1.本发明属于网络故障定位技术领域,更为具体地讲,涉及一种基于端到端业务性能指标的智能网络故障定位方法。
背景技术:
2.互联网竞争越来越激烈,满足用户需求、重视用户使用体验的技术性进步才是各大网络运营商寻求突破的关键点,这对服务的可用性以及响应速度提出了更高的要求。随着网络规模的不断扩大,细粒度的链路性能指标测量已成为提高网络可靠性和增强用户体验的前提条件之一,网络管理者一般通过获取网络链路性能指标定位网络故障发生点,从而进行网络异常检测、网络故障恢复等管理行为。
3.传统网络中,由于测量能力以及网络控制能力的限制,链路性能指标的测量大多采取统计特性估计法和代数反演法。统计特性估计法只能估计出链路性能指标分布,不能得到链路的实时性能指标,而代数反演法实现开销较大。可编程网络技术的出现为进行及时和准确的链路性能指标测量奠定了基础,它具有灵活的控制能力和可编程特性,从而有利于控制网络链路性能指标的探测行为。
4.随着可编程网络的发展,在可编程网络中使用int技术获取链路性能指标的研究逐渐增多。int作为一种备受关注的细粒度网络性能指标测量方法,旨在实现细粒度的实时数据平面监视。它通过在数据层面收集和报告网络状态来实现对网络状态的监控,整个过程不消耗控制平面的计算资源。它允许数据包搜集网络设备的内部状态信息,例如队列深度、通过数据平面管道时的排队等待时间。
5.然而,使用int技术获取链路性能指标,将int报头和元数据栈附加到所有数据包上,这种方式仍有一些弊端:(1)网络开销问题:int消耗的网络带宽可能很大,对于小尺寸的数据包,这种网络开销问题影响较大;(2)监控系统过载问题:交换机对流经的数据包进行包头处理,添加元数据到数据包上。对于数据包到达率高的流量,这种操作增加了交换机的负担且终端信息收集服务器可能会过载,从而导致处理延迟增加。针对上述问题,目前学者们的研究中有两种解决方法,(1)减少插入数据包的元数据字节数,但随着网络拓扑增大,这种方法仍然无法解决问题。(2)网络中所有节点选择性地插入元数据,这种方法搜集到的链路性能信息有限,难以监测全网状态。
6.为解决int技术中数据包携带链路状态信息的开销过大导致处理延迟增加的问题,在2022年06月14日授权的、授权公告号为cn113162800b的中国发明专利中公开了一种基于强化学习的网络链路性能指标异常定位方法》,通过int技术获取网络节点的状态信息反映链路性能状态。异常节点定位时,从环境中获取的业务流路由信息,结合用户反馈结果生成环境状态,输入到强化学习(rl)代理,得到每个交换机对应的q值,选取最大的交换机为异常节点,并开放其int功能,然后再输入环境状态,再定位异常节点,并进行修复,直到用户反馈所有业务流正常。同时,根据int信息监测出开放交换机(定位的异常节点)是否为真实的异常节点,给出奖励送到经验回放池,使决策神经网络输出的q值与交换机对应的奖
励值成正相关性,使得决策神经网络更能准确定位异常节点,这样在这些异常节点上使用int技术实时监测,不必在所有节点上使用,从而减少网络管理开销。
7.然而,其环境状态为维度为n*(2n 2)大小的矩阵,n为网络中所有业务流路由路径所经过的网络节点(交换机)的总数,第一列表示交换机上流经的业务数量,第二列表示流经该交换机节点的业务中是否有问题业务,第3至(n 2)列表示流经该交换机i的业务流的源节点,若其中一条业务的源节点是交换机k,则对应的第i行第k 2列为1,第(n 3)至(2n 2)列表示流经交换机i的业务流的目的节点,若其中一条业务的目的节点是交换机k,则对应的第i行第k n 2列为1。该环境状态设计上并未完全反应故障网络节点故障的本质,同时,在奖励方面只是一个简单的正负奖励,也为完全反应不同动作的实质,这样训练决策神经网络的收敛速度不够快,同时,定位所有故障的次数也较多,定位速度较慢。
技术实现要素:
8.本发明的目的在于克服现有技术的不足,提供一种基于端到端业务性能指标的智能网络故障定位方法,以提高训练智能决策模块中智能体(决策神经网络)的收敛速度,快速定位所有故障。
9.为实现上述发明目的,本发明基于端到端业务性能指标的智能网络故障定位方法,其特征在于,包括以下步骤:
10.(1)、构建端到端业务性能指标向量作为强化学习的初始状态s011.若网络能实现时钟同步技术获取到端到端业务的单向时延时,采用有向图的构建方式:将每个业务流发送端到接收端的时延以及接收端返回到发送端的时延作为端到端业务性能指标向量的元素,同时,将加上n个三位二进制数,n为有向链路数,用以表征每条链路的检测状态,其中,第一位为1表示未检测,为0表示已检测,第二位为1表示检测为故障,为0表示未检测/检测为正常,第三位为1表示检测为正常,为0表示未检测/检测为故障,初始状态时,n个三位二进制数均为[1 0 0],这样构建出一个2d 3n长度的端到端业务性能指标向量并作为强化学习的初始状态s0,d为业务流数量,j=1,2,
…
,d;
[0012]
若网络只能获取到端到端业务的往返时延时,采用无向图的构建方式:将每个业务流端到端的往返时延aj作为端到端业务性能指标向量的元素,同时,将加上n个三位二进制数,n为链路数,用以表征每条链路的检测状态,其中,第一位为1表示未检测,为0表示已检测,第二位为1表示检测为故障,为0表示未检测/检测为正常,第三位为1表示检测为正常,为0表示未检测/检测为故障,初始状态时,n个三位二进制数均为[1 0 0],这样构建出一个d 3n长度的端到端业务性能指标向量并作为强化学习的初始状态s0;
[0013]
初始化状检测次数t=0;
[0014]
(2)、发送动作a
t
到环境,检测并给予奖励
[0015]
将从网络即环境中获取的状态s
t
输入智能决策模块中智能体,输出动作a
t
即需要检测的链路为第i条,并且每次所需要检测的链路不会与之前的重复,然后智能体将决策即动作a
t
发送至环境即将第i条链路两端路由器的int功能打开检测其是否发生故障,并根据检测结果给予奖励r
t
:
[0016]
a)、决策动作正确,即检测的链路为故障:
[0017]
i.已经定位所有故障链路:r
t
=e-t*b,b》0,e》n*b;
[0018]
ii.未定位所有故障链路:r
t
=c,c》0;
[0019]
b)、决策动作错误,检测的链路为正常:r
t
=-d,d》0;
[0020]
其中,已经定位所有故障链路是指所有用户反馈时延低于正常时延阈值,未定位所有故障链路是指存在用户反馈时延高于正常时延阈值,e、b、c、d为常数项,根据具体实施网络进行确定;
[0021]
(3)、更新状态s
t
为状态s
t 1
[0022]
a)、决策动作正确,即检测的链路为故障:
[0023]
将状态s
t
中第i条链路对应的三位二进制数修改为[0 1 0],将所有流经第i条链路的业务流的时延设置为正常链路时延;
[0024]
b)、决策动作错误,检测的链路为正常:
[0025]
将状态s
t
中第i条链路对应的三位二进制数修改为[0 0 1];
[0026]
通过更新状态s
t
得到状态s
t 1
;
[0027]
(4)、构建训练数据
[0028]
构建一条训练数据《s
t
,a
t
,r
t
,s
t 1
》,并放入经验回放池,t=t 1,返回步骤(2),直到已经定位所有故障链路;
[0029]
(5)、训练智能体
[0030]
用经验回放池的训练数据对智能决策模块中智能体进行训练,训练好的智能决策模块中智能体用于故障定位;
[0031]
(6)、故障定位
[0032]
当需要进行新的故障定位时,用训练好的智能决策模块中智能体,进行步骤(1),并每次令t=t 1,重复步骤(2)、(3),直到定位所有故障链路。
[0033]
本发明的发明目的是这样实现的:
[0034]
本发明基于端到端业务性能指标的智能网络故障定位方法,在现有故障(异常)定位的基础上,对状态及更新进行了设计,依据每个业务流的时延以及每条链路的检测状态构建作为端到端业务性能指标向量作为强化学习的状态,送入智能决策模块中智能体后,输出动作a
t
即发送至环境即将第i条链路两端路由器的int功能打开检测其是否发生故障,并根据检测情况,对状态进行更新,a)、决策动作正确,即检测的链路为故障:将状态s
t
中第i条链路对应的三位二进制数修改为[0 1 0],将所有流经第i条链路的业务流的时延设置为正常链路时延;b)、决策动作错误,检测的链路为正常,将状态s
t
中第i条链路对应的三位二进制数修改为[0 0 1],通过更新状态s
t
得到状态s
t 1
,这样,在决策动作正确的情况下,除了有相应表征链路检测状态的维度进行变化,还有流经该链路的业务时延也需要进行相应地变化,让该业务时延从故障的时延大小转变为正常的时延大小,减小该链路在后续决策中的干扰,使得智能决策模块中智能体(决策神经网络)训练更容易收敛。本发明除了有端到端业务时延之外,还有表征每条链路检测状态的维度,可以更加准确地描述每次检测之后状态的变化,取得更好的决策效果。同时,本发明还对奖励进行了设计,通常在动作不正确的情况下,给予的奖励为固定的一个负奖励。在动作正确的情况下给予固定的正奖励。本发明根据当前故障定位情况给予正奖励为:在没有定位到所有故障时,给予固定的正奖励,定位到所有故障的时候,给予一个与检测次数相关的奖励,即进行检测的次数越小,奖励就会越大。这种做法可以更好地使智能决策模块中智能体(决策神经网络)训练收敛,达
到以最少的检测次数定位到所有故障的效果。
附图说明
[0035]
图1是本发明基于端到端业务性能指标的智能网络故障定位方法的应用场景示意图;
[0036]
图2是本发明基于端到端业务性能指标的智能网络故障定位方法的应用系统示意图;
[0037]
图3是本发明基于端到端业务性能指标的智能网络故障定位方法一种具体实施方式流程图;
[0038]
图4是本发明基于端到端业务性能指标的智能网络故障定位方法中一端到端业务性能指标向量实例示意图;
[0039]
图5是强化学习算法示意图。
具体实施方式
[0040]
下面结合附图对本发明的具体实施方式进行描述,以便本领域的技术人员更好地理解本发明。需要特别提醒注意的是,在以下的描述中,当已知功能和设计的详细描述也许会淡化本发明的主要内容时,这些描述在这里将被忽略。
[0041]
图1是本发明基于端到端业务性能指标的智能网络故障定位方法的场景示意图。
[0042]
本发明基于端到端业务性能指标的智能网络故障定位方法,利用端到端业务性能指标向量,通过强化学习算法智能决策出这些可能出现传输性能故障的链路,以缩小链路性能指标测量的范围。其场景示意图如附图1所示,在本实例中,可编程网络中有1个控制器,1个智能决策模块,3个用户,7个可编程交换机,11条链路。此处只是为了表示方便,真实场景可以有任意a个用户,m个可编程交换机,n条链路,网络中业务流量数目为d条,其中每条业务的路由路径唯一,用户在使用网络应用时周期性地收集业务流量的端到端往返延时aj∈{a1,a2,...,ad},使用基于强化学习算法的智能决策模块选择发生故障的链路,从而选择网络中的某些可编程交换机vi∈{v1,v2,...,vm},通过控制器通知这些可编程交换机,开放其int功能,进而进行对该链路的细粒度状态检测,从而定位到故障链路。
[0043]
图2是本发明基于端到端业务性能指标的智能网络故障定位方法的应用系统示意图。
[0044]
如图2所示,本发明应用系统主要分为三个部分,其功能划分如下:
[0045]
(1)智能决策模块
[0046]
智能决策模块基于强化学习算法,由一个终端服务器担任,其中集成了智能决策系统,主要由神经网络组成。神经网络由多个计算层组成,可以看作是一个复杂的数学函数,它将给定的输入映射到所需的输出。
[0047]
(2)控制器
[0048]
控制器负责将智能决策模块的决策转换为网络操作,环境状态将作为反馈传递给智能决策模块。控制器通过修改网络设备内的流表,控制交换机的int功能是否开放。根据开放int功能后收集到的信息可以知道相应的链路是否发生故障。
[0049]
(3)可编程交换机。
[0050]
可编程交换机即链路实现网络流量的转发以及网络范围的遥测,这些遥测数据将通过终端交换机传递给上层服务器。
[0051]
图3是本发明基于端到端业务性能指标的智能网络故障定位方法一种具体实施方式流程图。
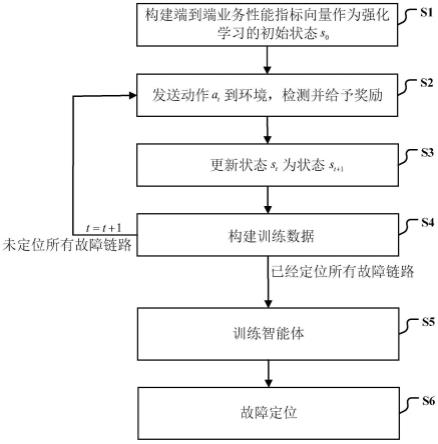
[0052]
在本实施例中,如图3所示,本发明基于端到端业务性能指标的智能网络故障定位方法包括以下步骤:
[0053]
步骤s1:构建端到端业务性能指标向量作为强化学习的初始状态s0[0054]
若网络能实现时钟同步技术获取到端到端业务的单向时延时,采用有向图的构建方式:将每个业务流发送端到接收端的时延以及接收端返回到发送端的时延作为端到端业务性能指标向量的元素,同时,将加上n个三位二进制数,n为有向链路数,用以表征每条链路的检测状态,其中,第一位为1表示未检测,为0表示已检测,第二位为1表示检测为故障,为0表示未检测/检测为正常,第三位为1表示检测为正常,为0表示未检测/检测为故障,初始状态时,n个三位二进制数均为[1 0 0],这样构建出一个2d 3n长度的端到端业务性能指标向量并作为强化学习的初始状态s0,d为业务流数量,j=1,2,
…
,d。需要说明的是,因为这里是有向的,因而一条链路需要分成两个方向,这里的n指的是有向链路数,是网络拓扑中的边数*2的,即是无向图中链路数的两倍。
[0055]
若网络只能获取到端到端业务的往返时延时,采用无向图的构建方式:将每个业务流端到端的往返时延aj作为端到端业务性能指标向量的元素,同时,将加上n个三位二进制数,n为链路数,用以表征每条链路的检测状态,其中,第一位为1表示未检测,为0表示已检测,第二位为1表示检测为故障,为0表示未检测/检测为正常,第三位为1表示检测为正常,为0表示未检测/检测为故障,初始状态时,n个三位二进制数均为[1 0 0],这样构建出一个d 3n长度的端到端业务性能指标向量并作为强化学习的初始状态s0。
[0056]
初始化状检测次数t=0。
[0057]
在本实施例中,以无向图、往返时延为例,构建的端到端业务性能指标向量如图4所示。为便于寻址,d条业务流的往返时延aj从左到右依次排列,而n条链路的检测状态从右到左依次排列,并且其位置用负数来表示,最右边的位置为-1,最左边的位置为-3n,这样,对于第i条链路,其检测状态对应的第一位为state[-3i],第二位为state[-3i 1],第三位为state[-3i 2],初始状态为state[-3i]为1,state[-3i 1]为0,state[-3i 2]为0。具体检测状态的含义为:
[0058][0059][0060]
表1
[0061]
如表1所示,当第一位state[-3i]为1,则表示第i条链路未被检测,当第二位state[-3i 1]为1,则表示第i条链路已经被检测过且检测为故障,当第三位state[-3i 2]为1,则表示第i条链路已经被检测过且检测为正常。由此可知,这三位数中,有且只有一位为1。
[0062]
步骤s2:发送动作a
t
到环境,检测并给予奖励
[0063]
如图5所示,强化学习由两部分组成:智能体和环境。在强化学习过程中,智能体与环境一直在交互。智能体在环境中获取某个状态后,它会利用该状态输出一个动作。然后这个动作会在环境中被执行,环境会根据智能体采取的动作,输出下一个状态以及当前这个动作带来的奖励。智能体的目的就是尽可能多地从环境中获取奖励。强化学习属于现有技术,在此不再赘述。
[0064]
在本实施例中,状态记为state,如图4所示的为端到端业务性能指标向量,动作为每次选择需要检测的链路为第i条,记为动作a
t
。
[0065]
将从网络即环境中获取的状态s
t
输入智能决策模块中智能体,输出动作a
t
即需要检测的链路为第i条,并且每次所需要检测的链路不会与之前的重复,然后智能体将决策即动作a
t
发送至环境即将第i条链路两端路由器的int功能打开检测其是否发生故障,并根据检测结果给予奖励r
t
。
[0066]
强化学习中的奖励机制不宜过于复杂,简单清晰的奖励有利于引导代理选择改善当前环境的动作,并且为了以最少的检测次数将所有的故障链路定位出来,奖励reward的设置如下:
[0067]
a)、决策动作正确,即检测的链路为故障:
[0068]
i.已经定位所有故障链路:r
t
=e-t*b,b》0,e》n*b;
[0069]
ii.未定位所有故障链路:r
t
=c,c》0;
[0070]
b)、决策动作错误,检测的链路为正常:r
t
=-d,d》0;
[0071]
其中,已经定位所有故障链路是指所有用户反馈时延低于正常时延阈值,未定位所有故障链路是指存在用户反馈时延高于正常时延阈值,e、b、c、d为常数项,根据具体实施网络进行确定。
[0072]
在本发明中,增加r
t
=e-t*b的奖励,则表示如果能以越少的检测次数定位所有的路障链路则奖励就会越大。这种做法可以更好地使智能决策模块中智能体(决策神经网络)训练收敛,达到以最少的检测次数定位到所有故障的效果。
[0073]
在本实施例中,具体的奖励设置为:
[0074]
a)、决策动作正确,即检测的链路为故障:
[0075]
i.已经定位所有故障链路:r
t
=1000-t*40,即e=1000,b=40;
[0076]
ii.未定位所有故障链路:r
t
=10,即c=10;
[0077]
b)、决策动作错误,检测的链路为正常:r
t
=-10,即d=0。
[0078]
步骤s3:更新状态s
t
为状态s
t 1
[0079]
a)、决策动作正确,即检测的链路为故障:
[0080]
将状态s
t
中第i条链路对应的三位二进制数修改为[0 1 0],将所有流经第i条链路的业务流的时延设置为正常链路时延。在本实施例中,具体为:
[0081]
i.state[-3i]=0
[0082]
ii.state[-3i 1]=1
[0083]
iii.aj=正常链路时延,j为所属有所有流经第i条链路的业务流。
[0084]
b)、决策动作错误,检测的链路为正常:将状态s
t
中第i条链路对应的三位二进制数修改为[0 0 1]。在本实施例中,具体为:
[0085]
i.state[-3i]=0
[0086]
ii.state[-3i 2]=1
[0087]
从上可以看出,如果决策动作正确,即检测的链路为故障,三位数的第一位需修改为0,表示对该条链路已经进行了检测,第二位需修改为1,表示已经检测为故障链路,并且对于流经该链路的业务时延,都需要减去一个值,这个值为故障链路时延与正常链路时延的差值;如果决策动作错误,即检测的链路为正常,三位数的第一位需修改为0,表示对该条链路已经进行了检测,第三位需修改为1,表示已经检测为正常链路。
[0088]
通过更新状态s
t
得到状态s
t 1
。
[0089]
步骤s4:构建训练数据
[0090]
构建一条训练数据《s
t
,a
t
,r
t
,s
t 1
》,并放入经验回放池,t=t 1,返回步骤(2),直到已经定位所有故障链路。
[0091]
步骤s5:训练智能体
[0092]
用经验回放池的训练数据对智能决策模块中智能体进行训练,训练好的智能决策模块中智能体用于故障定位。训练好的智能决策模块中智能体的输入为端到端业务性能指标向量,输出为整数i,整数i表示需要检测第i条链路。
[0093]
步骤s6:故障定位
[0094]
当需要进行新的故障定位时,用训练好的智能决策模块中智能体,进行步骤s1,并每次令t=t 1,重复步骤s2、s3,直到定位所有故障链路。
[0095]
本发明基于端到端业务性能指标的智能网络故障定位方法不需要打开所有可编程交换机的int功能,只需要对决策模块中智能体给出的链路两端的交换机开发int功能即可,很大程度上缓解了网络开销问题与监控系统过载问题。本发明优势主要还是体现在奖励设计与状态设计方面。奖励设计方面,在动作不正确的情况下,给予的奖励为固定的一个负奖励。在动作正确的情况下根据当前故障定位情况给予正奖励,即在没有定位到所有故障时,给予固定的正奖励,定位到所有故障的时候,所进行检测的次数越小,奖励就会越大。这种做法可以更好地使神经网络训练收敛,达到以最少的检测次数定位到所有故障的效果。在状态设计方面,除了有端到端业务时延之外,还有表征每条链路检测状态的维度,可以更加准确地描述每次检测之后状态的变化。在决策动作正确的情况下,除了有相应表征链路检测状态的维度进行变化,还有流经该链路的业务时延也需要进行相应地变化,让该业务时延从故障的时延大小转变为正常的时延大小,减小该链路在后续决策中的干扰,减小该链路在后续决策中的干扰,使得智能决策模块中智能体(决策神经网络)训练更容易收敛,取得更好的决策效果,快速定位所有故障。
[0096]
本发明在不同网络拓扑中的应用
[0097]
本发明可应用于不同大小的网络拓扑中。在源自于阿德莱德大学的开源网络拓扑中(http://www.topology-zoo.org/),选取aarnet、geant、garr进行应用。其中,这三个网络拓扑信息如表2所示。
[0098][0099]
表2
[0100]
应用结果如附表3所示。
[0101][0102]
表3
[0103]
其中,名字带
“‑
1”表示无向图,带
“‑
2”表示有向图,表头的1次~7次表示检测的次数,可以看出,基本都能以90%以上的概率能以最少的步数检测出来所有故障链路,以99%的概率在7步之内检测出所有故障链路。
[0104]
尽管上面对本发明说明性的具体实施方式进行了描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。