j个节点,x为输入的特征,z为通道挤压后的特征图;
[0051]
s4302:激励阶段;
[0052]
通过两次全连接计算后,经过softmax函数激活和温度系数得到权值,计算公式为:
[0053]
z=w2δ(w1z)
[0054][0055]
其中,δ代表relu激活函数,σ代表softmax激活函数,w1、w2分别表示两次全连接的权重参数,z表示通道挤压后的特征图,z表示第二层全连接的输出,τ表示温度系数;k表示参与聚合的卷积核个数,πk为第k个卷积核对应的注意力权值,zk为第k个卷积核在z中对应的值,zj为第j个卷积核在z中对应的值;
[0056]
s4303:根据se模块得到的权重和偏置的注意力,计算动态卷积核中的权重和偏置:
[0057][0058][0059]
式中,k为卷积核个数,wk为第k个卷积核的权重,πk为第k个卷积核的注意力权值,w为动态卷积核权重,bk为第k个卷积核的偏置,b为动态卷积核的偏置;
[0060]
s4304:构造9
×
1的动态卷积层对多维自适应图卷积层的输出进行卷积操作,计算公式为:
[0061]
y=δ(wf
out
b)
[0062]
式中,y为动态卷积后的输出,f
out
为多维图卷积层的输出,δ为relu激活函数;
[0063]
步骤s5中,基于多支流网络的训练方式,分别使用所述分支训练数据训练所述动态时序多维自适应图卷积网络模型时,采用随机梯度下降法作为优化策略,选择交叉熵函数作为梯度反向传播的损失函数。
[0064]
本发明提供的一种基于动态时序多维自适应图卷积网络的骨架行为识别方法,在动态时序多维自适应图卷积网络模型的空间域上,通过非局部网络和维度变换获取空间自适应图、时间自适应图和通道自适应图,将多维度自适应图与初始邻接矩阵及掩码矩阵相结合,提出一种新的多维自适应邻接矩阵参与空间图卷积,得到多维自适应图卷积模块;多维自适应图卷积模块中通过多维自适应邻接矩阵增强了对人体骨架信息在空间、时间和通道维度的特征的提取能力,更能表达骨架时空图中节点间、帧间和通道间的连接关系和各维度之间的关联性,从而在图卷积过程中更能挖掘人体骨架的多维度结构特征,提高了多维度行为信息的关联性,增强了行为特征的空间提取能力,确保提高了最终的骨架行为识别的准确率;在动态时序多维自适应图卷积网络模型的时间域上,通过结合动态卷积和时序卷积,在时序卷积中引入se注意力网络计算各卷积核权重和偏置的权值,相结合构造为动态时序卷积网络,增强了时间特征的表示能力,实现了时间域中行为信息特征的充分提取,提高了识别准确率;结合多维自适应图卷积模块和动态时序卷积模块构建的动态时序多维自适应图卷积模型,在多流网络下进行端到端的训练后得到训练好的基于骨架的行为识别支流模型,能够在待识别时空图中充分提取多维、动态、有效的时空特征信息,使模型取得优异的识别准确率和良好的泛化性能。
附图说明
[0065]
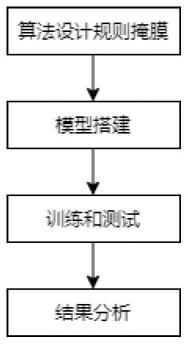
图1为本发明中基于动态时序多维自适应图卷积网络的骨架行为识别方法流程示意图;
[0066]
图2为本发明中节点划分方法示意图;
[0067]
图3为本发明中时间维度变换的工作原理示意图;
[0068]
图4为本发明中通道维度变换的工作原理示意图;
[0069]
图5为本发明中提出的多维自适应邻接矩阵的结构示意图;
[0070]
图6为本发明中动态时序卷积的工作原理示意图;
[0071]
图7为本发明中时空图卷积块的结构示意图;
[0072]
图8为本发明中动态时序多维自适应图卷积网络模型结构示意图。
具体实施方式
[0073]
如图1所示,本发明包括基于动态时序多维自适应图卷积网络的骨架行为识别方法,其包括以下步骤。
[0074]
s1:获取历史数据中的原始视频样本,对原始视频样本进行预处理,并获取原始视频样本中骨架信息数据。
[0075]
s2:将原始视频样本的骨架信息数据建模成骨架时空图。
[0076]
s3:基于获取的骨架信息数据,进行数据处理后,提取骨架行为特征数据,基于骨架行为特征数据获得多支流的训练数据,记作:多支流训练用特征数据。具体应用时,在于骨架行为特征数据提取训练用数据时,同时还需要提取测试用骨架行为特征数据。
[0077]
本实施例中,多支流训练用特征数据包括:节点信息joint、骨骼信息bone、节点运动信息joint_motion、骨骼运动信息bone_motion。
[0078]
具体的基于骨架信息数据,提取骨架行为特征数据,对骨架行为特征数据进行建模的方法,包括以下步骤:
[0079]
s3-1:以节点自身建模作为关节信息,假设t帧的节点信息joint表示为jt;
[0080]
s3-2:以靠近骨骼重心的节点为源节点以远离骨骼重心的节点为目标节点骨骼信息bone表示源节点指向目标节点的向量由于节点数比骨骼数多1,将中心节点设置为空骨骼即值为0,方便简化网络设计,保持特征维度不变;
[0081]
s3-3:节点运动信息和骨骼运动信息以各自相邻两帧之间的坐标差表示,因此节点运动信息joint_motion计算公式为骨骼运动信息bone_motion的计算公式为由于时间帧数比运动信息多1,将最后一帧的值设为0,方便简化网络设计,保持特征维度不变。
[0082]
s4:基于自适应图卷积方法和动态卷积,构建动态时序多维自适应图卷积网络模型,作为骨架行为识别模型;骨架行为识别模型包括:骨架行为识别支流模型。
[0083]
具体的构建动态时序多维自适应图卷积网络模型,包括以下步骤。
[0084]
s4-1:将骨架时空图中每一个节点的邻域进行子集划分,得到骨架时空图对应的骨架节点子集;骨架节点子集包括:节点自身子集、向心邻居节点子集、离心邻居节点子集;
[0085]
节点自身子集中包括节点自身;
[0086]
向心邻居节点子集中包括:靠近骨架重心的向心邻居节点;
[0087]
离心邻居节点子集中包括:远离骨架重心的离心邻居节点;
[0088]
如图2所示,图2为骨架时空图中的节点划分方法,每个小圆表示一个骨架节点;
[0089]
设g为重心节点,以节点b为例,其邻域包括a、b、c三个节点;其中b表示节点自身,a表示靠近骨架重心的近心邻居节点,c表示远离骨架重心的离心邻居节点。
[0090]
s4-2:基于骨架时空图,构建多维度自适应图,多维度自适应图包括:空间自适应图、时间自适应图和通道自适应图;
[0091]
空间自适应图为基于骨架时空图提取的空间图;
[0092]
时间自适应图为基于骨架时空图提取的时间图经过维度变换后生成;
[0093]
通道自适应图为基于骨架时空图提取的通道图经过维度变换后生成;
[0094]
将多维度自适应图和初始邻接矩阵及掩码矩阵相结合得到多维自适应邻接矩阵,将多维自适应邻接矩阵进行图卷积,并与骨架节点子集一起构建空间图卷积层,记作:多维自适应图卷积模块。
[0095]
本发明技术方案中,在获得空间自适应图的同时,通过非局部网络和维度变换,获取时间自适应图和通道自适应图,并相结合获得了多维自适应图卷积模块,增强了图卷积网络中空间、时间和通道多维度关联人体骨架信息特征的提取,进一步提高了图卷积网络骨架行为识别的准确率。
[0096]
具体应用时,构造多维自适应图卷积模块的步骤包括:
[0097]
s4201:定义节点、时间帧和通道为各自维度的维度节点,使用归一化的嵌入高斯函数来计算两个维度节点vi和vi的相似度f(vi,vi):
[0098][0099]
其中:n为维度节点的个数,θ(vi)、φ(vj)选用两个并行的1
×
1卷积运算,作为维度节点i和维度节点j的嵌入函数;
[0100]
s4202:结合softmax函数计算空间图sk、时间图tk、通道图ck,计算公式分别为:
[0101][0102][0103][0104]
式中f
in
代表输入的骨架行为特征数据,w
θ
、w
φ
分别表示嵌入高斯函数θ和φ;
[0105]
其中空间图sk∈rv×v即空间自适应图,对时间图tk∈r
t
×
t
和通道图进行维度变换,生成时间自适应图和通道自适应图
[0106]
如图3所示为时间维度变换模块的工作原理,将时间图tk∈r
t
×
t
作为输入,通过unsqueeze函数增加维度,使用permute函数进行维度转换((0,1,2,3)
→
(0,2,1,3)),然后进行卷积运算(convt1),将通道数t变为1,再次利用permute函数进行维度转换((0,1,2,3)
→
(0,3,1,3)),接着进行批归一化处理(bn_t),进行第二次卷积运算(convt2),将通道数t变为v
×
v,通过view函数进行重构(reshape),最后通过softmax函数计算,得到时间自适应图;
[0107]
如图4所示为通道维度变换模块的工作原理,将通道图作为输入,通过unsqueeze函数增加维度,使用permute函数进行维度转换((0,1,2,3)
→
(0,2,1,3)),然后进行卷积运算(convc1),将通道数ce变为1,再次利用permute函数进行维度转换((0,1,2,3)
→
(0,3,1,2)),接着进行批归一化处理(bn_t),进行第二次卷积运算(convc2),将通道数ce变为v
×
v,通过view函数进行重构(reshape),最后通过softmax函数计算,得到通道自适应图;
[0108]
s4203:结合各维度自适应图和初始邻接矩阵生成多维自适应邻接矩阵,进行图卷积操作:
[0109][0110]
其中,分别为输入特征和多维自适应图卷积的输出,c
in
表示输入通道,c
out
表示输出通道,wk为卷积核函数,kv代表预定义的最大距离;根据节点划分策略设置kv的值,即:骨架节点子集中包括3个节点子集,则kv设置为3;
[0111]ak
是初始邻接矩阵,bk是一种增强数据掩码矩阵,sk、分别是通过非局部网络生成的空间自适应图、时间自适应图和通道自适应图。
[0112]
如图5所示,为本发明技术方案中的多维自适应邻接矩阵,即图5中的输入f
in
表示骨架行为特征数据,尺寸为n
×c×
t
×
v,分别代表批次尺寸、通道数、帧数和关节数;θk(x)和φk(x)数代表非局部网络的高斯嵌入函数,用于计算各节点、各时间帧和各通道间的相似度,获得空间图、时间图和通道图,进一步通过时间维度变换模块(图中标记为:t2v dimension-change module)或者通道维度变换模块(图中标记为:c2v dimension-change module),将时间图和通道图转换为时间自适应图和通道自适应图本发明中的多维自适应邻接矩阵增强了对人体骨架信息在空间、时间和通道维度的特征的提取能力,更能表达节点间、帧间和通道间的连接关系和各维度之间的关联性,从而在图卷积过程中更能挖掘人体骨架的多维度结构特征,提高模型的识别准确率。
[0113]
s4-3:基于骨架时空图,引入对二维卷积权重和偏置的注意力机制,构造9
×
1的动态时序卷积提取骨架时空图的时间特征,构建时序图卷积层,记作:动态时序卷积模块。
[0114]
具体的构造动态时序卷积模块的步骤包括:
[0115]
s4301:挤压阶段;
[0116]
通过全局平均池化将特征的维度压缩到通道所表示的维度;挤压过程表示为:
[0117][0118]
式中,t代表帧数,v代表节点数,i和j表示时域中第i帧和空域第j个节点,x为输入的特征,z为通道挤压后的特征图;
[0119]
s4302:激励阶段;
[0120]
通过两次全连接计算后,经过softmax函数激活和温度系数得到权值,计算公式为:
[0121]
z=w2δ(w1z)
[0122][0123]
其中,δ代表relu激活函数,σ代表softmax激活函数,w1、w2分别表示两次全连接的权重参数,z表示通道挤压后的特征图,z表示第二层全连接的输出,τ表示温度系数;k表示参与聚合的卷积核个数,πk为第k个卷积核对应的注意力权值,zk为第k个卷积核在z中对应的值,zj为第j个卷积核在z中对应的值;
[0124]
s4303:根据se模块得到的权重和偏置的注意力,计算动态卷积核中的权重和偏置:
[0125][0126][0127]
式中,k为卷积核个数,wk为第k个卷积核的权重,πk为第k个卷积核的注意力权值,w为动态卷积核权重,bk为第k个卷积核的偏置,b为动态卷积核的偏置;
[0128]
s4304:构造9
×
1的动态卷积层对多维自适应图卷积层的输出进行卷积操作,计算公式为:
[0129]
y=δ(wf
out
b)
[0130]
式中,y为动态卷积后的输出,f
out
为多维图卷积层的输出,δ为relu激活函数。
[0131]
如图6所示为动态时序卷积的工作过程的实施例,输入的f
in
为动态时序卷积层的输入特征,图中虚线框中为注意力机制模块,包括:依次连接的avg pool、fc、relu、fc和softmax,f
in
通过注意力机制模块处理后得到注意力权值π1~π4,将π1~π4与卷积核covn1~covn4相结合,聚合计算得到动态卷积核conv参与卷积运算,f
in
依次送入conv、bn、relu处理后得到输出f
out
。
[0132]
s4-4:将多维自适应图卷积模块和动态时序卷积模块相结合,构建动态时序多维自适应图卷积块;
[0133]
动态时序多维自适应图卷积块包括:依次连接的多维自适应图卷积层、bn层、relu和动态时序卷积层。
[0134]
如图7所示,所述动态时序多维自适应图卷积块包括:依次连接的多维自适应图卷积模块(图中标记为:md-agcn)、bn层、relu层和动态时序卷积模块(图中标记为dytcn);
[0135]
骨架特征经过多维自适应图卷积模块,提取空间多维特征,再通过relu激活函数激活和batchnorm2d函数进行批归一化,然后输入进动态时序卷积模块,通过聚合了四个卷积核的动态卷积层,获得时序表示能力更强的时序特征;
[0136]
最后,利用动态卷积构造res选择性卷积,并将其与上述步骤的输出相加,构建残差模型。残差连接可增强模型的灵活性,而不会降低原始性能。
[0137]
s4-5:构建骨架行为识别模型;
[0138]
骨架行为识别模型包括:依次连接的bn层、10个动态时序多维自适应图卷积块、gap层和softmax层。如图8所示,每个图卷积块上的三个数字分别表示输入通道、输出通道
和步长。
[0139]
s5:设置并调整骨架行为识别模型的超参数,使用多支流训练用特征数据,对骨架行为识别模型中的每一个骨架行为识别支流模型进行训练,获得训练好的骨架行为识别支流模型。
[0140]
具体实现时,基于多支流网络的训练方式,分别使用分支训练数据训练动态时序多维自适应图卷积网络模型时,采用随机梯度下降法作为优化策略,选择交叉熵函数作为梯度反向传播的损失函数。
[0141]
s6:获取待识别视频数据,提取待识别视频数据组中的骨架信息数据,基于骨架信息数据提取待识别骨架时空图,将待识别骨架时空图并分别输入到每一个训练好的人体骨架行为识别支流模型中,将各支流模型的输出进行融合,得到最终的骨架行为识别结果。
[0142]
模型训练具体实施时,基于pytorch深度学习框架下进行的。优化策略采用随机梯度下降(stochastic gradient descent,sgd),nesterov动量设为0.9,迭代周期设为50,初始学习率设置为0.1,为克服训练时过拟合的问题,选择交叉熵作为损失函数并将权重衰减设置为0.0001,衰减周期设在第30和40个周期,batch size设为32。
[0143]
选择交叉熵作为梯度反向传播的损失函数:
[0144][0145]
其中,i代表第i个样本,c代表类别,p
ic
表示对于第i个样本属于类别c的预测概率,y
ic
表示指示变量(0或1),如果该行为类别和训练集中样本i(即每一帧骨架序列)的类别相同就是1,否则是0;m表示行为类别的数量。
[0146]
表1为动态时序多维自适应图卷积网络模型结构的实施例,基于下面表1中的网络结构,将输入的数据,经过10个子网络结构块的处理之后,进入gap层,在gap层中将子网络结构块输出的3维数据转换成1维数据,然后通过fc层将数据从480000降低维度到60(120)维,最后映射到60(120)维后进行预测。
[0147]
表1:动态时序多维自适应图卷积网络模型的结构
[0148]
模型层输入和输出通道数步长(stride)输出数据尺寸输入
ꢀꢀ
[3,300,25]1
st
in_channels=3,out_channels=641[64,300,25]2
nd
in_channels=64,out_channels=641[64,300,25]3
rd
in_channels=64,out_channels=641[64,300,25]4
th
in_channels=64,out_channels=64l[64,300,25]5
th
in_channels=64,out_channels=1282[128,150,25]6
th
in_channels=128,out_channels=1281[128,150,25]7
th
in_channels=128,out_channels=1281[128,150,25]8
th
in_channels=128 out_channels=2562[256,75,25]9
th
in_channels=256,out_channels=2561[256,75,25]10
th
in_channels=256,out_channels=2561[256,75,25]gap
ꢀꢀ
[480000]fc[480000,60]或[480000,120] [60]或[120]
[0149]
为了验证本发明技术方案中的人体行为识别方法的有效性和实用性,选取ntu-rgb d与ntu-rgb d120数据集作为实验数据集进行实验。
[0150]
ntu-rgb d用3个microsoft kinect v2传感器采集,这三个传感器分别放置的角度是-45
°
,0
°
,45
°
,一共包含60类动作。其中第1-49个动作是单人动作,第50-60个动作是双人交互动作。ntu-rgb d数据集有两种评价方式:交叉对象(x-sub)和交叉视角(x-view)。测试结果如表2所示。
[0151]
表2:ntu-rgb d数据集中x-view和x-sub下的识别准确率(%)
[0152]
情景jointbonejoint-motionbone-motionjoint bonedtmda-gcnx-view94.894.893.192.996.196.5x-sub87.888.585.985.989.990.4
[0153]
表2中,joint、bone、joint-motion、bone-motion、joint bone分别表示关节、骨骼、关节运动、骨骼运动、关节和骨骼特征;dtmda-gcn表示本发明技术方中的基于动态时序多维自适应图卷积网络模型构建的骨架行为识别模型,对应的准确率为将四支流输出进行融合,得到最终的骨架行为识别结果。因为本实验是基于数据集验证模型的准确率,所以四个支流的输出结果定义为准确率,实际应用本发明技术方案进行骨架行为识别时根据具体的需求,定义四个支流的输出结果,如:将输出结果定义为骨架行为的概率。
[0154]
同时,基于ntu-rgb d数据集,将本发明技术方案中的基于动态时序多维自适应图卷积网络模型与其他的骨架行为识别模型进行对比,对比结果如下面表3所示:
[0155]
表3:基于ntu-rgb d数据集,不同模型的识别准确率对比(%)
[0156]
模型x-subx-viewsta-lstm73.481.2va-lstm79.287.7tcn74.383.1clipcnn mtln79.684.8as-gcn86.894.2st-gcn81.588.32s-agcn88.595.1ms-aagcn90.096.2dtmda-gcn90.496.5
[0157]
从表3中的数据可以看出:在以x-view与x-sub两种方式划分的ntu数据集上,本发明技术方案均取得最高的识别准确率,分别为96.5%与90.4%,本发明技术方案能够提高骨架行为的识别准确率。
[0158]
ntu-rgb d120相比于ntu-rgb d数据集,有更多的样本由更多主体在更多不同的摄像机视图中执行。该数据集包含120个动作,由106个不同的主体执行。ntu-rgb d120数据集提供了两个基准来评估,即交叉对象(x-sub)和交叉设置(x-set)。基于ntu-rgb d120数据集,将本发明技术方案中的基于动态时序多维自适应图卷积网络模型与其他的骨架行为识别模型进行对比,对比结果如表4所示。
[0159]
表4:基于ntu-rgb d120数据集,不同模型的识别准确率对比(%)
[0160]
模型x-subx-setupsoft rnn36.344.9dynamic skeleton50.854.7spatio-temporal lstm55.757.9gca-lstm58.359.2sgn79.281.5skelemotion67.766.92s-agcn82.984.94s shift-gcn85.987.6dtmda-gcn(joint)81.283.9dtmda-gcn(bone)83.485.6dtmda-gcn(joint bone)85.487.4dtmda-gcn86.588.2
[0161]
从表4中的数据可以看出,在以x-sub与x-setup两种方式划分的ntu-rgb d120数据集上,我们的发明技术方案取得最高的识别准确率,分别为86.5%与88.2%,进一步验证了模型良好的识别准确率,并且本发明的基于ntu-rgb d数据集和ntu-rgb d120数据集都能取得良好的识别准确率,可知本技术中的骨架行为识别模型具备良好的泛化性能。
[0162]
本发明提供一种基于动态时序多维自适应图卷积网络的骨架行为识别方法,在针对骨架时空图进行建模时,同时考虑了空间、时间和通道三个维度之间的关联性,其不仅能够实现对骨架信息在空间、时间和通道维度上的特征提取和融合,还能增强时间特征的表示能力;同时,在大型骨架数据集上取得优异的识别准确率,并具备有良好的泛化性能。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。