基于textrank与注意力机制的长文本分类方法
技术领域
1.本发明属于长文本特征提取技术领域,特别涉及基于textrank与注意力机制的长文本分类方法。
背景技术:
2.文本分类任务可按照文本长度,分为短文本分类与长文本分类。而长文本分类任务相较于短文本分类,难点在于对较长序列的特征信息提取与重点内容划分。现有的文本分类方法没有很好地针对长文本做一些方法上的改进,在应用时没有充分考虑长文本与短文本的不同,这样会导致分类模型在长文本语境与短文本语境上的性能存在差异。
3.如文献提出一种多尺度卷积注意力结合gru(gated recurrent unit)的分类方法,虽然该分类方法取得了不错的分类性能,但是其实验所应用的数据集都是短文本数据集,最长数据集的平均文本长度也仅为45。文献采用sru(simple recurrent unit)和attention的方式提取特征信息,普通的attention没法充分地提取长文本中的关键特征信息。
技术实现要素:
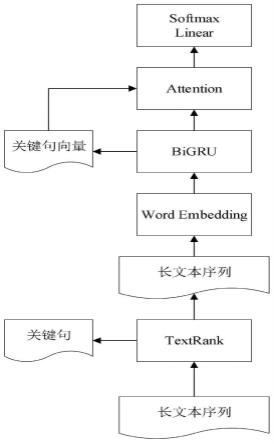
4.为了克服以上技术问题,本发明的目的在于提供基于textrank与注意力机制的长文本分类方法,该方法适用于长文本的主题分类与情感分析,对于较长的文本会根据文中词语的重要程度裁剪文本,提高了每段文本的质量。其次,该方法会提取当前文本的关键句作为注意力机制的查询向量,根据关键句向量计算文本的注意力得分,使模型更关注与关键句语义相近的部分。
5.为了实现上述目的,本发明采用的技术方案是:
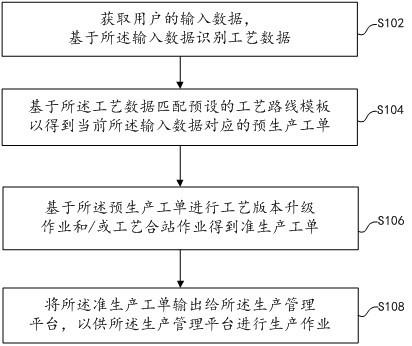
6.基于textrank与注意力机制的长文本分类方法,包括以下步骤;
7.step1:将长文本序列输入textrank层计算出长文本的关键句序列与关键词序列,关键句序列与关键词序列按照权重排序,权重越接近1,则越重要,选出关键句序列中权重最接近1的句子作为该文本的关键句,对长文本序列进行数据预处理操作,按照设置好的样本统一长度裁剪或填充每条文本,对于较长的文本将其权重较低的关键词裁剪掉,对于较短的文本在其尾部填充上权重较高的关键词;
8.step2:将经过textrank层处理后的文本序列输入word embedding层生成词向量表示;
9.step3:将长文本向量输入bigru层中,bigru将结合文本的上下文提取其特征信息;
10.step4:结合文本的关键句对文本向量进行注意力计算,得出文本向量里对应关键句的注意力分数,根据注意力分数更新文本特征向量;
11.step5:将更新后的文本特征向量输入到linear与softmax层得出分类结果。
12.所述textrank是利用图网络生成各词的带权图节点,若两词存在一个共现窗口
中,则在两词节点之间建立边,在训练中不断迭代更新各节点的权值,各节点权值的更新公式如下:
[0013][0014]
其中,ws{vi}、ws{vj}代表i词与j词的权重值;vi、vj代表i词与j词在图中的节点;invi、outvj分别代表vi的入度集合与vj的出度集合;d为阻尼系数,通常设置为0.85,说明该点指向另一个节点的概率为85%。
[0015]
所述textrank的关键句序列是以句子间相似度为依据,通过构造句子级别的有权图,更新句子节点之间的相似度权重,再根据各句子的相似度分数排列成关键句序列,各句子节点之间的相似度计算公式如下:
[0016][0017]
其中si、sj为两句子节点,wk为两句子间的单词,整个公式(2)就是在计算两句子间的内容重复度。
[0018]
所述textrank层的处理步骤如下:
[0019]
step1:首先要进行的是数据预处理操作,将长文本序列输入textrank层中,通过停用词表分词并过滤掉无关词;
[0020]
step2:根据式(1)更新各词节点的权重,根据权重值将各词排序成关键词序列,根据长文本中任意表示句子结束的标点符号分句,通过式(2)计算出关键句;
[0021]
step3:根据设置好的文本统一长度,对于较长文本删除其中的较不重要关键词,对于较短文本在其尾部添加较重要关键词,以这种方法保证各样本长度相同,同时也保留了较长样本的重要内容,加强了较短样本的特征信息;
[0022]
step4:将关键句序列中权值最高的句子作为当前样本的关键句,将处理好的文本输入下一层;
[0023]
所述bigru层的作用是提取输入文本的特征信息,通过前向gru层与反向gru层充分考虑文本的上下文关系;
[0024]
gru网络的核心公式如下:
[0025]zt
=σ(wz·
[h
t-1
,x
t
])
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ⑶
[0026]rt
=σ(wr·
[h
t-1
,x
t
])
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ⑷
[0027][0028][0029]
其中,式(3)(4)为更新门和重置门的计算公式,由h
t-1
与当前输入x
t
计算得出,σ为sigmoid函数;公式(5)为当前时刻候选记忆单元的计算公式,由重置门筛选出h
t-1
中要留下的信息结合x
t
构成公式(6)为当前时刻h
t
的计算公式,z
t
决定丢弃多少h
t-1
中的信息,决定留下多少中的信息。
[0030]
所述bigru是双向的gru,将文本序列正向输入gru得出正向特征,将文本序列反向输入gru得出反向特征,结合正向特征与反向特征作为文本序列的整体上下文特征;
[0031]
将正向输出与反向输出想加作为长文本的内容向量h,公式如下:
[0032][0033]
将关键句输入bigru中,将所有隐藏层的最后时间步输出想加作为关键句的总结向量,公式如下:
[0034][0035]
其中num_layers为隐藏层层数,hi为第i层的最后时间步输出,将k
sen
与h一起输入attention层。
[0036]
所述attention层根据长文本中内容的重要程度为其分配权重值,将关键句与注意力机制相结合;
[0037]
将关键句向量k
sen
作为注意力机制的query,将长文本内容向量h作为注意力机制的key与value,计算公式如下:
[0038][0039]
其中d为收敛因子,通常为词向量维度,q与k
t
相乘得出文本向量相对于关键句的分数矩阵,除以收敛因子后通过softmax函数归一化得到文本向量权重矩阵,通过权重矩阵更新文本向量v得到向量c,将向量c输入最后一层得出分类结果。
[0040]
本发明的有益效果。
[0041]
本发明给现有的文本分类方法提供了新思路,设计了一款适用于长文本的主题分类模型。提出了基于textrank的文本预处理方法,以及基于关键句的注意力计算方法,提升了长文本分类任务的准确率。对于日常生活中的长篇文章与新闻的主题分类、社交平台长评情感分类提供了一种现实可行的解决方案。
附图说明:
[0042]
图1为本发明的长文本分类方法。
[0043]
图2为gru网络结构示意图。
[0044]
图3为bigru网络结构示意图。
具体实施方式
[0045]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0046]
实施例:
[0047]
步骤一:输入一段长文本,长文本如下:
[0048]
长文本标签this movie is very good.i like it very much.the hero in...positive
[0049]
结合textrank算法挑选出长文本中的关键词,关键词序列如下[movie,like,good,hero,...],若文本长度为480,文本统一长度为500,则需要从关键词序列中挑选出最重要的20个关键词填充到该长文本的末尾。
[0050]
步骤二:将经过textrank处理后的长文本输入glove模型生成向量表示,该长文本的向量形状为[1,500,100],其中1为文本数量,500为文本的长度,100为词向量的大小。
[0051]
步骤三:将该长文本向量输入bigru模型,根据上下文语义提取长文本的特征信息。
[0052]
将第一个时间步的输出与最后一个时间步的输出拼接,作为当前长文本的总结向量,输入到注意力层。
[0053]
步骤四:注意力层将“positive”作为查询向量query,将当前长文本作为待查向量key,通过点积注意力计算方式,给长文本的各个单词分配注意力权重。计算公式如下:
[0054][0055]
其中v
positive
为“positive”的词向量表示,k
t
为矩阵转置后的k向量,d为词向量的维度,用于缩放点积后的值,softmax为归一化函数。
[0056]
步骤五:将当前长文本的向量c属于到linear层与softmax层得出分类结果。
[0057]
实验选用两个长文本数据集:imdb、yelp。imdb和yelp为都为二分类数据集。过滤掉imdb数据集中长度小于400的样本,过滤后的imdb数据集中共有3370条样本作为训练集,3147条样本作为测试集。过滤掉yelp中长度小于400的样本,其中训练集设置为20000条,测试集设置为5000条。
[0058]
其中imdb数据集的平均样本长度为590,yelp数据集中平均样本长度为545。设置各数据集信息如下表所示:
[0059]
表1数据集信息
[0060][0061]
实验参数设置
[0062]
本文实验采用对比实验法,选用的对比模型为lstm、gru、bi gru、bilstm、textcnn、bigru-att、cnn-bigru、textrank-bi gru-att。本文所有模型的词嵌入模型都为glove(global vectors)模型,优化函数为adam,词向量维度为100。学习率为1e-4,在imd b与yelp数据集上的批量大小分别为128和64,隐藏层个数为100,训练迭代次数为10,cnn的卷积核大小为[3,4,5],通道数为100。
[0063]
4.3实验评价指标
[0064]
本实验采用的评价指标为精确率、召回率、f1值,计算公式如下:
[0065][0066]
[0067][0068]
其中tp为正类中预测为正类的数量;fp为吧负类预测为正类的数量;fn为把正类预测为负类的数量。
[0069]
实验结果及分析
[0070]
各模型在imdb、yelp数据集的实验结果如下表所示:
[0071]
表2 imdb数据集各模型实验结果(%)
[0072][0073][0074]
表3 yelp数据集各模型实验结果(%)
[0075][0076]
如表2所示,本文方法在imdb数据集上的精确率为74.52%、召回率为80.06%、f1为77.44%。如表3所示,本文方法在yelp数据集上的精确率为87.01%、召回率为87.64%、f1值为87.32%。本文方法在两长文本数据集上的实验结果都优于对比模型,其中f1值比textrank-bigru-att模型高3.03%、8.13%,说明本文结合了关键句来做长文本的注意力计算能加强模型的特征提取能力,能凸显长文本的中的重要特征信息。当文本较长时,普通的注意力机制只能找出相对于长文本内部来说比较重要的内容,这样的特征提取方式范围太广,没有针对性。而长文本的关键句一般蕴含着文本的主题思想,用主题思想去做注意力计算能加强特征提取的针对性,使内容上更贴近关键句的部分获得更高的权重。将textrank-bigru-att对比bigru-att模型,f1值高出0.17%、2.33%,证明了基于textrank的数据预处理,在保证样本长度一致的同时也能充分保留较长文本的重要信息,增强较短文本的特征信息。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。