1.本发明涉及数据处理技术领域,具体涉及一种基于大数据的同类商品选型推荐方法。
背景技术:
2.在大数据时代的网购生活中,网购用户能够选择的商品数量与日俱增,商品之间的类型关系也变得错综复杂。网购用户在通过文本描述搜索商品时,由于用户描述关键词不准确、商品推荐算法考虑不周等问题,用户在数以亿计的商品中难以搜索到自己心里描述的商品,同类商品推荐方法成为了解决这一问题的重要手段。
3.现有技术所推荐的商品虽然具有一定的命中率,即成功引导用户产生相应的购物行为的商品推送信息数量占到了商品推送信息总量的一定比例,但是存在其固有缺陷:现有技术向用户推荐的是用户已经购买过的商品的同类商品,用户很可能因为已经购买的商品而不再考虑所推荐的商品。因而现有技术在进行商品推荐时会产生大量的无效推送信息,无法实现对商品的精准推荐,而且浪费网络及计算机资源。
技术实现要素:
4.为了解决现有技术中在进行商品推荐时产生大量的无效推送信息,以及浪费网络及计算机资源的技术问题,本发明提供了一种基于大数据的同类商品选型推荐方法,该方法通过获取用户输入的每个关键词的目标分词,目标分词获取多个候选商品,进一步地,获取每个候选商品的推荐分数,并根据所述推荐分数将每个候选商品进行排列,最后将排列后的候选商品推荐给用户,提升了对用户进行商品推荐的准确性;有鉴于此,本发明通过以下技术方案予以实现。
5.一种基于大数据的同类商品选型推荐方法,包括以下步骤:获取用户在客户端搜索框输入的关键词文本,根据所述关键词文本获取每个关键词的目标分词;根据所述目标分词获取多个候选商品;根据每个关键词中目标分词对应的候选商品的数量获取每个关键词的长尾度;从多个候选商品中点击任一候选商品作为锚定商品;获取所述锚定商品与其余候选商品的相似性;根据每个候选商品的销售量获取每个候选商品的热门度;根据所述锚定商品的浏览时长,以及对所述锚定商品的处置行为获取所述锚定商品的浏览兴趣度;根据所述锚定商品与每个候选商品的相似度、每个关键词的长尾度和每个候选商品的热门度,以及所述锚定商品的浏览时长,获取每个候选商品的重要程度;根据每个候选商品的重要程度获取每个候选商品与所述锚定商品的关联性;根据每个候选商品与所述锚定商品的关联性获取每个候选商品的推荐分,根据所述推荐分对每个候选商品进行排列,并将排列后的候选商品展示在所述锚定商品所在的页面中。
6.进一步地,根据所述关键词文本获取每个关键词的目标分词的过程中,还包括获取所述关键词文本中每个关键词出现的时间点;获取每个关键词的多个分词,并根据每个关键词出现的时间点获取每两个分词之间的时间间隔,根据所述时间间隔获取每个关键词的目标分词;对每个目标分词进行商品推荐,获得多个候选商品。
7.进一步地,所述获取每个关键词的长尾度的过程为:获取每个关键词中目标分词对应的候选商品的数量;获取与每个候选商品有关联的商品数量的平均值;通过将所述平均值与所述候选商品的数量进行求差获得每个关键词的长尾度。
8.进一步地,所述候选商品的销售量包括周销售量、月销售量和年销售量。
9.进一步地,所述获取候选商品的热门度的过程中,还包括设定每个商品年销量的权重值、月销量的权重值和周销量的权重值,并根据年销量的权重值、月销量的权重值和周销量的权重值,以及年销量、月销量和周销量获取每个候选商品的热门度;所述候选商品的热门度通过下式确定:式中,为候选商品的热门度;为候选商品周销售量的权重值;为候选商品的周销售量;为候选商品月销售量的权重值;为候选商品的月销售量;为候选商品年销售量的权重值;为候选商品的年销售量。
10.进一步地,所述根据锚定商品的浏览时长,以及对锚定商品的处置行为获取所述锚定商品的浏览兴趣度的过程中,所述处置行为包括收藏行为,加入购物车行为和购买行为;所述锚定商品的浏览兴趣度通过下式确定:式中,为锚定商品的浏览兴趣度;为浏览商品的时长;表示收藏行为,有收藏行为时的值为1,无收藏行为时的值为0;表示购物行为,有加入购物车的行为时的值为1,无加入购物车的行为时的值为0;表示购买行为,有购买行为时的值为1,无购买行为时,的值为0;表示向下取最接近的整数。
11.进一步地,还包括根据候选商品和锚定商品构建知识图谱;获取所述锚定商品与每个候选商品在知识图谱中的距离;根据所述锚定商品与每个候选商品在知识图谱中的距离确定所述锚定商品与每个候选商品的相似度。
12.进一步地,所述候选商品的重要程度获取每个候选商品与所述锚定商品的关联性的获取过程为:构建图神经网络,图神经网络包括输入层、卷积层、全连接层和输出层;在输入层输入所述锚定商品与每个候选商品的相似度、每个关键词的长尾度和每个候选商品的热门度,以及所述锚定商品的浏览时长,获取每个候选商品的重要程度;在卷积层根据每个候选商品的标签向量进行卷积操作,在知识图谱中选择任一个
节点,并将与选定的节点相邻的所有的节点作为邻域,根据所有邻域内节点的重要程度获取重要程度的聚合权重;依次获取每一节点对应所有邻域内节点的重要程度获取重要程度的聚合权重,并对所有节点进行分类;输出层输出每个候选商品与锚定商品的关联性。
13.进一步地,所述候选商品的重要程度通过下式确定:式中,表示候选商品的重要程度,为候选商品对应关键词的长尾度;为锚定商品与候选商品的相似度;为候选商品的热门度;为锚定商品的浏览兴趣度。
14.进一步地,还包括对每个候选商品进行更新,并获取多次更新后的候选商品的推荐分;所述候选商品的推荐分通过下式确定:式中,为第个候选商品在次更新后的推荐分;为第个候选商品在次更新后的探索分数;为第个候选商品在次更新后卡尔曼增益系数;为第个候选商品的估计分数。
15.与现有技术相比,本发明的有益效果是:本发明提供了一种基于大数据的同类商品选型推荐方法,该方法通过获取用户输入的每个关键词的目标分词,目标分词获取多个候选商品,由此可根据用户在输入框输入的关键词确定多个候选商品;进一步地,根据每个关键词对应的候选商品构建知识图谱;根据每个关键词中目标分词对应的候选商品的数量获取每个关键词的长尾度;进一步地,获取锚定商品与每个候选商品的相似度,并根据每个候选商品的年销售量、月销售量和周销售量获取每个候选商品的热门度;获取锚定商品的浏览兴趣度;进一步地,获取每个候选商品与锚定商品的关联性;获取每个候选商品的推荐分数,然后将全部候选商品根据推荐分数的大小进行排列,并将排列后的候选商品展示在所述锚定商品所在的页面中,由此可实现根据用户输入的关键词进行同类商品的推荐;本发明解决了现有技术中,在进行商品推荐时产生大量的无效推送信息,以及浪费网络及计算机资源的技术问题。
附图说明
16.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
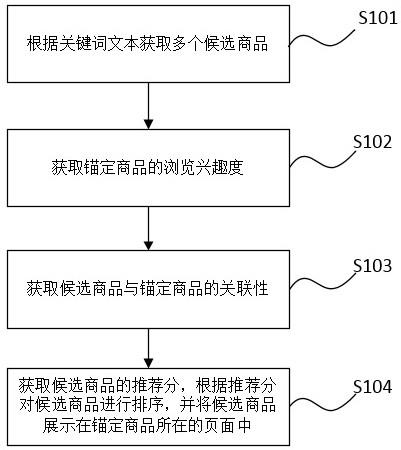
17.图1为本发明的实施例提供的商品推荐方法的流程示意图。
具体实施方式
18.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于
本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
19.本实施例提供了一种基于大数据的同类商品选型推荐方法,如图1所示,方法包括:s101,获取用户在搜索框输入的关键词文本,获取关键词文本中每个关键词出现的时间点;获取每个关键词的多个分词;根据每个关键词出现的时间点获取多个分词中每两个分词之间的时间间隔;根据时间间隔获取每个关键词的目标分词;对每个目标分词进行商品推荐,获得多个候选商品;需要说明的是,本实施例中通过构建数据处理服务器,根据数据处理服务器完成了对用户数的采集,服务器采用flink大数据框架,flink控制台控制着多个数据库和服务器,包括用户库、商品库、店铺库以及装载本方法的算法服务器,并且调用flink的机器学习(flinkml)和图分析(gelly)组件;当用户点开客户端上的搜索框后,开始获取用户的数据流,进行在线分析;实际上,在电商平台的商品搜索过程中,搜索结果的数量是庞大的,而且无法全部展示,同时后台运算着许多推荐算法进行筛选,因此,可以认为搜索和推荐是等价的;当展示初次推荐的结果后,如果用户点击了一个商品,那么本实施例会在商品展示页面的客户端窗口看不到的后续页面中生成与刚才点击的商品同类型的商品;在这一过程中,算法会分析出用户输入的关键词中的具体商品类别信息,最终实现提升用户选购的效率,提升用户购买的可能性,提高商品的点击率和转化率;本实施例中将用户点击的商品称为锚定商品;s102,根据每个关键词对应的候选商品构建知识图谱;根据每个关键词中目标分词对应的候选商品的数量获取每个关键词的长尾度;获取锚定商品与每个候选商品的相似度,并根据每个候选商品的年销售量、月销售量和周销售量获取每个候选商品的热门度;获取锚定商品的浏览兴趣度;获取每个候选商品与候选商品对应点关键词的匹配程度,根据匹配程度获取每个候选商品的估计分数;需要说明的是,本实施例中是根据每个关键词对应的候选商品构建知识图谱的;在电商领域中,知识图谱是由节点和边组成,节点包括商品的名词和概念,例如皮包、耐磨;两个节点之间的边代表两个节点之间的关系;例如,当商品标题中出现
ꢀ“
短裤”这个词汇时,通过使用<短裤,品类是一种品类,裤子>这一条常识知识,知道该商品是“裤子”;当商品标题中出现“亚麻”这个词汇时,通过使用<亚麻,材质等义材质,麻布>这一条常识知识,知道这个商品的材质是“麻布”;然后获得候选商品的列表,按照店铺分为多个模块;对每一个候选商品进行embedding操作,能够使属性相近的标签词语在空间中尽量靠近,即向量的数值大小尽量相近,接下来每一个候选商品都有属性向量;根据每个关键词中目标分词对应的候选商品的数量获取每个关键词的长尾度的过程为,获取每个关键词中目标分词对应的候选商品的数量;获取与每个候选商品有关联的商品数量的平均值;每个关键词的长尾度为每个候选商品有关联的商品数量的平均值与每个关键词中目标分词对应的候选商品的数量的差值;获取锚定商品与每个候选商品的相似度的过程为,获取锚定商品与每个候选商品在知识图谱中的距离;根据锚定商品与每个候选商品在知识图谱中的距离确定锚定商品与每个候选商品的相似度;锚定商品与每个候选商品的相似度通过下式确定:
式中,为锚定商品与候选商品的相似度;表示知识图谱中锚定商品与候选商品之间第条间接路线的距离;为锚定商品与候选商品之间全部的间接路线;根据每个候选商品的年销售量、月销售量和周销售量获取每个候选商品的热门度的过程中,还包括设定每个商品年销售量的权重值、月销售量的权重值和周销售量的权重值,并根据年销售量的权重值、月销售量的权重值和周销售量的权重值,以及年销售量、月销售量和周销售量获取每个候选商品的热门度;候选商品的热门度通过下式确定:式中,为候选商品的热门度;为候选商品周销售量的权重值;为候选商品的周销售量;为候选商品月销售量的权重值;为候选商品的月销售量;为候选商品年销售量的权重值;为候选商品的年销售量;需要说明的是,本实施例中根据实施条件设定候选商品周销售量的权重值为0.7;候选商品月销售量的权重值为0.2;候选商品年销售量的权重值为0.1;实施者可根据具体实施条件设定其他的值为候选商品周销售量的权重值、候选商品月销售量的权重值和候选商品年销售量的权重值;锚定商品的浏览兴趣度通过下式确定:式中,为锚定商品的浏览兴趣度;为浏览商品的时长;表示收藏行为,有收藏行为时的值为1,无收藏行为时的值为0;表示购物行为,有加入购物车的行为时的值为1,无加入购物车的行为时的值为0;表示购买行为,有购买行为时的值为1,无购买行为时,的值为0;表示向下取最接近的整数。
20.获取每个候选商品与候选商品对应点关键词的匹配程度,根据匹配程度获取每个候选商品的估计分数的过程为,构建标题transformer,其中使用注意力机制得到注意力分数;输入为搜索关键词和所有候选商品的标题,输出为每一个候选商品的关键词匹配度,候选商品的关键词匹配度是一个之间的概率值,代表语义的相似性;
需要说明的是,求关键词匹配度本质上是电商query类目预测问题,用于召回相似的标题关键词,以此衡量标题相关性,候选商品最终得到估计分数,估计分数和探索分数在一开始各为50,关键词匹配度,代表此候选商品越可能是关键词代表的商品,因此估计分数越高;s103,构建图神经网络,图神经网络包括输入层、卷积层、全连接层和输出层;在输入层根据锚定商品与任一候选商品的相似度、候选商品的热门度、锚定商品的浏览兴趣度,以及候选商品对应关键词的长尾度,获取候选商品对应知识图谱中节点的重要程度;依次获取每个候选商品对应知识图谱中节点的重要程度;在卷积层根据每个候选商品的标签向量进行卷积操作,在知识图谱中选择任一个节点,并将与选定的节点相邻的所有的节点作为邻域,根据所有邻域内节点的重要程度获取重要程度的聚合权重;依次获取每一节点对应所有邻域内节点的重要程度获取重要程度的聚合权重;在全连接层交换所有节点对应所有邻域内节点的重要程度获取重要程度的聚合权重,并对所有节点进行分类;输出层输出每个候选商品与锚定商品的关联性;获取每个候选商品对应知识图谱中节点的重要程度的过程为,训练关键词语义分析网络,人为对数据集的候选商品的相似性进行标注,80%作为训练集,20%作为测试集,使用bpr损失函数,优化器使用adam,经过训练最终得到生成效果良好的神经网络推荐系统中使用广泛的 bpr损失;该损失基于贝叶斯排序,考虑到了可观察到和不可观察到的用户与物品交互的相对顺序,认为观察到的交互项的重要程度比不可观察到的交互项的重要程度更高;在图神经网络输入层根据锚定商品与任一候选商品的相似度、候选商品的热门度、锚定商品的浏览兴趣度,以及候选商品对应关键词的长尾度,获取候选商品对应知识图谱中节点的重要程度;锚定商品在知识网络中表示为节点,因此知识网络中节点的重要程度通过下式确定:式中,表示候选商品对应的节点的重要程度,为候选商品对应关键词的长尾度;为锚定商品与候选商品的相似度;为候选商品的热门度;在卷积层根据每个候选商品的标签向量进行卷积操作,在知识图谱中选择任一个节点,并将与选定的节点相邻的所有的节点作为邻域,根据所有邻域内节点的重要程度获取重要程度的聚合权重;依次获取每一节点对应所有邻域内节点的重要程度获取重要程度的聚合权重;要程度的聚合权重通过下式确定:式中,是归一化激活函数,为余弦相似度,即两个向量进行点乘,因为进行了embedding,所以两个商品越是相似,余弦相似度越大;表示第个候选商品的标签向量;表示第个候选商品对应的节点的重要程度;在后续的聚合中,每个节点使用最新的向量值,总共聚合3次,以保证每个节点充
分感知周围节点的信息,得到最终更新完成的特征向量;最终经过全连接层交换所有节点的信息,实现分类效果,在输出层输出每个候选商品与锚定商品的关联性,进一步地得到每个候选商品经历了第n次更新后的探索分通过下式确定:式中,为第个候选商品经历了第n次更新后的探索分;为候选商品与锚定商品的关联性;为第个候选商品经历了第n-1次更新后的探索分;需要说明的是,探索分是一个累加的过程,每探索一次给用户可能感兴趣的商品提高探索分,设定所有候选商品的初始探索分为;s104,根据关联性获取每个节点在进行多次更新后的探索分数,根据探索分数和估计分数获取每个节点在进行多次更新后的推荐分,根据推荐分将多个候选商品进行排列,并将排列后的候选商品推荐给用户端;用户根据推荐信息选择符合自己购买意向的候选商品;本实施例中,首先,获取购买了某一商品的所有用户数据,追溯他们的搜索关键词,得到逻辑树状图,即可对每一次点击结果进行标注;然后训练神经网络;将80%的标注数据作为训练集,将20%标注数据作为测试集,使用bpr损失函数,优化器使用adam,经过训练最终得到生成效果良好的神经网络;设训练过后,第一神经网络的识别准确率为,即进行数据更新,更新候选商品的推荐分数;推荐分数为估计分数和探索分数的融合,具体数据融合技术为卡尔曼滤波,在用户第n次点击后得到第i个候选商品的数据融合后的推荐分数通过下式确定:式中,为第n次点击后得到第i个候选商品的推荐分数,为第个候选商品经历了第n次更新后的探索分;为第i个候选商品第n次点击后的卡尔曼增益系数;为每个候选商品的推荐分;需要说明的是,本实施例中第n次点击后的卡尔曼增益系数与前一次点击之后的估计误差相关;其中第n次点击后的卡尔曼增益系数通过下式确定:
式中,为第i个候选商品第n次点击后的卡尔曼增益系数;为n次点击后的估计分与n-1次点击后估计分的差值;为为点击误差;其中,;为第i个候选商品第n次点击后的推荐分;为第i个候选商品第n次点击后的卡尔曼增益系数;为n次点击后的估计分与n-1次点击后估计分的差值;为候选商品对应关键词的长尾度;表示向下取整;表示第i个候选商品的推荐分,表示初始值;第i个候选商品第n次点击后的推荐分通过第i个候选商品的推荐分迭代获得;依次获得第n次点击后得到每个候选商品的数据融合后的推荐分数;根据推荐分将多个候选商品由大到小进行排列,并将排列后的候选商品展示在所述锚定商品所在的页面中;需要说明的是,在每一次点击后将根据候选商品的推荐分数将候选商品推荐给用户,从而达到越浏览,越是推荐用户想要的商品;本实施例结合互联网的词条和数据进行数据库的更新, 用户在浏览一件商品时是需要花时间的,这时候足够在分布式服务器上运行本算法,从而在后续的页面中展示推荐的同类型商品;大数据系统不承担神经网络的训练任务,仅用来运行训练完成的模型,因此测试过程的显存占用量反映了真实的大数据平台配置需求,本实施例在测试过程中占用显存相比于原算法增加不明显,因此能够运行于一般的电商平台服务器;综上,本实施例提供了一种基于大数据的同类商品选型推荐方法,通过该方法通过获取用户输入的每个关键词的目标分词,目标分词获取多个候选商品,由此可根据用户在输入框输入的关键词确定多个候选商品;根据每个关键词对应的候选商品构建知识图谱;根据每个关键词中目标分词对应的候选商品的数量获取每个关键词的长尾度;获取锚定商品与每个候选商品的相似度,并根据每个候选商品的年销售量、月销售量和周销售量获取每个候选商品的热门度;获取锚定商品的浏览兴趣度;通过构建图神经网络可获得每个候选商品与锚定商品的关联性;获取每个候选商品的推荐分数,然后将全部候选商品根据推荐分数的大小进行排列,并将排列后的候选商品展示在所述锚定商品所在的页面中,由此可实现根据用户输入的关键词进行同类商品的推荐;本实施例解决了现有技术中,在进行商品推荐时产生大量的无效推送信息,以及浪费网络及计算机资源的技术问题。
21.以上仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。