1.本发明属于智能交通预测领域,具体的说,是一种基于改进互补集合经验模态分解、改进麻雀搜索算法和双向门口循环单元网络的短时交通流组合模型智能预测方法及应用。
背景技术:
2.近年来,随着城市化进程的加快,城市人口密度的不断增大,车辆的普及在给人民百姓带来便利的同时,也为交通安全的保障增加了困难,由于交通拥堵所带来的交通事故等问题屡见不鲜。这一背景下,对城市道路交通系统进行管理与控制的智能交通控制系统应运而生。短时交通流预测也称为交通流量预测,是实现智能交通系统有效诱导和控制的关键一步,其研究对于提升道路管控水平和缓解路网交通压力具有重要的意义。
3.为了提高交通流量预测精度,各专家提出了许多行之有效的预测模型及算法。目前,交通流量预测方法主要分为两类:一是基于传统数学理论的交通流量预测算法,如历史平均法、卡尔曼滤波算法、灰度模型法等,这些方法大都利用统计学知识进行线性分析,难以应对复杂路网系统对交通流量序列产生的非线性、非平稳性以及时序相关性等特性,因此预测精度较差,对缓解交通压力作用有限;二是基于非线性系统理论的交通流量预测算法,如非线性回归算法、小波算法、混沌理论模型、突变理论模型等,其利用非线性方程描述强非线性曲线,但无法有效挖掘短时交通流内部的时序相关性,并且计算效率偏低导致训练速度过慢,在实际道路管控应用中存在时效性局限。以上两类预测方法,均未全面、综合地考虑在现实复杂交通路网中交通流量的交通流量时间序列的非线性、非平稳性以及时序相关性特征,并且模型方法训练收敛速度较慢。
4.基于以上分析,交通流量具有复杂的非线性、非平稳性和时序相关性等特征,而单一的预测模型和方法都有预测精度以及训练收敛速度等方面的限制性,在利用交通流量预测时存在较大的误差,难以精准反映道路交通状况,并且较长的训练速度对其辅助智能交通系统管控道路时存在时效性差的问题。
技术实现要素:
5.本发明是为了解决上述两类交通流量预测方法的不足,提出一种基于改进组合模型的交通流量预测方法及应用,以期能从非线性、非平稳性以及时序相关性三方面出发,提升智能交通模型的预测精度和预测速度,从而实时地为智能交通系统反映道路交通状况,辅助其提高道路管控水平,缓解路网交通压力。
6.为解决上述技术问题,本发明采用以下技术方案:
7.本发明一种基于改进组合模型的交通流量预测方法的特点在于,包括如下步骤:
8.步骤1:提取预测路段的原始交通流量数据并进行处理:
9.步骤1.1:利用交通流量传感器周期性采集预测路段处的交通流量数据,从而构建所述预测路段的历史交通流量数据库x
his
;
10.步骤1.2:从所述历史交通流量数据库x
his
中获取采样天数为d、单日采集的交通流量数据量为m的交通流量训练集x=(x1,x2,...,xi,...,xn)
t
,其中,xi表示第i个采样时刻的交通流量数据;n表示交通流量训练集的采样点总数,且n=d
×
m;
11.步骤2:基于边界局部特征延拓优化的互补集合经验交通流量模态分解:
12.步骤2.1:以交通流量训练集x中第1个采样点的交通流量数据x1作为x的左边界,寻找最靠近左边界的两个邻近交通流量极大值以及两个邻近交通流量极小值
13.利用式(1)对交通流量训练集x进行左边界相似性特征延拓,得到左边界处的延拓交通流量极大值延拓交通流量极小值以及最靠近左边界的第一个交通流量极大值与延拓交通流量极大值之间的时间间隔最靠近左边界的第一个交通流量极小值与延拓交通流量极小值之间的时间间隔延拓交通流量极大值的时序位置延拓交通流量极小值的时序位置
[0014][0015]
式(1)中,表示最靠近左边界的第一个交通流量极大值的时序位置;表示最靠近左边界的第二个交通流量极大值的时序位置;表示最靠近左边界的第一个交通流量极小值的时序位置;表示最靠近左边界的第二个交通流量极小值的时序位置;
[0016]
步骤2.2:以交通流量训练集x中第n个采样点的交通流量数据xn作为x的右边界,寻找最靠近右边界的两个邻近交通流量极大值以及两个邻近交通流量极小值
[0017]
利用式(2)对交通流量训练集序列x进行右边界相似性特征延拓,得到右边界的延拓交通流量极大值延拓交通流量极小值以及最靠近右边界的第一个交通流量极大值与延拓交通流量极大值之间的时间间隔最靠近右边界的第一个交通流量极小值与延拓交通流量极小值之间的时间间隔延拓交通流量极大值的时序位置延拓交通流量极小值的时序位置
[0018][0019]
式(2)中,n
max
表示交通流量训练集x中极大值的总个数;n
min
表示交通流量训练集x中极小值的总个数;表示第n
max-1个交通流量极大值;表示第n
max-1个交通流量极小值;表示交通流量极大值的时序位置;表示最靠近右边界的第一个交通流量极大值的时序位置;表示交通流量极小值的时序位置;t
min
表示最靠近右边界的第一个交通流量极小值的时序位置;
[0020]
利用式(3)得到延拓交通流量训练集f:
[0021][0022]
式(3)中,j表示当前采样时刻;
[0023]
步骤2.3:向延拓交通流量训练集f中先后加入符号相反的交通流量高斯白噪声序列
±nu
,从而利用式(4)得到第u次添加交通流量高斯白噪声序列得到的交通流量正噪声序列和负噪声序列
[0024][0025]
式(4)中,nu表示第u次添加的服从交通流量正态分布的高斯白噪声序列;u=1,2,...,o;o表示添加交通流量高斯白噪声序列的总次数;
[0026]
步骤2.4:利用式(5)将交通流量的正噪声序列和负噪声序列分别进行经验模态分解,得到交通流量正噪声序列的第v个正交通流量分量序列交通流量负噪声序列的第v个负交通流量分量序列
[0027][0028]
式(5)中,表示第v次运算的模态分解函数;v=1,2,...,m;m表示imf交通流量模态分量序列的总数;
[0029]
利用式(6)得到交通流量正噪声序列与正交通流量分量序列交通流量负
噪声序列与负交通流量分量序列的关系式:
[0030][0031]
式(6)中,表示第u次添加交通流量高斯白噪声序列后的正噪声序列分解后所得到的正交通流量残差分量序列;表示第u次添加交通流量高斯白噪声序列后的负噪声序列分解后所得到的负交通流量残差分量序列;
[0032]
步骤2.5:利用式(7)得到第v个imf交通流量模态分量序列imfv以及延拓交通流量训练集f与m个imf交通流量模态分量序列之间的关系式:
[0033][0034]
式(7)中,r表示延拓交通流量训练集f经过分解后所得的总交通流量残差分量;
[0035]
步骤3:利用改进的麻雀搜索算法优化双向门控循环单元预测模型的网络权值参数:
[0036]
步骤3.1:定义并初始化学习率lr、批样本数量b、最大迭代次数为maxiter,当前bigru网络迭代次数q=1;
[0037]
步骤3.2:构建由m个bigru预测子网络组成的双向门控循环单元预测模型,其中,任意第q个bigru预测子网由一组正、反向gru网络构成;设置正、反向gru网络中的门控循环单元个数均为n
gru
,正、反向gru网络中的神经元个数均为n
layers
,并在0-1范围内随机初始化第q个bigru预测子网络中待优化的权值参数集合其中,ω
q,r
和u
q,r
表示第q个bigru预测子网络中重置门rgq的权值系数;ω
q,z
和u
q,z
表示第q个bigru预测子网络中更新门ugq的权值系数;ω
q,xh
和ω
q,hh
表示第q个bigru预测子网络中候选隐含状态的网络权值系数;表示第q个正向gru网络中输出层的网络权值系数;表示第q个负向gru网络中输出层的网络权值系数;q=1,2,...,m;
[0038]
步骤3.3:基于第q个imf交通流量模态分量imfq,利用改进的麻雀搜索算法对第q个bigru预测子网络中待优化的权值参数择优,从而得到第q个bigru预测子网络中的最优权值参数集合其中,ω
q,r*
和u
q,r*
表示第q个bigru预测子网络中重置门rgq的最佳权值系数;ω
q,z*
和u
q,z*
表示第q个bigru预测子网络中更新门ugq的最佳权值系数;ω
q,xh*
和ω
q,hh*
表示第q个bigru预测子网络中候选隐含状态的最佳网络权值系数;表示第q个正向gru网络中输出层的最佳网络权值系数;
表示第q个负向gru网络中输出层的最佳网络权值系数;
[0039]
步骤3.4:判断q<m是否成立,若成立,则将q 1赋值给q后,返回步骤3.3顺序执行;否则,输出总的最优参数集合
[0040]
步骤4:利用改进麻雀搜索算法优化的双向门控循环单元网络对交通流量进行组合预测:
[0041]
步骤4.1:定义待预测交通流量数据的总数为n
*
,初始化q=1;
[0042]
步骤4.2:根据总的最优权值参数集合w
*
对m个bigru预测子网分别进行网络权值赋值,相应得到与各交通流量模态分量对应的m个性能最佳bigru交通流量预测模型;
[0043]
步骤4.3:将第q个imf交通流量模态分量imfq输入第q个最佳性能bigru交通流量预测模型中进行交通流量模态分量预测,并得到第q个imf交通流量模态分量imfq的预测序列其中,h
z,q
表示第q个imf交通流量模态分量imfq中第z个交通流量分量数据的预测值;
[0044]
步骤4.4:若q<m,则将q 1赋值给q后返回步骤4.3顺序执行,否则,表示得到m个分量预测序列{h1,h2,...,hq,...,hm}并进行加权重构,得到交通流量最终预测序列其中,yz表示第z个交通流量最终预测值,且
[0045]
本发明所述的基于改进组合模型的交通流量预测方法的特点也在于,所述步骤3.3的改进麻雀搜索算法包括如下步骤:
[0046]
步骤3.3.1:定义并初始化改进麻雀搜索算法的最大迭代次数iter
max
、参与搜索麻雀的数量np、预警值r2、权重调整参数ω
begin
、ω
end
、发现者数量pd及警戒者数量sd;
[0047]
初始化当前迭代次数为iter=1、当前权值参数的迭代次数h=1、当前参与搜索麻雀的迭代次数sp=1;
[0048]
定义并初始化第q个bigru预测子网络中第h个权值参数的第sp只麻雀的历史最优适应度值以及历史最优位置值从而利用式(8)得到第q个bigru预测子网络中第h个权值参数的历史最优适应度向量及历史最优位置向量
[0049][0050]
步骤3.3.2:随机初始化第iter次迭代时第sp只麻雀在训练第q个bigru中第h个网络权值参数时的位置并为np只麻雀随机赋予0-1之间的随机数;
[0051]
步骤3.3.3:将第q个imf交通流量模态分量imfq输入第q个bigru预测子网络中利用式(9)计算第q个bigru预测子网络中第h个权值参数的平均绝对误差,作为第q个bigru预测子网络中第h个权值参数的第iter-1次迭代的历史最佳适应度函数
[0052][0053]
式(9)中,表示第q个imf交通流量模态分量序列imfq中第iq个真实交通流量
模态分量值,表示第iter-1次迭代时将输入第q个bigru预测子网络中训练第h个权值参数时输出的第iq个交通分量预测值;
[0054]
步骤3.3.4:若则将赋值给第q个bigru网络中第h个权值参数的历史最优适应度值否则,历史最优适应度值不变;
[0055]
步骤3.3.5:利用式(10)得到第iter次迭代的线性动态自适应权重ω
iter
:
[0056][0057]
步骤3.3.6:利用式(11)得到第iter 1次迭代时训练第q个bigru中第h个网络权值参数时的第sp只发现者麻雀位置
[0058][0059]
式(11)中,exp(
·
)表示以自然常数e为底的指数函数;λ表示0-1之间的随机数;q表示服从正态分布的随机数;l表示全元素为1的1
×
d矩阵;st表示安全值;
[0060]
步骤3.3.7:根据式(12)得到第iter 1次迭代时训练第q个bigru中第h个网络权值参数时的第sp只追随者麻雀位置
[0061][0062]
式(12)中,表示第iter次迭代时第q个bigru网络中第h个网络权值参数时的全局最差位置;表示第iter 1次迭代时第q个bigru网络中第h个网络权值参数时发现者所占据的最优适应度位置;a
表示取值为-1至1的d
×
1矩阵,且a
=a
t
(aa
t
)-1
,其中,a表示元素为1或-1的1
×
d矩阵;
[0063]
步骤3.3.8:根据式(13)得到第iter 1次迭代时训练第q个bigru中第h个网络权值参数时的第sp只警戒者麻雀位置
[0064][0065]
式(13)中,表示第iter次迭代时第q个bigru网络中第h个网络权值参数的全局最优位置;β表示服从标准正态分布的随机数;k表示麻雀移动方向的步长控制;δ表示最小常数;表示第iter次迭代时训练第q个bigru网络中第h个权值参数时第sp只麻雀的当前适应度值;表示第q个bigru网络中第h个权值参数的历史最优适应度值;
表示第q个bigru网络中第h个权值参数的历史最差适应度值;
[0066]
步骤3.3.9:将赋值给第q个bigru网络中第h个权值参数的历史最优适应度值将历史最优位置同时将全局最优位置所对应的麻雀所赋予的随机数作为第q个bigru网络中第h个权值参数的最优权值参数;
[0067]
步骤3.3.10:将第q个imf交通流量模态分量imfq输入当前具备第h个最佳权值参数的第q个bigru预测子网络中进行预测,得到交通流量模态分量预测输出其中,表示第iter次迭代时将输入第q个bigru预测子网络中训练第h个权值参数时输出的第iq个交通分量预测值;
[0068]
步骤3.3.11:若iter<iter
max
,则将iter 1赋值给iter后返回步骤3.3.3顺序执行;否则,输出第h个最佳权值参数的值,并执行步骤3.3.12;
[0069]
步骤3.3.12:若h<8,则将h 1赋值给h后返回步骤3.3.3顺序执行;否则,输出第q个bigru预测子网络中的最优权值参数集合
[0070]
本发明一种电子设备,包括存储器以及处理器,其特点在于,所述存储器用于存储支持处理器执行所述方法的程序,所述处理器被配置为用于执行所述存储器中存储的程序。
[0071]
本发明一种计算机可读存储介质,计算机可读存储介质上存储有计算机程序,其特点在于,所述计算机程序被处理器运行时执行所述方法的步骤。
[0072]
本发明基于交通流量时间序列的复杂非线性、非平稳性以及时间依赖性三个方面的特点,与传统仅考虑其中一个或两个方面特点的预测方法相比,具备更好的交通流量预测精度以及速度,具体地说,本发明具有以下技术效果:
[0073]
1、由于神经网络模型难以挖掘交通流量序列中的先验信息并加以利用,从而造成预测交通流量数据资源浪费,本发明通过改进互补集合经验模态分解算法将其分解为一系列体现趋势性、周期性及随机性信息的本征交通流量序列分量,提取了交通流量序列中的先验特征,有效细化了复杂路网系统中交通流量序列的非线性及非平稳性信息,从而提高了对先验历史交通流量数据集的利用率;
[0074]
2、由于传统神经网络模型通常使用线性的梯度下降法进行参数训练,而梯度下降法在复杂路网系统中常常因交通流量序列中的非线性特性而发生梯度爆炸、梯度消失等问题,影响交通流量预测精度;而麻雀搜索算法摒弃梯度概念,采用元启发式思想进行参数寻优,有效避免了交通流量非线性带来的梯度问题,因此,本发明利用改进麻雀搜索算法替代bigru网络中梯度下降法对权值参数进行择优,并在标准ssa算法中引入线性动态自适应权重以提高全局搜索及局部开采能力,进一步提升了交通流量预测的精度以及训练速度。
[0075]
3、路网交通系统对交通流量的预测精度及时效性均有着较为严格要求,考虑到传统预测模型因其线性计算结构,往往无法全面考虑到交通流量序列中的非线性及时序相关性,而神经网络结构因其非线性映射功能对非线性交通流量序列的预测具有较大优势;同时,bigru网络的结构在lstm模型的基础上简化,实验效果相似但训练速度更快,因此,本发明利用改进麻雀搜索算法优化的双向门控循环单元网络深度挖掘交通流量序列中存在的
非线性及时序相关性,有效提高交通组合预测模型的学习能力以及预测精度的同时,保证了智能交通系统在交通流量预测时效方面的要求。
附图说明
[0076]
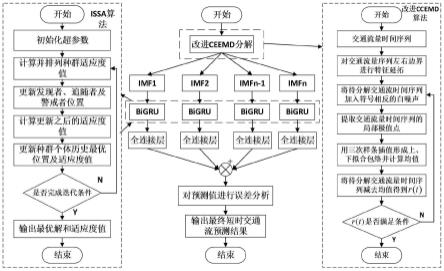
图1为本发明基于改进组合模型的交通流量预测方法结构图;
[0077]
图2为本发明基于改进组合模型的交通流量预测方法流程图;
[0078]
图3为本发明芜湖路与徽州大道交叉口东路采样点示意图;
[0079]
图4为本发明改进ceemd对交通流量序列模态分解后的结果图;
[0080]
图5为本发明2018年6月20日6:00至18:00时段内时间间隔5min交通流量预测结果图。
具体实施方式
[0081]
下面结合附图和实施例对本发明进行进一步详细说明。
[0082]
本实施例中,基于交通流量时间序列的复杂非线性、非平稳性以及时序相关性三方面特性,以提高交通流量预测模型的预测精度及收敛速度为目标,提出了一种基于改进互补集合经验模态分解、改进麻雀搜索算法和双向门口循环单元网络的短时交通流组合模型智能预测方法。如图1所示,具体的说,一种基于改进组合模型的交通流量预测方法,包括如下步骤:
[0083]
步骤1:提取预测路段的原始交通流量数据并进行处理:
[0084]
步骤1.1:利用交通流量传感器周期性采集预测路段处的交通流量数据,从而构建预测路段的历史交通流量数据库x
his
;
[0085]
步骤1.2:从历史交通流量数据库x
his
中获取采样天数为d、单日采集的交通流量数据量为m的交通流量训练集x=(x1,x2,...,xi,...,xn)
t
,其中,xi表示第i个采样时刻的交通流量数据;n表示交通流量训练集的采样点总数,且n=d
×
m;
[0086]
步骤2:基于边界局部特征延拓优化的互补集合经验交通流量模态分解:
[0087]
步骤2.1:以交通流量训练集x中第1个采样点的交通流量数据x1作为x的左边界,寻找最靠近左边界的两个邻近交通流量极大值以及两个邻近交通流量极小值
[0088]
利用式(1)对交通流量训练集x进行左边界相似性特征延拓,得到左边界处的延拓交通流量极大值延拓交通流量极小值以及最靠近左边界的第一个交通流量极大值与延拓交通流量极大值之间的时间间隔最靠近左边界的第一个交通流量极小值与延拓交通流量极小值之间的时间间隔延拓交通流量极大值的时序位置延拓交通流量极小值的时序位置
[0089][0090]
式(1)中,表示最靠近左边界的第一个交通流量极大值的时序位置;表示最靠近左边界的第二个交通流量极大值的时序位置;表示最靠近左边界的第一个交通流量极小值的时序位置;表示最靠近左边界的第二个交通流量极小值的时序位置;
[0091]
步骤2.2:采用步骤2.1相同原理,以交通流量训练集x中第n个采样点的交通流量数据xn作为x的右边界,寻找最靠近右边界的两个邻近交通流量极大值以及两个邻近交通流量极小值
[0092]
利用式(2)对交通流量训练集序列x进行右边界相似性特征延拓,得到右边界的延拓交通流量极大值延拓交通流量极小值以及最靠近右边界的第一个交通流量极大值与延拓交通流量极大值之间的时间间隔最靠近右边界的第一个交通流量极小值与延拓交通流量极小值之间的时间间隔延拓交通流量极大值的时序位置延拓交通流量极小值的时序位置
[0093][0094]
式(2)中,n
max
表示交通流量训练集x中极大值的总个数;n
min
表示交通流量训练集x中极小值的总个数;表示第n
max-1个交通流量极大值;表示第n
max-1个交通流量极小值;表示交通流量极大值的时序位置;表示最靠近右边界的第一个交通流量极大值的时序位置;表示交通流量极小值的时序位置;t
min
表示最靠近右边界的第一个交通流量极小值的时序位置;
[0095]
利用式(3)得到延拓交通流量训练集f:
[0096][0097]
式(3)中,j表示当前采样时刻;
[0098]
步骤2.3:向延拓交通流量训练集f中先后加入符号相反的交通流量高斯白噪声序列
±nu
,从而利用式(4)得到第u次添加交通流量高斯白噪声序列得到的交通流量正噪声序列和负噪声序列
[0099][0100]
式(4)中,nu表示第u次添加的服从交通流量正态分布的高斯白噪声序列;u=1,2,...,o;o表示添加交通流量高斯白噪声序列的总次数;
[0101]
步骤2.4:利用式(5)将交通流量的正噪声序列和负噪声序列分别进行经验模态分解,得到交通流量正噪声序列的第v个正交通流量分量序列交通流量负噪声序列的第v个负交通流量分量序列
[0102][0103]
式(5)中,表示第v次运算的模态分解函数;v=1,2,...,m;m表示imf交通流量模态分量序列的总数;
[0104]
利用式(6)得到交通流量正噪声序列与正交通流量分量序列交通流量负噪声序列与负交通流量分量序列的关系式:
[0105][0106]
式(6)中,表示第u次添加交通流量高斯白噪声序列后的正噪声序列分解后所得到的正交通流量残差分量序列;表示第u次添加交通流量高斯白噪声序列后的负噪声序列分解后所得到的负交通流量残差分量序列;
[0107]
步骤2.5:利用式(7)对第u个正噪声序列的第v个正交通流量分量序列负噪声序列的第v个负交通流量分量序列进行去平均值操作,得到第v个imf交通流量模态分量序列imfv以及延拓交通流量训练集f与m个imf交通流量模态分量序列之间的关系式:
[0108][0109]
式(7)中,r表示延拓交通流量训练集f经过分解后所得的总交通流量残差分量;
[0110]
步骤3:利用改进的麻雀搜索算法优化双向门控循环单元预测模型的网络权值参数:
[0111]
步骤3.1:定义并初始化学习率lr、批样本数量b、最大迭代次数为maxiter,当前bigru网络迭代次数q=1;
[0112]
步骤3.2:构建由m个bigru预测子网络组成的双向门控循环单元预测模型,其中,任意第q个bigru预测子网由一组正、反向gru网络构成;设置正、反向gru网络中的门控循环单元个数均为n
gru
,正、反向gru网络中的神经元个数均为n
layers
,并在0-1范围内随机初始化第q个bigru预测子网络中待优化的权值参数集合其中,ω
q,r
和u
q,r
表示第q个bigru预测子网络中重置门rgq的权值系数;ω
q,z
和u
q,z
表示第q个bigru预测子网络中更新门ugq的权值系数;ω
q,xh
和ω
q,hh
表示第q个bigru预测子网络中候选隐含状态的网络权值系数;表示第q个正向gru网络中输出层的网络权值系数;表示第q个负向gru网络中输出层的网络权值系数;q=1,2,...,m;
[0113]
步骤3.3:基于第q个imf交通流量模态分量imfq,利用改进的麻雀搜索算法对第q个bigru预测子网络中待优化的权值参数择优,从而得到第q个bigru预测子网络中的最优权值参数集合其中,ω
q,r*
和u
q,r*
表示第q个bigru预测子网络中重置门rgq的最佳权值系数;ω
q,z*
和u
q,z*
表示第q个bigru预测子网络中更新门ugq的最佳权值系数;ω
q,xh*
和ω
q,hh*
表示第q个bigru预测子网络中候选隐含状态的最佳网络权值系数;表示第q个正向gru网络中输出层的最佳网络权值系数;表示第q个负向gru网络中输出层的最佳网络权值系数;
[0114]
步骤3.3.1:根据交通流量数据规模,结合麻雀搜索算法的有效实验数据范围,定义并初始化改进麻雀搜索算法的最大迭代次数iter
max
、参与搜索麻雀的数量np、预警值r2、权重调整参数ω
begin
、ω
end
、发现者数量pd及警戒者数量sd;
[0115]
初始化当前迭代次数为iter=1、当前权值参数的迭代次数h=1、当前参与搜索麻雀的迭代次数sp=1;
[0116]
定义并初始化第q个bigru预测子网络中第h个权值参数的第sp只麻雀的历史最优适应度值以及历史最优位置值从而利用式(8)得到第q个bigru预测子网络中第h个权值参数的历史最优适应度向量及历史最优位置向量
[0117][0118]
步骤3.3.2:随机初始化第iter次迭代时第sp只麻雀在训练第q个bigru中第h个网络权值参数时的位置并为np只麻雀随机赋予0-1之间的随机数;
[0119]
步骤3.3.3:将第q个imf交通流量模态分量imfq输入第q个bigru预测子网络中利用式(9)计算第q个bigru预测子网络中第h个权值参数的平均绝对误差,作为第q个bigru预测子网络中第h个权值参数的第iter-1次迭代的历史最佳适应度函数
[0120][0121]
式(9)中,表示第q个imf交通流量模态分量序列imfq中第iq个真实交通流量模态分量值,表示第iter-1次迭代将输入第q个bigru预测子网络中训练第h个权值参数时输出的第iq个交通分量预测值;
[0122]
步骤3.3.4:若则将赋值给第q个bigru网络中第h个权值参数的历史最优适应度值否则,历史最优适应度值不变;
[0123]
步骤3.3.5:利用式(10)得到第iter次迭代的线性动态自适应权重ω
iter
:
[0124][0125]
步骤3.3.6:利用式(11)得到第iter 1次迭代时训练第q个bigru中第h个网络权值参数时的第sp只发现者麻雀位置
[0126][0127]
式(11)中,exp(
·
)表示以自然常数e为底的指数函数;λ表示0-1之间的随机数;q表示服从正态分布的随机数;l表示全元素为1的1
×
d矩阵;st表示安全值;当r2<st时,表示种群觅食环境内无捕食者,发现者可以在区域内进行广泛搜索;当r2>=st时,表示警戒者发现了捕食者出现,种群迅速向安全区域转移;
[0128]
步骤3.3.7:根据式(12)得到第iter 1次迭代时训练第q个bigru中第h个网络权值参数时的第sp只追随者麻雀位置
[0129][0130]
式(12)中,表示第iter次迭代时第q个bigru网络中第h个网络权值参数时的全局最差位置;表示第iter 1次迭代时第q个bigru网络中第h个网络权值参数时发
现者所占据的最优适应度位置;a
表示取值为-1至1的d
×
1矩阵,且a
=a
t
(aa
t
)-1
,其中,a表示元素为1或-1的1
×
d矩阵;当时,表示追随者发现发现者自身能量水平过低,其第sp只追随者需要前往其他区域继续觅食;当时,表示第sp只追随者跟随发现者觅食中心行动,随机在中心位置附近随机觅食;
[0131]
步骤3.3.8:根据式(13)得到第iter 1次迭代时训练第q个bigru中第h个网络权值参数时的第sp只警戒者麻雀位置
[0132][0133]
式(13)中,表示第iter次迭代时第q个bigru网络中第h个网络权值参数的全局最优位置;β表示服从标准正态分布的随机数;k表示麻雀移动方向的步长控制;δ表示最小常数;表示训练第q个bigru网络中第h个权值参数时第sp只麻雀的当前适应度值;表示第q个bigru网络中第h个权值参数的历史最优适应度值;表示第q个bigru网络中第h个权值参数的历史最差适应度值;当时,表示麻雀处于种群的边缘,易遭受捕食者攻击;当时,表示麻雀位于种群中心,随机向其他麻雀靠拢;
[0134]
步骤3.3.9:将赋值给第q个bigru网络中第h个权值参数的历史最优适应度值将历史最优位置同时将第sp只全局最优位置麻雀于步骤3.3.2所赋予的随机数作为第q个bigru网络中第h个权值参数的最优权值参数;
[0135]
步骤3.3.10:将第q个imf交通流量模态分量imfq输入当前具备第h个最佳权值参数的第q个bigru预测子网络中进行预测,得到交通流量模态分量预测输出其中,表示第iter次迭代将输入第q个bigru预测子网络中训练第h个权值参数时输出的第iq个交通分量预测值;
[0136]
步骤3.3.11:若iter<iter
max
,则将iter 1赋值给iter后返回步骤3.3.3顺序执行;否则,输出第h个最佳权值参数的值,并执行步骤3.3.12;
[0137]
步骤3.3.12:若h<8,则将h 1赋值给h后返回步骤3.3.3顺序执行;否则,输出第q个bigru预测子网络中的最优权值参数集合
[0138]
步骤3.4:判断q<m是否成立,若成立,则将q 1赋值给q后,返回步骤3.3顺序执行;否则,输出总的最优参数集合
[0139]
步骤4:利用改进麻雀搜索算法优化的双向门控循环单元网络对交通流量进行组
合预测:
[0140]
步骤4.1:定义待预测交通流量数据的总数为n
*
,初始化q=1;
[0141]
步骤4.2:根据总的最优权值参数集合w
*
对m个bigru预测子网分别进行网络权值赋值,相应得到与各交通流量模态分量对应的m个性能最佳bigru交通流量预测模型;
[0142]
步骤4.3:将第q个imf交通流量模态分量imfq输入第q个最佳性能bigru交通流量预测模型中进行交通流量模态分量预测,并得到第q个imf交通流量模态分量imfq的预测序列其中,h
z,q
表示第q个imf交通流量模态分量imfq中第z个交通流量分量数据的预测值;
[0143]
步骤4.4:若q<m,则将q 1赋值给q后返回步骤4.3顺序执行,否则,表示得到m个分量预测序列{h1,h2,...,hq,...,hm}并进行加权重构,得到交通流量最终预测序列其中,yz表示第z个交通流量最终预测值,且
[0144]
本实施例中,一种电子设备,包括存储器以及处理器,该存储器用于存储支持处理器执行上述方法的程序,该处理器被配置为用于执行该存储器中存储的程序。
[0145]
本实施例中,一种计算机可读存储介质,是在计算机可读存储介质上存储有计算机程序,该计算机程序被处理器运行时执行上述方法的步骤。
[0146]
应用实例
[0147]
1)数据集选取和模型评价指标
[0148]
本发明选取合肥市芜湖路与徽州大道交叉口东路如图2所示作为数据采样点,采用2018年6月1日至20日6:00至18:00时段内时间间隔5min的共2400个交通流量数据,其中,选取前1920个交通流量数据作为训练集,后480个交通流量数据作为测试集,取测试集中前92个数据点作为实验结果展示曲线。
[0149]
为了评估本发明组合预测模型的预测效果,采用平均绝对误差(mean absolute error,mae)、平均绝对百分比误差(mean absolute percentage error,mape)和均方根误差(root mean squared error,rmse)作为预测模型最终的评价标准。其定义分别如下:
[0150]
(1)平均绝对误差(mean absolute error,mae):绝对误差的平均值。
[0151][0152]
(2)平均绝对百分比误差(mean absolute percentage error,mape):预测误差占真实值的百分比。
[0153][0154]
(3)均方根误差(root mean squared error,rmse):预测值与真实值的均方根差。
[0155][0156]
式(14)、(15)、(16)中,y
′
t
表示为模型预测交通流量数值;y
t
表示为实际交通流量数值。
[0157]
2)参数选取及仿真实验分析
[0158]
首先利用改进ceemd模态分解,将原始交通流量序列分解得到的imf交通流量模态分量和残差分量。高斯白噪声的标准差设置一般为0.01~0.4,通常建议白噪声幅值为原信号标准差的0.2倍,因此本节设置其信噪比nstd为0.2。噪声添加次数ne一般选取为50~1000,经过多次实验,当ne为500、最大迭代次数为maxiter为2000时,此模态分解效果最优,交通流量分量imf总数m=9,改进ceemd分解后的imf交通流量模态分量如图3所示。
[0159]
分别将各交通流量模态分量输入issa优化的bigru预测模型进行训练,利用bigru网络对各路网交通流量模态分量进行时空相关性挖掘。通常固定学习率l为0.01或0.001,bigru隐含神经元个数在{32,64,128}中选取,一般ssa种群大小n在20~100,发现者数量与跟随者数量占比为20%和10%。根据前期研究经验及多次实验,本节由训练集规模设置学习率l=0.001,bigru隐含神经元个数为32,网络中批量处理batchsize=32,权重调整参数ω
begin
=0.9、ω
end
=0.4,ssa种群大小n=50,最大迭代次数iterm=100,安全值st=0.8,上边界及下边界分别为-5和5时,各bigru网络模型预测效果最优。
[0160]
最后,将各issa优化的bigru预测模型的预测结果加权重构,具体交通流量预测方法流程图如图4所示,得到改进组合模型的最终预测曲线结果如图5所示。图5为合肥市芜湖路与徽州大道交叉口东路2018年6月20日6:00至18:00时段内时间间隔5min交通流量预测结果。由图5可见,原始交通流量存在强烈的非线性,例如交通流量时序点0至时序点20段,同时存在明显的非平稳性,例如交通流量时序点35至时序点45段,而本发明的交通流量组合预测方法在类似过程中,均能够稳定且精准地跟踪其剧烈波动,在交通流量预测方面表现出优越的性能,能够有效反映该采样点道路交通状况,为智能交通诱导提供了良好的基础。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。