1.本发明涉及自然语言处理技术领域,涉及一种中文分词(cws)的方法,尤其涉及一种基于多模态主动学习的中文分词方法。
背景技术:
2.中文分词作为中文自然语言处理领域的重要研究内容之一,广泛应用于命名实体识别、词性标注和机器翻译等领域,是许多中文自然语言处理任务的首要预处理环节。近年来,随着深度学习的迅猛发展,中文分词已实现96%-98%的高性能表现。而这往往需要大规模高精度标注数据作为训练依据,但大规模数据的标注工作量是难以想象的。同时在医学影像、国防安全等领域,获取大规模未标注数据集已是非常困难的,更不必说完成高精度的数据标注工作。针对以上问题,学者通常利用主动学习策略,选择有代表性的未标注样本,经过人工标注后与少量已标注样本一起作为训练数据,在最小化数据标注代价的基础上实现高性能的分词表现。但是这些基于传统主动学习策略的方法往往无法与深度预训练模型相结合,利用深度学习的优势,改善分词性能。同时在新闻访谈和新闻实录等场景下,除了文本数据,还存在音频和视频等其他模态数据,主流中文分词方法仅使用文本数据作为模型输入的做法似乎也不是一个非常好的选择。
技术实现要素:
3.基于现有分词方法的不足,本发明提出一种多模态主动学习的中文分词方法,该方法将主动学习策略融入深度学习,构造多样性预测模块预测样本信息量,选择富含信息的未标注样本进行人工标注,与已标注样本进行迭代训练。同时区别于目前仅使用文本特征作为输入的分词方法,利用文本特征和音频特征作为输入。而且本发明进一步融入依存句法信息,使用异构图注意力网络提取句法结构特征,缓解标注数据匮乏问题。
4.为了实现上述目的,本发明提供的技术方案如下:一种基于多模态主动学习的中文分词方法,所述方法包括如下步骤:
5.步骤1、使用bert模型对文本序列处理得到文本特征;
6.1-1对于文本序列c={c1,c2,
…
,cn},在其前后插入特殊标记[cls]和[sep],接着传入bert模型,得到文本特征x={x1,x2,
…
,xn}。
[0007]
步骤2、使用音频处理工具librosa和resnet模型对音频序列处理得到音频特征;
[0008]
2-1对于文本序列对应的音频数据,使用蒙特利尔强制对齐器提取音素和字符的精确时间戳以对齐文本和音频数据。
[0009]
2-2使用音频处理工具libr0sa对音频数据进行处理,提取mfcc特征。
[0010]
2-3使用resnet模型对音频序列s={s1,s2,...,sn}进行处理,得到音频特征a={a1,a2,...,an}。
[0011]
步骤3、使用句法解析器stanfordparser对文本序列处理得到句法结构图,利用异构图注意力网络处理句法结构图提取句法结构特征,使用注意力机制融合句法结构特征和
文本特征,得到句法文本特征;
[0012]
3-1使用句法解析器stanfordparser对文本序列c={c1,c2,...,cn}进行处理,得到依存句法结构图。
[0013]
3-2使用异构图注意力网络对依存句法结构图进行特征提取,得到句法结构图特征v={v1,v2,...,vm}。
[0014]
3-3使用注意力机制融合文本特征和句法结构图特征,获取句法文本特征,具体公式如下:
[0015][0016][0017]
其中,σ(
·
)表示激活函数,α
ij
表示字符i对句法结构图中节点j的注意力权重,m表示句法结构图节点总数,ffn(
·
)表示前馈神经网络,oi表示字符i的句法文本向量表示。
[0018]
步骤4、使用多模态交互模块,融合句法文本特征和音频特征,得到多模态字符向量表示;
[0019]
4-1使用标准lstm捕获句法文本和音频向量表示的隐藏状态,具体公式如下:
[0020][0021][0022]
4-2采用多头线性注意力门控机制控制隐藏状态不同维度的贡献,具体公式如下:
[0023][0024][0025][0026]
其中,由和拼接而来,和是投射矩阵,和是线性投射矩阵。l表示线性注意力层数,d表示的维度大小,hi表示第i个字符的多模态向量表示。此外,按照句法文本和音频特征的各自维度将hi拆分成和用于获取下一个字符的多模态向量表示,linearma(
·
)表示多头线性注意力门控机制,用以挖掘不同模态的不同维度重要性。
[0027]
步骤5、使用crf输入多模态字符向量表示,实现条件序列标注;
[0028]
5-1将多模态字符向量表示输入crf,获取字符预测标签,具体公式如下:
[0029][0030]
其中,表示输入crf的多模态字符向量表示,n表示字符总数,和为特征函数,y表示所有可能预测标签序列。
[0031]
步骤6、使用多样性预测模块输入多模态字符向量表示,获取样本所含信息量;
[0032]
6-1对多模态字符向量表示取平均,获取句子级别多模态向量表示。具体公式如下:
[0033]
sk=mean(h
k1
,h
k2
,
…
,h
kn
)
[0034]
其中,h
ki
表示第k个样本的第i个字符,mean(
·
)表示平均函数,sk表示第k个样本的句子级别多模态向量表示;
[0035]
6-2使用多层前馈神经网络,输入句子级别多模态向量表示,预测样本所含信息量。具体公式如下:
[0036][0037]
其中,表示样本预测信息量,ffn(
·
)表示多层前馈神经网络;
[0038]
6-3训练阶段,对一个minibatch的n个样本的句子级别多模态向量表示,使用dropout相似样本构造方法,构造样本的相似句子级别多模态向量表示。具体公式如下:
[0039]sk n
=dropout(sk)
[0040]
其中,s
k n
表示第k个样本的相似句子级别多模态向量表示,dropout(
·
)表示对向量不同维度值按照特定概率置零;
[0041]
6-4训练阶段,利用数据增强后的2n个句子级别多模态向量表示,构造样本信息量伪标签,具体公式如下:
[0042][0043]
其中,sim(v,u)=v
t
·
u/||v||||u||表示12范数归一化内积,τ表示温度系数,rk表示第k个样本的信息量伪标签;
[0044]
6-5训练阶段,使用crf损失函数计算分词模块损失,使用均方误差计算样本信息量预测损失。具体公式如下:
[0045][0046]
其中,λ表示样本信息量预测损失权重。
[0047]
该方案为了降低多样性预测模块学习代价,本发明将其与其他分词模块一起进行联合学习。通过实验表明,本发明在减少数据标注代价的基础上,在中文分词的各方面性能都较其他基线方法有了一定提升。为了更好融合音频特征和句法文本特征,构造基于线性注意力机制的轻量混合长短时记忆门控模块,进行音频和句法文本特征的跨模态信息交互得到多模态字符向量表示,用于输入crf进行分词。
[0048]
相对于现有技术,本发明的有益效果如下:
[0049]
1)本发明将主动学习策略融入深度学习,利用多样性预测模块,预测样本所含信息量,以选择信息量最为丰富的样本进行人工标注,与已标注样本一起迭代训练,在最小化数据标注代价的基础上尽可能降低对分词效果的影响。
[0050]
2)模型区别于以往仅使用文本特征作为输入的分词方法,使用音频特征作为模型补充输入,利用声学信息帮助分词。
[0051]
3)本发明仅提取梅尔倒谱频率系数特征用于音频特征提取,缓解音频特征工程工作量,减少额外工作消耗。
[0052]
4)本发明模型使用依存句法信息作为补充信息,利用异构图注意力网络提取句法结构特征,使用注意力机制融合句法结构特征和文本特征,获取句法文本特征,进一步缓解标注语料匮乏的问题。
附图说明
[0053]
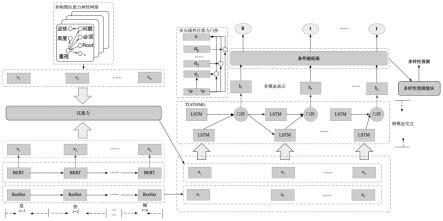
图1是本发明模型架构图。
具体实施方式
[0054]
下面结合附图对本发明的技术方案作进一步说明。
[0055]
实施例1:如图1所示,一种基于多模态主动学习的中文分词方法,具体实现步骤如下:
[0056]
步骤1、使用bert模型对文本序列处理得到文本特征;
[0057]
1-1对于文本序列c={c1,c2,...,cn},在其前后插入特殊标记[cls]和[sep],接着传入bert模型,得到文本特征x={x1,x2,...,xn}。
[0058]
步骤2、使用音频处理工具librosa和resnet模型对音频序列处理得到音频特征;
[0059]
2-1对于文本序列对应的音频数据,使用蒙特利尔强制对齐器提取音素和字符的精确时间戳以对齐文本和音频数据;
[0060]
2-2使用音频处理工具librosa对音频数据进行处理,提取mfcc特征;
[0061]
2-3使用resnet模型对音频序列s={s1,s2,...,sn}进行处理,得到音频特征a={a1,a2,...,an};
[0062]
步骤3、使用句法解析器stanfordparser对文本序列处理得到句法结构图,利用异构图注意力网络处理句法结构图提取句法结构特征,使用注意力机制融合句法结构特征和文本特征,得到句法文本特征;
[0063]
3-1使用句法解析器stanfordparser对文本序列c={c1,c2,...,cn}进行处理,得到依存句法结构图。
[0064]
3-2使用异构图注意力网络对依存句法结构图进行特征提取,得到句法结构图特征v={v1,v2,...,vm}。
[0065]
3-3使用注意力机制融合文本特征和句法结构图特征,获取句法文本特征,具体公式如下:
[0066][0067][0068]
其中,σ(
·
)表示激活函数,α
ij
表示字符i对句法结构图中节点j的注意力权重,m表示句法结构图节点总数,ffn(
·
)表示前馈神经网络,oi表示字符i的句法文本向量表示。
[0069]
步骤4、使用多模态交互模块,融合句法文本特征和音频特征,得到多模态字符向量表示;
[0070]
4-1使用标准lstm捕获句法文本和音频向量表示的隐藏状态,具体公式如下:
[0071][0072][0073]
4-2采用多头线性注意力门控机制控制隐藏状态不同维度的贡献,具体公式如下:
[0074][0075][0076]
其中,由和拼接而来,和是投射矩阵,和是线性投射矩阵。l表示线性注意力层数,d表示的维度大小,hi表示第i个字符的多模态向量表示。此外,按照句法文本和音频特征的各自维度将hi拆分成和用于获取下一个字符的多模态向量表示。linearma(
·
)表示多头线性注意力门控机制,用以挖掘不同模态的不同维度重要性。
[0077]
步骤5、使用crf输入多模态字符向量表示,实现条件序列标注;
[0078]
5-1将多模态字符向量表示输入crf,获取字符预测标签。具体公式如下:
[0079][0080]
其中,表示输入crf的多模态字符向量表示,n表示字符总数,和为特征函数,y表示所有可能预测标签序列。
[0081]
步骤6、使用多样性预测模块输入多模态字符向量表示,获取样本所含信息量;
[0082]
6-1对多模态字符向量表示取平均,获取句子级别多模态向量表示。具体公式如下:
[0083]
sk=mean(h
k1
,h
k2
,
…
,h
kn
)
[0084]
其中,h
ki
表示第k个样本的第i个字符,mean(
·
)表示平均函数,sk表示第k个样本的句子级别多模态向量表示。
[0085]
6-2使用多层前馈神经网络,输入句子级别多模态向量表示,预测样本所含信息量。具体公式如下:
[0086][0087]
其中,表示样本预测信息量,ffn(
·
)表示多层前馈神经网络。
[0088]
6-3训练阶段,对一个minibatch的n个样本的句子级别多模态向量表示,使用dropout相似样本构造方法,构造样本的相似句子级别多模态向量表示。具体公式如下:
[0089]sk n
=dropout(sk)
[0090]
其中,s
k n
表示第k个样本的相似句子级别多模态向量表示,dropout(
·
)表示对向量不同维度值按照特定概率置零。
[0091]
6-4训练阶段,利用数据增强后的2n个句子级别多模态向量表示,构造样本信息量伪标签。具体公式如下:
[0092][0093]
其中,sim(v,u)=v
t
·
u/||v||||u||表示12范数归一化内积,τ表示温度系数,rk表示第k个样本的信息量伪标签。
[0094]
6-5训练阶段,使用crf损失函数计算分词模块损失,使用均方误差计算样本信息
量预测损失。具体公式如下:
[0095][0096]
其中,λ表示样本信息量预测损失权重。
[0097]
为了验证本发明相对于其他分词的优势,进行了一系列的对比实验。实验的步骤主要包括三个方面:数据准备、模型训练和模型测试。
[0098]
1)数据准备
[0099]
由于目前中文分词语料都为单模态文本语料,因此在进行实验之前,首先需要进行多模态中文分词语料的收集。本实验从“学习强国”新闻平台爬取了包含文本翻译的120段视频,将其分割成1831个句子。由于该新闻平台的视频画面主要是特定的新闻场景,而非说话者画面等对分词有意义的视频信息。因此,本实验仅考虑使用其中的文本数据和音频数据,利用ctb中文分词指南对语料进行标注。实验过程中,将标注语料按照6∶2∶2的比例划分为训练集1098个句子、测试集367个句子和验证集366个句子。然后,将训练集按照1∶9的比例划分为初始标注数据集110个句子,未标注数据集988个句子。表1展示了本实验多模态分词语料的统计情况。
[0100]
表1
[0101][0102]
2)模型训练
[0103]
为了证明本发明提出的基于多模态主动学习的中文分词方法的有效性,我们在相同数据集上选择如下基准模型与本发明提出的方法作为对比:
[0104]
·
ltp:该方法使用文本特征作为输入,利用bert作为文本编码器,使用crf作为解码器,主动学习策略使用结合句子级别和字符级别不确定性的least token probability(ltp)策略。
[0105]
·
our approach(w/o.tlsthmg):该方法使用文本特征和音频特征作为输入,使用异构图注意力网络提取依存句法特征,利用注意力机制融合依存句法特征和文本特征,获取句法文本特征,拼接句法文本特征和音频特征输入crf获得分词结果。主动学习策略使用
多样性预测模块对样本信息量进行预测。
[0106]
·
our approach:该方法为本发明提出的基于多模态主动学习的中文分词方法。
[0107]
3)实验结果
[0108]
将准备好的数据应用于上述模型,可得到如表2所示结果。结果中显示了训练后模型在测试集上的精确率(p)、召回率(r)及f1-measure,这些评价指标值越大则说明模型的表现越出色。
[0109]
表2
[0110][0111]
从表2可看到提出的基于多模态主动学习的中文分词方法要优于其他基准模型,取得了最优的结果。这主要是因为本发明提出的分词方法可以有效融合依存句法特征、文本特征和音频特征,同时借助多样性预测模块预测样本所含信息量,选择信息量丰富的样本进行人工标注,与已标注样本一起进行迭代训练,从而获得更好的分词效果。
[0112]
以上均为本发明的较佳实施例,并非依此限制本发明的保护范围,在上述基础上做出的等同替换或者替代,均应涵盖于本发明的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
