1.本发明涉及一种训练老年性黄斑部退化的分类模型的电子装置和方法。
背景技术:
2.依据临床病征的严重程度,老年性黄斑部退化(age-related macular degeneration,amd)分类为第一期(或第i期)、第二期(或第ii期)、第三期(或第iii期)以及第四期(或第iv期)。目前,有人员利用人工智能(artificial intelligence,ai)模型分析眼底图(fundus image)以为老年性黄斑部退化的严重程度进行分类。人员可利用由医疗人员标注的训练数据来训练人工智能模型。一般来说,医疗人员会根据眼底图中的黄斑部范围来为老年性黄斑部退化进行分类。然而,不同医疗人员对黄斑部范围的认定可能不同。因此,由不同医疗人员所标注的训练数据所训练的人工智能模型可能存在过度拟合(overfitting)的问题,从而降低了人工智能模型的分类准确度。
技术实现要素:
3.本发明提供一种训练老年性黄斑部退化的分类模型的电子装置和方法,可训练出具有高准确度的老年性黄斑部退化的分类模型。
4.本发明的一种训练老年性黄斑部退化的分类模型的电子装置,包含处理器以及收发器。处理器耦接收发器,其中处理器经配置以执行:通过收发器取得训练数据;基于机器学习算法计算对应于训练数据的损失函数向量,其中损失函数向量包含对应于老年性黄斑部退化的第一期的第一损失函数值以及对应于老年性黄斑部退化的第二期的第二损失函数值;根据第一期与第二期之间的分期差异产生第一惩罚权重;根据第二损失函数值以及第一惩罚权重更新第一损失函数值以产生更新损失函数向量;以及根据更新损失函数向量训练分类模型。
5.在本发明的一实施例中,上述的损失函数向量还包含对应于老年性黄斑部退化的第三期的第三损失函数值,其中处理器还经配置以执行:根据第一期与第三期之间的第二分期差异产生第二惩罚权重;以及根据第三损失函数值以及第二惩罚权重更新第一损失函数值以产生更新损失函数向量。
6.在本发明的一实施例中,上述的第二分期差异大于分期差异,并且第二惩罚权重大于第一惩罚权重。
7.在本发明的一实施例中,上述的第一惩罚权重与分期差异成正比。
8.在本发明的一实施例中,上述的训练数据报含标注了老年性黄斑部退化分期的眼底图。
9.在本发明的一实施例中,上述的损失函数向量对应于二进制互熵函数。
10.在本发明的一实施例中,上述的处理器基于机器学习算法计算对应于训练数据的归一化机率向量,根据眼底图的标注产生对应于老年性黄斑部退化分期的一位有效编码向量,并且将归一化机率向量以及一位有效编码向量输入至二进制互熵函数以产生损失函数
向量。
11.在本发明的一实施例中,上述的更新损失函数向量中的更新损失函数值包含第二损失函数值以及第一惩罚权重的第一商数。
12.在本发明的一实施例中,上述的更新损失函数值还包含第三损失函数以及第二惩罚权重的第二商数。
13.本发明的一种训练老年性黄斑部退化的分类模型的方法,包含:取得训练数据;基于机器学习算法计算对应于训练数据的损失函数向量,其中损失函数向量包含对应于老年性黄斑部退化的第一期的第一损失函数值以及对应于老年性黄斑部退化的第二期的第二损失函数值;根据第一期与第二期之间的分期差异产生第一惩罚权重;根据第二损失函数值以及第一惩罚权重更新第一损失函数值以产生更新损失函数向量;以及根据更新损失函数向量训练分类模型。
14.基于上述,本发明的电子装置可利用惩罚权重更新机器学习算法的损失函数值,并利用更新损失函数值训练分类模型。本发明可避免分类模型过度拟合并可提升分类模型的准确度。
附图说明
15.图1根据本发明的一实施例示出一种用于训练老年性黄斑部退化的分类模型的电子装置的示意图;
16.图2根据本发明的一实施例示出更新损失函数向量的示意图;
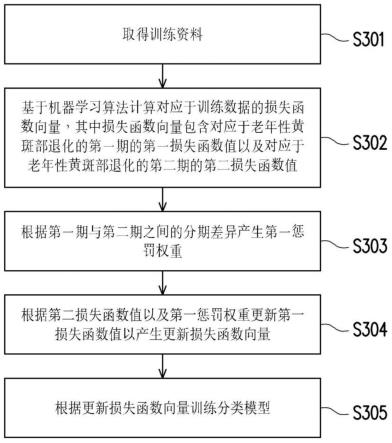
17.图3根据本发明的一实施例示出一种用于训练老年性黄斑部退化的分类模型的方法的流程图。
18.附图标记说明
19.100:电子装置;
20.110:处理器;
21.120:存储媒体;
22.130:收发器;
23.20:二进制互熵函数;
24.21:归一化机率向量;
25.22:一位有效编码向量;
26.23:损失函数向量;
27.24:权重矩阵;
28.25:更新损失函数向量;
29.s301、s302、s303、s304、s305:步骤。
具体实施方式
30.现将详细地参考本发明的示范性实施例,示范性实施例的实例说明于附图中。只要有可能,相同元件符号在附图和描述中用来表示相同或相似部分。
31.用于分类老年性黄斑部退化的分类模型可基于医疗人员所标注的训练数据(例如:标注了老年性黄斑部退化分期的眼底图)而产生。然而,医疗人员所决定的训练数据的
标注不一定是正确的。例如,医疗人员有可能将老年性黄斑部退化的第一期分类为老年性黄斑部退化的第二期。如果分类模型过于专注于为这些容易被混淆的数据进行分类,则分类模型可能因过度拟合而丧失泛化能力(generalization ability)。据此,本发明提出了一种训练老年性黄斑部退化的分类模型的方法,可避免训练出过度拟合的分类模型。
32.图1根据本发明的一实施例示出一种用于训练老年性黄斑部退化的分类模型的电子装置100的示意图。电子装置100可包含处理器110、存储媒体120以及收发器130。分类模型可用以将输入数据分类为老年性黄斑部退化的第一期、第二期、第三期或第四期。
33.处理器110例如是中央处理单元(central processing unit,cpu),或是其他可程序化的一般用途或特殊用途的微控制单元(micro control unit,mcu)、微处理器(microprocessor)、数字信号处理器(digital signal processor,dsp)、可程序化控制器、特殊应用集成电路(application specific integrated circuit,asic)、图形处理器(graphics processing unit,gpu)、图像信号处理器(image signal processor,isp)、图像处理单元(image processing unit,ipu)、算数逻辑单元(arithmetic logic unit,alu)、复杂可程序逻辑装置(complex programmable logic device,cpld)、现场可程序化逻辑门阵列(field programmable gate array,fpga)或其他类似组件或上述组件的组合。处理器110可耦接至存储媒体120以及收发器130,并且存取和执行存储于存储媒体120中的多个模块和各种应用程序,藉以执行电子装置100的功能。
34.存储媒体120例如是任何型态的固定式或可移动式的随机存取内存(random access memory,ram)、只读存储器(read-only memory,rom)、闪存(flash memory)、硬盘(hard disk drive,hdd)、固态硬盘(solid state drive,ssd)或类似组件或上述组件的组合,而用于存储可由处理器110执行的多个模块或各种应用程序。
35.收发器130以无线或有线的方式传送及接收信号。收发器130还可以执行例如低噪声放大、阻抗匹配、混频、向上或向下频率转换、滤波、放大以及类似的操作。
36.处理器110可通过收发器130取得用于训练分类模型的训练数据集合,其中训练数据集合可包含多笔训练数据。训练数据例如是标注了老年性黄斑部退化分期的眼底图。
37.图2根据本发明的一实施例示出更新损失函数向量23的示意图。分类模型例如是一种机器学习模型。处理器110可基于机器学习算法计算对应于训练数据的损失函数向量23。由于老年性黄斑部退化包含第一期、第二期、第三期以及第四期,故损失函数向量23可包含分别对应于第一期、第二期、第三期以及第四期的四个损失函数值。然而,本发明不限于此。例如,损失函数向量23可包含任意数量的损失函数值。在本实施例中,损失函数向量23可表示为[e(1)e(2)e(3)e(4)],其中e(1)为对应于第一期的损失函数值,e(2)为对应于第二期的损失函数值,e(3)为对应于第三期的损失函数值,并且e(4)为对应于第四期的损失函数值。
[0038]
机器学习算法的损失函数例如是二进制互熵(binary cross entropy)函数20。处理器110可根据二进制互熵函数20产生损失函数向量23。具体来说,在训练分类模型的过程中,机器学习算法的softmax函数可输出归一化机率向量21,其中归一化机率向量21可包含分别对应于第一期、第二期、第三期以及第四期的四个归一机率。然而,本发明不限于此。例如,归一化机率向量21可包含任意数量的归一机率。在本实施例中,归一化机率向量21可表示为[p(1)p(2)p(3)p(4)],其中p(1)为第一期的归一机率,p(2)为第二期的归一机率,p(3)
为第三期的归一机率,并且p(4)为第四期的归一机率。归一机率属于0到1的闭区间(closed interval),如方程式(1)所示,其中p(j)为老年性黄斑部退化的第j期的归一机率。
[0039]
p(j)∈[0,1]
…
(1)
[0040]
另一方面,处理器110可根据训练数据(即:标注了老年性黄斑部退化分期的眼底图)的标注产生对应于老年性黄斑部退化分期的一位有效编码(one-hot encoding)向量22。一位有效编码向量22可包含分别对应于第一期、第二期、第三期以及第四期的四个编码值。然而,本发明不限于此。例如,一位有效编码向量22可包含任意数量的编码值。在本实施例中,一位有效编码向量22可表示为[c(1)c(2)c(3)c(4)],其中c(1)为第一期的编码值,c(2)为第二期的编码值,c(3)为第三期的编码值,并且c(4)为第四期的编码值。编码值可为“0”或“1”。一位有效编码向量22可包含一个编码值“1”以及三个编码值“0”,其中编码值“1”对应于标注在训练数据的老年性黄斑部退化分期,并且编码值“0”对应于未被标注在训练数据的老年性黄斑部退化分期。举例来说,若训练数据被标注为第三期,则一位有效编码向量22可表示为[0 0 1 0]。
[0041]
在取得归一化机率向量21以及一位有效编码向量22后,处理器110可将归一化机率向量21以及一位有效编码向量22输入至二进制互熵函数20以产生损失函数向量23。
[0042]
一般来说,分期差异(stage difference)的绝对值较小的两期较难以区别。分期差异的绝对值较大的两期较容易区别。举例来说,将眼底图分类为第一期以及第二期的其中之一的难度大于将眼底图分类为第一期以及第三期的其中之一的难度。换句话说,第一期被误判为第二期的机率较高,而第一期被误判为第三期的机率较低。分类模型过度专注于区分分期差异较小的分期可能导致过度拟合发生。为了避免分类模型的过度拟合,处理器110可利用惩罚权重来更新分类模型的损失函数值,并且根据更新损失函数值训练分类模型。
[0043]
具体来说,处理器110可将损失函数向量23与权重矩阵24相乘以产生更新损失函数向量25,并且根据更新损失函数向量25训练分类模型。更新损失函数向量25的尺寸可与损失函数向量23的尺寸相同。假设损失函数向量23表示为[e(1)e(2)e(3)e(4)],则处理器110可根据方程式(2)计算更新损失函数向量25,其中m为权重矩阵24,并且[e(1)’e(2)’e(3)’e(4)’]为更新损失函数向量25。更新损失函数向量25可包含第一期的更新损失函数e(1)’,第二期的更新损失函数e(2)’,第三期的更新损失函数e(3)’以及第四期的更新损失函数e(4)’。
[0044]
[e(1)
′
e(2)
′
e(3)
′
e(4)
′
]=[e(1) e(2) e(3) e(4)]
·m…
(2)
[0045]
更新损失函数向量25中的更新损失函数值可以方程式(3)表示,其中e(i)’代表第i期的更新损失函数值(或更新损失函数向量25的第i行的元素),e(j)代表第j期的损失函数值(或损失函数向量23的第j行的元素),a(i,j)代表对应于第i期和第j期的误差权重,并且b(i,j)代表对应于第i期和第j期的惩罚权重。i或j属于1到4的闭区间(即:i∈[1,4]且j∈[1,4])。不同分期的误差权重可以相同或相异。
[0046]
e(i)
′
=∑
j,j≠i
e(j)
·
(a(i,j) b(i,j))
…
(3)
[0047]
如方程式(3)所示,处理器110可根据损失函数值e(2)、损失函数值e(3)或损失函数值e(4)来产生更新损失函数值e(1)’。举例来说,更新损失函数值e(1)’可包含损失函数值e(2)与惩罚权重b(1,2)的商数e(1)
·
b(1,2)、损失函数值e(3)与惩罚权重b(1,3)的商数
e(3)
·
b(1,3)以及损失函数值e(4)与惩罚权重b(1,4)的商数e(4)
·
b(1,4)。
[0048]
处理器110可根据第i期和第j期之间的分期差异(即:i-j)计算对应于第i期和第j期的惩罚权重b(i,j)。在一实施例中,惩罚权重b(i,j)可与第i期和第j期之间的分期差异(即:i-j)的绝对值成正比,如方程式(4)所示。举例来说,由于第一期与第三期之间的分期差异|1-3|大于第一期与第二期之间的分期差异|1-2|,故对应于第一期与第三期的惩罚权重b(1,3)大于对应于第一期与第二期的惩罚权重b(1,2)。
[0049]
b(i,j)
∝
|i-j|
…
(4)
[0050]
假设每个误差权重a(i,j)均等于1,并且惩罚权重b(i,j)等于第i期和第j期之间的分期差异乘以0.1(如方程式(5)所示)。据此,则方程式(2)中的权重矩阵24可以方程式(6)表示。处理器110可将损失函数向量23与权重矩阵24相乘以产生更新损失函数向量25。在取得更新损失函数向量25后,处理器110可根据更新损失函数向量25训练老年性黄斑部退化的分类模型。
[0051]
b(i,j)=0.1
·
|i-j|
…
(5)
[0052][0053]
图3根据本发明的一实施例示出一种用于训练老年性黄斑部退化的分类模型的方法的流程图,其中所述方法可由如图1所示的电子装置100实施。在步骤s301中,取得训练数据。在步骤s302中,基于机器学习算法计算对应于训练数据的损失函数向量,其中损失函数向量包含对应于老年性黄斑部退化的第一期的第一损失函数值以及对应于老年性黄斑部退化的第二期的第二损失函数值。在步骤s303中,根据第一期与第二期之间的分期差异产生第一惩罚权重。在步骤s304中,根据第二损失函数值以及第一惩罚权重更新第一损失函数值以产生更新损失函数向量。在步骤s305中,根据更新损失函数向量训练分类模型。
[0054]
综上所述,本发明的电子装置可利用惩罚权重更新机器学习算法的损失函数值。电子装置可利用其他分类的损失函数值来更新特定分类的损失函数值。若所述其他分类与所述特定分类是容易被混淆的分类,则电子装置给予所述其他分类较低的惩罚权重。若所述其他分类与所述特定分类是不容易被混淆的分类,则电子装置给予所述其他分类较高的惩罚权重。如此,由更新损失函数值所训练出的分类模型将不会因过度专注于区分容易被混淆的分类而导致过度拟合。据此,本发明的电子装置可提升分类模型的准确度。
[0055]
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
