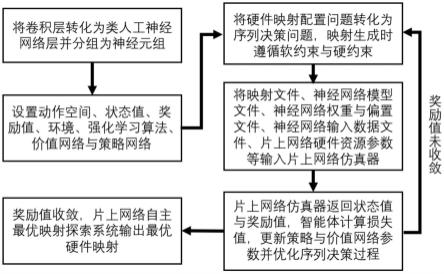
1.本发明涉及片上网络(network on chip,noc)领域,具体地说是涉及能够提供不同大量不同随机输入硬件映射并评估其对应的片上网络所需仿真性能指标,自主自动地探索出适应片上网络系统对应神经网络计算任务的最优硬件映射。
背景技术:
2.神经网络解决了包括自动驾驶、图像和语音识别、数据挖掘和自然语言处理等领域内的难题。片上网络在运行神经网络的多核系统的片上数据通信中显示出巨大的潜力。在片上网络中,处理单元(pe,processing element)负责计算指定的神经元,并根据硬件映射与其他处理单元进行交互。神经网络由数百万个参数组成,这导致片上系统的通信延迟很高。硬件映射对运行大规模神经网络的基于片上的加速器的性能起着至关重要的作用。
3.传统的硬件映射优化算法有穷举法(如神经网络感知映射算法)与启发式算法(如遗传算法)等。然而,面对巨大的映射探索空间,传统的硬件映射优化算法的效果主要依赖于初始化映射,这可能导致它们只能探索到局部次优解。
4.基于上述背景,对广阔映射探索空间进行全局搜索的自主化最优映射探索系统对能够进行神经网络计算的片上网络加速器意义重大。
技术实现要素:
5.发明目的:提供一种基于强化学习的片上网络自主最优映射探索系统,该系统能够提供不同大量不同随机输入硬件映射并评估其对应的片上网络所需仿真性能指标,自主自动地探索出适应片上网络系统对应神经网络计算任务的最优硬件映射。
6.技术方案:
7.一种基于强化学习的片上网络自主最优映射探索系统,包括以下步骤:
8.步骤1、将片上网络所需计算的神经网络卷积层转化成为类人工神经网络层,并将神经元进行分组得到神经元组;
9.优选地,神经网络卷积层的展开方式为:
[0010][0011]
优选地,k为卷积神经网络的卷积核的个数,y
′
和x
′
为输出神经元的行数和列数,o
i,j,k
为输出神经元。按照三层循环的顺序排列输出神经元阵列,nn代表需要在加速器上进行计算的神经网络,n0到n
x
′y′
k-1
代表将卷积神经网络转化为一维的类人工神经网络后的每个神经元。
[0012]
步骤2、对基于强化学习的片上网络自主最优映射探索系统进行动作空间、状态值、奖励值、环境、强化学习算法、价值网络与策略网络的设置与配置;
[0013]
优选地,动作空间需要包含片上系统所有可用的计算核节点,神经元组可以映射到这些计算节点进行计算,而不违反软约束或硬约束。
[0014]
优选地,状态值定义为在某一时刻下硬件映射相关特征的串联。该特征串联数组
包括神经元组对应的计算单元编码索引,以及片上网络系统计算单元的硬件布局图的一维展开数组。计算单元的硬件布局图上会提供待计算神经网络的层信息。
[0015]
优选地,奖励值设定规则如下:如果在一个回合中没有重复动作,则最后一步的奖励为环境返回的值,其他步骤中的奖励值为零。最后一步中,若没有重复动作,环境反馈的奖励值为片上网络系统通信延迟的反比函数,公式如下:
[0016][0017]
片上网络系统的通信延迟为总运行周期与计算延迟的差:
[0018]
t
communication
=runtime-t
computation
[0019]
计算延迟为待计算神经网络每层所需最大计算延迟的计算节点延迟的总和,而每个计算节点的延迟为纯计算延迟与最后一个神经元组串行输入到非线性单元的延迟:
[0020][0021]
其中,通过nmac对单个计算单元节点的输出神经元分组,给出每个计算单元中神经元计算所需的最大组数。
[0022]
每个计算单元节点内部神经元的计算是组内并行、组间串行的,在并行的乘加单元处理后,每组再串行进入一个非线性单元。
[0023]
优选地,环境为片上网络加速器,即成本模型。
[0024]
优选地,强化学习算法包括近端策略优化算法(ppo)与异步优势动作评价算法(a2c)。
[0025]
优选地,价值网络与策略网络均为全连接的多层感知器(mlp),包括输入层,三层隐藏层与输出层。两个网络的输入层神经元数为状态数组的元素数量。三层隐藏层的神经元数量均为q,每层的激活函数为relu。策略网络的输出层个数为片上网络的计算单元节点个数,价值网络的输出层个数为1。策略网络的输出提供了智能体选择不同计算单元节点的概率,价值网络的输出提供了损失函数的结果。
[0026]
步骤3:将硬件映射配置问题转化为序列决策问题,自动化进行硬件映射的生成,映射生成时遵循软约束与硬约束;
[0027]
优选地,软约束适用于神经元组数量较少的情况,硬约束适用于神经元组数量较多的情况。
[0028]
优选地,在软约束条件下,只要回合中的一步有重复的动作,就会给智能体一个很大的负奖励值。在最后一步中,软约束条件下环境的返回值是重复动作的负奖励值的总和。每一步重复动作的负奖励值设置需要保证即使只有一个重复动作,负奖励值也要比系统运行总周期大。
[0029]
优选地,在硬约束条件下,若智能体无法提供有效地硬件映射动作序列,片上网络自主最优映射探索系统会干预动作概率,在每一步抽取动作之前,向策略网络添加掩码,并将之前步骤中选择过的动作的概率设置为零,同时,其他未选择动作按比例增加概率值。故在硬约束模式下,回合中的所有步都是不重复的,智能体从环境中获得最后一步的奖励值,其他步的奖励值均为零。硬约束条件下,为策略网络概率添加掩膜并根据调整后的概率抽
取动作的公式如下:
[0030]
p
′
n 1
(pem)=0,if an=pem,
[0031][0032][0033]an 1
=sample(pe0,
…
,pem),ap
′
n 1
=mask_ap
n 1
[0034]
步骤4:根据强化学习算法策略网络的概率生成映射策略后,将映射文件、神经网络模型文件、神经网络权重与偏置文件、神经网络输入数据文件、片上网络硬件资源参数等输入片上网络加速器;
[0035]
步骤5:片上网络加速器作为环境返回智能体所需要的状态值与奖励值,智能体根据返回值计算损失值,更新策略与价值网络参数并优化序列决策过程;
[0036]
优选地,更新价值与策略网络时所用的状态值需要归一化到范围[-1,1],以稳定智能体训练。
[0037]
步骤6:重复步骤3~5,策略网络最终学习到如何预测映射配置动作以最大程度优化奖励值,当奖励值收敛时,最优奖励值对应的序列动作为理想的最优硬件映射。
[0038]
本发明的有益效果是:
[0039]
第一,本发明提供一种基于强化学习的片上网络自主最优映射探索系统,适用于自动化地对执行神经网络计算的片上网络加速器进行自动化的最优硬件探索,所探索的硬件映射的优化目标为系统仿真通信延迟。解决了现有随机搜索等方式很难获取最佳映射的问题。
[0040]
第二,本发明将映射配置问题转化为序列决策问题,让硬件映射问题更加适应强化学习框架,并提出软约束与硬约束两种约束模式,分别适用于小规模和大规模的神经元组数量,以帮助训练智能体。
[0041]
第三,本发明的方法基于强化学习算法,相较于传统的穷举法与启发式算法只能得到局部次优解,本发明能对硬件映射的动作空间进行全局的搜索并探索到映射的全局最优解,具有良好的实际应用价值。提出的基于rlf的自主最优映射探索架构,与当前最先进的硬件映射解决方法相比,使用a2c,平均通信延迟减少4.27%至33.33%,平均通信吞吐提高了5.17%至63.60%;使用ppo,平均通信延迟减少4.11%至33.21%,平均通信吞吐率提高了5.23%至63.68%。
附图说明
[0042]
图1为本发明的训练流程图。
[0043]
图2为待计算神经网络的卷积层示例图。
[0044]
图3为本发明将卷积层转化后的类人工神经网络示例图。
[0045]
图4为类人工神经网络进行分组的示例图。
[0046]
图5为本发明的硬件映射配置问题转化为序列决策问题的示例图。
[0047]
图6为本发明的软约束与硬限制下强化学习算法的训练收敛情况对比图。
[0048]
图7为本发明的最优映射与其他映射的通信延迟对比结果图。
[0049]
图8为本发明的最优映射与其他映射的平均通信吞吐率对比结果图。
具体实施方式
[0050]
下面结合附图和具体实施方式,对本发明进行详细地说明。
[0051]
如图1所示的是基于强化学习的片上网络自主最优映射探索系统的训练流程图,本实施例所述的片上网络为二维mesh片上网络。在进行强化学习算法的第一轮动作抽取之前,需要将片上网络所需计算的神经网络卷积层转化成为类人工神经网络层,并将神经元进行分组得到神经元组。
[0052]
图2为一待计算神经网络的其中卷积层的示例,图中,卷积层由多维度神经元构成,包括输入神经元行(y)/列(x)/通道(c)、权重核的行(r)/列(s)/个数(k)、输出神经元行(y’)/列(x’),权重核的通道数是c,权重核的通道数与输入神经元通道数一致,输出神经元通道数与权重核的个数一致。
[0053]
将示例的神经网络卷积层按照行流式展开,展开后的示例图如图3所示,展开所遵循的公式如下:
[0054][0055]
其中,k为卷积神经网络的卷积核的个数,y
′
和x
′
为输出神经元的行数和列数,o
i,j,k
为输出神经元。按照三层循环的顺序排列输出神经元阵列,nn代表需要在加速器上进行计算的神经网络,n0到n
x
′y′
k-1
代表将卷积神经网络转化为一维的类人工神经网络后的每个神经元。
[0056]
若将神经元组大小设置为m,则每m个神经元将被分配到一组。当神经网络层中的神经元数量不是神经元组大小的倍数时,每层中多余的神经元自动被分配去一组,如图4所示。神经元组大小的上限取决于片上网络系统中每个处理单元输入和输出突触的数量以及处理单元的计算资源。有两种模式可以选择,即全层映射模式和融合层映射模式。
[0057]
在aome强化学习框架中,将两个有向图之间的映射转换为神经元组序列号和处理元素id之间的匹配,以方便映射的表达。
[0058]
在进一步的实施例中,为了适应片上系统的神经网络计算为了适应片上系统的神经网络计算,以八个数据维度表示的cnn层应在在映射之前,应将其重塑为类似于一维的ann层。这个转换过程是映射生成的第一步。为了在单个处理元素中计算多个神经元,第二步是在将神经元分配给特定的处理单元之前,将其重塑为给定的神经元组大小的集群。
[0059]
在该片上网络自主最优映射探索系统中,分好组后的神经元组序列号与对应片上网络处理单元序号组成的数组即为简化后的硬件映射表达。
[0060]
确定好硬件映射表达方式后,接着需要对基于强化学习的片上网络自主最优映射探索系统进行动作空间、状态值、奖励值、环境、强化学习算法、价值网络与策略网络的设置与配置。
[0061]
动作空间需要包含片上系统所有可用的计算核节点,神经元组可以映射到这些计算节点进行计算,而不违反软约束或硬约束。
[0062]
状态值定义为在某一时刻下硬件映射相关特征的串联。该特征串联数组包括神经元组对应的计算单元编码索引,以及片上网络系统计算单元的硬件布局图的一维展开数组。计算单元的硬件布局图上会提供待计算神经网络的层信息。
[0063]
奖励值设定规则如下:如果在一个回合中没有重复动作,则最后一步的奖励为环境返回的值,其他步骤中的奖励值为零。
[0064]
最后一步中,若没有重复动作,环境反馈的奖励值为片上网络系统通信延迟的反比函数,公式如下:
[0065][0066]
其中,c为常量,map表示该回合生成的映射,nn表示片上网络需要计算的神经网络,r
(map,nn)
表示环境返回的奖励值。
[0067]
片上网络系统的通信延迟为总运行周期与计算延迟的差:
[0068]
t
communication
=runtime-t
computation
[0069]
计算延迟为待计算神经网络每层所需最大计算延迟的计算节点延迟的总和,而每个计算节点的延迟为纯计算延迟与最后一个神经元组串行输入到非线性单元的延迟:
[0070][0071]
其中,n
in
为单个计算单元节点中输入的神经元数量,n
out
为单个计算单元节点中输出的神经元数量,nmac为处理单元内置乘加器的数量。
[0072]
通过nmac对单个计算单元节点的输出神经元分组,给出每个计算单元中神经元计算所需的最大组数。每个计算单元节点内部神经元的计算是组内并行、组间串行的,在并行的乘加单元处理后,每组再串行进入一个非线性单元。
[0073]
该系统的强化学习算法中的环境为片上网络加速器,即成本模型。
[0074]
强化学习算法包括近端策略优化算法(ppo)与异步优势动作评价算法(a2c)。价值网络与策略网络均为全连接的多层感知器(mlp),包括输入层,三层隐藏层与输出层。两个网络的输入层神经元数为状态数组的元素数量。三层隐藏层的神经元数量均为q,每层的激活函数为relu。策略网络的输出层个数为片上网络的计算单元节点个数,价值网络的输出层个数为1。策略网络的输出提供了智能体选择不同计算单元节点的概率,价值网络的输出提供了损失函数的结果。
[0075]
设置好强化学习算法的配置后,需要将硬件映射配置问题转化为序列决策问题如图5所示,自动化进行硬件映射的生成。在初始状态s0中,有一个全空的处理单元硬件布局图和未被分配的神经元组。当训练开始时,系统将在每个时间步为特定的处理单元分配一个神经元组,然后跳到下一个状态。t代表要映射的神经元组总数。因此,在最终状态s
t
输出该回合的映射解决方案。状态中的数字表示由处理单元需要计算的神经网络层索引。例如,在s
t
中,数字1到7表示运行的卷积神经网络有7层,数字1出现3次表示第一层有3个神经元组。这样的表达式有利于表达数据的传输,因为数据传输仅发生在不同的卷积神经网络层
之间。在同一层中,不同的神经元组彼此不通信。通过这种方式,我们可以根据硬件布局观察不同神经网络层之间的数据流并得出哪些处理单元被相同的神经网络层使用。
[0076]
通过图5(a)中的s
t
向量可以看到哪些pe被同一个nn层使用。在图5(a)中,pe5、pe8和pe11被同一个nn层使用。
[0077]
动作空间中的每个动作都被赋予了一个概率值。根据从策略网络获得的概率为每个神经元组选择处理单元。由于每个处理单元的计算资源是有限的,将不同的神经元组分配给同一个pe节点会会大大增加片上网络系统的运行时间。
[0078]
硬件映射生成时需遵循软约束与硬约束。软约束适用于神经元组数量较少的情况,而硬约束适用于神经元组数量较多的情况。
[0079]
在软约束条件下,只要回合中的一步有重复的动作,就会给智能体一个很大的负奖励值。在最后一步中,软约束条件下环境的返回值是重复动作的负奖励值的总和。每一步重复动作的负奖励值设置需要保证即使只有一个重复动作,负奖励值也要比系统运行总周期大。
[0080]
例如,在图5(a)中,动作a1与动作a0是一样的。与动作a0相同,并且在状态s2中出现重复的"1"。因此,得到的奖励是r1=-20000。在时间t,这个回报是r
t
=-60000。惩罚的大小取决于系统运行时间的舍入值。保证了即使只有一个重复的动作,惩罚也会大于运行时间。
[0081]
在硬约束条件下,若智能体无法提供有效地硬件映射动作序列,片上网络自主最优映射探索系统会干预动作概率,在每一步抽取动作之前,向策略网络添加掩码,并将之前步骤中选择过的动作的概率设置为零,同时,其他未选择动作按比例增加概率值。故在硬约束模式下,回合中的所有步都是不重复的,智能体从环境中获得最后一步的奖励值,其他步的奖励值均为零。硬约束条件下,若第n步抽取的计算单元序号为pem,则第n 1步时智能体为策略网络概率p
n 1
添加掩膜后变为p
′
n 1
,并根据调整后的概率抽取第n 1步动作的公式如下:
[0082]
p
′
n 1
(pem)=0,if an=pem,
[0083][0084][0085]an 1
=sample(pe0,
…
,pem),ap
′
n 1
=mask_ap
n 1
[0086]
其中,tp是除了上一步抽取的计算单元节点外,其他所有计算单元节点被抽取概率的总和。mask_ap
n 1
为添加掩膜后策略网络抽取第n 1步动作的概率。sample函数限制智能体根据ap
′
n 1
的概率对第n 1步的动作进行抽取。
[0087]
在硬约束模式下,所有步骤的行动都是非重复性的。从环境中获得最后一步的奖励,而其他步骤的奖励为零,如图5(b)所示。
[0088]
策略网络和价值网络,输入层的大小都等于状态向量中的元素数。前四层网络的激活采用relu激活单元。策略网络中输出层的神经元数量等于基于noc的系统中pe节点的数量,而价值网络的输出层大小为1。策略网络的输出层提供了选择不同pe节点的概率,而价值网络的输出层则显示了损失函数的结果。
[0089]
根据强化学习算法策略网络的概率生成映射策略后,将映射文件、神经网络模型文件、神经网络权重与偏置文件、神经网络输入数据文件、片上网络硬件资源参数等输入片上网络加速器。
[0090]
性能评估模型可以分析和确定计算单元在时间和空间上的复用。然后,它相应地估计神经网络应用的运行延迟。成本模型将评估的性能结果返回给智能体。它还提供状态信息,包括分配给神经元组的处理单元序号和片上网络硬件布局图,也就是处理单元的布局。由成本模型提供的系统运行时间包括通信延迟和计算延迟。处理单元的计算延迟由输入神经元的数量n
in
、输出神经元的数量n
out
和每个pe中的乘法累加器(mac)的数量n
mac
决定。
[0091]
片上网络加速器作为环境返回智能体所需要的状态值与奖励值,智能体根据返回值计算损失值,更新策略与价值网络参数并优化序列决策过程。更新价值与策略网络时所用的状态值需要归一化到范围[-1,1],以稳定智能体训练。
[0092]
智能体重复地进行动作的生成并利用奖励值与状态值进行训练,策略网络最终学习到如何预测映射配置动作以最大程度优化奖励值,当奖励值收敛时,最优奖励值对应的序列动作为理想的最优硬件映射。
[0093]
在巨大的硬件映射探索空间下。不同的映射会影响到noc系统中的跳数和拥堵情况,并导致不同的系统性能。因此,进行了一个初步的实验,在实验中收集不同映射的通信延迟。在该实施例中,选择lenet作为一个实验神经网络,它需要被映射到noc系统中。在一个实例中,通过蒙特卡洛方法获得最优映射。给定随机映射,从noc系统的成本模型中得到他们的通信延迟。根据实验结果,最好的随机映射和最差的随机映射的通信延迟之间有很大的差距,这意味着硬件映射对系统的性能有很大的影响,所以我们需要探索最佳的硬件映射。由于较好映射的频率较低,通过随机搜索获得最佳映射是很困难的。因此,有效地探索最佳映射是非常有价值的。
[0094]
对表1中的10个神经网络进行最优硬件映射探索以验证该系统的性能。表1中给出了各神经网络的神经网络元组个数、神经网络元组大小与神经网络每层神经元的大小。
[0095]
表1:待计算的各神经网络配置
[0096]
[0097][0098]
图6展示了cnn-fc网络和lenet网络在软约束与硬约束下的奖励值与损失值的收敛情况。根据表1中的元组个数配置情况可以看到,cnn-fn的元组个数为13,使用软约束进行训练即能保证强化学习算法的奖励值与损失值稳定收敛,如图6(a)与图6(b)。然而,如果将lenet网络在软约束模式下训练,则很难抽取到不重复的映射配置动作,两种强化学习算法的奖励值都不能收敛到最大值,甚至会随着训练的进行而减小,如图6(c)与图6(d)。若将软约束模式换成硬约束模式,这种情况将得到改善,如图6(e)与图6(f)。
[0099]
图7和图8展示了所有实验神经网络的不同硬件映射下的通信延迟与平均通信吞吐率。与传统的x方向上的映射(dirx)、y方向上的映射(diry)、基于遗传算法的映射(ga)、基于神经网络感知算法的映射(ea)相比,该基于强化学习的片上网络自主最优映射探索系统提供的最优映射,若用近端策略优化算法(ppo),在10个实验神经网络中的平均通信延迟分别降低了27.19%,33.21%,4.11%和12.31%,平均通信吞吐率分别提高了43.18%,63.68%,5.23%和14.87%;若用异步优势动作评价算法(a2c),在10个实验神经网络中的平均通信延迟分别降低了27.30%,33.33%,4.27%和12.46%,平均通信吞吐率分别提高了43.24%,63.60%,5.17%和14.83%。
[0100]
以上示意性地对本发明创造及其实施方式进行了描述,该描述没有限制性,在不背离本发明的精神或者基本特征的情况下,能够以其他的具体形式实现本发明。附图中所示的也只是本发明创造的实施方式之一,实际的结构并不局限于此,权利要求中的任何附图标记不应限制所涉及的权利要求。所以,如果本领域的普通技术人员受其启示,在不脱离本创造宗旨的情况下,不经创造性的设计出与该技术方案相似的结构方式及实施例,均应属于本专利的保护范围。此外,“包括”一词不排除其他元件或步骤,在元件前的“一个”一词不排除包括“多个”该元件。产品权利要求中陈述的多个元件也可以由一个元件通过软件或者硬件来实现。第一,第二等词语用来表示名称,而并不表示任何特定的顺序。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
