一种基于transformer时空特征学习的运动想象脑电解码方法
技术领域
1.本发明涉及一种基于transformer时空特征学习的运动想象脑电解码方法,属于运动想象脑电技术领域。
背景技术:
2.脑机接口(brain computer interface,bci)是基于大脑皮层或头皮表面产生的神经活动进行的,它不依赖于周围神经和人体肌肉的大脑组织的运行通路,可以直接把人头皮表面上提取到的脑电信息转换为对外部设备的控制命令,从而实现大脑与外部设备之间的通信。运动想象脑电图(motor imageryelectroencephalogram,mi-eeg)是一种无需外部刺激的自我调节的脑电图,可通过电极检测到。bci的一个主要挑战是从大脑活动中解释运动意图。高效的神经解码算法可以显著提高解码精度,从而提高bci的性能。脑电信号的低信噪比、非线性、非平稳性等特点导致分类精度较低,为脑电解码带来了很大的挑战。因此,从预处理的脑电信号中提取特征以区分不同动作的脑电信号是bci技术中最重要的部分,即脑电信号的特征提取与分类。
3.近些年来,深度学习的方法被大量应用于脑电信号的分类,它可以使用深度架构从原始mi-eeg数据中自动学习高级和潜在的复杂特征,消除了手工特征提取的需要。卷积神经网络(convolutional neural networks,cnn)因其强大的局部特征学习能力而被广泛应用,但cnn的性能依赖于每一层卷积核的选择,大的卷积核会阻碍深层cnn的利用率,而小的卷积核则限制了cnn的感受野,如果没有相当深的结构,很难感知信号内部广泛的关系,这可能会导致大量的计算。研究者引入了循环神经网络(recurrent neural network,rnn)和长短时记忆网络(long-short term memory,lstm)的eeg信号分析方法,但是,这些方法仍然不足以处理更多的扩展数据,并且rnn只作用于先前的记忆和当前的状态。虽然lstm能够捕获长距离依赖信息,但是无法并行计算,而卷积神经网络(cnn)能够并行计算,但是无法捕获长距离依赖信息,它需要通过层叠或者扩张卷积核来增大感受野。而transformer模型在长序列特征相关性计算和模型可视化与可解释性方面优于其他模型,在处理长期依赖关系方面表现出更优的性能。
技术实现要素:
4.本发明要解决的技术问题是提出一种基于transformer时空特征学习的运动想象脑电解码方法,从而解决上述问题。
5.本发明的技术方案是:一种基于transformer时空特征学习的运动想象脑电解码方法,具体步骤为:
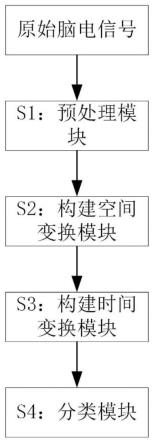
6.step1:构建预处理模块,对原始的运动想象脑电信号进行滤波处理。
7.step2:构建空间变换模块,所述空间变换模块的输入数据为step1输出的预处理后的运动想象脑电数据,所述空间变换模块的输出是提取后的空间特征。
8.step3:构建时间变换模块,所述时间变换模块的输入数据为step2输出的空间特征,所述时间变换模块的输出是运动想象脑电数据的时间特征。
9.step4:构建分类模块。所述分类模块的输入为step2和step3学习到的时空特征输入到分类器得到运动想象分类结果。
10.所述的预处理为根据fbcsp的思想对原始的运动想象脑电信号进行滤波处理,并将多个ovr的输出进行叠加作为空间变换模块的输入。
11.将step1得到的预处理的运动想象脑电信号经过卷积核为51,步长为1的卷积层对位置信息进行编码,位置编码后的输出作为空间变换模块的输入,然后将经过位置编码和空间变换后的特征序列作为多头注意力模型的输入。多头注意力模块是由3个相同的编码器层堆叠而成,每一层由5个注意力层和由两个完全连接层组成的前馈神经网络两个子层构成,两个子层的输出都经过层归一化和残差连接。
12.所述的空间变换模块为采用缩放点积注意力机制对特征通道进行加权,以获取通道之间的相关性。
13.所述加权具体为:
14.先将输入数据分别与三个不同的权重矩阵相乘得到查询(query)向量q、键(key)向量k和值(value)向量v,这三个权重矩阵大小相同,然后按公式(1)计算加权值,q与k点乘的结果,再除以缩放因子进行归一化,再通过softmax函数,对应的就是各个通道之间的相互关联程度,然后乘上对应的矩阵v,得到最后的加权结果,即通道加权的表示,矩阵q代表将用于匹配的每个通道,矩阵k代表使用点积的所有其他通道。
[0015][0016]
其中,attention(q,k,v)是加权表示,查询向量q、键向量k和值向量v是由向量打包的矩阵,作为缩放点积注意力模块的输入。
[0017]
所述时间变换模块采用多头注意力机制模块,从不同的角度感知脑电信号的全局时间依赖关系,对经过空间模块压缩的数据进行切片,然后分成5个更小的部分,即头部,将各部分的输出线性变换并进行串联连接,最后将得到的注意力向量作为输出,具体如公式(2)-(3)所示:
[0018]
mutihead(q,k,v)=concat(head1,
…
,headh)w0ꢀꢀꢀ
(2)
[0019]
headi=attention(qw
iq
,kw
ik
,vw
iv
)
ꢀꢀꢀ
(3)
[0020]
其中,concat是矩阵拼接函数,headi是第i个head的输出结果,h是head的个数,w0是最终输出的线性变换,w
iq
,w
ik
,w
iv
分别为q,k,v在第i个head上的线性变换。
[0021]
对所述step 4中和step3中提取的时空特征进行层归一化和平均池化,再输入到一个完全连接层进行分类,经过分类模块输出对应的分类标签,通过与真实标签比对计算损失函数,所述损失函数为交叉熵损失函数,具体如下所示:
[0022][0023]
其中,m是试验次数,n是类别数,第m次试验的真实标签,表示类别n第m次试验的预测概率。
[0024]
本发明的有益效果是:可以在有限数据的情况下学习脑电信号的特征,并取得了良好的分类精度,有效提高运动想象脑电信号的分类准确率。
附图说明
[0025]
图1是本发明步骤流程图;
[0026]
图2是本发明基于transformer的时空特征学习网络框图;
[0027]
图3是本发明实施例中受试者的分类结果的混淆矩阵图;
[0028]
图4是本发明实施例中受试者的训练损失和准确率曲线图。
具体实施方式
[0029]
下面结合附图和具体实施方式,对本发明作进一步说明。
[0030]
实施例1:如图1所示,一种基于transformer时空特征学习的运动想象脑电解码方法,具体步骤为:
[0031]
step1:本实施例采用的是2008年第四次国际脑机接口竞赛左右手运动想象的脑电信号数据集bcicompetitionivdataset 2a,所述的预处理为根据fbcsp的思想对原始的运动想象脑电信号进行滤波处理,以带宽为4hz在4-40hz的范围内将运动想象脑电信号分解为4-8hz、8-12hz、12-16hz、
…
、36-40hz共9个频带上的信号。由于传统的fbcsp只适用于二分类,本发明使用一对多(one vs rest,ovr)的分类策略来处理多分类的任务,其原理是将多类任务中的每一类都分别与其他类区分。
[0032]
首先,fbcsp使用由chebyshevⅱ型滤波器构成的滤波器组将其分解成b个频带的信号,即b(1≤b≤9)个带通滤波器,将mi-eeg信号分成b个不同频带范围的mi-eeg,将第b个带通滤波器得到的mi-eeg用eb表示,然后分别对每个频带成分计算“二分类”csp投影矩阵wb,得到滤波器其中每类mi任务分别包含n(n=72)个实验数据。
[0033]
具体过程如下:
[0034]
step1.1:首先计算第b个滤波器的“两类”mi-eeg中每个实验的协方差矩阵:
[0035][0036]
其中,trace(x)代表矩阵x的对角线元素之和,t为转置运算符。
[0037]
step1.2:通过一类和“剩余”类的平均协方差和得到所有实验的混合空间协方差c
bc
:
[0038][0039]
其中,c
bo
为其中一类的协方差矩阵,c
bo
为“剩余”类的协方差矩阵,n为“剩余类别”的实验数据。
[0040]
step1.3:对混合空间协方差矩阵进行特征值分解:
[0041][0042]
其中,u
bc
为特征向量矩阵,λ
bc
为特征值对角矩阵。
[0043]
step1.4:构造白化矩阵pb和空间系数矩阵sb:
[0044][0045][0046][0047]
其中,s
bo
为其中一类的空间系数矩阵,s
br
为“剩余”类的空间系数矩阵。
[0048]
step1.5:利用s
bo
和s
br
具有的相同的特征向量构成矩阵bb对其进行分解:
[0049][0050][0051]
其中,λ
bo
和λ
br
为特征值对角阵。
[0052]
step1.6:计算投影矩阵wb,得到经过空间滤波后的脑电信号zb:
[0053][0054][0055]
其中,zb是过滤数据,是多个子滤波器叠加构成的最终空间滤波器。
[0056]
step2:如图2所示,所述的位置编码层采用卷积核为51,步长为1的卷积层对位置信息进行编码,位置编码后的输出作为空间变换模块的输入。所述的空间变换模块是采用缩放点积注意力机制对特征通道进行加权,以获取通道之间的相关性。先将输入数据分别与三个不同的权重矩阵相乘得到查询(query)向量q、键(key)向量k和值(value)向量v,这三个矩阵大小相同,按公式(11)计算加权值。q与k点乘的结果,再除以缩放因子进行归一化,再通过softmax函数,对应的就是各个通道之间的相互关联程度,然后乘上对应的矩阵v,得到最后的加权结果,即通道加权的表示。矩阵q代表将用于匹配的每个通道,矩阵v代表使用点积的所有其他通道。
[0057][0058]
其中,attention(q,k,v)是加权表示,查询向量q、键向量k和值向量v是由向量打包的矩阵,作为缩放点积注意力模块的输入。
[0059]
step3:所述的时间特征是采用多头注意力机制模块,从不同的角度感知脑电信号的全局时间依赖关系。对经过空间模块压缩的数据进行切片,然后分成5个更小的部分,即头部。将各部分的输出线性变换并进行串联连接,最后将得到的注意力向量作为输出。具体公式如(12)-(13)所示:
[0060]
mutihead(q,k,v)=concat(head1,
…
,headh)w0ꢀꢀꢀ
(12)
[0061]
headi=attention(qw
iq
,kw
ik
,vw
iv
)
ꢀꢀꢀ
(13)
[0062]
其中,concat是矩阵拼接函数;headi是第i个head的输出结果,h是head的个数;w0是最终输出的线性变换;w
iq
,w
ik
,w
iv
分别为q,k,v在第i个head上的线性变换。
[0063]
针对本发明的多头注意力模块是由3个相同的编码器层堆叠而成,每一层由5个注意力层和由两个完全连接层组成的前馈神经网络两个子层构成,两个子层的输出都经过层归一化和残差连接。残差连接层主要是进行残差连接,该方法有效解决了梯度消失和梯度
爆炸的问题;ln正则化层主要作用是对输入数据进行归一化处理;前馈网络模块(feed-forward network,ffn)由两层前馈神经网络组成。
[0064]
step4:将step2和step3提取的时空特征进行层归一化和平均池化后,输入到一个完全连接层通过softmax分类器进行分类。经过分类模块输出对应的分类标签,通过与真实标签比对计算损失函数,所述损失函数采用交叉熵损失函数,具体公式如下所示:
[0065][0066]
其中,m是试验次数,n是类别数,第m次试验的真实标签,表示类别n第m次试验的预测概率。
[0067]
具体实施中,本发明的网络模型与c2cm、eegnet以及fbsf-tscnn模型进行对比,将测试集的平均识别精度作为评价指标,当识别精度越高,模型的识别能力越好。9名受试者的分类正确率和kappa值如下表:
[0068][0069]
表1:其现有方法在不同受试者的正确率与kappa系数
[0070]
图3展示了受试者a03、a07、a08、a09分类结果的混淆矩阵,图4展示了4个受试者a03、a07、a08、a09的训练损失和准确率曲线。结果分析:
[0071]
表1实验结果表明,与现有的方法相比,基于fbcsp和transformer的时空特征学习的运动想象脑电解码模型分类精度对于9个受试者都有提高。此外,从图3和图4中可以发现,本发明整体性能是可信的,对于不同类别具有良好的分类能力,并且没有太多的偏差。
[0072]
综上所述,本发明可以在有限数据的情况下学习eeg的特征,并取得了良好的分类精度。
[0073]
以上结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。