1.本发明涉及图像识别领域,尤其是涉及一种基于多模态预训练持续学习的目标检测优化方法。
背景技术:
2.近年来,目标检测模型已经在各个领域得到广泛应用。然而,大部分目标检测模型都遵循数据收集-模型训练评估-模型部署上线的流程。一般情况下,模型在部署上线之后不会继续更新,对线上发生的误报及对目标检测结果需要优化的情况,只能通过重新训练的方式优化模型。在这样的背景下,频繁训练或微调模型,以及后续的模型评估上线会带来巨大的迭代成本,如果能够在检测完成后对结果进行优化,就不需要频繁调整或训练上游模型,可以低成本提升结果准确度。
技术实现要素:
3.本发明主要是解决现有技术所存在的目标检测结果缺乏有效准确的优化手段的技术问题,提供一种基于多模态预训练持续学习的目标检测优化方法。
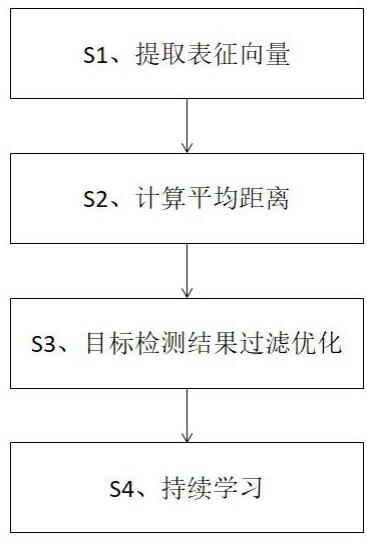
4.本发明针对上述技术问题主要是通过下述技术方案得以解决的:一种基于多模态预训练持续学习的目标检测优化方法,包括以下步骤:s1、提取表征向量:将对图片i进行目标检测所得到的包含目标j的结果输入训练后的表征提取模型,获得目标j的表征向量;目标检测得到的结果可以包含若干个目标,j是其中之一,一轮只处理一个目标;s2、计算平均距离:知识库包括正表征库和负表征库;计算目标j的表征向量与正表征库中的每个表征向量的余弦距离,并取最大的前k个计算平均值得到正平均距离d_ij_pos;计算目标j的表征向量与负表征库中的每个表征向量的余弦距离,并取最大的前k个计算平均值得到负平均距离d_ij_neg;k为预设的超参数;s3、目标检测结果过滤优化:比较d_ij_pos和d_ij_neg,如果d_ij_pos《d_ij_neg,则将此目标j的检测结果过滤;如果d_ij_pos》d_ij_neg,则将此目标j的检测结果保留;s4、持续学习:对于正表征库的每个表征向量,计算其与正表征库中其它表征向量的余弦距离,并取最大的前k个计算平均值得到此表征向量的平均距离,对正表征库的所有表征向量的平均距离再求平均值得到正库平均距离c_pos;对于负表征库的每个表征向量,计算其与负表征库中其它表征向量的余弦距离,并取最大的前k个计算平均值得到此表征向量的平均距离,对负表征库的所有表征向量的平均距离再求平均值得到负库平均距离c_neg;对每个被保留的目标j, 如果d_ij_pos《c_pos且 d_ij_neg》c_neg , 则将此目标j的表征向量纳入正表征库;对每个被过滤的目标j, 如果d_ij_neg《c_neg 且d_ij_pos》c_pos , 则将此目标j的表征向量纳入负表征库。
5.通过持续学习,可以不断更新知识库,从而不断提升目标检测结果优化的准确度。
6.作为优选,所述表征提取模型包括图像编码器和特征金字塔网络(fpn),图像编码
器为主干部分;图像编码器为任意的基于图像的神经网络模型,例如resnet、 convnext、vision transformer等;目标检测所得到的包含目标j的结果包括图片i和目标j区域图片;图片i一般为3个颜色通道的自然图像;目标j区域图片理解为从图片i中截取的目标j所在区域的图像,具体形式可以是若干个坐标围成的范围;目标j的表征向量提取过程具体为:s101、将图片i输入到作为主干部分的图像编码器,抽取每个输出层输出的特征得到图片i的整体多层特征图;s102、依据目标j区域图片在图片i中的位置,从整体多层特征图中截取得到目标多层特征图;s103、使用特征金字塔网络对目标多层特征图进行提取池化,例如roialign,得到目标j的表征向量。
7.作为优选,表征提取模型的训练时引入文本编码器和教师图像编码器,文本编码器为现有的文本特征提取模型,教师图像编码器为现有的训练后的图像特征提取模型(可以采用表征提取模型中的图像编码器,然后用现有公开的训练库进行训练后作为教师图像编码器);表征提取模型的训练时的损失函数为:l=l
cntrst
l
dist
l
cntrst-img
其中,l
cntrst
为目标图文对比损失,计算公式如下:式中,n为训练所用的样本总数,训练所用的样本包括整体图像、整体图像的描述文本、目标区域图片和目标的描述文本,v_m是第m个样本的目标区域图片经过表征提取模型后得到的图像表征,l_m是第m个样本的目标的描述文本经过文本编码器后得到的文本表征,文本编码器一般可以采用bert、 roberta等,文本编码器参与训练但不会被更新,p(v_m,l_m)的计算公式如下:式中,s为计算括号中两个对象的相似度,τ为温度超参数,nri为同一批训练所用样本中除第m个样本之外的其它样本的目标的描述文本经过文本编码器后得到的文本表征集合,即文本描述k和图片目标i不匹配,但是和同一个batch(训练样本集)中的其他目标k匹配;s的计算公式为:
式中,t表示转置,双竖线表示求向量长度,即norm2;l
dist
为图片自监督蒸馏损失,计算公式如下:式中,l
kl
表示计算kullback-leibler散度,q_m为第m个样本的整体图像经过图像编码器后再经过指数归一化(softmax)得到的被识别为同一批训练样本中每个整体图像所属类别的概率;q_m_t为第m个样本中的整体图像经过教师图像编码器后再经过指数归一化得到的被识别为整体图像自身所属类别的概率;教师图像编码器的网络权重不更新,即教师图像编码器参与训练但不被训练;l
cntrst-img
为图片级别自监督对比损失:p(v_m_img)为第m个样本的整体图像输入图像编码器后得到的整图表征(区别于之前的多层表征),l_m_img为第m个样本的整体图像的描述文本输入文本编码器后得到的整图描述文本表征;通过上述训练任务,模型通过反向传播的方式进行训练优化。表征提取模型中的图像编码器可以选择在公开的大规模预训练数据上进行预训练的模型作为初始模型。
8.作为优选,步骤s02中,余弦距离的计算公式为:其中,x=(x1,x2,
…
,xn)表示目标表征向量,y=(y1,y2,
…
,yn)表示知识库中的表征向量,n是向量的维度。
9.作为优选,知识库的原始建立来源于上游目标检测模型对图像的目标推理以及用户对识别结果的反馈。
10.本发明带来的实质性效果是,可以对目标检测结果进行优化,从而达到在不需要更新上游大模型的基础上,以极低的成本提升预训练大模型在目标识别的精准度,节省模型重新训练迭代的成本,消除基础模型的频繁更新对下游任务造成的影响。
附图说明
11.图1是本发明的一种目标检测优化过程的流程图。
具体实施方式
12.下面通过实施例,并结合附图,对本发明的技术方案作进一步具体的说明。
13.实施例:本实施例的一种基于多模态预训练持续学习的目标检测优化方法,如图1所示,包括以下步骤:s1、提取表征向量:将对图片i进行目标检测所得到的包含目标j的结果输入训练后的表征提取模型,获得目标j的表征向量;目标检测得到的结果可以包含若干个目标,j是其中之一,一轮只处理一个目标;s2、计算平均距离:知识库包括正表征库和负表征库;计算目标j的表征向量与正表征库中的每个表征向量的余弦距离,并取最大的前k个计算平均值得到正平均距离d_ij_pos;计算目标j的表征向量与负表征库中的每个表征向量的余弦距离,并取最大的前k个计算平均值得到负平均距离d_ij_neg;k为预设的超参数,一般可以取值为50;s3、目标检测结果过滤优化:比较d_ij_pos和d_ij_neg,如果d_ij_pos《d_ij_neg,则将此目标j的检测结果过滤;如果d_ij_pos》d_ij_neg,则将此目标j的检测结果保留;s4、持续学习:对于正表征库的每个表征向量,计算其与正表征库中其它表征向量的余弦距离,并取最大的前k个计算平均值得到此表征向量的平均距离,对正表征库的所有表征向量的平均距离再求平均值得到正库平均距离c_pos;对于负表征库的每个表征向量,计算其与负表征库中其它表征向量的余弦距离,并取最大的前k个计算平均值得到此表征向量的平均距离,对负表征库的所有表征向量的平均距离再求平均值得到负库平均距离c_neg;对每个被保留的目标j, 如果d_ij_pos《c_pos且 d_ij_neg》c_neg , 则将此目标j的表征向量纳入正表征库;对每个被过滤的目标j, 如果d_ij_neg《c_neg 且d_ij_pos》c_pos , 则将此目标j的表征向量纳入负表征库。
14.所述表征提取模型包括图像编码器和特征金字塔网络,图像编码器为主干部分;图像编码器为任意的基于图像的神经网络模型,例如resnet、 convnext、vision transformer等;目标检测所得到的包含目标j的结果包括图片i和目标j区域图片;图片i一般为3个颜色通道的自然图像;目标j区域图片理解为从图片i中截取的目标j所在区域的图像,具体形式可以是若干个坐标围成的范围;目标j的表征向量提取过程具体为:s101、将图片i输入到作为主干部分的图像编码器,抽取每个输出层输出的特征得到图片i的整体多层特征图;s102、依据目标j区域图片在图片i中的位置,从整体多层特征图中截取得到目标多层特征图;s103、使用特征金字塔网络对目标多层特征图进行提取池化,例如roialign,得到目标j的表征向量。
15.具体操作如下:对图像编码器中conv2,conv3,conv4和conv5输出层的输出{c2,c3,c4,c5}作为fpn的特征,分别对应于输入图片的下采样倍数为{4,8,16,32},自顶向下的过程通过上采样(up-sampling)的方式将顶层的小特征图放大到上一个阶段的特征图一样的大小;c5 通过1x1卷积与上采样,加上c4 1x1卷积之后的特征图得到融合层m4,并依次类推得到m3,m2;通过3x3卷积得到最终的fpn特征{p2,p3,p4,p5};在经过fpn进行特征提取之后,一个非线性变换(神经网络全连接层)被用来将特征表示映射到对比损失的空间;对图
像i的目标j来说,就是通过图像区域编码器将目标j抽取为一个表征向量v_ij。
16.表征提取模型的训练时引入文本编码器和教师图像编码器,文本编码器为现有的文本特征提取模型,教师图像编码器为现有的训练后的图像特征提取模型,可以采用与表征提取模型中相同的图像编码器,然后用现有公开的训练库进行训练后作为教师图像编码器;表征提取模型的训练时的损失函数为:l=l
cntrst
l
dist
l
cntrst-img
其中,l
cntrst
为目标图文对比损失,计算公式如下:式中,n为训练所用的样本总数,训练所用的样本包括整体图像、整体图像的描述文本、目标区域图片和目标的描述文本,v_m是第m个样本的目标区域图片经过表征提取模型后得到的图像表征,l_m是第m个样本的目标的描述文本经过文本编码器后得到的文本表征,文本编码器采用bert或roberta,文本编码器参与训练但不会被更新,p(v_m,l_m)的计算公式如下:式中,s为计算括号中两个对象的相似度,τ为温度超参数,nri为同一批训练所用样本中除第m个样本之外的其它样本的目标的描述文本经过文本编码器后得到的文本表征集合,即文本描述k和图片目标i不匹配,但是和同一个batch(训练样本集)中的其他目标k匹配;s的计算公式为:式中,t表示转置,双竖线表示求向量长度,即norm2;l
dist
为图片自监督蒸馏损失,计算公式如下:式中,l
kl
表示计算kullback-leibler散度,q_m为第m个样本的整体图像经过图像编码器后再经过指数归一化(softmax)得到的被识别为同一批训练样本中每个整体图像所属类别的概率;q_m_t为第m个样本中的整体图像经过教师图像编码器后再经过指数归一化
得到的被识别为整体图像自身所属类别的概率;教师图像编码器的网络权重不更新,即教师图像编码器参与训练但不被训练;l
cntrst-img
为图片级别自监督对比损失;p(v_m_img)为第m个样本的整体图像输入图像编码器后得到的整图表征(区别于之前的多层表征),l_m_img为第m个样本的整体图像的描述文本输入文本编码器后得到的整图描述文本表征;通过上述训练任务,模型通过反向传播的方式进行训练优化。表征提取模型中的图像编码器可以选择在大规模预训练数据上进行预训练的模型作为初始模型。
17.步骤s02中,余弦距离的计算公式为:其中,x=(x1,x2,
…
,xn)表示目标表征向量,y=(y1,y2,
…
,yn)表示知识库中的表征向量,n是向量的维度。
18.知识库的原始建立来源于上游目标检测模型对图像的目标推理以及用户对识别结果的反馈。
19.本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
20.尽管本文较多地使用了表征向量、平均距离等术语,但并不排除使用其它术语的可能性。使用这些术语仅仅是为了更方便地描述和解释本发明的本质;把它们解释成任何一种附加的限制都是与本发明精神相违背的。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。