基于gate-mixup数据增强的知识蒸馏化工文本分类方法及装置
技术领域
1.本发明属于自然语言文本处理技术领域,具体涉及一种基于gate-mixup数据增强的知识蒸馏化工文本分类方法及装置。
背景技术:
2.随着深度学习模型训练技术的发展,模型参数量以亿为单位骤增,然而受限于实际使用环境的软硬件以及经济成本限制,很多大型模型难以被真正应用在现实生活中,知识蒸馏技术的出现很好地缓解了这个问题。
3.知识蒸馏技术可以将大型模型的优越性能传递给轻量级模型,但是由于化工领域的特殊背景很多文本无法被有效挖掘并制作成数据集,因此使得模型无法被有效训练,最终也很难获得可以应用在化工领域的模型。
4.面对这个问题,通常可以采取数据增强来扩充数据集,如今主流的数据增强方法通常是随机插入、同义替换、回译、mixup等。这些方法不免都需要很大地改动原始数据,并且这些方法通常都不针对具体的自然语言处理任务,通用性很强,但是并没有针对知识蒸馏任务进行专门构建。
5.因此,针对应用在化工文本领域的大参数量文本分类模型知识蒸馏任务,亟需一种与知识蒸馏过程结合更为紧密的数据增强方法来提升学生模型文本分类性能。
技术实现要素:
6.发明目的:本发明所要解决的技术问题是提供一种基于gate-mixup数据增强的知识蒸馏化工文本分类方法及装置,有效考虑到化工领域文本数据挖掘困难进而导致模型训练样本少,知识蒸馏得到的学生模型性能提升较小的问题,有效提升学生模型分类精度。
7.技术方案:本发明提出一种基于gate-mixup数据增强的知识蒸馏化工文本分类方法,具体包括以下步骤:
8.(1)输入原始化工产品语料集,对语料集中的化工产品文本样本进行数据清洗以及预处理;
9.(2)基于从原始化工产品语料集中按照预设比例随机抽取的各化工产品样本文本,以及各化工产品样本文本分别对应预设分类下的相应真实类别,以化工产品样本文本为输入,化工产品样本文本所对应预设分类下相应类别为输出,同时对图神经网络教师模型以及transformer学生模型进行初始训练,获得可以加载训练得到的初始权重的教师模型与学生模型;
10.(3)基于原始化工产品语料集中的化工产品样本文本,进行一阶段相互学习蒸馏知识训练,将样本文本按照预设批次数量输入加载了初始权重的教师模型,教师模型输出对应文本表示,将文本表示输入教师分类器中输出获得文本样本的预测结果;
11.(4)通过预设指标函数对预测结果进行指标评分,将获得的分数f1输入门控单
元中,根据门控单元的预设阈值函数进行筛选,若阈值函数输出非零,则将教师模型输出的该文本表示作为教师模型logits的有效输出,通过第一蒸馏损失函数对学生模型进行蒸馏训练指导;否则对教师模型输出的文本表示进行数据增强,将文本表示与根据预设的dropout参数进行dropout操作后得到的教师模型输出的文本表示进行mixup操作,获得数据增强后的文本表示;
12.(5)将文本表示与原始文本表示进行残差叠加作为教师模型输出的logits,通过预设第一蒸馏损失函数对学生模型进行蒸馏训练指导;
13.(6)基于原始化工产品语料集中的化工产品样本文本,进行二阶段相互学习知识蒸馏训练,将样本文本按照预设批次数量输入加载了初始权重的学生模型,学生模型输出对应文本表示,将文本表示输入学生分类器中输出获得文本样本的预测结果;
14.(7)通过预设指标函数对预测结果进行指标评分,将获得的分数f2输入门控单元中,根据门控单元的预设阈值函数进行筛选,若阈值函数输出非零,则将学生模型输出的该文本表示作为学生模型logits的有效输出,通过第二蒸馏损失函数对教师模型进行蒸馏训练指导,否则对学生模型输出的文本表示进行数据增强,将文本表示与根据预设的dropout参数进行dropout操作后得到的学生模型输出的文本表示进行mixup操作,获得数据增强后的文本表示;
15.(8)将文本表示与原始文本表示进行残差叠加作为学生模型输出的logits,通过预设第二蒸馏损失函数对教师模型进行蒸馏训练指导;
16.(9)循环执行上述一阶段和二阶段相互学习知识蒸馏训练,直到达到预设的训练轮数,输出知识蒸馏训练好的学生模型;将化工产品文本样本输入学生模型,获得预测输出文本类别。
17.进一步地,步骤(4)和步骤(7)所述预设指标函数为f1-score生成函数。
18.进一步地,步骤(4)和步骤(7)所述门控单元的预设阈值函数具体公式如下:
[0019][0020]
ε=λf1 (1-λ)f2[0021]
其中,f表示通过预设指标函数生成的指标评分,δ表示预设阈值上下浮动超参数,ε表示基础评判评分,f1和f2分别表示初始权重加载到对应模型上预测生成的宏平均f1-score指标和微平均f1-score指标,λ表示调整两个指标之间权重的超参数。
[0022]
进一步地,步骤(4)所述数据增强具体实现公式如下:
[0023][0024][0025]
其中,μ表示从β分布获得的mixup插值混合超参数,x代表输入对应经过dropout操作后的教师模型的化工产品文本样本。
[0026]
进一步地,步骤(4)和步骤(7)所述根据预设的dropout参数进行dropout操作,具体公式如下:
[0027]
0.5≤d
init
《1
[0028]
d=0.75tanh(t
·
ε)
[0029]
其中,dropout操作使得神经网络随机失活比例取值初始化范围为d
init
,表示失活神经网络节点数占全部神经网络节点数的比重,初始化后每一组文本表示的dropout操作参数为d,t表示归一化缩放超参数,tanh表示归一化函数。
[0030]
进一步地,步骤(5)所述残差叠加公式为:
[0031][0032]
其中,r
t
表示教师模型logits的有效输出。
[0033]
进一步地,步骤(5)所述指导学生模型训练的预设第一蒸馏损失函数ls公式为:
[0034][0035]
其中,表示学生模型训练过程中根据化工产品样本文本训练输出的预测类别与真实类别labels之间的交叉熵损失函数;表示用于相互学习损失计算的kl散度函数,γ代表控制不同损失之间权重的超参数,z表示门控单元的预设阈值函数输出结果。
[0036]
进一步地,步骤(8)所述指导教师模型训练的预设第二蒸馏损失函数l
t
公式为:
[0037][0038]
其中,表示教师模型训练过程中根据化工产品样本文本训练输出的预测类别与真实类别label
t
之间的交叉熵损失函数;表示用于相互学习损失计算的kl散度函数,α代表控制不同损失之间权重的超参数,z表示门控单元的预设阈值函数输出结果。
[0039]
基于相同的发明构思,本发明还提供一种基于gate-mixup数据增强的知识蒸馏化工文本分类装置,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述计算机程序被加载至处理器时实现上述基于gate-mixup数据增强的知识蒸馏化工文本分类方法。
[0040]
有益效果:与现有技术相比,本发明的有益效果:1、本发明考虑到模型在进行相互学习知识蒸馏时,困难样本会降低知识蒸馏效果,构建了门控单元,通过模型初始参数获得筛选条件,可以根据实际需求,调整宏平均和微平均权重参数,实现门控筛选机制对多数量样本或者少数量样本的重要程度进行倾斜,然后对困难样本产生的文本表示进行筛选,并对其进行数据增强,与现有技术相比,只针对困难样本进行数据增强,简单样本文本表示让模型直接进行训练学习,困难样本文本表示进行数据增强,有效提高知识蒸馏速度,最终使得学生模型性能得到提升;
[0041]
2、本发明与现有mixup数据增强方法相比,通过模型自身dropout机制就可以生成新的文本表示,结合基础评判评分的变化自适应调整dropout机制随机失活比率,实现对不同困难样本动态生成文本表示,随后经mixup实现数据增强,文本表示实现更简单,无需引入额外的词向量或者模型文本表示信息;
[0042]
3、本发明考虑传统知识蒸馏方法简单的单一教师学生模型无法充分利用到模型结构差异性带来的有益性的问题,构建了一种基于相互学习机制的知识蒸馏方法,让图神
经网络教师模型和transformer学生模型可以充分学习彼此模型结构差异,同时本发明构建的学生模型仅为单层transformer模型,相比较于传统知识蒸馏方法中的多层transformer结构的bert等模型,有效降低了模型参数量,并通过相互学习机制弥补参数量下降带来的性能损失,提升了知识蒸馏训练速度。
附图说明
[0043]
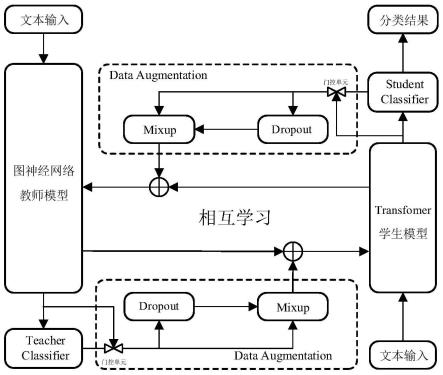
图1是知识蒸馏流程图。
具体实施方式
[0044]
下面结合附图对本发明作进一步详细说明。
[0045]
本发明提出一种基于gate-mixup数据增强的知识蒸馏化工文本分类方法,包括以下步骤:
[0046]
步骤1:输入原始化工产品语料集,对语料集中的化工产品文本样本进行数据清洗以及预处理。
[0047]
步骤2:基于从原始化工产品语料集中按照预设比例随机抽取的各化工产品样本文本,以及各化工产品样本文本分别对应预设分类下的相应真实类别,以化工产品样本文本为输入,化工产品样本文本所对应预设分类下相应类别为输出,同时对图神经网络教师模型以及transformer学生模型进行初始训练,获得可以加载训练得到的初始权重的教师模型与学生模型。
[0048]
步骤3:基于原始化工产品语料集中的化工产品样本文本,进行一阶段相互学习蒸馏知识训练,将样本文本按照预设批次数量输入加载了初始权重的教师模型,教师模型输出对应文本表示将文本表示输入教师分类器中输出获得文本样本的预测结果
[0049]
步骤4:通过预设指标函数对预测结果进行指标评分,此处预设指标函数为f1-score生成函数;将获得的分数f1输入门控单元中,根据门控单元的预设阈值函数进行筛选,若阈值函数输出非零,则将教师模型输出的该文本表示作为教师模型logits的有效输出,通过第一蒸馏损失函数对学生模型进行蒸馏训练指导,否则对教师模型输出的文本表示进行数据增强,将文本表示与根据预设的dropout参数进行dropout操作后得到的教师模型输出的文本表示进行mixup操作,获得数据增强后的文本表示
[0050]
门控单元的预设阈值函数具体公式如下:
[0051][0052]
ε=λf1 (1-λ)f2[0053]
其中,f表示通过预设指标函数生成的指标评分,δ表示预设阈值上下浮动超参数,ε表示基础评判评分,f1和f2分别表示初始权重加载到对应模型上预测生成的宏平均f1-score指标和微平均f1-score指标,λ表示调整两个指标之间权重的超参数。
[0054]
数据增强具体实现公式如下:
[0055]
[0056][0057]
其中,μ表示从β分布获得的mixup插值混合超参数,x代表输入对应经过dropout操作后的教师模型的化工产品文本样本。
[0058]
实际应用当中,根据预设的dropout参数进行dropout操作,其中dropout操作具体公式如下:
[0059]
0.5≤d
init
《1
[0060]
d=0.75tanh(t
·
ε)
[0061]
其中,dropout操作使得神经网络随机失活比例取值初始化范围为d
init
,表示失活神经网络节点数占全部神经网络节点数的比重,初始化后每一组文本表示的dropout操作参数为d,t表示归一化缩放超参数,tanh表示归一化函数。
[0062]
步骤5:将文本表示与原始文本表示进行残差叠加作为教师模型输出的logits,通过预设第一蒸馏损失函数对学生模型进行蒸馏训练指导。
[0063]
残差叠加公式为:
[0064][0065]
其中,r
t
表示教师模型logits的有效输出。
[0066]
实际应用当中,指导学生模型训练的预设第一蒸馏损失函数ls公式为:
[0067][0068]
其中,表示学生模型训练过程中根据化工产品样本文本训练输出的预测类别与真实类别labels之间的交叉熵损失函数;表示用于相互学习损失计算的kl散度函数,γ代表控制不同损失之间权重的超参数,z表示门控单元的预设阈值函数输出结果。
[0069]
步骤6:基于原始化工产品语料集中的化工产品样本文本,进行二阶段相互学习知识蒸馏训练,将样本文本按照预设批次数量输入加载了初始权重的学生模型,学生模型输出对应文本表示将文本表示输入学生分类器中输出获得文本样本的预测结果
[0070]
步骤7:通过预设指标函数对预测结果进行指标评分,将获得的分数f2输入门控单元中,根据门控单元的预设阈值函数进行筛选,若阈值函数输出非零,则将学生模型输出的该文本表示作为学生模型logits的有效输出,通过第二蒸馏损失函数对学生模型进行蒸馏训练指导,否则对学生模型输出的文本表示进行数据增强,将文本表示与根据预设的dropout参数进行dropout操作后得到的学生模型输出的文本表示进行mixup操作,获得数据增强后的文本表示
[0071]
数据增强具体实现公式如下:
[0072][0073][0074]
其中,η表示从β分布获得的mixup插值混合超参数,x代表输入对应经过dropout操作后的学生模型的化工产品文本样本。
[0075]
步骤8:将文本表示与原始文本表示进行残差叠加作为学生模型输出的logits,通过预设第二蒸馏损失函数对教师模型进行蒸馏训练指导。
[0076]
实际应用当中,残差叠加公式为:
[0077][0078]
其中,rs表示学生模型logits的有效输出。
[0079]
指导教师模型训练的预设第二蒸馏损失函数l
t
公式为:
[0080][0081]
其中,表示教师模型训练过程中根据化工产品样本文本训练输出的预测类别与真实类别label
t
之间的交叉熵损失函数;表示用于相互学习损失计算的kl散度函数,α代表控制不同损失之间权重的超参数,z表示门控单元的预设阈值函数输出结果。
[0082]
步骤9:循环执行上述一阶段(步骤3至步骤5)和二阶段(步骤6至步骤8)相互学习知识蒸馏训练,如图1所示,直到达到预设的训练轮数,输出知识蒸馏训练好的学生模型。将化工产品文本样本输入学生模型,获得预测输出文本类别。
[0083]
基于相同的发明构思,本发明还提供一种基于gate-mixup数据增强的知识蒸馏化工文本分类装置,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述计算机程序被加载至处理器时实现上述的一种基于gate-mixup数据增强的知识蒸馏化工文本分类方法。
[0084]
实际应用当中,为了更好的说明本方法的可行性与有效性,将本发明所设计一种基于gate-mixup数据增强的知识蒸馏化工文本分类方法与装置应用于实际当中,对128051条化工产品文本进行文本分类实验,结果表明使用本发明设计方法知识蒸馏训练得到的学生模型,应用在文本分类任务上性能优于现有知识蒸馏方法获得的学生模型,f1值和准确率分别达到了87.62%和87.46%。
[0085]
上面结合附图对本发明的实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下做出各种变化。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。