1.本发明涉及生物技术领域,尤其涉及一种用于筛选早期胃肿瘤高危患者的预测预警检测蛋白芯片的方法及应用。
背景技术:
2.胃病的种类很多,包括:慢性肠炎、结肠炎、慢性胃炎(浅表性、糜烂性、萎缩性、反流性)、胃窦炎、胃溃疡、胃出血、胃穿孔、十二指肠溃疡、胃癌等。一般的检查有13c 呼气试验(是检测幽门螺杆菌hp的金标准)、血清抗hp抗体测定、x线检查、消化内镜检查、胶囊内镜检查、胃液分析、胃电图、胃功能三项等。针对胃癌的筛查,目前最有效的方法是胃肠镜检查。
3.早期胃癌一般无明显症状,到了进展期,才会一定程度出现某些症状,如:上腹部疼痛、腹胀、食欲不振、消瘦、恶心呕吐、下咽困难等,但上述症状均不典型,并非胃癌特有,也见于慢性胃炎、胃溃疡、功能性消化不良、胃食管反流病等良性病变。在原有胃病基础上发生癌变时,其症状已长期存在,更易引起忽视,而没有及时就诊。
4.标志物检测由于具有侵入性小易于检测等优点成为当前研究的热点,目前临床所用的标志物cea、ca199和ca724敏感性特异性较差,ca724阳性率只有47.7%,cea为25%,ca19-9为25%,目前还缺乏有效的筛选早期胃癌的方法。
5.近年来,蛋白质组学研究在技术上取得了巨大的进展,越来越多蛋白质组学研究新技术的出现,新的研究策略不断涌现,针对不同的研究样本、不同的研究目的,各个蛋白质组学研究手段各有优势;利用蛋白质组学研究策略能高通量地、动态地对比分析健康和疾病不同状态下蛋白表达谱的改变,可有效地应用于肿瘤标志物的筛选、鉴定,肿瘤分类,肿瘤治疗效果的评价及肿瘤发生机制等方面的研究,使得肿瘤的诊断、分类、疗效评价由过去应用单一的肿瘤标志物进行判断发展成为现在的应用蛋白谱或基因表达谱的改变来进行综合判断。从血清中寻找能用于胃癌早期诊断的敏感性和特异性高的肿瘤标志物已是亟待解决的问题。
技术实现要素:
6.本发明的目的在于为了解决目前早期胃肿瘤高危患者的预测预警检测标志物缺乏,而提供一种用胃癌早期筛查的蛋白芯片。
7.进一步本发明还提供了该蛋白芯片的制作方法。
8.进一步本发明还提供了该蛋白芯片的应用。
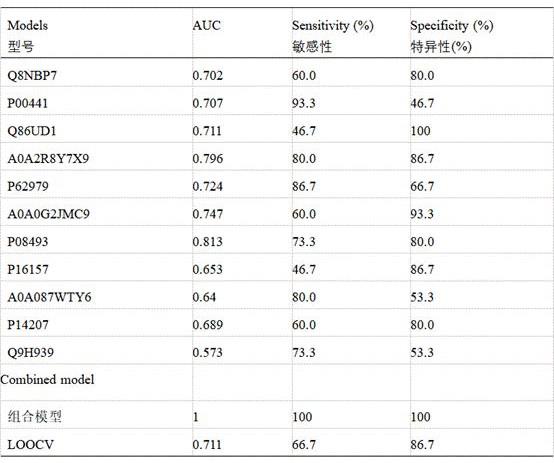
9.为了实现上述目的,本发明采用以下技术方案:一种用于胃癌早期筛查的蛋白芯片,包括固相载体和阵列式分布于固相载体上的差异蛋白抗体,所述差异蛋白抗体包括:q8nbp7、p00441、q86ud1、a0a2r8y7x9、p62979、a0a0g2jmc9、p08493、p16157、a0a087wty6、p14207、q9h939。
10.进一步的差异蛋白筛选过程为:建立正常、癌前病变、早期及进展期的发展过程中
若干人的蛋白质组学4个对照组,使用液相色谱-串联质谱(lc-ms / ms)结合串联质量标签(tmt)标签来比较患者和健康志愿者的血浆蛋白质组,对照uniprot human数据库搜索生成的ms/ ms质谱,使用r软件(www.r-project.org)进行数据分析。通过学习t检验在原始p值截止值为0.05的情况下,鉴定了不典型增生或低、高级别上皮内瘤组,早期胃癌组,进展期胃癌组和健康对照组之间差异表达的蛋白质。
11.进一步的差异蛋白验证过程为:构建包含差异表达蛋白质的逻辑回归模型以区分病例和对照。使用r包metaboanalystr和ropls构建opls-da模型。r2y和q2y指标用于评估模型的性能。投影重要性(vip)分数的可变性既反映了每个组件的负载权重,又反映了其所解释的响应的可变性,因此可用于特征选择。为了进一步选择egc的潜在生物标记,使用了监督的多元技术opls-da。各组与对照组明显分开,表明血浆蛋白质组学发现的潜在效率。然后,我们采用称为vip评分的统计数据来选择生物标记。使用vip》 2的临界值,并选择了43种蛋白质。这些生物标记物的kegg通路分析揭示了丰富的术语,包括卟啉和叶绿素代谢以及氮代谢。使用lc-ms / ms与tmt标记相结合,我们从各组患者和健康对照人群中鉴定了90种的胃癌肿瘤直接相关标志物(图1)和11种差异表达最大蛋白质:q8nbp7、p00441、q86ud1、a0a2r8y7x9、p62979、a0a0g2jmc9、p08493、p16157、a0a087wty6、p14207、q9h939。
12.进一步的,所述蛋白芯片还包括阳性对照和阴性对照。
13.进一步的,所述固相载体为玻璃载片、滴定板或滤膜。
14.进一步的,所述蛋白芯片是分别将差异蛋白抗体、阳性对照和阴性对照利用点制基因微阵列商品化点样仪或喷膜法点制到固相载体上。
15.进一步的,所述差异蛋白抗体、阳性对照和阴性对照点样3-5个重复。
16.一种用于胃癌早期筛查的蛋白芯片的制作方法,所述制作方法包括以下步骤:1)固相载体及其处理:使用琼脂糖膜处理固相载体,所述固相载体上设置有阴性控制孔与阳性控制孔;2)蛋白质预处理:将差异蛋白抗体溶解;3)点制微阵列:将步骤2)得到的差异蛋白抗体、阳性对照和阴性对照利用点制基因微阵列商品化点样仪或喷膜法点制到固相载体上,每个差异蛋白抗体、阳性对照和阴性对照点样3-5个重复;4)固定微阵列:使用链霉亲和素于步骤3)得到的固相载体上;5)封闭微阵列:待差异蛋白抗体微阵列固定后,使用bsa或者甘油进行芯片封闭,静置后得到蛋白芯片。
17.进一步的,所述差异蛋白抗体包括:q8nbp7、p00441、q86ud1、a0a2r8y7x9、p62979、a0a0g2jmc9、p08493、p16157、a0a087wty6、p14207、q9h939。
18.进一步的一种用于胃癌早期筛查的蛋白芯片的应用,获取样本后,将样本用生物素标记,与包含上述包含q8nbp7、p00441、q86ud1、a0a2r8y7x9、p62979、a0a0g2jmc9、p08493、p16157、a0a087wty6、p14207、q9h939差异蛋白的蛋白芯片共孵育,经过化学耦合后,再加入目标蛋白的生物素标记抗体;反应结束后,结合荧光和比色扫描,检测hrp-链霉亲和素或荧光素-链霉亲和素芯片信号,结合系统软件,将数据进行图像量化,标准化,并建立一定计算模型,执行数据分析和建模;采用spss 22.0统计软件进行统计分析,计量资料采用均数
±
标准差表示,并采用独立样本t检验进行统计分析,计数资料采用卡方检验。以p《0.05为差异有统计学意义,差异标准:auc》0.7。
19.本发明的有益效果是:本发明液相色谱-串联质谱(lc-ms / ms)结合串联质量标签(tmt)标签来比较患者和健康志愿者的血浆蛋白质组。运用logistic回归模型和正交信号校正-偏最小二乘判别分析(opls-da)模型,最终根据各组之间蛋白组学分析结果,进一步建立胃癌诊断模型,找出差异蛋白,制作蛋白芯片;该芯片将能精准预测个体发生胃癌的概率以及分期,应用于胃癌的早期筛查,可实现胃癌预警准确率66%以上,对晚期病情可达86%左右。本发明可对高风险人群实现快速检测,可有效提高胃癌早期发现率与生存率。
20.本发明1)所需样本量极少(10-100微升);2)有高的信噪比,高准确性、灵敏性(单克隆抗体);3)快速、微型化和自动化(3小时内);4)可通过标准曲线进行定量检测;因此,本发明研发的产品将大大提高临床诊断胃癌早期患者的准确率及效率,具有很强的应用创新性及十分重要的临床研究意义。
附图说明
21.图1:筛选的胃癌肿瘤直接相关标志物
具体实施方式
22.下面将结合实验数据对本发明的技术方案进行清楚、完整的描述,显然,所描述的实施例是本发明的一部分实施方式,而不是全部的实施方式。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施方式,都属于本发
明保护的范围。
23.除非另行定义,文中所使用的所有专业与科学用语与本领域熟练人员所熟悉的意义相同。此外,任何与所记载内容相似或均等的方法及材料皆可应用于本发明中。文中所述的较佳实施方法与材料仅作示范之用。
24.差异蛋白筛选(1)血样采集在xx三甲医院根据胃镜检查及活检病理金标准选取癌前病变、胃癌早期、进展期、健康的患者175例(不典型增生或低、高级别上皮内瘤变30例,早期胃癌30例;进展期胃癌30例,健康受试者85例),该研究得到xx医院伦理委员会的批准,所有参与者签署知情同意书后,按照实验室标准,留取血液标本。
25.(2)定量检测在实验室使用液相色谱-串联质谱(lc-ms/ms)结合串联质量标签(tmt)标签开展定量检验。
26.使用easy-nlc1000系统(thermofisherscientific,waltham,ma,usa),以0.250
µ
l/min的流速通过120分钟的梯度洗脱,以120分钟的梯度洗脱分离tmt标记的肽,该系统直接与q-exacitvehf-x光谱仪(thermofisherscientific,美国马萨诸塞州沃尔瑟姆)。分析柱为熔融石英毛细管柱(内径75
µ
m,长150mm;填充有c-18树脂,美国马萨诸塞州列克星敦)。流动相a由0.1%甲酸组成,流动相b由100%乙腈和0.1%甲酸组成。对于定量蛋白质组学分析,使用xcalibur3.0.63软件(thermofisherscientific,沃尔瑟姆,马萨诸塞州,美国)以依赖数据的采集模式操作q-exacitvehf-x光谱仪,并且只有一个完整的扫描质量自动增益控制(agc)目标值为2e6时,在orbitrap(350-1550m/z,120,000分辨率)中获得最大频谱。进行了数据依赖的采集方法,以17500的分辨率收集生成的ms/ms质谱图,agc目标为1e6,在每个质谱图中观察到的前40个离子的最大注入时间(it)为50ms。隔离窗口设置为1.2da宽度,动态排除时间为20s,碰撞能量设置为38%。
27.对照uniprothuman数据库搜索生成的ms/ms质谱(https://www.uniprot.org;august10,2016;89,105sequences),使用proteomediscoverer2.1软件中的sequest搜索引擎(pd,thermofisherscientific,美国马萨诸塞州沃尔瑟姆)。搜索标准如下:需要完全的胰蛋白酶特异性;允许进行一次错位切割;设置了氨基甲酰甲基化(c)和tmt六链体(k和n端)作为固定修饰;氧化(m)被设定为可变修饰。对于在orbitrap质量分析仪中采集的所有ms,前体离子质量公差设置为10ppm;对于所有获得的ms2质谱图,碎片离子质量容差设置为20mmu。使用pd提供的percolator计算肽的错误发现率。当q值小于1%时,认为肽谱匹配正确。当根据反向诱饵数据库搜索时,基于肽谱匹配确定了错误发现。仅分配给给定蛋白质组的肽被认为是独特的。蛋白质发现的错误发现率也设为0.01。相对蛋白质定量是根据制造商的说明,使用pd2.1对每个肽的六个报告离子强度进行的。仅对具有两个或多个独特肽段匹配的蛋白质进行定量。蛋白质比率被计算为属于蛋白质的所有肽命中的中位数。定量精度表示为蛋白质比例变异性。
28.(3)结果分析1)鉴定差异表达的蛋白质使用r软件(www.r-project.org)进行数据分析。从分析中删除了各组中缺失值超
过50%的蛋白质。使用k最近邻法(knn)估计剩余的缺失值。然后将数据矩阵进行log2转换,以接近高斯分布。通过学习t检验在原始p值截止值为0.05的情况下,鉴定了不典型增生或低、高级别上皮内瘤组,早期胃癌组,进展期胃癌组和健康对照组之间差异表达的蛋白质。
29.2)logistic模型和交叉验证构建包含差异表达蛋白质的逻辑回归模型以区分病例和对照。构建接收器工作特性(roc)曲线以评估模型的诊断性能。使用r包proc计算roc曲线下的面积(auc),最佳截止值,灵敏度,特异性和准确性。
30.为了评估模型的预测性能,进行了留一法交叉验证(loocv)。更详细地,使用29个样本估计了逻辑模型,其余样本留作测试集。重复整个交叉验证过程30次,以覆盖所有样品,并计算平均准确度。
31.3)正交信号校正-偏最小二乘判别分析(opls-da)使用r包metaboanalystr和ropls构建opls-da模型。r2y和q2y指标用于评估模型的性能。投影重要性(vip)分数的可变性既反映了每个组件的负载权重,又反映了其所解释的响应的可变性,因此可用于特征选择。
32.(4)诊断模型组合模型的敏感性和特异性分别达到100%和100%,这表明其性能明显优于每种单独的蛋白质。但是,此结果可能来自模型的过度拟合。为了评估模型的预测性能,我们使用了loocv方法将整个数据集分为训练集和测试集。因此,loocv的敏感性和特异性分别为66.7%和86.7%。
33.为了进一步选择egc的潜在生物标记,使用了监督的多元技术opls-da。各组与对照组明显分开,表明血浆蛋白质组学发现的潜在效率。然后,我们采用称为vip评分的统计数据来选择生物标记。使用vip》2的临界值,并选择了43种蛋白质。这些生物标记物的kegg通路分析揭示了丰富的术语,包括卟啉和叶绿素代谢以及氮代谢。
34.使用lc-ms/ms与tmt标记相结合,我们从各组患者和健康对照人群中鉴定了90种的胃癌肿瘤直接相关标志物和11种差异表达最大蛋白质。
35.蛋白芯片制作:固相载体及其处理载体选择必须符合1)表面有可以进行化学反应的活性基团;2)使单位载体上结合的蛋白质分子达到最佳容量;有足够的稳定性;具有良好的生物兼容性。一般载体包括滴定板、滤膜、凝胶及载玻片,常用的则是载玻片。固相载体首先用琼脂糖膜处理。
36.蛋白质预处理选择具有高纯度和完好生物活性的候选差异蛋白抗体进行溶解。
37.点制微阵列将预处理好的候选差异蛋白抗体利用点制基因微阵列商品化点样仪或喷膜法,按照既定顺序点制到固相载体上。每个目的蛋白抗体点样3-5个重复。且需设置阴性和阳性控制孔。点间距为4.5mm,点的直径250μm阴性对照(normaligg),阳性对照(anti-rnapolymeraseii)。
38.差异蛋白抗体包括:q8nbp7、p00441、q86ud1、a0a2r8y7x9、p62979、a0a0g2jmc9、p08493、p16157、a0a087wty6、p14207、q9h939。
39.固定微阵列载玻片等固相载体需要基于化学修饰产生醛基固定蛋白,常用为:链霉亲和素。
40.封闭微阵列差异蛋白抗体微阵列固定后,用bsa或者甘油进行芯片封闭,静置后待用。
41.蛋白芯片的应用验证:随机获取正常和胃癌早期患者的血清,经生物素标记后和蛋白芯片共孵育,再加入目标蛋白的生物素标记抗体,最后,基于hrp-链霉亲和素或荧光素-链霉亲和素检测芯片信号,用于判定候选标志物表达水平样本获取、处理及分组获取正常和胃癌早期患者外周血15ml,留取10ml血液使用ficol淋巴细胞分离液分离人pbmc(注:取血后,2 h内分离最好,最长不宜超过6 h),并提取pbmc蛋白。留取5ml,37℃孵育30 min,高速离心后(1500rpm/min,15 min),收集上清液,结合白蛋白去除试剂盒(bio-rad),基于亲和树脂特异性去除血清中高丰度的白蛋白,用于后续蛋白组学检测。研究分组:1)正常组血清2)正常组外周血单核细胞3)疾病组血清4)疾病组外周血单核细胞。
42.蛋白芯片孵育获取入组群体(200例正常/200例患者)的血清和单核细胞样本,将样品用生物素标记后,与蛋白芯片共孵育;经过化学耦合后,再加入目标蛋白的生物素标记抗体,严格控制反应温度和时间;最后,终止反应并清洗蛋白芯片;荧光检测设置参数,结合荧光和比色扫描,检测hrp-链霉亲和素或荧光素-链霉亲和素芯片信号。结合系统软件,将数据进行图像量化,标准化,并建立一定计算模型,执行数据分析和建模。
43.统计分析数据采用spss 22.0统计软件进行统计分析,计量资料采用均数
±
标准差表示,并采用独立样本t检验进行统计分析,计数资料采用卡方检验。以p《0.05为差异有统计学意义。差异标准:auc》0.7。
44.以上对本发明的具体实施例进行了详细描述,但其只作为范例,本发明并不限制于以上描述的具体实施例。对于本领域技术人员而言,任何对本发明进行的等同修改和替代也都在本发明的范畴之中。因此,在不脱离本发明的精神和范围下所作的均等变换和修改,都应涵盖在本发明的范围内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。