1.本发明涉及基于起源图的日志压缩领域,具体涉及一种基于起源图的日志采集、压缩、存储方法。
背景技术:
2.高级持续威胁(apt)攻击对政府和大型企业造成的危害日趋严重,与常规攻击或普通黑客的攻击不同,威胁攻击者遵循“低且慢“的原则,使用执行攻击所需的高级工具和先进方法,通过多个攻击载体渗透目标主机,以不同的形式执行多个攻击阶段,包括侦察、驻点建立、横向渗透、痕迹清理,并采用多种规避技术尽可能长时间潜伏在目标主机中不被入侵检测系统发现,最终达到窃取用户办公电脑和存储设备中的敏感数据、阻碍服务器正常活动的执行,破坏核心基础设施完整性的目的。
3.安全分析人员需要良好的分析工具组织和抽象终端主机活动之间的交互关系来描述和建模防御攻击,起源图被认为是一种威胁建模的标准工具。起源图受到数据来源概念的启发,利用终端的系统审计日志构建带时间戳的有向无环图(dag)来表示系统实体之间的依赖关系和因果关系,以支持安全从业者进行相关的安全分析操作,如捕捉可疑的事件链、检测实时的攻击威胁以及调查攻击的源点和影响。
4.尽管基于起源图的端点检测与响应系统被证明非常有效。然而,由于apt攻击的高持久性和潜伏性,起源图需要收集长时间的海量历史日志记录以支持安全工作者执行全面、精准的安全分析任务,这不仅带来了巨大的存储开销,而且还急剧增加了计算成本。
5.根据调研显示,当前基于起源图的处理系统存在如下问题:当前的数据采集策略为系统事件建立的依赖关系存在虚假依赖、依赖缺失、依赖爆炸等问题,降低了后续安全调查结果的可信度。
6.当前的数据压缩策略为了达到高压缩比可能会删除关键的可疑活动,阻碍因果关系的分析。
7.当前的数据存储策略没有考虑优化审计日志数据的存储模型,浪费了存储空间。同时缺乏特定的图形查询功能以及可视化的高级事件视图,存在昂贵的人工成本。
8.现有的基于起源图的数据处理策略只考虑日志采集、压缩、存储中的一方面。没有全方面的考察采集、压缩、存储过程中优化的可能性,联合采取采集、压缩、存储中的优化策略为基于apt攻击的安全分析任务提供可靠、便捷、高效的数据基底。
技术实现要素:
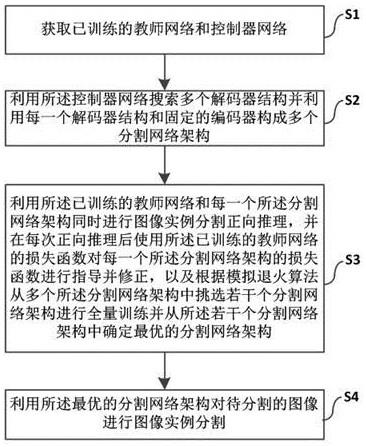
9.针对现有技术的不足,本发明提供了一种基于起源图的日志采集、压缩、存储方法,合理地组合数据采集、压缩、存储策略来快速响应基于apt的安全分析任务。
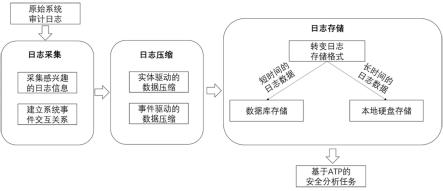
10.一种基于起源图的日志采集、压缩、存储方法,包括如下步骤:(1) 采集日志数据:采集原始系统审计日志,建立系统实体间的交互关系;(2) 实施日志压缩:执行基于起源图的数据压缩策略对建立因果关系后的系统审
growth的模板学习策略对频繁使用的系统实体组合生成模板,根据模板匹配建立因果关系后的系统审计日志中符合模板中系统操作序列的系统实体,匹配成功后进行合并,形成实体集合;频繁使用为一小时内出现10次~10万次;实体驱动的日志压缩方法聚合实现相同功能的实体,相较于原生的审计日志,实体驱动的日志压缩方法大幅度减少了审计日志中的实体数量,减轻了安全分析人员执行安全分析任务的负担同时也加速了安全分析任务的开展;(2-2)事件驱动的日志压缩:观察实体集合间的交互关系,观察实体集合间的交互关系是否是冗余的,如果是冗余的,则进行压缩,如果不冗余的,则不进行压缩。
18.观察实体集合间的交互关系是否是冗余的,具体包括:将排好序的交互关系作为输入,为每一对实体集合的每种类型的交互关系维护一个堆栈,一旦有同一对实体集合的事件入栈时,检查该交互关系的前向和后向跟踪能力是否可以和堆栈中的交互关系相同,若相同,则聚合两个交互关系,将前一个交互关系的结束时间延长到后一个交互关系的结束时间,完成压缩,得到压缩后的系统审计日志。
19.事件驱动的日志压缩在不改变审计日志的结构特征和语义特征的情况下大幅度减少了不影响安全分析任务的冗余交互关系。减轻了原生审计日志的存储成本同时也加快了后续安全分析任务的执行效率。
20.步骤(3)中,(3-1)第一种日志数据存储方式:设计一种具有空间效率的基于起源图的数据存储格式,每个实体集合间的交互关系使用8~12个字节进行存储,存储在系统实体中。
21.设计一种具有空间效率的基于起源图的数据存储格式,每个实体集合间的交互关系使用8~12个字节进行存储,具体包括:(3-1-1)将实体集合间的交互关系存储在系统实体中,并使用可变长度编码策略编码实体集合间的交互关系;(3-1-2)用相对增量的时间表示方法来编码同一实体集合上的多个交互关系的发生时间和结束时间;(3-1-3)根据实体标识符采用索引表来引用实体集合。
22.第一种日志数据存储方式优化了审计日志在内存中的表示形式,使得计算机可以一次性将所有审计日志写入内存中,一方面使得安全分析任务可以更加全面的理解审计日志中代表的系统活动,另一面促进了安全分析任务的快速检测与实时分析。
[0023] (3-2)第二种日志数据存储方式:将压缩后的系统审计日志经过预处理后,输入到双层长短期记忆网络的深度神经网络预测每个字词的概率,并利用得到的概率执行算术编码策略进行文本无损压缩存储在本地硬盘中。
[0024]
第二种日志数据存储方式针对审计日志的结构特征进行优化,与传统的文本无损压缩方法相比,能够达到更高的压缩率,实现了在相同硬盘空间中存储更多的信息数据。为需要调查长时间审计日志的安全分析任务提供了审计日志存储问题的解决方法。
[0025]
所述的预处理具体包括:(3-2-1)将压缩后的系统审计日志进行关键字模板处理;
(3-2-2)将关键字模板处理后的系统审计日志进行单调值处理;(3-2-3)单调值处理后的系统审计日志进行频繁事件处理。
[0026]
频繁事件处理具体包括:将单调值处理后的系统审计日志中的实体集合间的交互关系,若主体、客体、操作类型相同,根据相同次数的频繁程度用可变长度编码策略进行编码。
[0027]
频繁事件的定义:每五秒发生15~25次相同操作的事件,进一步优选,每五秒发生二十次相同操作的事件。
[0028]
本发明的有益效果主要表现在:1、日志采集策略建立了系统事件间可靠、完整的依赖关系和因果关系,有效缓解了虚假依赖、依赖缺失、依赖爆炸等问题;2、日志压缩策略在尽可能保留了起源图语义的同时也实现了高压缩比,缓解了日志的空间开销;3、日志存储策略考虑了短时间的日志数据和长时间的日志数据,并进一步删除了信息的冗余,为安全分析任务提供了全面、完整的系统执行历史背景视图;4、合理地组合数据采集、压缩、存储策略来快速响应基于apt的安全分析任务。
附图说明
[0029]
图1为一种基于起源图的日志采集、压缩、存储方法流程图。
[0030]
图2为ldx流程示例的示意图。
[0031]
图3为补偿增量示例的示意图。
[0032]
图4为一种双层lstm深度神经网络的模型架构的示意图。
[0033]
图5为因果关系追踪示例的示意图。
具体实施方式
[0034]
下面将结合附图对本发明作进一步描述。
[0035]
如图1所示,一种基于起源图的日志采集、压缩、存储方法,包括如下步骤:(1) 采集系统审计日志数据,建立系统实体间的交互关系;(2) 执行基于起源图的数据压缩策略,降低数据存储开销;(3) 设计基于起源图的日志数据存储模型,进一步降低数据中的信息冗余。并设计基于起源图的图形数据库,该数据库具有特定于apt攻击的查询语言。
[0036]
步骤(1)中,采集日志数据的详细步骤如下:(1-1)处理原始系统审计日志:根据用户的需求从windows、linux等多个操作系统收集审计日志,用户可以通过设置指定的文件,套接字、路径名、网络地址来跟踪其感兴趣的进程、主机、应用程序之间的任何信息流。收集审计日志的具体信息如表1、表2所示:表1系统实体属性
表2系统事件属性审计日志的格式为:{"eventname","processid","processname","parentprocessid","parentprocessname","threadid","timestamp","arguments":{"fileindex","filekey","filename","fileobject","infoclass","irpptr","length","ttid"}}。
[0037]
(1-2)建立系统事件交互关系:利用轻量级双执行策略为系统事件建立真实且完整的因果关系,具体来说,轻量级双执行策略预定义输入点和交汇点,给定一个主执行,并行派生一个执行并改变其输入值,若在主执行和从执行对齐的交汇点处(如write()或sendmsg())上观察到输出缓冲区数据存在差异,则汇点和输入点存在依赖关系。如图2所示,针对read()函数,启动一个从源点开始的从执行,并更改套接字句柄,比较输出结果是否与主执行的输出结果一致,若一致,则套接字句柄与源存在依赖关系;针对write()以及sendmsg()函数,启动一个从源点开始的从执行,更改缓冲去内容,比较输出结果是否与主执行的输出结果一致,若一致,则缓冲区内容与源存在依赖关系。同时,利用一种轻量级动态对齐方案,通过维护一个计数器来反映执行进度,从而防止由于扰动可能会导致系统调用差异的问题。具体来说,它为每次执行操作都维护一个代表进度的计数器,具有相同计数器值和相同pc的执行点被保证是对齐的。当两个执行采用一个条件判断语句的不同分支时,由于这些分支可能具有不同数量的系统调用,因此添加到计数器的值可能不同。该技术补偿增量较小的分支中的计数器,以便达到分支的连接点时计数器必须具有相同的值,如图3所示。
[0038]
步骤(2)中,实施日志压缩的详细步骤如下:(2-1)实体驱动的日志压缩:针对应用程序在执行期间创建和操作的临时文件产生的日志,若任何临时文件直接或通过传递于记录的事件,则将该事件标记为可访问时间,删除与初始审计日志中无法访问的系统实体。采用基于fp-growth的模板学习策略,为每个应用程序中频繁使用的文件组合生成模板,并合并匹配模板的实体集合。
[0039]
(2-2)事件驱动的日志压缩:在保持因果关系依赖性的条件下聚合所有可聚合的事件。具体来说,将排好序的事件流作为输入,为每一对实体间的每种类型的事件维护一个堆栈,一旦有同一对实体间的事件入栈时,检查该事件的前向和后向跟踪能力是否可以和
堆栈中的事件相同,若相同,则聚合两个事件,将前一个事件的结束时间延长到后一个事件的结束时间。对于有公共字段的传入边,在不牺牲因果关系跟踪性能的情况下将多条邻近范围内边聚合为一条边,该合并后的边可以通过指针查找包含的所有传入边的具体信息,仅当查询时间范围包含当前系统事件的时间戳时,才对聚合后的边进行解压缩,因此保障了安全分析任务的有效性和可靠性。
[0040]
步骤(3)中,执行日志存储的详细步骤如下:(3-1)日志数据存储格式设计:设计一种具有空间效率的基于起源图的数据存储格式,每个事件仅使用10个字节进行存储。将事件存储在系统实体中,从而避免了系统实体到事件的指针以及时间标识符,并使用可变长度编码系统事件和实体。利用每个实体的事件发生顺序,利用相对时间来存储同一实体上不同事件的时间戳。通过实体标识符中主体表的索引来引用客体。
[0041]
(3-2)日志数据存储:将相隔时间较久的日志数据经过预处理后,将日志数据输入双层lstm的深度神经网络预测每个字词的概率,并利用得到的概率执行算术编码策略从而进行文本无损压缩方法存储在本地硬盘中。预处理过程分为四个阶段:(1)关键字模板处理:用短数字编码固定的关键字模板,删除关键字固定搭配中存在的冗余,例如固定审计日志模板{"eventname","processid","processname","parentprocessid","parentprocessname","threadid","timestamp","arguments"}。(2)单调值处理:压缩日志条目中共享的公共字符和数字:比如时间戳、用于记录统计信息的计数器、数据库的事务标识符等。(3)频繁事件处理:压缩频繁发生的相同事件,例如,仅时间戳不同但拥有固定属性(如主体、客体、操作类型相同)的事件,根据事件发生的频繁程度用可变长度进行编码。双层长短期记忆网络的深度神经网络如图4,为一种双层lstm深度神经网络的模型架构。
[0042]
将最近的日志数据存储在由postgresql支持的关系数据库中,利用大规模并行处理(mpp)数据库greenplum来存储和搜索系统事件和实体,并提供因果关系追踪,如图5所示。前向分析进程p1影响的范围,跟踪到进程p1对文件f1进行写入操作,然后对进行p2、进行读操作,之后连接进程p3,最终写入了文件f2。因此进程p1的影响范围为文件f1、f2以及进程p1、p2、p3。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。